Motion-Compensated Weight Compression
Pith reviewed 2026-06-30 12:55 UTC · model grok-4.3
The pith
Aligning permutation-symmetric blocks across layers turns model depth into a predictable sequence for more efficient weight compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Motion-Compensated Weight Compression aligns permutation-symmetric blocks across layers to maximize cross-layer correspondence, turns depth into a predictable sequence, applies a lightweight layer-sequential predictor with periodic keyframes, and encodes only the quantized prediction residuals using a learned entropy model trained under a rate-distortion objective. The decoder reconstructs the weights by entropy decoding, dequantization, predictor-driven reconstruction, and inverse alignment, producing weights ready for inference without retraining.
What carries the argument
Motion-Compensated Weight Compression (MCWC), which performs cross-layer alignment of permutation-symmetric blocks followed by layer-sequential residual prediction and entropy coding of the residuals.
Load-bearing premise
Permutation-symmetric blocks can be aligned reliably across layers to produce a sequence predictable enough for a lightweight predictor to outperform independent layer compression.
What would settle it
A controlled experiment that applies the full pipeline but replaces the learned alignment step with random or layer-independent permutations and measures whether the rate-accuracy Pareto gains over baselines disappear.
Figures


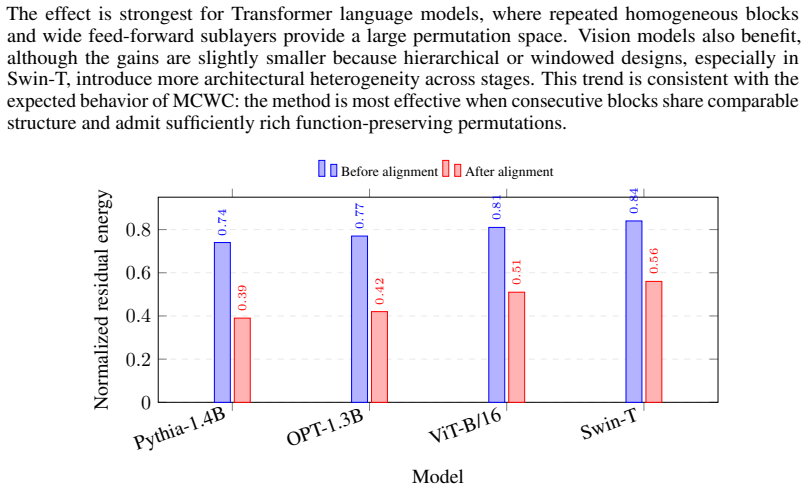


read the original abstract
Neural network weights are increasingly a bottleneck for deployment, yet most compression pipelines treat layers independently and overlook cross-layer redundancy induced by function-preserving symmetries. We propose Motion-Compensated Weight Compression (MCWC), a weight-only codec that aligns permutation-symmetric blocks (e.g., hidden units and attention heads) to maximize cross-layer correspondence, turning depth into a predictable sequence. In the aligned coordinate system, MCWC uses a lightweight layer-sequential predictor with periodic keyframes and encodes only quantized prediction residuals using a learned entropy model trained under a rate distortion objective. A simple decoder reconstructs deployable weights by entropy decoding, dequantization, predictor-driven reconstruction, and inverse alignment, enabling fast weight materialization for inference. Across Transformer language modeling and vision classification, MCWC improves the rate accuracy Pareto frontier over strong quantization and learned weight-codec baselines, while maintaining competitive decode time. Ablations confirm that alignment, prediction, entropy modeling, and keyframe scheduling are each necessary for the full gains. Our code is available via https://github.com/Ism-ail11/MCWC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Motion-Compensated Weight Compression (MCWC), a weight-only codec that aligns permutation-symmetric blocks (hidden units, attention heads) across layers to convert depth into a low-entropy sequence. A lightweight layer-sequential predictor with periodic keyframes then encodes only quantized residuals under a learned entropy model trained with a rate-distortion objective. The decoder performs entropy decoding, dequantization, predictor reconstruction, and inverse alignment to recover deployable weights. Experiments on Transformer language models and vision classifiers report improved rate-accuracy Pareto frontiers versus strong quantization and learned weight-codec baselines, with competitive decode latency; ablations confirm each component (alignment, prediction, entropy modeling, keyframing) is necessary. Code is released.
Significance. If the reported Pareto gains and ablation results hold under full scrutiny, the work provides a practical advance in exploiting function-preserving symmetries for neural weight compression, addressing a key deployment bottleneck for large Transformers. The combination of alignment, sequential prediction, and fast decoding distinguishes it from layer-independent codecs, and the open code release supports reproducibility.
minor comments (3)
- [Abstract] Abstract: the claim of Pareto improvement would be strengthened by including one or two concrete numbers (e.g., bits-per-parameter reduction at iso-accuracy or accuracy delta at fixed rate) rather than qualitative language only.
- [Method] The description of the alignment procedure and its inverse would benefit from an explicit equation or short pseudocode block showing how permutation matrices are computed and applied across layers.
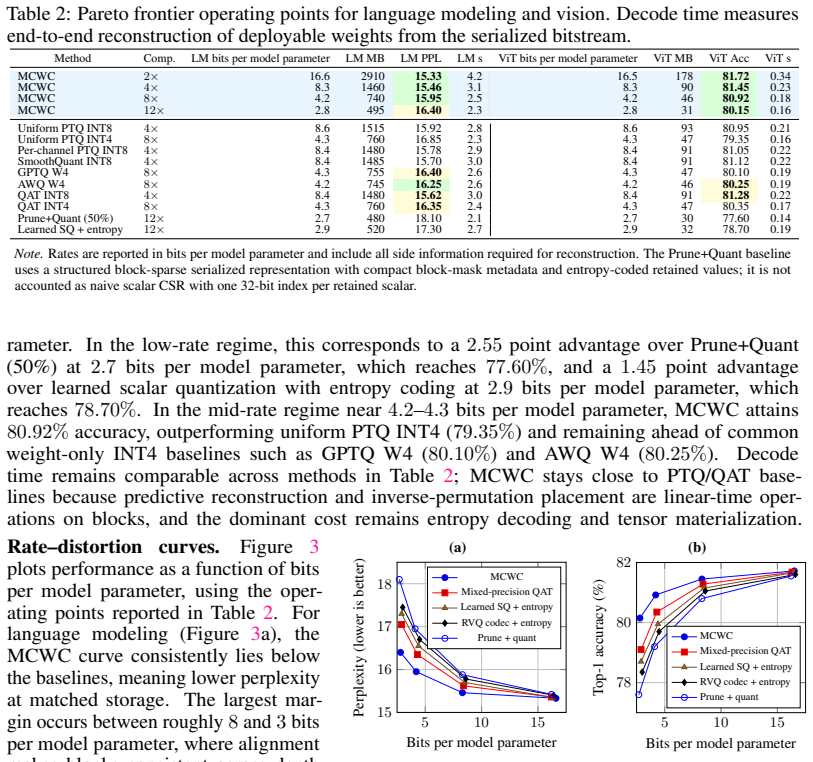
- [Experiments] Figure captions and axis labels in the rate-accuracy plots should explicitly state the datasets, model sizes, and baseline methods used so readers can immediately interpret the curves.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of MCWC and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical weight codec that aligns permutation-symmetric blocks, applies a layer-sequential predictor with keyframes, and encodes quantized residuals under a rate-distortion objective. No derivation chain, equations, or claims are presented that reduce reported gains to quantities defined by the method's own fitted parameters or to self-citations. Ablations are cited as confirming component necessity, and results are shown via external benchmarks on Transformers. This is a standard empirical engineering contribution with independent experimental content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901. Association for Computational Linguistics, 2023
2023
-
[2]
K., Hayase, J., and Srinivasa, S
Samuel K. Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries.arXiv preprint arXiv:2209.04836, 2022. URL https://arxiv.org/abs/2209.04836
-
[3]
Variational image compression with a scale hyperprior
Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Varia- tional image compression with a scale hyperprior. InInternational Conference on Learning Representations, 2018. URLhttps://arxiv.org/abs/1802.01436
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling.arXiv preprint arXiv:2304.01373, 2023. URL https:...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Universal deep neural network compression,
Yoojin Choi, Mostafa El-Khamy, and Jungwon Lee. Universal deep neural network compression,
-
[6]
URLhttps://arxiv.org/abs/1802.02271
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale, 2022. URL https://arxiv.org/abs/2208.07339
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186, 2019
2019
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021. URL...
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [11]
-
[12]
Steven K. Esser, Jeffrey L. McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S. Modha. Learned step size quantization.arXiv preprint arXiv:1902.08153, 2019. URLhttps://arxiv.org/abs/1902.08153
-
[13]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[14]
Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot.arXiv preprint arXiv:2301.00774, 2023. URL https://arxiv.org/abs/2301. 00774
-
[15]
Optimal brain compression: A framework for accurate post-training quantization and pruning
Elias Frantar, Sidak Pal Singh, and Dan Alistarh. Optimal brain compression: A framework for accurate post-training quantization and pruning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URLhttps://arxiv.org/abs/2208.11580
-
[16]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Serverlessllm: Low-latency serverless inference for large language models, 2024
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. Serverlessllm: Low-latency serverless inference for large language models, 2024. URLhttps://arxiv.org/abs/2401.14351
-
[18]
Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. InInternational Conference on Learning Representations, 2016. URLhttps://arxiv.org/abs/1510.00149
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Getting free bits back from rotational symmetries in llms, 2024
Jiajun He, Gergely Flamich, and José Miguel Hernández-Lobato. Getting free bits back from rotational symmetries in llms, 2024. URLhttps://arxiv.org/abs/2410.01309
-
[20]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InInternational Conference on Learning Representations (ICLR),
-
[21]
URLhttps://arxiv.org/abs/1903.12261
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[22]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InIEEE/CVF International Conference on Computer Vision (ICCV),
- [23]
-
[24]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, and Justin Gilmer. The many faces of robustness: A critical analysis of out-of-distribution generalization. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021. URL https: //arx...
-
[25]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. URL https://arxiv.org/abs/1712.05877
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. URLhttps://www.cs.toronto.edu/~kriz/cifar.html
2009
-
[29]
Tiny imagenet visual recognition challenge, 2015
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge, 2015. URL https: //cs231n.stanford.edu/reports/2015/pdfs/yle_project.pdf
2015
-
[30]
Compressing neural networks with inter prediction and linear transformation.IEEE Access, 9:69601–69608, 2021
Kang-Ho Lee and Sung-Ho Bae. Compressing neural networks with inter prediction and linear transformation.IEEE Access, 9:69601–69608, 2021
2021
-
[31]
Brecq: Pushing the limit of post-training quantization by block reconstruction,
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. Brecq: Pushing the limit of post-training quantization by block reconstruction,
- [32]
-
[33]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for LLM compression and acceleration.arXiv preprint arXiv:2306.00978, 2023. URLhttps://arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[36]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022
2022
-
[37]
Dvc: An end-to-end deep video compression framework, 2019
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. Dvc: An end-to-end deep video compression framework, 2019. URL https://arxiv.org/abs/1812. 00101
2019
-
[38]
CoSpaDi: Compressing LLMs via Calibration-Guided Sparse Dictionary Learning
Denis Makhov, Dmitriy Shopkhoev, Magauiya Zhussip, Ammar Ali, and Stamatios Lefkimmi- atis. Cospadi: Compressing llms via calibration-guided sparse dictionary learning, 2026. URL https://arxiv.org/abs/2509.22075
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330,
-
[40]
URLhttps://aclanthology.org/J93-2004/
2004
-
[41]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016. URLhttps://arxiv.org/abs/1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Re- current neural network based language model
Tomáš Mikolov, Martin Karafiát, Lukáš Burget, JanˇCernocký, and Sanjeev Khudanpur. Re- current neural network based language model. InProc. Interspeech, 2010. URL https: //www.isca-archive.org/interspeech_2010/mikolov10_interspeech.html
2010
-
[43]
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
David Minnen, Johannes Ballé, and George Toderici. Joint autoregressive and hierarchical priors for learned image compression, 2018. URLhttps://arxiv.org/abs/1809.02736
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context, 2016. URL https://arxiv. org/abs/1606.06031. 12
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
Fidel A. Guerrero Peña, Heitor Rapela Medeiros, Thomas Dubail, Masih Aminbeidokhti, Eric Granger, and Marco Pedersoli. Re-basin via implicit sinkhorn differentiation, 2022. URL https://arxiv.org/abs/2212.12042
-
[47]
Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
2019
-
[48]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[49]
ImageNet Large Scale Visual Recognition Challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015. doi: 10.1007/s11263-015-0816-y. URL https://arxiv.org/abs/ 1409.0575
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11263-015-0816-y 2015
-
[50]
Neural Weight Compression for Language Models
Jegwang Ryu, Minkyu Kim, Seungjun Shin, Hee Min Choi, Dokwan Oh, and Jaeho Lee. Neural weight compression for language models, 2026. URL https://arxiv.org/abs/ 2510.11234
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Arnab Sanyal, Gourav Datta, Prithwish Mukherjee, Sandeep P. Chinchali, and Michael Or- shansky. Entrollm: Entropy encoded weight compression for efficient large language model inference on edge devices, 2025. URLhttps://arxiv.org/abs/2505.02380
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[53]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017. URLhttps://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
Noam Shazeer, Zhenzhong Lan, Youlong Cheng, Nan Ding, and Le Hou. Talking-heads attention, 2020. URLhttps://arxiv.org/abs/2003.02436
-
[55]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y . Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu, 2023. URLhttps://arxiv.org/abs/2303.06865
-
[56]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. A simple and effective pruning approach for large language models, 2024. URLhttps://arxiv.org/abs/2306.11695
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Ilya O. Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, and Alexey Dosovitskiy. MLP-Mixer: An all-MLP architecture for vision. InAdvances in Neural Information Processing Systems, volume 34, pages 24261–24272, 2021
2021
-
[58]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. InProceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 10347–10357. PMLR, 2021
2021
-
[59]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv. org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Deepcabac: A universal compression algorithm for deep neural networks
Simon Wiedemann, Heiner Kirchhoffer, Stefan Matlage, Paul Haase, Arturo Marban, Talmaj Marinc, David Neumann, Tung Nguyen, Heiko Schwarz, Thomas Wiegand, Detlev Marpe, and Wojciech Samek. Deepcabac: A universal compression algorithm for deep neural networks. IEEE Journal of Selected Topics in Signal Processing, 14(4):700–714, May 2020. ISSN 1941-
2020
-
[62]
URL http://dx.doi.org/10.1109/JSTSP.2020
doi: 10.1109/jstsp.2020.2969554. URL http://dx.doi.org/10.1109/JSTSP.2020. 2969554
-
[63]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023. URL https://arxiv.org/abs/2211.10438
-
[64]
Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,
- [65]
-
[66]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models, 2022. URL https: //arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
+b ′ 2 =W 2 ϕ(W1x+b 1) +b 2.(29) Proof.Letu=W 1x+b 1 andu ′ =W ′ 1x+b ′
-
[68]
Screened greedy (Kcand=16) + refinement
Using (28), u′ = ΠW 1x+ Πb 1 = Π(W 1x+b 1) = Πu.(30) Because ϕ is coordinate-wise as in (27), permuting coordinates before applying ϕ permutes the outputs after applyingϕ: ϕ(u′) =ϕ(Πu) = Πϕ(u).(31) Substituting (31) into the output withW ′ 2 gives W ′ 2ϕ(u′) +b ′ 2 =W 2Π−1Πϕ(u) +b 2 =W 2ϕ(u) +b 2,(32) which proves (29). RemarkD.2 (Parameterized per-channe...
2048
-
[69]
One λ encode cost
and Penn Treebank [ 34, 36] to probe distribution shifts across corpora with different token statistics. For downstream generalization, zero-shot accuracy is reported on LAMBADA (last-word prediction) [ 39] and a small multi-task suite constructed from held-out validation splits, using the decoded weights without prompt tuning. Calibration sequences are a...
1940
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.