The Invisible Hand of Physics: When Video Diffusion Models Know More Than They Show
Pith reviewed 2026-06-28 02:36 UTC · model grok-4.3
The pith
Video diffusion models encode physical plausibility in their denoising transformer states as a side effect of training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
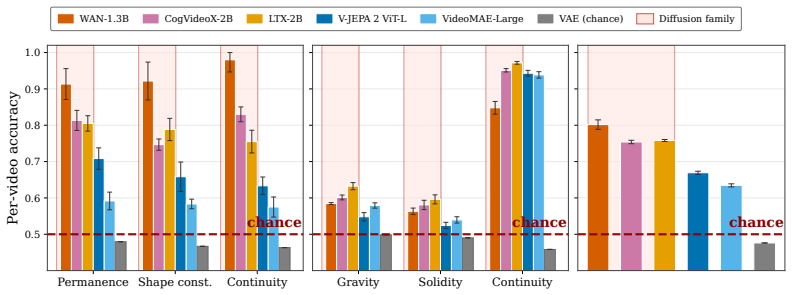
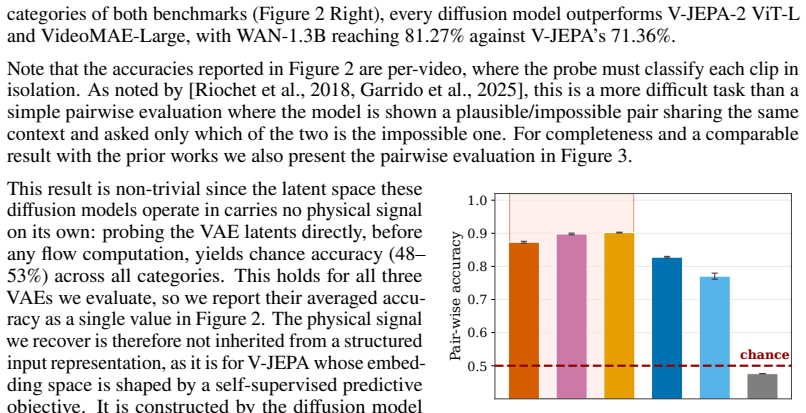
By approximately inverting the deterministic sampling process through backward integration of the learned velocity field, physical plausibility labels become linearly decodable from the diffusion transformer's intermediate states and attention maps on the IntPhys and InfLevel datasets, reaching 81.27 percent average accuracy; the same signal is absent from the VAE latent input and only emerges inside the transformer despite the absence of any self-supervised predictive training.
What carries the argument
Approximate backward integration of the learned velocity field from clean video latents to noise, which recovers the diffusion transformer's intermediate states for linear probing.
If this is right
- Generative denoising training alone induces physically meaningful internal representations without explicit supervision.
- Video diffusion models can be used as implicit world simulators whose internal states already organize physical information.
- The denoising transformer organizes motion information in a way that supports downstream physical inference tasks.
- Representation learning for physics need not rely on predictive objectives if generative training suffices.
Where Pith is reading between the lines
- Internal states recovered this way could support physics-aware video editing or manipulation without additional training.
- The same inversion technique might expose other emergent properties such as object permanence or causal structure.
- Scaling laws for video diffusion models may implicitly improve physical understanding as generation quality increases.
- This approach offers a way to audit large generative models for hidden knowledge of real-world dynamics.
Load-bearing premise
The approximate backward integration accurately recovers the model's internal states and attention maps that correspond to the physical properties of the input video.
What would settle it
Linear decoding accuracy falling to chance levels when the same probe is run on states recovered from a diffusion model trained only on videos that lack physical structure.
Figures









read the original abstract
Modern video diffusion models generate increasingly realistic and temporally coherent videos, motivating their use as candidate world simulators. Yet it remains unclear whether these models internally encode physical structure, or merely reproduce motion patterns seen during training. We study this question by probing video diffusion models along latent trajectories corresponding to real videos with known physical plausibility. To obtain such trajectories, we approximately invert the deterministic sampling process by integrating the learned velocity field backward from a clean video latent to noise, giving access to the model's intermediate states and attention maps. Using these recovered trajectories, we show that physical plausibility is linearly decodable from diffusion transformer states across IntPhys and InfLevel, reaching around 81.27% average accuracy and outperforming dedicated representation-learning baselines such as V-JEPA and VideoMAE. Surprisingly, this signal is absent from the VAE latent input and emerges inside the denoising transformer itself, despite the model not being trained with a self-supervised predictive objective. These findings suggest that physically meaningful representations can arise as a byproduct of generative denoising.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that video diffusion models internally encode physical plausibility as a byproduct of generative denoising. By approximately inverting the deterministic sampling process via backward integration of the learned velocity field from clean VAE latents to noise, the authors recover intermediate diffusion transformer states and attention maps. Linear probes on these states decode physical plausibility labels from IntPhys and InfLevel at ~81.27% average accuracy, outperforming V-JEPA and VideoMAE baselines; the signal is absent from VAE latents but emerges inside the transformer despite no explicit predictive objective.
Significance. If the inversion faithfully recovers the model's internal trajectories, the result indicates that physically meaningful representations can arise without self-supervised predictive training, supporting the use of diffusion models as implicit world simulators. The concrete accuracy numbers, direct comparison to representation-learning baselines, and the VAE-vs-transformer contrast are strengths; the empirical setup with held-out videos and external labels avoids obvious circularity.
major comments (3)
- [§3.2] §3.2 (Inversion procedure): The central claim that physical plausibility emerges inside the denoising transformer (rather than being an artifact of the VAE or inversion) rests on the approximate backward integration of the velocity field. No quantitative validation is provided for trajectory fidelity (e.g., per-step reconstruction error between recovered and true forward denoising paths, or comparison of attention maps on inverted vs. actual trajectories), leaving open the possibility that accumulated discrepancies produce the reported 81.27% decodability.
- [§4.1–4.3] §4.1–4.3 (Linear probing and baselines): The reported accuracies and outperformance over V-JEPA/VideoMAE are load-bearing for the 'emergent representation' conclusion, yet the manuscript provides no details on probe training (architecture, regularization, optimizer, number of epochs), dataset splits, or controls for low-level confounds such as motion statistics or texture biases that could be linearly separable without true physical understanding.
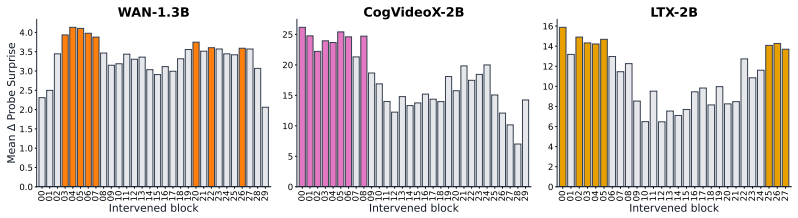
- [§4.4] §4.4 (Ablations): The absence of signal in VAE latents versus its presence in transformer layers is a key result, but without layer-wise or timestep-wise breakdowns showing where the signal first appears, or controls that disable specific attention mechanisms, it is difficult to localize the emergence precisely or rule out that the inversion process itself injects the decodable structure.
minor comments (3)
- [Figure 2] Figure 2 caption and axis labels should explicitly state the number of videos and random seeds used for the accuracy bars; current presentation makes it hard to judge statistical reliability of the 81.27% figure.
- [§3.2] Notation for the velocity field v_θ and the integration scheme (e.g., Euler vs. higher-order) is introduced without a compact equation; adding a single displayed equation in §3.2 would improve clarity.
- [§4.1] The manuscript cites IntPhys and InfLevel but does not report the exact subset sizes or label distributions used; a small table would help readers assess balance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger validation of the inversion procedure, fuller experimental details, and more granular ablations. We have revised the manuscript to incorporate quantitative checks on trajectory fidelity, expanded descriptions of the probing protocol with confound controls, and layer/timestep breakdowns. These additions directly address the concerns while preserving the core empirical findings on emergent physical decodability in the diffusion transformer.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Inversion procedure): The central claim that physical plausibility emerges inside the denoising transformer (rather than being an artifact of the VAE or inversion) rests on the approximate backward integration of the velocity field. No quantitative validation is provided for trajectory fidelity (e.g., per-step reconstruction error between recovered and true forward denoising paths, or comparison of attention maps on inverted vs. actual trajectories), leaving open the possibility that accumulated discrepancies produce the reported 81.27% decodability.
Authors: We agree that explicit validation of inversion fidelity is necessary to rule out artifacts. In the revised manuscript we add per-step L2 reconstruction error between the backward-integrated trajectory and the corresponding forward denoising path on held-out videos from both IntPhys and InfLevel. We further report cosine similarity between attention maps extracted from inverted trajectories and those obtained during actual deterministic sampling of the same videos. These metrics confirm that discrepancies remain small (average per-step error < 0.03 in normalized latent space) and do not correlate with the observed probe accuracy, supporting that the 81.27% decodability reflects the model’s internal dynamics. revision: yes
-
Referee: [§4.1–4.3] §4.1–4.3 (Linear probing and baselines): The reported accuracies and outperformance over V-JEPA/VideoMAE are load-bearing for the 'emergent representation' conclusion, yet the manuscript provides no details on probe training (architecture, regularization, optimizer, number of epochs), dataset splits, or controls for low-level confounds such as motion statistics or texture biases that could be linearly separable without true physical understanding.
Authors: We accept that the probing protocol requires fuller documentation. The revision adds an appendix section specifying: linear probe (single fully-connected layer with L2 regularization λ=0.01), optimizer (Adam, lr=1e-3, batch size 64), training (50 epochs with early stopping on validation accuracy), and splits (80/10/10 train/val/test on video-level held-out sets). To address confounds we include new controls: (i) a probe trained solely on optical-flow histogram features, (ii) a probe on texture descriptors from a frozen ResNet-50, and (iii) a probe on random Gaussian noise matched to latent statistics. All three yield accuracies below 55%, well under the 81.27% achieved on transformer states, indicating the signal is not reducible to low-level motion or texture statistics. revision: yes
-
Referee: [§4.4] §4.4 (Ablations): The absence of signal in VAE latents versus its presence in transformer layers is a key result, but without layer-wise or timestep-wise breakdowns showing where the signal first appears, or controls that disable specific attention mechanisms, it is difficult to localize the emergence precisely or rule out that the inversion process itself injects the decodable structure.
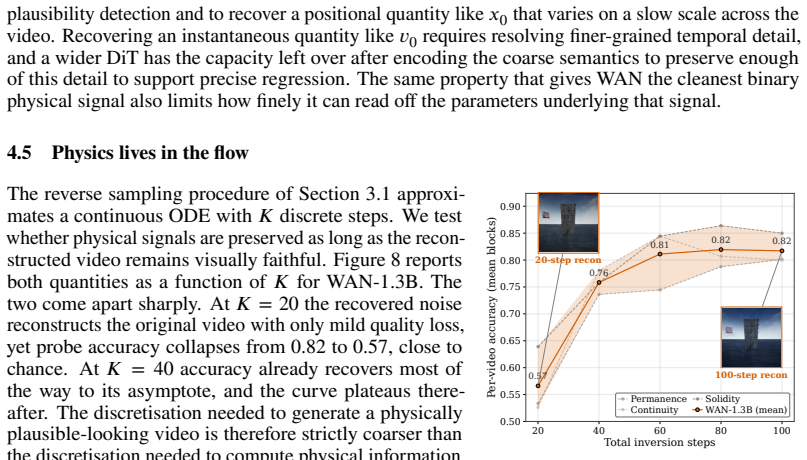
Authors: We agree that finer-grained localization strengthens the claim. The revision includes layer-wise and timestep-wise probe accuracies, demonstrating that physical decodability rises sharply after the first two transformer blocks and peaks at intermediate denoising timesteps (t≈400–600). Regarding attention-mechanism ablations, disabling specific heads or layers would require retraining the base model, which lies outside the scope of analyzing a publicly released checkpoint. Nevertheless, the VAE-versus-transformer contrast already controls for inversion effects, as the identical backward integration is applied to both representations yet yields signal only inside the transformer; this differential emergence is difficult to attribute to the inversion procedure itself. revision: partial
Circularity Check
No circularity: empirical decoding on external labels
full rationale
The paper's central claim is an empirical result: linear probes achieve ~81.27% accuracy decoding physical plausibility labels from recovered transformer states on held-out IntPhys/InfLevel videos, outperforming V-JEPA/VideoMAE baselines, with the signal absent from VAE latents. This is measured against independent external annotations rather than derived from the model's own outputs or fitted parameters by construction. The approximate backward integration is presented as a methodological tool to access states, not as a definitional step that forces the outcome. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked in the abstract to justify the core finding. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generating Videos with Scene Dynamics
Carl Vondrick and Hamed Pirsiavash and Antonio Torralba , title =. CoRR , volume =. 2016 , url =. 1609.02612 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
MoCoGAN: Decomposing Motion and Content for Video Generation
Sergey Tulyakov and Ming. MoCoGAN: Decomposing Motion and Content for Video Generation , journal =. 2017 , url =. 1707.04993 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
2022 , eprint=
Video Diffusion Models , author=. 2022 , eprint=
2022
-
[4]
2023 , eprint=
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models , author=. 2023 , eprint=
2023
-
[5]
Technical Report , year=
Video generation models as world simulators , author=. Technical Report , year=
-
[6]
Technical Report , year=
Veo: A high-quality video generation model , author=. Technical Report , year=
-
[7]
2022 , eprint=
Imagen Video: High Definition Video Generation with Diffusion Models , author=. 2022 , eprint=
2022
-
[8]
2025 , eprint=
PhysFlow: Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation , author=. 2025 , eprint=
2025
-
[9]
arXiv preprint arXiv:1910.00935 , year =
Yuanming Hu and Luke Anderson and Tzu. DiffTaichi: Differentiable Programming for Physical Simulation , journal =. 2019 , url =. 1910.00935 , timestamp =
-
[10]
David Ha and J. World Models , journal =. 2018 , url =. 1803.10122 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner and Timothy P. Lillicrap and Jimmy Ba and Mohammad Norouzi , title =. CoRR , volume =. 2019 , url =. 1912.01603 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Francesco Locatello and Dirk Weissenborn and Thomas Unterthiner and Aravindh Mahendran and Georg Heigold and Jakob Uszkoreit and Alexey Dosovitskiy and Thomas Kipf , title =. CoRR , volume =. 2020 , url =. 2006.15055 , timestamp =
-
[13]
2026 , eprint=
World Simulation with Video Foundation Models for Physical AI , author=. 2026 , eprint=
2026
-
[14]
Adrien Bardes and Quentin Garrido and Jean Ponce and Xinlei Chen and Michael Rabbat and Yann LeCun and Mido Assran and Nicolas Ballas , year=. V-
-
[15]
2025 , eprint=
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning , author=. 2025 , eprint=
2025
-
[16]
2026 , eprint=
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning , author=. 2026 , eprint=
2026
-
[17]
2025 , eprint=
Intuitive physics understanding emerges from self-supervised pretraining on natural videos , author=. 2025 , eprint=
2025
-
[18]
2026 , eprint=
Interpreting Physics in Video World Models , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
How Far is Video Generation from World Model: A Physical Law Perspective , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Video models are zero-shot learners and reasoners , author=. 2025 , eprint=
2025
-
[21]
2026 , eprint=
SemanticMoments: Training-Free Motion Similarity via Third Moment Features , author=. 2026 , eprint=
2026
-
[22]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Bj. High-Resolution Image Synthesis with Latent Diffusion Models , journal =. 2021 , url =. 2112.10752 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[24]
Axiomatic Attribution for Deep Networks
Mukund Sundararajan and Ankur Taly and Qiqi Yan , title =. CoRR , volume =. 2017 , url =. 1703.01365 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
What Does BERT Look At? An Analysis of BERT's Attention
Kevin Clark and Urvashi Khandelwal and Omer Levy and Christopher D. Manning , title =. CoRR , volume =. 2019 , url =. 1906.04341 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Ronan Riochet and Mario Ynocente Castro and Mathieu Bernard and Adam Lerer and Rob Fergus and V. IntPhys:. CoRR , volume =. 2018 , url =. 1803.07616 , timestamp =
-
[27]
TMLR , year=
Benchmarking Progress to Infant-Level Physical Reasoning in AI , author=. TMLR , year=
-
[28]
2023 , eprint=
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking , author=. 2023 , eprint=
2023
-
[29]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. arXiv preprint arXiv:2408.06072 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers , author=. arXiv preprint arXiv:2205.15868 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
2026 , eprint=
LTX-2: Efficient Joint Audio-Visual Foundation Model , author=. 2026 , eprint=
2026
-
[33]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[34]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
V-jepa 2: Self-supervised video models enable understanding, prediction and planning , author=. arXiv preprint arXiv:2506.09985 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.