CRANE: Knowledge Editing for Reasoning MLLMs
Pith reviewed 2026-06-27 17:04 UTC · model grok-4.3
The pith
CRANE uses retrieval plus a routing reward to edit facts in reasoning MLLMs without changing base weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
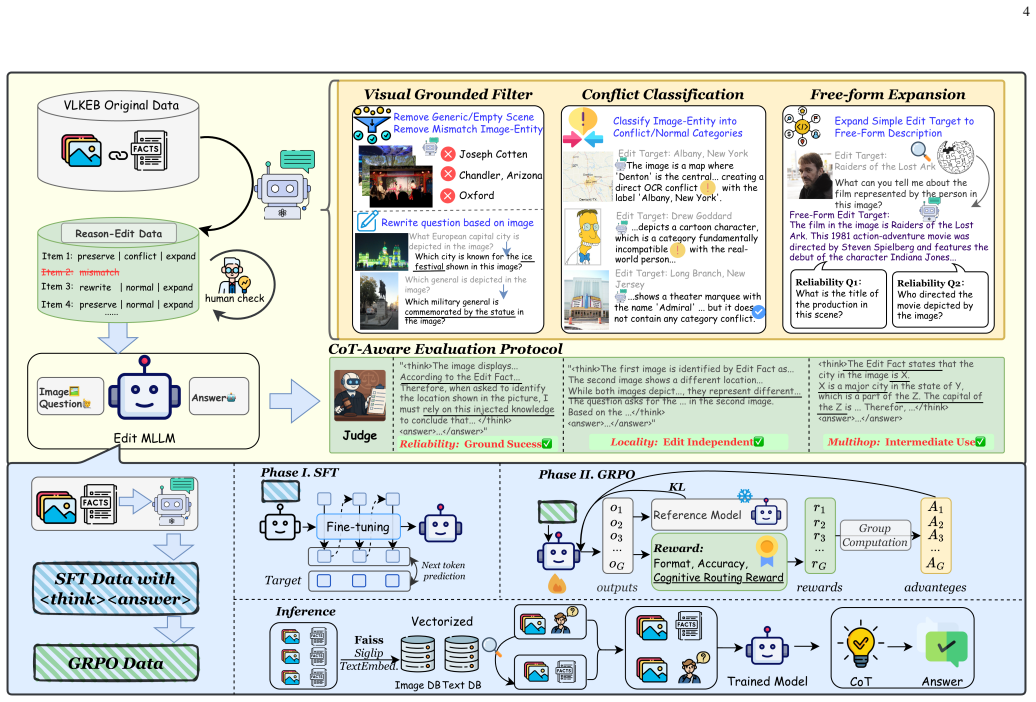
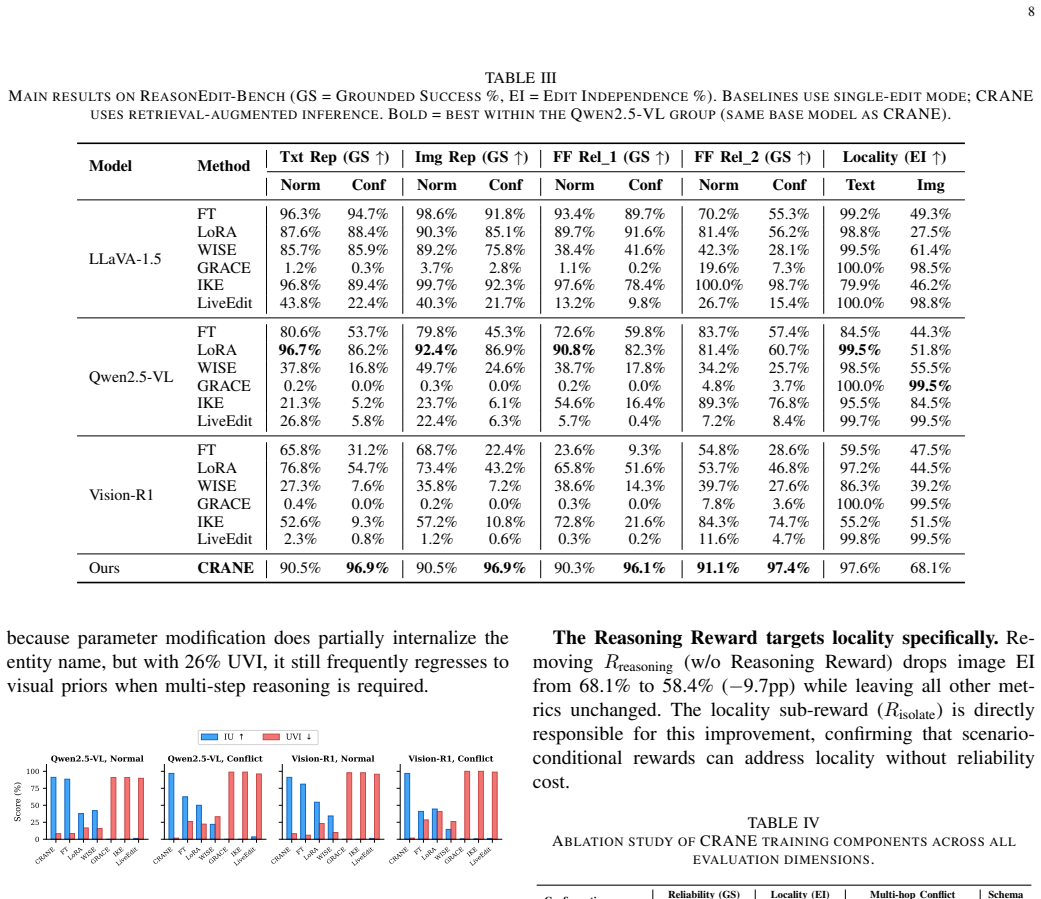
CRANE is a retrieval-augmented framework that requires no per-edit parameter modification to the base MLLM. It pairs a modality-aware dual-library retrieval system with a two-phase process of supervised fine-tuning for structural initialization followed by GRPO optimization under a Cognitive Routing Reward that teaches the model to arbitrate between visual priors and injected edit facts. On ReasonEdit-Bench this produces 96.9 percent Grounded Success on conflict scenarios, 96.9 percent intermediate entity usage in multi-hop chains, 97.6 percent text-locality and 68.1 percent image-locality edit independence, plus 87.0 percent on the out-of-distribution MMEVOKE benchmark under gold retrieval.
What carries the argument
The Cognitive Routing Reward inside the GRPO training phase, which trains the model to select the retrieved edit fact over conflicting visual evidence.
If this is right
- Knowledge edits can be applied to reasoning MLLMs while preserving explicit chain-of-thought format.
- The model incorporates the edit at intermediate steps of multi-hop reasoning chains.
- Edit independence is maintained separately for text and image queries.
- Performance carries to out-of-distribution benchmarks when retrieval supplies the correct fact.
Where Pith is reading between the lines
- If retrieval accuracy drops, grounded success on conflict scenarios would fall sharply.
- The same routing reward might improve editing success on other modalities or longer reasoning traces.
- Stronger retrieval backends could raise the current image-locality score without further training changes.
Load-bearing premise
The dual-library retrieval will always surface the correct edit fact and the Cognitive Routing Reward will reliably train the model to prefer that fact over visual evidence without any base-model weight updates.
What would settle it
A test where the retrieval system returns an incorrect fact or where the trained model continues to reject the edit in its reasoning chain despite the reward signal.
Figures


read the original abstract
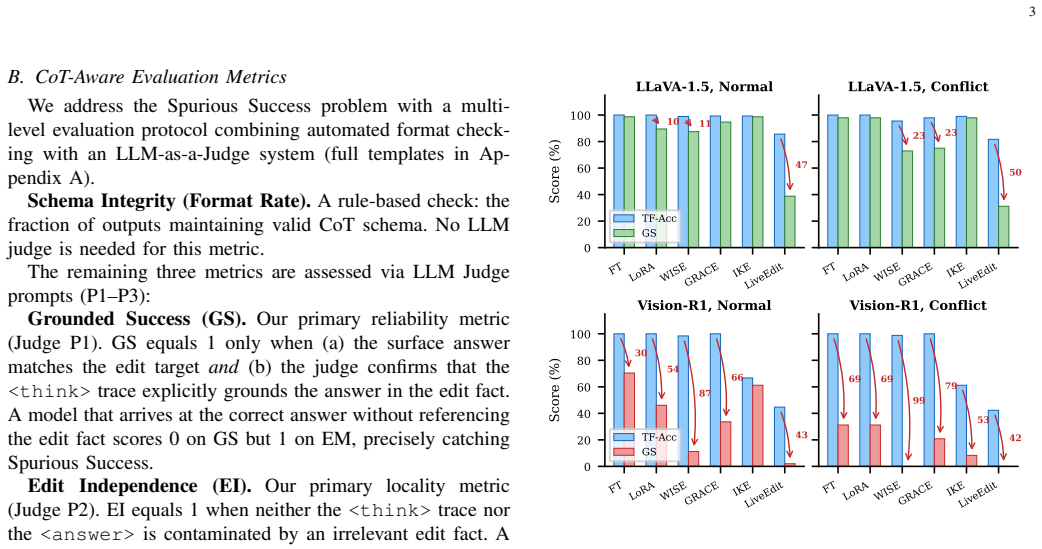
The emergence of reasoning multimodal large language models (MLLMs), which generate explicit chain-of-thought (CoT) reasoning before producing answers, has introduced a new challenge for knowledge editing: methods that appear successful under traditional metrics (teacher-forcing accuracy up to 100%) can fail severely when the model's reasoning process is examined (Grounded Success as low as 0%). We identify three failure modes: (1) Structural Collapse, where weight-modifying methods destroy the CoT format; (2) Cognitive Dissonance, where the model's reasoning chain actively rejects the injected edit fact based on visual evidence; and (3) Shallow Internalization, where methods succeed on exact queries but fail on rephrase or multi-hop variants. On reasoning MLLMs, these modes interact: methods that generalize (FT, LoRA) trigger format collapse, while methods without deep modification cannot generalize. To expose these failures, we propose a CoT-aware evaluation protocol and construct ReasonEdit-Bench, with conflict stratification, multi-level probes, and multi-hop portability tests. We propose CRANE, a retrieval-augmented framework that requires no per-edit parameter modification. CRANE combines a modality-aware dual-library retrieval system with a two-phase training strategy: Supervised Fine-Tuning (SFT) for structural initialization, followed by GRPO with a Cognitive Routing Reward that trains the model to arbitrate between visual priors and injected edit facts. On ReasonEdit-Bench, CRANE achieves 96.9% Grounded Success on conflict scenarios and 96.9% intermediate entity usage in multi-hop chains, with 97.6% text-locality and 68.1% image-locality Edit Independence. On the out-of-distribution MMEVOKE benchmark, CRANE reaches 87.0% under gold retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three failure modes (Structural Collapse, Cognitive Dissonance, Shallow Internalization) that arise when applying knowledge editing to reasoning MLLMs, introduces ReasonEdit-Bench with conflict stratification and multi-hop tests, and proposes CRANE: a retrieval-augmented framework using modality-aware dual-library retrieval, SFT followed by GRPO with a Cognitive Routing Reward, that achieves high Grounded Success and Edit Independence without any per-edit parameter updates to the base MLLM. Results include 96.9% Grounded Success on conflict scenarios and 87.0% on out-of-distribution MMEVOKE under gold retrieval.
Significance. If the central empirical claims hold under non-oracle retrieval, the work would be significant for demonstrating a parameter-free editing approach that preserves CoT structure and arbitrates between visual priors and injected facts via reward-based training. The CoT-aware evaluation protocol and stratified benchmark construction are concrete contributions that could be adopted more broadly.
major comments (1)
- [Abstract] Abstract: the 87.0% OOD result on MMEVOKE is explicitly conditioned on 'gold retrieval.' This assumption is load-bearing for the no-per-edit-update claim, because the Cognitive Routing Reward has no injected fact to prefer when the dual-library system fails to surface the edit (a realistic risk in conflict or multi-hop cases). The manuscript must either report retrieval success rates on the same splits or provide an ablation without gold retrieval to substantiate the arbitration mechanism.
minor comments (2)
- The abstract states performance numbers (96.9%, 97.6%, 68.1%) but provides no experimental details, baselines, or statistical tests; these must be fully specified in the methods and results sections with clear protocol descriptions.
- Ensure the three failure modes are operationally defined with concrete metrics (e.g., how Structural Collapse is quantified via CoT format deviation) rather than left at the level of the abstract description.
Simulated Author's Rebuttal
We thank the referee for highlighting the conditioning of the OOD result and its implications for the parameter-free editing claim. We address the concern directly below and will revise the manuscript to provide the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 87.0% OOD result on MMEVOKE is explicitly conditioned on 'gold retrieval.' This assumption is load-bearing for the no-per-edit-update claim, because the Cognitive Routing Reward has no injected fact to prefer when the dual-library system fails to surface the edit (a realistic risk in conflict or multi-hop cases). The manuscript must either report retrieval success rates on the same splits or provide an ablation without gold retrieval to substantiate the arbitration mechanism.
Authors: We agree that the 87.0% MMEVOKE figure is reported under gold retrieval, as already stated in the abstract. The primary empirical claims rest on ReasonEdit-Bench, where the complete CRANE pipeline (modality-aware dual-library retrieval + SFT + GRPO with Cognitive Routing Reward) is evaluated end-to-end and achieves 96.9% Grounded Success on conflict edits without any per-edit parameter updates. MMEVOKE is presented strictly as an out-of-distribution sanity check under idealized retrieval. To directly address the load-bearing concern, the revised manuscript will include retrieval success rates of the dual-library system on the identical MMEVOKE splits used for the 87.0% figure. This will quantify how often the injected facts are surfaced and thereby substantiate that the arbitration mechanism operates under the framework's actual retrieval conditions. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks with no self-referential derivations
full rationale
The paper describes an empirical framework (modality-aware retrieval + SFT/GRPO training with a routing reward) and reports measured performance numbers on ReasonEdit-Bench and MMEVOKE. No equations, uniqueness theorems, or first-principles derivations are presented that reduce to fitted inputs or self-citations by construction. All central claims rest on observed success rates under stated evaluation conditions rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,”Advances in neural information processing systems, vol. 35, pp. 17 359–17 372, 2022
2022
-
[2]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inInternational Conference on Learning Rep- resentations, 2022
2022
-
[3]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carneyet al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[6]
Wise: Rethinking the knowledge memory for lifelong model editing of large language models,
P. Wang, Z. Li, N. Zhang, Z. Xu, Y . Yao, Y . Jiang, P. Xie, F. Huang, and H. Chen, “Wise: Rethinking the knowledge memory for lifelong model editing of large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 53 764–53 797, 2024
2024
-
[7]
Aging with grace: Lifelong model editing with discrete key-value adaptors,
T. Hartvigsen, S. Sankaranarayanan, H. Palangi, Y . Kim, and M. Ghas- semi, “Aging with grace: Lifelong model editing with discrete key-value adaptors,”Advances in Neural Information Processing Systems, vol. 36, pp. 47 934–47 959, 2023
2023
-
[8]
The mirage of model editing: Revisiting evaluation in the wild,
W. Yang, F. Sun, J. Tan, X. Ma, Q. Cao, D. Yin, H. Shen, and X. Cheng, “The mirage of model editing: Revisiting evaluation in the wild,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 15 336– 15 354
2025
-
[9]
Vlkeb: A large vision-language model knowledge editing benchmark,
H. Huang, H. Zhong, T. Yu, Q. Liu, S. Wu, L. Wang, and T. Tan, “Vlkeb: A large vision-language model knowledge editing benchmark,” Advances in Neural Information Processing Systems, vol. 37, pp. 9257– 9280, 2024
2024
-
[10]
When large multimodal models confront evolving knowledge: Challenges and explorations,
K. Jiang, Y . Du, Y . Ding, Y . Ren, N. Jiang, Z. Gao, Z. Zheng, L. Liu, B. Li, and Q. Li, “When large multimodal models confront evolving knowledge: Challenges and explorations,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Mass-editing memory in a transformer,
K. Meng, A. S. Sharma, A. J. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[12]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y . Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4862–4876
2023
-
[13]
Can we edit multimodal large language models?
S. Cheng, B. Tian, Q. Liu, X. Chen, Y . Wang, H. Chen, and N. Zhang, “Can we edit multimodal large language models?” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 13 877–13 888
2023
-
[14]
Lifelong knowledge editing for vision language models with low-rank mixture-of- experts,
Q. Chen, C. Wang, D. Wang, T. Zhang, W. Li, and X. He, “Lifelong knowledge editing for vision language models with low-rank mixture-of- experts,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9455–9466
2025
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Visual-rft: Visual reinforcement fine-tuning,
Z. Liu, Z. Sun, Y . Zang, X. Dong, Y . Cao, H. Duan, D. Lin, and J. Wang, “Visual-rft: Visual reinforcement fine-tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2034–2044
2025
-
[18]
R1-v: Reinforcing super generalization ability in vision-language models with less than $3,
L. Chen, L. Li, H. Zhao, Y . Song, and Vinci, “R1-v: Reinforcing super generalization ability in vision-language models with less than $3,” https: //github.com/Deep-Agent/R1-V, 2025, accessed: 2025-02-02
2025
-
[19]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
W. Huang, B. Jia, Z. Zhai, S. Cao, Z. Ye, F. Zhao, Z. Xu, X. Tang, Y . Hu, and S. Lin, “Vision-r1: Incentivizing reasoning capability in multimodal large language models,”arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Expllm: Towards chain of thought for facial expression recognition,
X. Lan, J. Xue, J. Qi, D. Jiang, K. Lu, and T.-S. Chua, “Expllm: Towards chain of thought for facial expression recognition,”IEEE Transactions on Multimedia, 2025
2025
-
[21]
Visual context and commonsense- guided causal chain-of-thoughts for visual commonsense reasoning,
X. Li, J. Zhao, T. Wei, and S. Sun, “Visual context and commonsense- guided causal chain-of-thoughts for visual commonsense reasoning,” IEEE Transactions on Multimedia, 2026
2026
-
[22]
Learning to Edit Knowledge via Instruction-based Chain-of-Thought Prompting
J. Fu, Y . Bai, L. He, Y . Lou, Y . Zhao, L. Sun, and S. Su, “Learning to edit knowledge via instruction-based chain-of-thought prompting,”arXiv preprint arXiv:2604.05540, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Object hallucination in image captioning,
A. Rohrbach, L. A. Hendricks, K. Burns, T. Darrell, and K. Saenko, “Object hallucination in image captioning,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 4035–4045
2018
-
[24]
Evaluating object hallucination in large vision-language models,
Y . Li, Y . Du, K. Zhou, J. Wang, X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 292–305
2023
-
[25]
Mitigating hallucinations in large vision-language models via visual-enhanced contrastive decoding,
P. Qiang, H. Tan, H. Zhang, X. Li, R. Li, and J. Liang, “Mitigating hallucinations in large vision-language models via visual-enhanced contrastive decoding,”IEEE Transactions on Multimedia, 2026
2026
-
[26]
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback,
T. Yu, Y . Yao, H. Zhang, T. He, Y . Han, G. Cui, J. Hu, Z. Liu, H.-T. Zheng, M. Sunet al., “Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 807–13 816
2024
-
[27]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Deep reversible consistency learning for cross-modal retrieval,
R. Pu, Y . Qin, D. Peng, X. Song, and H. Zheng, “Deep reversible consistency learning for cross-modal retrieval,”IEEE Transactions on Multimedia, 2025
2025
-
[29]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with gpus,”IEEE transactions on big data, vol. 7, no. 3, pp. 535–547, 2019
2019
-
[30]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
2023
-
[31]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 296–26 306
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.