Mind the Privileged-to-Camera Gap: Actor-Centric Sidecar Supervision for Camera-First Open-Loop Waypoint Prediction
Pith reviewed 2026-06-26 17:33 UTC · model grok-4.3
The pith
Road-user sidecar supervision cuts final displacement error to 1.223 meters in camera waypoint prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
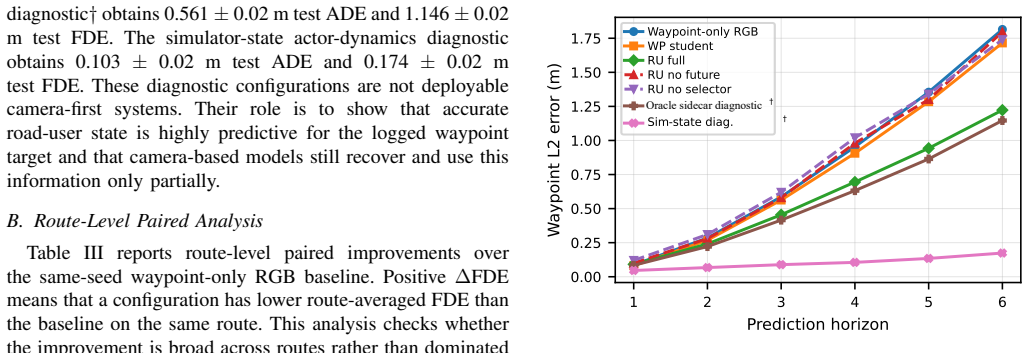
Road-user sidecar supervision (RU-sidecar) supplies actor grounding, privileged hindsight actor relevance relative to the logged ego trajectory, and selected-actor short-horizon motion labels during training for a model whose inputs at inference remain multi-view RGB, ego state, and route commands. This supervision reduces final displacement error to 1.223 meters from 1.716 meters in a matched no-teacher non-sidecar RGB control and improves performance on 1417 of 1494 routes.
What carries the argument
Road-user sidecar supervision (RU-sidecar), which supplies privileged actor-centric labels only during training.
If this is right
- Gains appear in every nonempty actor-conditioned slice, including a 29.1 percent reduction for samples containing at least four valid sidecar actors.
- A 30.0 percent error reduction occurs on samples where a vulnerable road user is present.
- Optional simulator-state teacher alignment can reach 1.186 meters final displacement error, though with higher seed variability.
- Non-deployable simulator-state diagnostics remain stronger than the camera model, indicating the privileged-to-camera gap persists.
Where Pith is reading between the lines
- The method shows one route for using rich simulation labels to shape representations that survive deployment without those labels.
- Further reductions may require additional mechanisms to narrow the remaining gap between full simulator diagnostics and camera-only performance.
- Analogous sidecar supervision could be tested in other camera-based prediction settings where simulation supplies dense actor metadata.
Load-bearing premise
Simulator-derived sidecar labels supply actor-centric supervision whose benefits transfer to the camera model on new routes.
What would settle it
Measuring final displacement error on real-world camera footage collected without simulator access would test whether the reported reductions persist outside the training environment.
Figures

read the original abstract
Camera-first autonomous-driving models predict future ego waypoints from images, ego-state features, and route commands, but waypoint supervision alone does not explicitly supervise actor-level representations of nearby road users. We study this as supervised representation learning for open-loop waypoint prediction. The deployable model uses multi-view RGB, ego state, and route command at inference. During training, simulator-derived sidecar labels supervise actor grounding, privileged hindsight actor relevance relative to the logged ego trajectory, and selected-actor short-horizon motion; these labels are never inference inputs. We evaluate route-disjoint splits with matched architecture, optimizer, validation criterion, checkpoint selection, and three seeds. A plain waypoint-only RGB baseline obtains 1.815$\pm$0.02 m final displacement error (FDE), and the matched no-teacher non-sidecar RGB control obtains 1.716$\pm$0.02 m. Road-user sidecar supervision (RU-sidecar) reduces FDE to 1.223$\pm$0.01 m, a 32.6% reduction over the plain baseline and 28.7% over the matched no-teacher non-sidecar RGB control. It improves over the plain baseline on 1445/1494 routes and over the matched no-teacher non-sidecar RGB control on 1417/1494 routes. Actor-conditioned slices show gains in all nonempty subsets, including 29.1% reduction for samples with at least four valid sidecar actors and 30.0% when a vulnerable road user is present. Optional simulator-state teacher alignment reaches 1.186$\pm$0.15 m FDE, but higher seed variability makes it secondary. Non-deployable simulator-state diagnostics remain stronger, indicating a privileged-to-camera gap. The evidence is limited to open-loop simulation diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes road-user sidecar (RU-sidecar) supervision using simulator-derived labels for actor grounding, relevance to ego trajectory, and short-horizon motion to train a camera-based model for open-loop waypoint prediction. The deployable model uses only RGB, ego state, and route commands at inference. On route-disjoint splits with matched setups and three seeds, RU-sidecar achieves 1.223±0.01 m FDE, a 28.7% improvement over the matched no-teacher control (1.716±0.02 m) and wins on 1417/1494 routes. The paper notes that simulator-state teacher alignment is stronger at 1.186±0.15 m but with higher variability, and that a privileged-to-camera gap remains.
Significance. This work provides empirical evidence that actor-centric supervision from privileged sources can be transferred to improve camera models without changing the inference pipeline. Strengths include the use of route-disjoint splits, multiple random seeds with standard deviations, per-route win counts, and actor-conditioned performance slices. The acknowledgment of the remaining gap between sidecar and full simulator state is honest and useful for the field.
major comments (2)
- [Abstract] Abstract: The evaluation is limited to open-loop FDE metrics in simulation; while this matches the stated scope of waypoint prediction, the absence of any closed-loop rollout results or analysis of how the FDE reduction affects downstream metrics such as collision avoidance leaves the practical impact of the 28.7% gain untested.
- [Abstract] Abstract: The 32.6% reduction is reported relative to the plain baseline, yet the matched no-teacher non-sidecar control already improves 5.5% over the plain baseline; the manuscript should isolate the incremental contribution of the sidecar labels versus the no-teacher control to substantiate that the actor-centric supervision is the primary driver.
minor comments (1)
- The abstract states results with three seeds and reports standard deviations, but does not indicate whether the same seeds were used for all ablations to ensure direct comparability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The evaluation is limited to open-loop FDE metrics in simulation; while this matches the stated scope of waypoint prediction, the absence of any closed-loop rollout results or analysis of how the FDE reduction affects downstream metrics such as collision avoidance leaves the practical impact of the 28.7% gain untested.
Authors: We agree that closed-loop evaluation and downstream metrics such as collision rates would provide further insight into practical impact. However, the stated scope of the work is open-loop waypoint prediction (as reflected in the title, abstract, and final sentence of the abstract). We have already been explicit about this boundary condition by stating that 'The evidence is limited to open-loop simulation diagnostics.' Extending to closed-loop rollouts would require additional simulation infrastructure and evaluation protocols outside the current contribution on actor-centric sidecar supervision for representation learning. revision: no
-
Referee: [Abstract] Abstract: The 32.6% reduction is reported relative to the plain baseline, yet the matched no-teacher non-sidecar control already improves 5.5% over the plain baseline; the manuscript should isolate the incremental contribution of the sidecar labels versus the no-teacher control to substantiate that the actor-centric supervision is the primary driver.
Authors: The manuscript already isolates the incremental contribution. We report the plain waypoint-only baseline at 1.815±0.02 m FDE, the matched no-teacher non-sidecar control at 1.716±0.02 m FDE (explicitly noting the 5.5% improvement), and RU-sidecar at 1.223±0.01 m FDE, with a 28.7% reduction relative to the no-teacher control. We further provide per-route win counts (1445/1494 over plain baseline; 1417/1494 over no-teacher control) and actor-conditioned slices that hold across all nonempty subsets. These elements directly substantiate that the sidecar labels drive the primary gain beyond the no-teacher control. revision: no
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper reports FDE values and per-route win counts from training RGB waypoint predictors under different supervision regimes (plain baseline, no-teacher control, RU-sidecar) on route-disjoint held-out splits with matched architectures and seeds. These are standard empirical outcomes on external test data; no equations, fitted parameters, or self-citations are invoked to derive the metrics. The optional simulator-state alignment result is presented as secondary and does not underpin the main RU-sidecar claim. No self-definitional, fitted-input, or self-citation patterns appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulator-derived sidecar labels accurately capture actor grounding, relevance to the logged ego trajectory, and short-horizon motion in a form that benefits camera representation learning.
Reference graph
Works this paper leans on
-
[1]
End-to-End Driving Via Conditional Imitation Learning , year =
Codevilla, Felipe and Miiller, Matthias and L\'. End-to-End Driving Via Conditional Imitation Learning , year =. 2018 IEEE International Conference on Robotics and Automation (ICRA) , pages =. doi:10.1109/ICRA.2018.8460487 , abstract =
-
[2]
Proceedings of the Conference on Robot Learning , pages =
Learning by Cheating , author =. Proceedings of the Conference on Robot Learning , pages =. 2020 , editor =
2020
-
[3]
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach , year=
Zhang, Zhejun and Liniger, Alexander and Dai, Dengxin and Yu, Fisher and Van Gool, Luc , booktitle=. End-to-End Urban Driving by Imitating a Reinforcement Learning Coach , year=
-
[4]
TransFuser: Imitation With Transformer-Based Sensor Fusion for Autonomous Driving , year=
Chitta, Kashyap and Prakash, Aditya and Jaeger, Bernhard and Yu, Zehao and Renz, Katrin and Geiger, Andreas , journal=. TransFuser: Imitation With Transformer-Based Sensor Fusion for Autonomous Driving , year=
-
[5]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Wu, Penghao and Jia, Xiaosong and Chen, Li and Yan, Junchi and Li, Hongyang and Qiao, Yu , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[6]
CVPR , year=
Learning from all vehicles , author=. CVPR , year=
-
[7]
Sophia Koepke and Zeynep Akata and Andreas Geiger , title =
Katrin Renz and Kashyap Chitta and Otniel-Bogdan Mercea and A. Sophia Koepke and Zeynep Akata and Andreas Geiger , title =. Conference on Robotic Learning (CoRL) , year =
-
[8]
The Thirteenth International Conference on Learning Representations , year=
Enhancing End-to-End Autonomous Driving with Latent World Model , author=. The Thirteenth International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2309.09777 , year=
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving , author=. arXiv preprint arXiv:2309.09777 , year=
-
[10]
arXiv preprint arXiv:2402.16720 , year=
Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2) , author=. arXiv preprint arXiv:2402.16720 , year=
-
[11]
2023 , eprint=
LMDrive: Closed-Loop End-to-End Driving with Large Language Models , author=. 2023 , eprint=
2023
-
[12]
2017 , editor =
Dosovitskiy, Alexey and Ros, German and Codevilla, Felipe and Lopez, Antonio and Koltun, Vladlen , booktitle =. 2017 , editor =
2017
-
[13]
Khanzada, F. K. and Kwon, J. , year =. Driving. doi:10.48550/arXiv.2512.04279 , journal =
-
[14]
Advances in Neural Information Processing Systems (
Model-Based Imitation Learning for Urban Driving , author =. Advances in Neural Information Processing Systems (
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.