Demystifying Data Organization for Enhanced LLM Training
Pith reviewed 2026-06-29 07:04 UTC · model grok-4.3
The pith
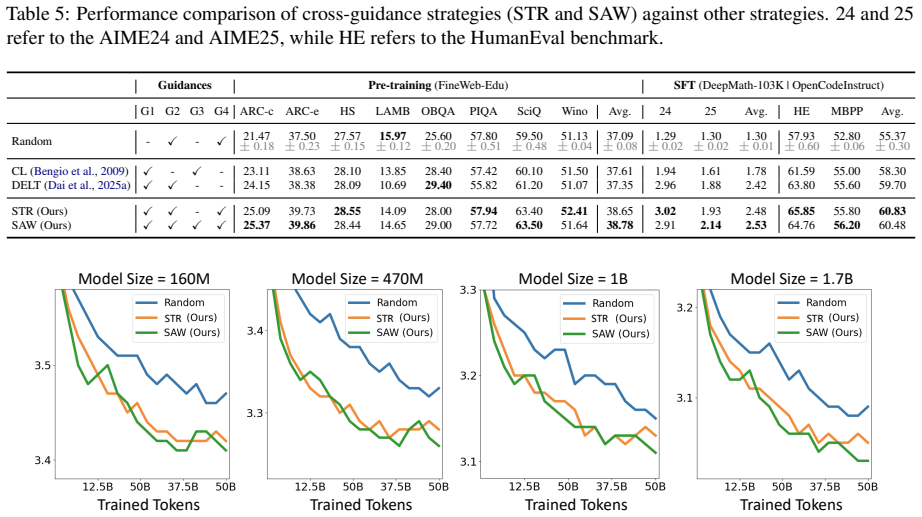
Data ordering methods STR and SAW, guided by four guidelines, enhance the stability and performance of LLM training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formalizing Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity as rules for data organization and instantiating them in the STR and SAW ordering procedures, the paper shows that reuse of pre-computed sample scores produces training runs that are both more stable and higher-performing than standard random or length-based ordering, with the gains holding across scales and stages.
What carries the argument
The four guidelines (Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, Local Diversity) that convert pre-computed sample scores into explicit data sequences via the STR and SAW ordering methods.
If this is right
- Training runs become more stable when data sequences follow the four guidelines.
- Performance improves on both pre-training and supervised fine-tuning tasks.
- The improvements appear across model scales and data volumes.
- The methods incur almost no extra compute because they reuse existing scores.
- Local diversity within batches and curriculum continuity across epochs each contribute to the observed gains.
Where Pith is reading between the lines
- Ordering could be inserted as a lightweight post-selection step in any existing data pipeline that already computes per-sample scores.
- The same guidelines might be tested on non-LLM sequence models to check whether the stability effect is architecture-specific.
- Separate validation of whether efficiency-oriented scores are also optimal for ordering would clarify the scope of the reuse assumption.
Load-bearing premise
That reusing pre-computed sample-level scores originally generated for data efficiency is sufficient to produce effective data organization without requiring new scoring or validation of the scores' relevance to ordering.
What would settle it
A controlled comparison in which identical models are trained on the same data but with random ordering versus STR/SAW ordering, showing no measurable difference in loss trajectories or downstream metrics, would falsify the central claim.
Figures




read the original abstract
Large Language Models (LLMs) have revolutionized various fields, yet their training efficiency is heavily reliant on effective data curation. While data selection has been widely studied, the strategic data organization for enhanced training remains an underexplored area, particularly since current LLMs are often trained for only one or a few epochs. This paper systematically explores the influence of data organization on LLM training by reusing pre-computed sample-level scores originally generated for data efficiency, thereby incurring minimal additional computational overhead. We identify and formalize four key guidelines for optimizing data organization: Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity. Guided by them, we introduce two novel data ordering methods termed STR and SAW. Extensive experiments across different model scales and data sizes, encompassing both pre-training and SFT stages, validate the effectiveness of our summarized guidelines. They also demonstrate the robustness of our proposed data ordering methods in enhancing the stability and performance of LLM training. Github Link: https://github.com/microsoft/data-efficacy/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that reusing pre-computed sample-level scores (originally for data-efficiency selection) allows identification of four guidelines for data organization—Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity—which are instantiated in two new ordering methods (STR and SAW). These methods are said to enhance training stability and performance for LLMs in both pre-training and SFT, with experiments across model scales and data sizes demonstrating robustness and minimal overhead.
Significance. If the attribution of gains to the guidelines and ordering methods holds, the work fills a gap in LLM training efficiency literature by offering practical, low-overhead organization strategies beyond selection. Strengths include the breadth of experiments across scales/stages and the public GitHub repository for reproducibility.
major comments (2)
- [Experiments and Guideline Formalization] The central experimental validation reuses scores computed for static selection (quality/influence/diversity) to instantiate ordering methods; no ablation or correlation analysis is provided to confirm these scores encode sequencing signals such as per-epoch loss trajectories or gradient norms required by Curriculum Continuity and Cyclic Scheduling.
- [Experimental Results] The claim that STR and SAW produce measurable gains attributable to the four guidelines rests on outcomes using the reused scores; without controls that swap in ordering-specific scores or randomize score order while preserving the guideline structure, it is unclear whether improvements are driven by the proposed organization or by the particular score distribution.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments' but does not quantify the stability or performance deltas (e.g., loss variance reduction or final accuracy gains) that would allow readers to assess effect sizes.
- [Method] Notation for STR and SAW is introduced without an explicit algorithmic pseudocode or complexity analysis in the main text, making it harder to verify the 'minimal overhead' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental validation and attribution of gains. We address each major comment below and commit to revisions that strengthen the link between the reused scores, the proposed guidelines, and the observed improvements.
read point-by-point responses
-
Referee: [Experiments and Guideline Formalization] The central experimental validation reuses scores computed for static selection (quality/influence/diversity) to instantiate ordering methods; no ablation or correlation analysis is provided to confirm these scores encode sequencing signals such as per-epoch loss trajectories or gradient norms required by Curriculum Continuity and Cyclic Scheduling.
Authors: We agree that the manuscript lacks explicit correlation analysis or ablations connecting the pre-computed selection scores to sequencing-specific signals such as per-epoch loss trajectories or gradient norms. The four guidelines were motivated by the statistical properties of these scores as established in prior selection literature, and the consistent gains across model scales and stages provide indirect support. In the revised manuscript we will add a dedicated analysis section correlating the scores with gradient norms and loss trajectories to directly address this point. revision: yes
-
Referee: [Experimental Results] The claim that STR and SAW produce measurable gains attributable to the four guidelines rests on outcomes using the reused scores; without controls that swap in ordering-specific scores or randomize score order while preserving the guideline structure, it is unclear whether improvements are driven by the proposed organization or by the particular score distribution.
Authors: The reported experiments already compare STR and SAW against random ordering and other baselines that use the identical score distribution, demonstrating gains. We nevertheless recognize that the absence of controls that randomize ordering while preserving guideline structure or that substitute ordering-specific scores leaves room for alternative explanations. We will add these control experiments in the revision to isolate the contribution of the organization guidelines from the underlying score distribution. revision: yes
Circularity Check
No significant circularity; claims rest on independent experimental validation.
full rationale
The paper reuses pre-existing sample-level scores from prior data-efficiency work, identifies four guidelines (Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, Local Diversity), instantiates them in STR and SAW ordering methods, and supports effectiveness via new experiments across model scales, data sizes, pre-training, and SFT. No derivation step reduces a claimed result to its inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise collapses to a self-citation chain. The central claims are falsifiable empirical outcomes rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visualizing and Understanding Curriculum Learning for Long Short-Term Memory Networks
Evaluating large language models trained on code. Zui Chen, Tianqiao Liu, Mi Tian, Weiqi Luo, Zitao Liu, and 1 others. 2025. Advancing mathematical rea- soning in language models: The impact of problem- solving data, data synthesis methods, and training stages. InThe Thirteenth International Conference on Learning Representations. V olkan Cirik, Eduard Ho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
On large-batch training for deep learning: Gen- eralization gap and sharp minima.arXiv preprint arXiv:1609.04836. Jisu Kim and Juhwan Lee. 2024. Strategic data or- dering: Enhancing large language model perfor- mance through curriculum learning.arXiv preprint arXiv:2405.07490. Yajing Kong, Liu Liu, Jun Wang, and Dacheng Tao
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 5067–5076
Adaptive curriculum learning. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 5067–5076. Hector Levesque, Ernest Davis, and Leora Morgenstern
-
[4]
DataComp-LM: In search of the next generation of training sets for language models
The winograd schema challenge. InProceed- ings of KR. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, and 1 others. 2022. Solving quan- titative reasoning problems with language models. Advances in neural information processing systems, 35:3843–3857....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jiasheng Ye, Peiju Liu, Tianxiang Sun, Yunhua Zhou, Jun Zhan, and Xipeng Qiu. 2024. Data mix- ing laws: Optimizing data mixtures by predicting language modeling performance.arXiv preprint arXiv:2403.16952. Dong Yin, Ashwin Pananjady, Max Lam, Dimitris Papailiopoulos, Kannan Ramchandran, and Peter Bar...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Existing methods broadly fall into three categories: deduplication, distribution alignment, and quality-based scoring
which demonstrate that data quality often outweighs quantity. Existing methods broadly fall into three categories: deduplication, distribution alignment, and quality-based scoring. SemDeDup (Abbas et al., 2023) and D4 (Tirumala et al., 2023) focus on removing semantic redundancy to enhance diversity. Beyond redundancy, DSIR (Xie et al.,
2023
-
[7]
selects subsets that mirror target distributions via importance weighting, while PDS (Gu et al.,
-
[8]
evaluates sample utility based on gradient consistency. More recently, fine-grained scoring systems have emerged to assess content quality; for instance, FineWeb-Edu (Penedo et al., 2023) employs classifiers to identify educational content, and QuRating (Wettig et al., 2024) evaluates text across multiple dimensions such as writing style and required expe...
2023
-
[9]
and MBPP (Austin et al., 2021). For general scenarios, we assess the trained models on a range of standard natural language understanding and reasoning benchmarks, includ- ing Hellaswag (HS; Zellers et al., 2019), Wino- grande (Wino; Levesque et al., 2012), LAM- BADA (LAMB; Paperno et al., 2016), Open- bookQA (OBQA; Mihaylov et al., 2018), ARC- easy/chall...
2021
-
[10]
5 to compute the predicted loss in Table 7
We use these constants and Eq. 5 to compute the predicted loss in Table 7. Goodness of Fit.We evaluate the goodness of fit of the scaling curves with respect to the training token size D and model size N respectively, by computing the correlation coefficient R2 = 1−P i(yi−ˆyi)2 P i(yi−y)2 , where yi is the ground truth value and ˆyi is the prediction. Reg...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.