Cross-Platform Chinese Offensive Comment Detection via Dual-Threshold Hard Example Mining
Pith reviewed 2026-06-29 00:50 UTC · model grok-4.3
The pith
Dual-threshold filtering of high- and low-confidence samples from unlabeled data allows low-cost adaptation of offensive comment detectors to new Chinese platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Filtering unlabeled samples whose prediction confidence falls at the high or low extremes produces a compact set of hard examples; labeling only those examples and performing secondary fine-tuning on them recovers performance lost to domain shift in Chinese offensive comment detection.
What carries the argument
Dual-threshold hard example mining, which selects samples by extreme prediction confidence values for targeted secondary fine-tuning.
If this is right
- The baseline RoBERTa model exhibits clear performance drops on Weibo, Xiaohongshu, Tieba, and Zhihu once domain distances are quantified.
- Secondary fine-tuning on the mined hard examples produces measurable gains across all four platforms.
- Only a small manually labeled subset is required instead of full platform-specific annotation.
- The approach operates without platform-specific validation sets beyond the initial test construction.
Where Pith is reading between the lines
- The same confidence-based selection could be tried on other text classification tasks that face platform or genre shift.
- Adjusting the two thresholds per unlabeled corpus might further reduce the number of labels needed.
- The method implicitly assumes that offensive language patterns missed by the source model are concentrated in the extreme-confidence tails.
Load-bearing premise
The samples chosen by the two confidence thresholds are the precise ones whose manual labels will correct domain-shift errors without introducing new biases.
What would settle it
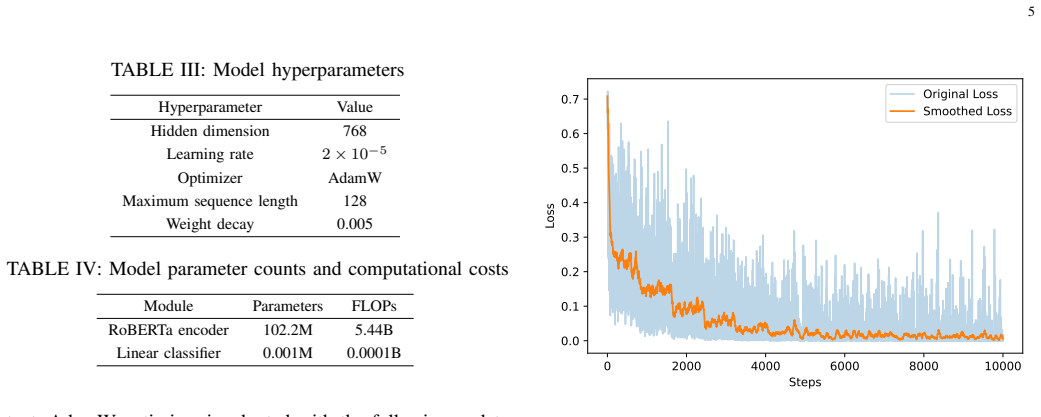
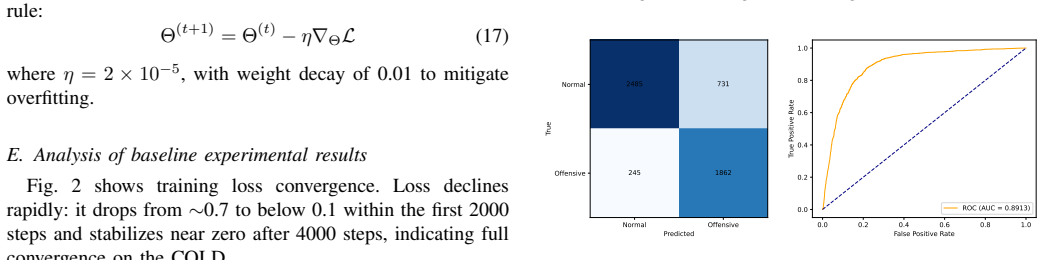
Run the secondary fine-tuning on the selected hard examples and measure whether F1 or accuracy on the four-platform test set fails to rise above the COLD-trained baseline.
Figures





read the original abstract
Cross-platform deployment of offensive comment detection for Chinese social media suffers performance degradation. The paper proposes a dual-threshold hard mining method to address this. First, the clean-Chinese-base RoBERTa is finetuned on COLD to establish a binary baseline for fair comparison. Second, a three-class fine-labeled test set covering Weibo, Xiaohongshu, Tieba, and Zhihu is constructed, domain distances from the source are quantified using Jaccard and Proxy-A Distance, as well as the degradation bottleneck of the baseline under domain shift is systematically revealed. Herein, a dual threshold hard example mining strategy is proposed. High- and low-confidence error-prone samples are filtered from unlabeled corpora by prediction confidence. The model is secondarily finetuned under implicit contexts with merely a small set of manually labeled hard examples, realizing low-cost cross-platform domain adaptation. Experiments reveal significant performance gains of the optimized model across four platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses performance degradation when deploying offensive comment detection models across Chinese social media platforms. It fine-tunes a RoBERTa baseline on the COLD dataset, constructs a three-class labeled test set spanning Weibo, Xiaohongshu, Tieba, and Zhihu, quantifies domain shift via Jaccard and Proxy-A distances, and reveals baseline degradation under shift. A dual-threshold hard-example mining procedure then filters high- and low-confidence error-prone samples from unlabeled target corpora; a small manually labeled subset of these hard examples is used for secondary fine-tuning under implicit contexts, yielding low-cost cross-platform adaptation. Experiments report significant performance gains on the four target platforms.
Significance. If the reported gains are reproducible and the dual-threshold procedure is shown to be robust, the work supplies a concrete, low-labeling-cost recipe for mitigating domain shift in Chinese offensive-language detection, which is a practically relevant problem given the rapid evolution of social-media platforms.
minor comments (2)
- [Abstract / §3] Abstract and §3: the phrase 'under implicit contexts' is used to describe the secondary fine-tuning step but is never defined; a brief gloss or pointer to the relevant subsection would improve clarity.
- [§4] The manuscript should state the exact numerical values chosen for the dual thresholds and the procedure used to select them (e.g., validation-set sweep or heuristic), as these choices are load-bearing for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the assessment of its practical relevance, and the recommendation for minor revision. The referee's description accurately reflects the paper's contributions on domain adaptation for Chinese offensive comment detection.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical pipeline: baseline fine-tuning on COLD, domain-distance measurement via Jaccard/Proxy-A, dual-threshold filtering of high/low-confidence samples from unlabeled data, manual labeling of a small hard-example subset, and secondary fine-tuning. No equations, derivations, or self-referential predictions appear in the provided text. Performance gains are reported as experimental outcomes on four platforms rather than reductions to fitted inputs or self-citations. The central claim remains independent of any load-bearing self-definition or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SCCD: A session-based dataset for Chinese cyberbullying detection,
Q. Yang, Y . Chen, Z. Xu, Y .-m. Shang, S. Guo, and X. Zhang, “SCCD: A session-based dataset for Chinese cyberbullying detection,” inProceedings of the 31st International Conference on Computational Linguistics, pp. 9533–9545, 2025
2025
-
[2]
Towards identifying social bias in dialog systems: Framework, dataset, and benchmark,
J. Zhou, J. Deng, F. Mi, Y . Li, Y . Wang, M. Huang, X. Jiang, Q. Liu, and H. Meng, “Towards identifying social bias in dialog systems: Framework, dataset, and benchmark,” inFindings of the Association for Computational Linguistics: EMNLP 2022, pp. 3576–3591, 2022
2022
-
[3]
Chinese offensive language detection:current status and future directions,
Y . Xiao, H. Bouamor, and W. Zaghouani, “Chinese offensive language detection:current status and future directions,”arXiv, 2024
2024
-
[4]
Categorizing offensive language in social networks: A Chinese corpus, systems and an explainable tool,
X. Tang and X. Shen, “Categorizing offensive language in social networks: A Chinese corpus, systems and an explainable tool,” in Proceedings of the 19th Chinese National Conference on Computational Linguistics, pp. 1045–1056, 2020
2020
-
[5]
Swsr: A chinese dataset and lexicon for online sexism detection,
A. Jiang, X. Yang, Y . Liu, and A. Zubiaga, “Swsr: A chinese dataset and lexicon for online sexism detection,”Online Social Networks and Media, vol. 27, p. 100182, 2022
2022
-
[6]
COLD: A benchmark for chinese offensive language detection,
J. Deng, J. Zhou, H. Sun, C. Zheng, F. Mi, H. Meng, and M. Huang, “COLD: A benchmark for chinese offensive language detection,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11580–11599, 2022
2022
-
[7]
NLP-based review for toxic comment detection tailored to the chinese cyberspace,
R. Ren, J. Zhao, X. Sun, and Q. Li, “NLP-based review for toxic comment detection tailored to the chinese cyberspace,”arXiv, 2026
2026
-
[8]
Rephrasing profanity in chinese text,
H.-P. Su, Z.-J. Huang, H.-T. Chang, and C.-J. Lin, “Rephrasing profanity in chinese text,” inProceedings of the First Workshop on Abusive Language Online, pp. 18–24, 2017
2017
-
[9]
Character-level Chinese toxic comment clas- sification algorithm based on CNN and Bi-GRU,
B. Zhang and Z. Wang, “Character-level Chinese toxic comment clas- sification algorithm based on CNN and Bi-GRU,” inProceedings of the 5th International Conference on Computer Science and Software Engineering, pp. 108–114, 2022
2022
-
[10]
Facilitating fine- grained detection of Chinese toxic language: Hierarchical taxonomy, resources, and benchmarks,
J. Lu, B. Xu, X. Zhang, C. Min, L. Yang, and H. Lin, “Facilitating fine- grained detection of Chinese toxic language: Hierarchical taxonomy, resources, and benchmarks,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16235–16250, 2023
2023
-
[11]
Offensive chinese text detection based on multi-feature fusion,
N. Li, S. Li, and J. Hong, “Offensive chinese text detection based on multi-feature fusion,” in2023 4th International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), pp. 460–465, IEEE, 2023
2023
-
[12]
Chinese offensive language detection algorithm based on pre-trained language model and pointer network augmentation,
B. Hou, X. Xie, D. Zhang, L. Zheng, and G. Yan, “Chinese offensive language detection algorithm based on pre-trained language model and pointer network augmentation,” in2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), pp. 800–805, IEEE, 2024
2024
-
[13]
A parallel dual-channel chinese offensive language detection method combining bert and ctm topic information,
T. Cao, H. Guo, S. Bai, B. Li, and N. Liu, “A parallel dual-channel chinese offensive language detection method combining bert and ctm topic information,”IEEE Access, vol. 12, pp. 95165–95184, 2024
2024
-
[14]
Chinese irony corpus construction and ironic structure analysis,
Y .-j. Tang and H.-H. Chen, “Chinese irony corpus construction and ironic structure analysis,” inProceedings of COLING 2014, The 25th international conference on computational linguistics: Technical papers, pp. 1269–1278, 2014
2014
-
[15]
Irony recognition via CNN integrated with linguistic features,
X. Lu and et al., “Irony recognition via CNN integrated with linguistic features,”Journal of Chinese Information Processing, vol. 33, no. 5, pp. 31–38, 2019
2019
-
[16]
A novel chinese sarcasm detection model based on retrospective reader,
L. Zhang, X. Zhao, X. Song, Y . Fang, D. Li, and H. Wang, “A novel chinese sarcasm detection model based on retrospective reader,” inInternational Conference on Multimedia Modeling, pp. 267–278, Springer, 2022
2022
-
[17]
The design and construction of a chinese sarcasm dataset,
X. Gong, Q. Zhao, J. Zhang, R. Mao, and R. Xu, “The design and construction of a chinese sarcasm dataset,” inProceedings of the twelfth language resources and evaluation conference, pp. 5034–5039, 2020
2020
-
[18]
Domain-enhanced prompt learning for chinese implicit hate speech detection,
Y . Zhang, T. Zhong, T. Yi, and H. Li, “Domain-enhanced prompt learning for chinese implicit hate speech detection,”IEEE Access, vol. 12, pp. 13773–13782, 2024
2024
-
[19]
A toxic euphemism detection framework for online social network based on semantic contrastive learning and dual channel knowledge augmentation,
G. Zhou, H. Wang, D. Jin, W. Wang, S. Jiang, R. Tang, and X. Chen, “A toxic euphemism detection framework for online social network based on semantic contrastive learning and dual channel knowledge augmentation,”Information Processing & Management, vol. 62, no. 4, p. 104143, 2025
2025
-
[20]
Enhancing offensive language detection with data augmentation and knowledge distillation,
J. Deng, Z. Chen, H. Sun, Z. Zhang, J. Wu, S. Nakagawa, F. Ren, and M. Huang, “Enhancing offensive language detection with data augmentation and knowledge distillation,”Research, vol. 6, p. 0189, 2023
2023
-
[21]
ToxiCloakCN: Evaluating robustness of offensive language detection in Chinese with cloaking perturbations,
Y . Xiao, Y . Hu, K. T. W. Choo, and R. K.-W. Lee, “ToxiCloakCN: Evaluating robustness of offensive language detection in Chinese with cloaking perturbations,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 6012–6025, 2024
2024
-
[22]
CangjieToxi: A Chinese offensive language detection benchmark with radical-level perturbations,
“CangjieToxi: A Chinese offensive language detection benchmark with radical-level perturbations,” inAnonymous ACL submission, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.