LLM-AutoSciLab: Closed-Loop Scientific Discovery via Active Experimentation with LLMs
Pith reviewed 2026-06-30 16:52 UTC · model grok-4.3
The pith
LLM-AutoSciLab closes the loop on scientific discovery by generating hypotheses then selecting experiments to test and refine them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
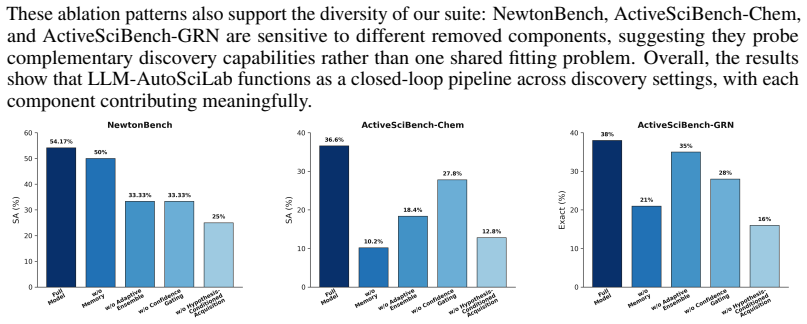
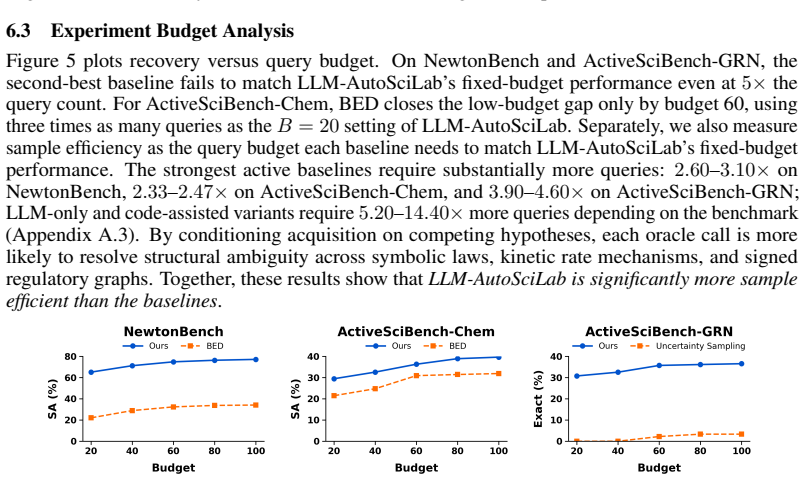
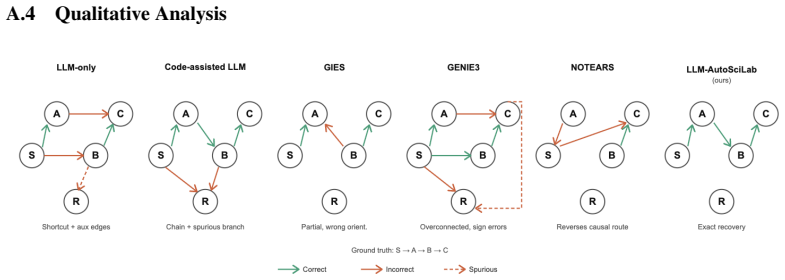
LLM-AutoSciLab iteratively proposes plausible hypotheses, selects informative experiments to distinguish or refine them, and updates its state using the resulting evidence. On NewtonBench it reaches 67.6 percent symbolic accuracy, on ActiveSciBench-Chem 35.1 percent symbolic accuracy, and on ActiveSciBench-GRN 31.1 percent exact graph recovery; hypothesis-guided experimentation is two to five times more sample-efficient than the strongest baselines.
What carries the argument
The closed-loop cycle that couples hypothesis generation with hypothesis-conditioned experiment selection and mechanism refinement driven by the language model.
If this is right
- Discovery problems can be solved with substantially fewer observations when experiment choice is conditioned on current hypotheses.
- The same iterative structure yields measurable gains on symbolic regression, enzyme-kinetics inference, and gene-network recovery.
- Performance scales with the ability of the model to propose and rank competing mechanisms rather than with passive data volume.
- Budget-constrained discovery shifts from static inference to active selection of the next measurement.
Where Pith is reading between the lines
- If the loop can be coupled to robotic lab hardware, the same efficiency gains could appear in physical experiments rather than simulations.
- The approach may generalize to other domains where each trial is costly, such as materials synthesis or clinical trial design.
- Success on the current benchmarks does not yet address how the method behaves when measurements contain substantial sensor noise or unmodeled variables.
- Replacing the language-model component with a different hypothesis proposer could isolate whether the gains come mainly from the closed-loop structure or from the specific model.
Load-bearing premise
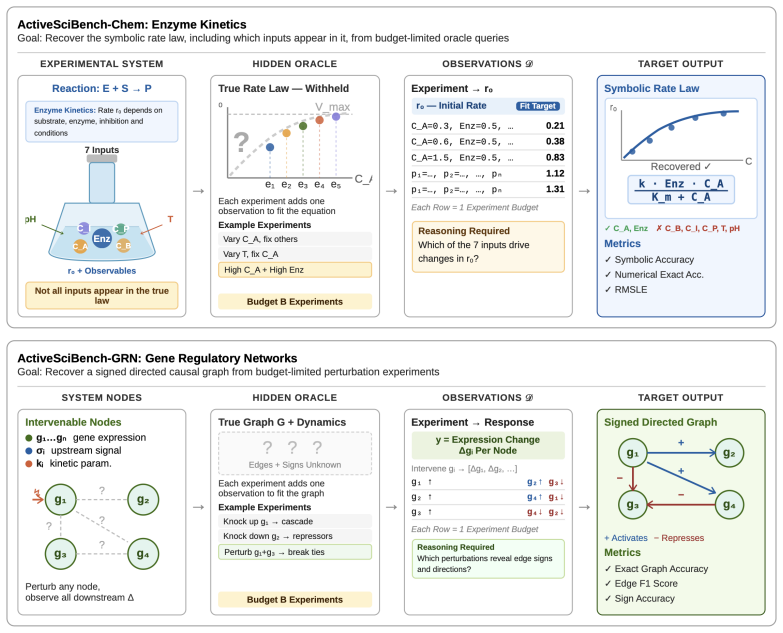
The synthetic tasks in ActiveSciBench-Chem and ActiveSciBench-GRN capture the core difficulties of real scientific discovery, including adaptive experiment design and mechanism recovery under budget constraints.
What would settle it
A direct comparison on the same benchmarks in which random or non-adaptive experiment selection recovers true mechanisms at rates statistically indistinguishable from LLM-AutoSciLab.
Figures




read the original abstract
Scientific discovery is a closed-loop process in which hypotheses guide data acquisition and observations refine the hypothesis space. Yet most approaches reduce discovery to supervised learning over fixed datasets, where limited observations can support multiple plausible mechanisms that fit locally but fail to generalize. Thus, the key challenge is selecting informative observations to resolve uncertainty, shifting the focus from static inference to adaptive data acquisition. To address this, we propose LLM-AutoSciLab, a closed-loop framework that couples hypothesis generation with hypothesis-conditioned experiment selection and mechanism refinement. Rather than fitting models to passively collected data, LLM-AutoSciLab iteratively proposes plausible hypotheses, selects informative experiments to distinguish or refine them, and updates its state using the resulting evidence. To evaluate dynamic, closed-loop scientific discovery with active data acquisition, we introduce ActiveSciBench, comprising two datasets: ActiveSciBench-Chem with 57 enzyme-kinetics tasks and ActiveSciBench-GRN with 45 gene-regulatory-network tasks. These datasets model discovery as a budget-constrained process requiring adaptive experiment design, variable selection, and recovery of true mechanisms. Across NewtonBench, ActiveSciBench-Chem, and ActiveSciBench-GRN, LLM-AutoSciLab outperforms prior methods, achieving 67.6% and 35.1% symbolic accuracy on NewtonBench and ActiveSciBench-Chem, respectively, and 31.1% exact graph recovery on ActiveSciBench-GRN. Moreover, hypothesis-guided experimentation is 2-5x more sample-efficient than the strongest competing baselines. Code and data are available at: https://github.com/scientific-discovery/LLM-AutoSciLab
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLM-AutoSciLab, a closed-loop framework coupling LLM-based hypothesis generation with hypothesis-conditioned experiment selection and mechanism refinement. It introduces ActiveSciBench comprising ActiveSciBench-Chem (57 enzyme-kinetics tasks) and ActiveSciBench-GRN (45 gene-regulatory-network tasks) to evaluate budget-constrained adaptive experiment design, variable selection, and mechanism recovery. On NewtonBench, ActiveSciBench-Chem, and ActiveSciBench-GRN the method reports 67.6% symbolic accuracy, 35.1% symbolic accuracy, and 31.1% exact graph recovery respectively, together with a 2-5x sample-efficiency gain over baselines. Code and data are released.
Significance. If the reported gains hold under the stated experimental protocol, the work demonstrates a concrete route from passive supervised learning on fixed datasets to active, hypothesis-guided data acquisition with LLMs. The public release of code and data is a clear strength that enables direct replication and extension.
major comments (1)
- [Abstract / ActiveSciBench section] Abstract and ActiveSciBench description: the central claim that LLM-AutoSciLab advances closed-loop scientific discovery rests on the assertion that the synthetic ActiveSciBench-Chem and ActiveSciBench-GRN tasks sufficiently model the core difficulties of real discovery (adaptive design, variable selection, mechanism recovery under budget constraints). No external validation against real experimental data with noise, incomplete observability, or higher complexity is supplied; if these synthetic constructions omit key frictions, the headline outperformance and efficiency numbers do not support the broader claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our benchmarks. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / ActiveSciBench section] Abstract and ActiveSciBench description: the central claim that LLM-AutoSciLab advances closed-loop scientific discovery rests on the assertion that the synthetic ActiveSciBench-Chem and ActiveSciBench-GRN tasks sufficiently model the core difficulties of real discovery (adaptive design, variable selection, mechanism recovery under budget constraints). No external validation against real experimental data with noise, incomplete observability, or higher complexity is supplied; if these synthetic constructions omit key frictions, the headline outperformance and efficiency numbers do not support the broader claim.
Authors: We agree that the lack of validation on real experimental data with noise and incomplete observability is a limitation that affects the strength of the broader claims. ActiveSciBench-Chem and ActiveSciBench-GRN are constructed from established mechanistic models (Michaelis-Menten kinetics and standard GRN ODEs) to isolate the effects of adaptive experiment selection and mechanism recovery under explicit budget constraints. These tasks do capture the stated core difficulties in a controlled setting. To address the concern, we will revise the manuscript to expand the limitations discussion, explicitly noting the gap to real-world conditions (e.g., measurement noise, unmodeled variables) and clarifying that the reported gains demonstrate the approach within these modeled environments rather than claiming immediate generalizability. We will also add a forward-looking statement on planned real-data extensions. revision: yes
Circularity Check
No circularity: empirical results on author-introduced synthetic benchmarks
full rationale
The paper presents LLM-AutoSciLab as a closed-loop framework and evaluates it via direct performance metrics (67.6% symbolic accuracy, 35.1%, 31.1% exact graph recovery, 2-5x sample efficiency) on NewtonBench plus the newly defined ActiveSciBench-Chem (57 tasks) and ActiveSciBench-GRN (45 tasks). These are explicit synthetic constructions for budget-constrained adaptive experiment design; the reported numbers are measured outcomes on those tasks, not quantities obtained by fitting parameters to a subset and then relabeling the fit as a prediction, nor by any self-referential definition or self-citation chain that reduces the headline claim to its own inputs. No equations appear in the provided text, and the evaluation is self-contained against the benchmarks the authors supply. This is the normal case of an empirical systems paper whose central claims rest on external measurement rather than internal algebraic identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate plausible scientific hypotheses and select informative experiments in the target domains
Forward citations
Cited by 1 Pith paper
-
LLM-ACES: Closed-Loop Discovery of Dynamical Systems with LLM-Guided Adaptive Search
LLM-ACES is a closed-loop method that combines LLM-proposed operator priors with disagreement-driven adaptive data acquisition to discover governing ODEs, reporting lowest median NMSE and 46-52% symbolic accuracy on 1...
Reference graph
Works this paper leans on
-
[1]
Nikhil Abhyankar, Sanchit Kabra, Saaketh Desai, and Chandan K. Reddy. LLEMA: Evolution- ary search with LLMs for multi-objective materials discovery. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[2]
The rise of self-driving labs in chemical and materials sciences.Nature Synthesis, 2:483 – 492, 2023
Milad Abolhasani and Eugenia Kumacheva. The rise of self-driving labs in chemical and materials sciences.Nature Synthesis, 2:483 – 492, 2023
2023
-
[3]
Autodiscovery: Open-ended scientific discovery via bayesian surprise
Dhruv Agarwal, Bodhisattwa Prasad Majumder, Reece Adamson, Megha Chakravorty, Satvika Reddy Gavireddy, Aditya Parashar, Harshit Surana, Bhavana Dalvi Mishra, Andrew McCallum, Ashish Sabharwal, and Peter Clark. Autodiscovery: Open-ended scientific discovery via bayesian surprise. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[4]
Microsoft Research AI4Science and Microsoft Azure Quantum. The impact of large lan- guage models on scientific discovery: a preliminary study using gpt-4.arXiv preprint arXiv:2311.07361, 2023
-
[5]
Deep batch active learning for drug discovery
Michael Bailey, Saeed Moayedpour, Ruijiang Li, Alejandro Corrochano-Navarro, Alexander Kötter, Lorenzo Kogler-Anele, Saleh Riahi, Christoph Grebner, Gerhard Hessler, Hans Matter, Marc Bianciotto, Pablo Mas, Ziv Bar-Joseph, and Sven Jager. Deep batch active learning for drug discovery. January 2024
2024
-
[6]
Pouya Behzadifar, Parshin Shojaee, Sanchit Kabra, Kazem Meidani, and Chandan K. Reddy. Decompose, adapt, and evolve: Towards efficient scientific equation discovery with large language models. InNeurIPS 2025 AI for Science Workshop, 2025
2025
-
[7]
Discrimination among mechanistic models.Technomet- rics, 9(1):57–71, 1967
George EP Box and WILLIAM J Hill. Discrimination among mechanistic models.Technomet- rics, 9(1):57–71, 1967
1967
-
[8]
Qiguang Chen, Mingda Yang, Libo Qin, Jinhao Liu, Zheng Yan, Jiannan Guan, Dengyun Peng, Yiyan Ji, Hanjing Li, Mengkang Hu, et al. Ai4research: A survey of artificial intelligence for scientific research.arXiv preprint arXiv:2507.01903, 2025
-
[9]
Tingting Chen, Beibei Lin, Zifeng Yuan, Qiran Zou, Hongyu He, Anirudh Goyal, Yew-Soon Ong, and Dianbo Liu. Hypospace: Evaluating llm creativity as set-valued hypothesis generators under underdetermination.arXiv preprint arXiv:2510.15614, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
A large-scale benchmark for network inference from single-cell perturbation data.Communica- tions Biology, 8(1):412, 2025
Mathieu Chevalley, Yusuf H Roohani, Arash Mehrjou, Jure Leskovec, and Patrick Schwab. A large-scale benchmark for network inference from single-cell perturbation data.Communica- tions Biology, 8(1):412, 2025
2025
-
[11]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
Miles Cranmer. Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
ODEFormer: Symbolic regression of dynamical systems with transformers
Stéphane d’Ascoli, Sören Becker, Philippe Schwaller, Alexander Mathis, and Niki Kilbertus. ODEFormer: Symbolic regression of dynamical systems with transformers. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[13]
Autoscilab: A self-driving laboratory for interpretable scientific discovery
Saaketh Desai, Sadhvikas Addamane, Jeffrey Y Tsao, Igal Brener, Laura P Swiler, Remi Dingreville, and Prasad P Iyer. Autoscilab: A self-driving laboratory for interpretable scientific discovery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 146–154, 2025
2025
-
[14]
Jingru Gan, Peichen Zhong, Yuanqi Du, Yanqiao Zhu, Chenru Duan, Haorui Wang, Daniel Schwalbe-Koda, Carla P Gomes, Kristin A Persson, and Wei Wang. Matllmsearch: Crystal struc- ture discovery with evolution-guided large language models.arXiv preprint arXiv:2502.20933, 2025
-
[15]
Symbolic regression with a learned concept library.Advances in Neural Information Processing Systems, 37:44678–44709, 2024
Arya Grayeli, Atharva Sehgal, Omar Costilla-Reyes, Miles Cranmer, and Swarat Chaudhuri. Symbolic regression with a learned concept library.Advances in Neural Information Processing Systems, 37:44678–44709, 2024. 10
2024
-
[16]
Olympus: a benchmarking framework for noisy optimization and experiment planning.Machine Learning: Science and Technology, 2(3):035021, 2021
Florian Häse, Matteo Aldeghi, Riley J Hickman, Loïc M Roch, Melodie Christensen, Elena Liles, Jason E Hein, and Alán Aspuru-Guzik. Olympus: a benchmarking framework for noisy optimization and experiment planning.Machine Learning: Science and Technology, 2(3):035021, 2021
2021
-
[17]
Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs.The Journal of Machine Learning Research, 13(1):2409–2464, 2012
Alain Hauser and Peter Bühlmann. Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs.The Journal of Machine Learning Research, 13(1):2409–2464, 2012
2012
-
[18]
Sequential optimal experimental design of perturbation screens guided by multi-modal priors.bioRxiv, 2023
Kexin Huang, Romain Lopez, Jan-Christian Hütter, Takamasa Kudo, Antonio Rios, and Aviv Regev. Sequential optimal experimental design of perturbation screens guided by multi-modal priors.bioRxiv, 2023
2023
-
[19]
Inferring regulatory networks from expression data using tree-based methods.PLoS ONE, 5, 2010
Vân Anh Huynh-Thu, Alexandre Irrthum, Louis Wehenkel, and Pierre Geurts. Inferring regulatory networks from expression data using tree-based methods.PLoS ONE, 5, 2010
2010
-
[20]
Generating Literature-Driven Scientific Theories at Scale
Peter Jansen, Peter Clark, Doug Downey, and Daniel S Weld. Generating literature-driven scientific theories at scale.arXiv preprint arXiv:2601.16282, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Active symbolic discovery of ordinary differential equations via phase portrait sketching
Nan Jiang, Md Nasim, and Yexiang Xue. Active symbolic discovery of ordinary differential equations via phase portrait sketching. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17626–17634, 2025
2025
-
[22]
Sanchit Kabra, Shobhnik Kriplani, Parshin Shojaee, and Chandan K. Reddy. SURFACEBENCH: A geometry-aware benchmark for symbolic surface discovery.Transactions on Machine Learning Research, 2026
2026
-
[23]
On-the- fly closed-loop materials discovery via bayesian active learning.Nature communications, 11(1):5966, 2020
A Gilad Kusne, Heshan Yu, Changming Wu, Huairuo Zhang, Jason Hattrick-Simpers, Brian DeCost, Suchismita Sarker, Corey Oses, Cormac Toher, Stefano Curtarolo, et al. On-the- fly closed-loop materials discovery via bayesian active learning.Nature communications, 11(1):5966, 2020
2020
-
[24]
Kyro, Anton Morgunov, Rafael I
Gregory W. Kyro, Anton Morgunov, Rafael I. Brent, and Victor S. Batista. Chemspaceal: An efficient active learning methodology applied to protein-specific molecular generation.Journal of Chemical Information and Modeling, 64(3):653–665, January 2024
2024
-
[25]
Integrated systems for computational scientific discovery.Proceedings of the AAAI Conference on Artificial Intelligence, 38(20):22598–22606, Mar
Pat Langley. Integrated systems for computational scientific discovery.Proceedings of the AAAI Conference on Artificial Intelligence, 38(20):22598–22606, Mar. 2024
2024
-
[26]
Julia Ling, Maxwell Hutchinson, Erin Antono, Sean Paradiso, and Bryce Meredig. High- dimensional materials and process optimization using data-driven experimental design with well-calibrated uncertainty estimates.Integrating Materials and Manufacturing Innovation, 6(3):207–217, 2017
2017
-
[27]
B. P. MacLeod, F. G. L. Parlane, T. D. Morrissey, F. Häse, L. M. Roch, K. E. Dettelbach, R. Moreira, L. P. E. Yunker, M. B. Rooney, J. R. Deeth, V . Lai, G. J. Ng, H. Situ, R. H. Zhang, M. S. Elliott, T. H. Haley, D. J. Dvorak, A. Aspuru-Guzik, J. E. Hein, and C. P. Berlinguette. Self-driving laboratory for accelerated discovery of thin-film materials.Sci...
2020
-
[28]
Data-driven discovery with large generative models.arXiv preprint arXiv:2402.13610, 2024
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Sanchaita Hazra, Ashish Sabharwal, and Peter Clark. Data-driven discovery with large generative models.arXiv preprint arXiv:2402.13610, 2024
-
[29]
Melnikov, Hendrik Poulsen Nautrup, Mario Krenn, Vedran Dunjko, Markus Tiersch, Anton Zeilinger, and Hans J
Alexey A. Melnikov, Hendrik Poulsen Nautrup, Mario Krenn, Vedran Dunjko, Markus Tiersch, Anton Zeilinger, and Hans J. Briegel. Active learning machine learns to create new quantum experiments.Proceedings of the National Academy of Sciences, 115(6):1221–1226, 2018
2018
-
[30]
Practical optimal experiment design with probabilistic programs
Long Ouyang, Michael Henry Tessler, Daniel Ly, and Noah Goodman. Practical optimal experiment design with probabilistic programs.arXiv preprint arXiv:1608.05046, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Mundhenk, Claudio Prata Santiago, Soo Kyung Kim, and Joanne Taery Kim
Brenden K Petersen, Mikel Landajuela Larma, Terrell N. Mundhenk, Claudio Prata Santiago, Soo Kyung Kim, and Joanne Taery Kim. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients. InInternational Conference on Learning Representations, 2021. 11
2021
-
[32]
Jalihal, Jeffrey N
Aditya Pratapa, Amogh P. Jalihal, Jeffrey N. Law, Aditya Bharadwaj, and T. M. Murali. Benchmarking algorithms for gene regulatory network inference from single-cell transcriptomic data.bioRxiv, 2019
2019
-
[33]
Active learning for efficient discovery of optimal gene combinations in the combinatorial perturbation space
Jason Qin, Hans-Hermann Wessels, Carlos Fernandez-Granda, and Yuhan Hao. Active learning for efficient discovery of optimal gene combinations in the combinatorial perturbation space. In NeurIPS 2024 Workshop on AI for New Drug Modalities, 2024
2024
-
[34]
Towards scientific discovery with generative ai: Progress, opportunities, and challenges
Chandan K Reddy and Parshin Shojaee. Towards scientific discovery with generative ai: Progress, opportunities, and challenges. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 28601–28609, 2025
2025
-
[35]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
2024
-
[36]
Genenetweaver: in silico bench- mark generation and performance profiling of network inference methods.Bioinformatics, 27(16):2263–2270, 08 2011
Thomas Schaffter, Daniel Marbach, and Dario Floreano. Genenetweaver: in silico bench- mark generation and performance profiling of network inference methods.Bioinformatics, 27(16):2263–2270, 08 2011
2011
-
[37]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K. Reddy. LLM-SR: Scientific equation discovery via programming with large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[38]
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K. Reddy. LLM-SRBench: A new benchmark for scientific equation discovery with large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[39]
Pdebench: An extensive benchmark for scientific machine learning.Advances in neural information processing systems, 35:1596–1611, 2022
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. Pdebench: An extensive benchmark for scientific machine learning.Advances in neural information processing systems, 35:1596–1611, 2022
2022
-
[40]
Ai feynman: A physics-inspired method for symbolic regression.Science advances, 6(16):eaay2631, 2020
Silviu-Marian Udrescu and Max Tegmark. Ai feynman: A physics-inspired method for symbolic regression.Science advances, 6(16):eaay2631, 2020
2020
-
[41]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
2023
-
[42]
Efficient evolutionary search over chemical space with large language models
Haorui Wang, Marta Skreta, Cher Tian Ser, Wenhao Gao, Lingkai Kong, Felix Strieth-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, Yuanqi Du, Alan Aspuru-Guzik, Kirill Neklyudov, and Chao Zhang. Efficient evolutionary search over chemical space with large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[43]
Newtonbench: Benchmarking generalizable scientific law discovery in LLM agents
Tianshi Zheng, Kelvin Kiu Wai Tam, Newt Nguyen Kim Hue Nam, Baixuan Xu, Zhaowei Wang, Cheng Jiayang, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, Yangqiu Song, Ginny Wong, and Simon See. Newtonbench: Benchmarking generalizable scientific law discovery in LLM agents. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[44]
Dags with no tears: Continuous optimization for structure learning.Advances in neural information processing systems, 31, 2018
Xun Zheng, Bryon Aragam, Pradeep K Ravikumar, and Eric P Xing. Dags with no tears: Continuous optimization for structure learning.Advances in neural information processing systems, 31, 2018
2018
-
[45]
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, and Chenhao Tan. Hypothesis generation with large language models. InProceedings of the 1st Workshop on NLP for Science (NLP4Science), pages 117–139, 2024. 12 Reproducibility Statement To ensure reproducibility, we provide the relevant implementation and experimental details throughout the paper...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.