AirGroundBench: Probing Spatial Intelligence in Multimodal Large Models under Heterogeneous Multi-View Embodied Collaboration
Pith reviewed 2026-06-29 04:31 UTC · model grok-4.3
The pith
MLLMs perform well on single-view perception but consistently fail at cross-view alignment and transformation reasoning in air-ground settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Evaluations reveal that current MLLMs handle spatial perception adequately but encounter consistent difficulties with cross-view alignment and transformation-intensive reasoning; these difficulties carry over into sequential vision-language navigation, and while dual-view inputs yield measurable gains they do not close the gap to human performance.
What carries the argument
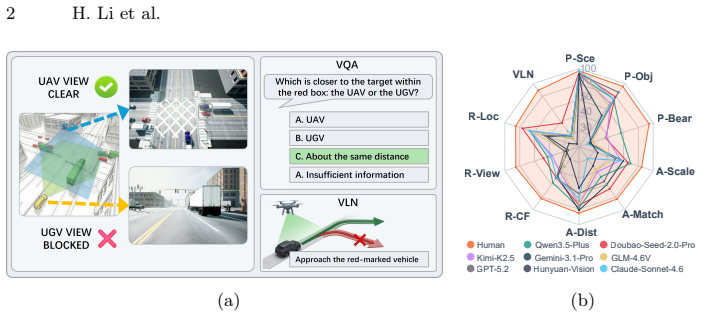
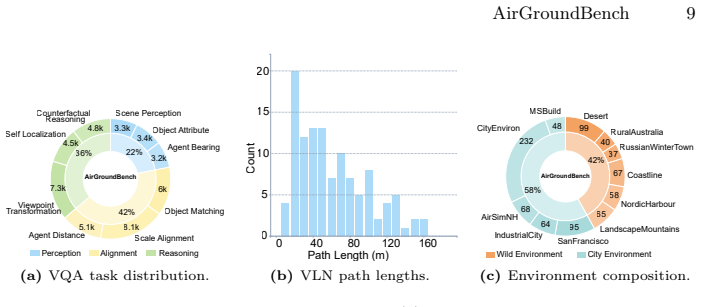
AirGroundBench, a benchmark built from 11 high-fidelity environments, 1,021 synchronized air-ground pairs, and approximately 62,000 four-option VQA instances plus 115 navigation episodes, annotated with cross-view object identities and metric 2D/3D boxes, and partitioned into ten task types across four capability dimensions.
If this is right
- Deficits in cross-view alignment directly degrade performance on embodied decision-making sequences.
- Dual-view inputs produce consistent but partial gains over single-view baselines.
- Geometric consistency across reference frames remains the dominant bottleneck for these models.
- Progress on alignment and transformation reasoning is required before reliable multi-agent navigation can be achieved.
Where Pith is reading between the lines
- The same alignment failures are likely to appear in any multi-scale sensor fusion setting, such as satellite-plus-street-level imagery.
- Adding explicit geometric modules or training objectives that penalize inconsistent cross-view predictions could be tested as a direct remedy.
- Extending the benchmark to include dynamic occlusion patterns or changing lighting would stress-test whether the identified bottlenecks are robust.
Load-bearing premise
The simulated environments and observation pairs faithfully reproduce the scale mismatch, asymmetric occlusion, and reference-frame problems that arise in actual heterogeneous air-ground collaboration.
What would settle it
Demonstration that any of the tested models reaches human-level accuracy on the same task suite when the inputs are replaced by real-world synchronized UAV-UGV video streams would falsify the claim of a persistent geometric-consistency limitation.
Figures

read the original abstract
In recent years, multimodal large language models (MLLMs) have shown strong potential for embodied intelligence, yet their ability to maintain geometrically consistent spatial understanding across heterogeneous views remains under-evaluated. Existing benchmarks largely focus on single-agent, single-view perception, leaving a gap in the systematic assessment of collaborative air-ground settings, where multi-scale observations are complementary but introduce scale mismatch, asymmetric occlusion, and reference-frame inconsistencies. We present AirGroundBench, a diagnostic benchmark for evaluating multi-view spatial intelligence in heterogeneous UAV-UGV collaboration. AirGroundBench is built from 11 high-fidelity simulated environments with 1,021 synchronized air-ground observation pairs, yielding approximately 62,000 dual-view, four-option single-choice visual question answering instances and 115 closed-loop vision-language navigation episodes. It covers 10 task types organized into four progressively demanding capability dimensions: spatial perception, cross-view alignment, spatial transformation and reasoning, and embodied decision-making. To support geometry-grounded evaluation and analysis, we provide structured spatial annotations, including cross-view object identities and metric 2D and 3D bounding boxes. Evaluations of 13 representative MLLMs under UAV-only, UGV-only, and dual-view input settings reveal consistent bottlenecks: models perform relatively well on spatial perception but struggle with cross-view alignment and transformation-intensive reasoning, and these deficits propagate to sequential decision-making in vision-language navigation. Although dual-view inputs provide measurable gains over single-view variants, a persistent gap from human performance remains, highlighting geometric consistency as a key limitation of current embodied MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AirGroundBench, a diagnostic benchmark for multi-view spatial intelligence in heterogeneous UAV-UGV collaboration. Constructed from 11 high-fidelity simulated environments yielding 1,021 synchronized observation pairs, it generates ~62,000 dual-view VQA instances and 115 closed-loop navigation episodes across 10 task types in four capability dimensions (spatial perception, cross-view alignment, spatial transformation/reasoning, embodied decision-making). Structured annotations include cross-view object identities and metric bounding boxes. Evaluations of 13 MLLMs under single- and dual-view settings show relative strength in perception but consistent weaknesses in alignment and transformation reasoning that propagate to navigation; dual-view inputs yield gains yet a persistent gap to human performance remains.
Significance. If the simulated tasks and annotations faithfully instantiate the geometric difficulties of scale mismatch, asymmetric occlusion, and reference-frame inconsistencies, the work would provide a valuable diagnostic tool for embodied MLLM research. The progressive task dimensions and geometry-grounded annotations are positive features that enable targeted analysis beyond aggregate accuracy.
major comments (2)
- [§3 and §5] §3 (Benchmark Construction) and §5 (Experiments): The headline claim that observed bottlenecks reflect fundamental limitations in cross-view alignment and transformation reasoning rests on the unverified assumption that the 11 simulated environments and 1,021 pairs reproduce real-world scale mismatch, asymmetric occlusion, and reference-frame inconsistencies. No quantitative comparison of simulated vs. real observation statistics (e.g., occlusion distributions, scale ratios, or camera calibration errors) is reported, and no physical-robot validation is included. This is load-bearing for interpreting the results as general rather than simulator-specific.
- [§4.2 and Table 2] §4.2 (Task Design) and Table 2: The four capability dimensions are presented as progressively demanding, yet the paper provides no ablation or correlation analysis showing that failure on transformation-intensive tasks causally drives the navigation deficits (as opposed to other factors such as instruction following or long-horizon planning). Without such evidence the propagation claim remains correlational.
minor comments (2)
- [Abstract and §5] The abstract and §1 state that dual-view inputs provide 'measurable gains' but do not report effect sizes or statistical significance for the improvement over single-view baselines in the main results tables.
- [Figure 3] Figure 3 (example observation pairs) would benefit from explicit scale bars or metric annotations to illustrate the claimed scale mismatch between air and ground views.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major comments below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3 and §5] §3 (Benchmark Construction) and §5 (Experiments): The headline claim that observed bottlenecks reflect fundamental limitations in cross-view alignment and transformation reasoning rests on the unverified assumption that the 11 simulated environments and 1,021 pairs reproduce real-world scale mismatch, asymmetric occlusion, and reference-frame inconsistencies. No quantitative comparison of simulated vs. real observation statistics (e.g., occlusion distributions, scale ratios, or camera calibration errors) is reported, and no physical-robot validation is included. This is load-bearing for interpreting the results as general rather than simulator-specific.
Authors: We agree that the benchmark is constructed in simulation and that we do not include direct quantitative comparisons to real-world data or physical robot experiments. Our environments are selected from high-fidelity simulators to capture the key geometric challenges mentioned, including variations in scale, occlusion, and viewpoints. However, we recognize that without explicit sim-to-real validation, the results should be interpreted within the context of simulated settings. In the revised version, we will expand the discussion in §3 and §5 to explicitly state the assumptions and limitations regarding generalization to real-world scenarios, and we will include qualitative examples comparing simulated observations to typical real UAV/UGV imagery where possible. revision: yes
-
Referee: [§4.2 and Table 2] §4.2 (Task Design) and Table 2: The four capability dimensions are presented as progressively demanding, yet the paper provides no ablation or correlation analysis showing that failure on transformation-intensive tasks causally drives the navigation deficits (as opposed to other factors such as instruction following or long-horizon planning). Without such evidence the propagation claim remains correlational.
Authors: The task dimensions are designed with logical progression in mind, where spatial transformation and reasoning build upon alignment and perception, and the navigation tasks require integrating these capabilities. The results in Table 2 show that models with lower performance on transformation tasks also exhibit larger gaps in navigation. While we did not perform explicit causal ablations, the per-dimension breakdowns support the propagation narrative. To address this, we will add a correlation analysis between dimension-specific accuracies and navigation success rates in the revised manuscript to provide more quantitative support for the claim. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper introduces AirGroundBench as a diagnostic benchmark consisting of simulated environments, observation pairs, VQA instances, and navigation episodes. It reports empirical performance of 13 MLLMs across task types and input settings. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on direct evaluation results rather than any chain that reduces to its own construction by definition. This is a standard empirical study; the absence of mathematical derivation chains makes circularity analysis inapplicable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI, M.: Kimi large language model.https://kimi.moonshot.cn(2024)
2024
-
[2]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
AI, Z.: Glm-4: Open multilingual multimodal large model. arXiv preprint arXiv:2406.12793 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., Reid, I., Gould, S., van den Hengel, A.: Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3674–3683 (2018).https://doi.org/10....
-
[4]
In: CVPR (2018)
Anderson, P., et al.: Vision-and-language navigation: Interpreting visually- grounded navigation instructions in real environments. In: CVPR (2018)
2018
-
[5]
Anthropic: Claude 3 model card.https://www.anthropic.com/news/claude-3- family(2024)
2024
-
[6]
In: ICCV (2015)
Antol, S., et al.: Vqa: Visual question answering. In: ICCV (2015)
2015
-
[7]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., et al.: Qwen-vl: A versatile vision-language model for understanding, lo- calization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Basappa, A., Goel, P., Karra, A., Karra, A., Gilmore, A., Zhu, K.: Amvicc: A novel benchmark for cross-modal failure mode profiling for vlms and igms (jan 2026),http://arxiv.org/abs/2601.17037v1, published: 2026-01- 20T00:06:58Z; Updated: 2026-01-20T00:06:58Z; Categories: cs.CV; cs.AI; PDF: https://arxiv.org/pdf/2601.17037v1.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
ByteDance: Doubao large model.https://www.volcengine.com/product/doubao (2024)
2024
-
[10]
Cai, H., Rao, Y., Huang, L., Zhong, Z., Dong, J., Tan, J., Lu, W., Zhong, R.: Airnav: A large-scale real-world uav vision-and-language navigation dataset with natural and diverse instructions (jan 2026),http://arxiv.org/abs/2601. 03707v1, published: 2026-01-07T08:46:09Z; Updated: 2026-01-07T08:46:09Z; Cat- egories: cs.CL; PDF: https://arxiv.org/pdf/2601.0...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
Chen, S., Guhur, P.L., Tapaswi, M., Schmid, C., Laptev, I.: Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). pp. 16516–16525 (2022).https://doi.org/10.1109/CVPR52688. 2022 . 01604,https : / / openaccess . thecvf . com ...
-
[12]
Dai, S., Ma, Z., Luo, Z., Yang, X., Huang, Y., Zhang, W., Chen, C., Guo, Z., Xu, W., Sun, Y., Sun, M.: Mm-uavbench: How well do multimodal large language mod- els see, think, and plan in low-altitude uav scenarios? (dec 2025),http://arxiv. org / abs / 2512 . 23219v1, published: 2025-12-29T05:49:54Z; Updated: 2025-12- 29T05:49:54Z; Categories: cs.CV; PDF: ...
-
[13]
Gao, C., Zhao, B., Zhang, W., Mao, J., Zhang, J., Zheng, Z., Man, F., Fang, J., Zhou, Z., Cui, J., Chen, X., Li, Y.: EmbodiedCity: A Benchmark Plat- form for Embodied Agent in Real-world City Environment (Oct 2024).https: //doi.org/10.48550/arXiv.2410.09604,http://arxiv.org/abs/2410.09604, arXiv:2410.09604 [cs] titleTranslation: TLDR: A benchmark platform...
-
[14]
Intelligence32(2), 175–191 (2004).https://doi.org/10
Hegarty, M., Waller, D.: A dissociation between mental rotation and perspective- taking spatial abilities. Intelligence32(2), 175–191 (2004).https://doi.org/10. 1016/j.intell.2003.12.001
2004
-
[15]
In: Advances in Neu- ral Information Processing Systems (NeurIPS) (2022),https://papers.neurips
Hu, Y., Fang, S., Lei, Z., Zhong, Y., Chen, S.: Where2comm: Communication- efficient collaborative perception via spatial confidence maps. In: Advances in Neu- ral Information Processing Systems (NeurIPS) (2022),https://papers.neurips. cc / paper _ files / paper / 2022 / file / 1f5c5cd01b864d53cc5fa0a3472e152e - Paper-Conference.pdf
2022
-
[16]
In: CVPR (2019)
Hudson, D., Manning, C.: Gqa: A new dataset for real-world visual reasoning. In: CVPR (2019)
2019
-
[17]
Jia, M., Qi, Z., Zhang, S., Zhang, W., Yu, X., He, J., Wang, H., Yi, L.: Om- niSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Lan- guage Models (Sep 2025).https://doi.org/10.48550/arXiv.2506.03135,http: //arxiv.org/abs/2506.03135,arXiv:2506.03135[cs]titleTranslation:TLDR:Om- niSpatial is introduced, a comprehensive and challenging b...
-
[18]
In: ECCV (2020)
Krantz, J., et al.: Beyond the nav-graph: Vision-and-language navigation in con- tinuous environments. In: ECCV (2020)
2020
-
[19]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
Ku, A., Anderson, P., Patel, R., Ie, E., Baldridge, J.: Room-across-room: Multi- lingual vision-and-language navigation with dense spatiotemporal grounding. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 4392–4412 (2020).https://doi.org/10.18653/v1/ 2020.emnlp-main.356,https://aclanthology.org/2020....
-
[20]
SpatialMosaic: A Multiview VLM Dataset for Partial Visibility
Lee, K., Lee, I., Kwak, M., Ryu, K., Hong, J., Park, J.: Spatialmosaic: A multi- view vlm dataset for partial visibility (dec 2025),http://arxiv.org/abs/2512. 23365v1, published: 2025-12-29T10:48:54Z; Updated: 2025-12-29T10:48:54Z; Cat- egories: cs.CV; PDF: https://arxiv.org/pdf/2512.23365v1.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Li, D., Li, H., Wang, Z., Yan, Y., Zhang, H., Chen, S., Hou, G., Jiang, S., Zhang, W., Shen, Y., Lu, W., Zhuang, Y.: ViewSpatial-Bench: Evaluating Multi- perspective Spatial Localization in Vision-Language Models (Sep 2025).https: //doi.org/10.48550/arXiv.2505.21500,http://arxiv.org/abs/2505.21500, arXiv:2505.21500 [cs] titleTranslation: - TLDR: This work...
-
[22]
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?arXiv:2503.23765, 2025
Li, Y., Zhang, Y., Lin, T., Liu, X., Cai, W., Liu, Z., Zhao, B.: STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding? (Jul 2025). https://doi.org/10.48550/arXiv.2503.23765,http://arxiv.org/abs/2503. 23765, arXiv:2503.23765 [cs] titleTranslation: Sti-benchMllms TLDR: STI-Bench is introduced, a benchmark designed to evaluate MLLMs’s ...
-
[23]
Liu, X., Liu, Y., Qiu, H., Qirong, Y., Lian, Z.: Indooruav: Bench- marking vision-language uav navigation in continuous indoor environments (dec 2025),http : / / arxiv . org / abs / 2512 . 19024v1, published: 2025-12- 22T04:42:35Z; Updated: 2025-12-22T04:42:35Z; Categories: cs.RO; cs.AI; PDF: https://arxiv.org/pdf/2512.19024v1.pdf AirGroundBench 17
-
[24]
Clarendon Press, Oxford University Press (1978)
O’Keefe, J., Nadel, L.: The Hippocampus as a Cognitive Map. Clarendon Press, Oxford University Press (1978)
1978
-
[25]
OpenAI: Gpt-4v(ision) system card.https://openai.com/research/gpt- 4v- system-card(2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qi, Y., Wu, Q., Anderson, P., Wang, X., Wang, W.Y., Shen, C., van den Hen- gel, A.: Reverie: Remote embodied visual referring expression in real indoor en- vironments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9989–9998 (2020).https://doi.org/10. 1109/CVPR42600.2020.01000,https://openaccess.thecvf.co...
-
[27]
Science 171(3972), 701–703 (1971).https://doi.org/10.1126/science.171.3972.701
Shepard, R.N., Metzler, J.: Mental rotation of three-dimensional objects. Science 171(3972), 701–703 (1971).https://doi.org/10.1126/science.171.3972.701
-
[28]
Sohn, T.S., Dillitzer, M., Corso, J.J., Sax, E.: Embodied4C: Measuring What Mat- ters for Embodied Vision-Language Navigation (Dec 2025).https://doi.org/10. 48550/arXiv.2512.18028,http://arxiv.org/abs/2512.18028, arXiv:2512.18028 [cs] titleTranslation: 4C- TLDR: Comprehensive evaluation across ten state-of-the- art VLMs and four embodied control baselines...
-
[29]
arXiv preprint arXiv:2312.14838 (2023)
Sun, Y., et al.: Ernie 4.0: Knowledge enhanced foundation model. arXiv preprint arXiv:2312.14838 (2023)
-
[30]
Gemini: A Family of Highly Capable Multimodal Models
Team, G.D.: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Team, Q.: Qwen2-vl: Enhancing vision-language models with multimodal reason- ing. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Tencent: Hunyuan large model.https://hunyuan.tencent.com(2024)
2024
-
[33]
Cognitive maps in rats and men.Psychological Review, 55(4):189–208, 1948
Tolman, E.C.: Cognitive maps in rats and men. Psychological Review55(4), 189– 208 (1948).https://doi.org/10.1037/h0061626
-
[34]
In: IEEE/CVF International Conference on Computer Vision
Wang, Z., Li, X., Yang, J., Liu, Y., Jiang, S.: Gridmm: Grid memory map for vision-and-language navigation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 5579–5588 (2023).https: //doi.org/10.1109/ICCV51070.2023.01432,https://openaccess.thecvf.com/ content/ICCV2023/papers/Wang_GridMM_Grid_Memory_Map_for_Vision- a...
-
[35]
Xu, H., Hu, Y., Zhu, Z., Gao, C., Wang, Z., Rao, J., Lu, W., Li, W., Yin, Q., Li, Y.: Citycube: Benchmarking cross-view spatial reasoning on vision-language models in urban environments (jan 2026),http://arxiv.org/abs/2601.14339v1, published: 2026-01-20T13:44:02Z; Updated: 2026-01-20T13:44:02Z; Categories: cs.CV; cs.AI; PDF: https://arxiv.org/pdf/2601.14339v1.pdf
-
[36]
Xu, R., Xiang, H., Tu, Z., Xia, X., Yang, M.H., Ma, J.: V2x-vit: Vehicle-to- everything cooperative perception with vision transformer. In: European Confer- enceonComputerVision(ECCV)(2022).https://doi.org/10.1007/978-3-031- 19842- 7_7,https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/ 136990106.pdf
-
[37]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Yang, S., Xu, R., Xie, Y., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Duan, H., Yue, X., Lin, D., Wang, T., Pang, J.: MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence (Sep 2025).https://doi.org/10.48550/arXiv.2505.23764, http://arxiv.org/abs/2505.23764,arXiv:2505.23764[cs]titleTranslation:Mmsi- bench TLDR: An automated error analysis pipeli...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.23764 2025
-
[38]
Zha, J., Fan, Y., Zhang, T., Chen, G., Chen, Y., Gao, C., Chen, X.: AirCop- Bench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning (Nov 2025).https://doi.org/10.48550/arXiv.2511.11025,http: //arxiv.org/abs/2511.11025, arXiv:2511.11025 [cs] titleTranslation: Aircop- bench TLDR: AirCopBench is introduced, the first comprehensive ...
- [39]
-
[40]
Zhou, G., Hong, Y., Wang, Z., Wang, X.E., Wu, Q.: Navgpt-2: Unleashing navi- gational reasoning capability for large vision-language models. In: European Con- ference on Computer Vision (ECCV) (2024).https://doi.org/10.1007/978- 3- 031- 72667- 5_15,https://www.ecva.net/papers/eccv_2024/papers_ECCV/ papers/01143.pdf
-
[41]
Zhou, Y., Quang, L., Nieto-Granda, C., Loianno, G.: CoPeD-Advancing Multi- Robot Collaborative Perception: A Comprehensive Dataset in Real-World Envi- ronments (May 2024).https://doi.org/10.48550/arXiv.2405.14731,http: //arxiv.org/abs/2405.14731, arXiv:2405.14731 [cs] titleTranslation:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.