C-ReD: A Comprehensive Chinese Benchmark for AI-Generated Text Detection Derived from Real-World Prompts
Pith reviewed 2026-05-21 00:05 UTC · model grok-4.3
The pith
C-ReD benchmark lets detectors spot AI-written Chinese text from real prompts and generalize to new models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
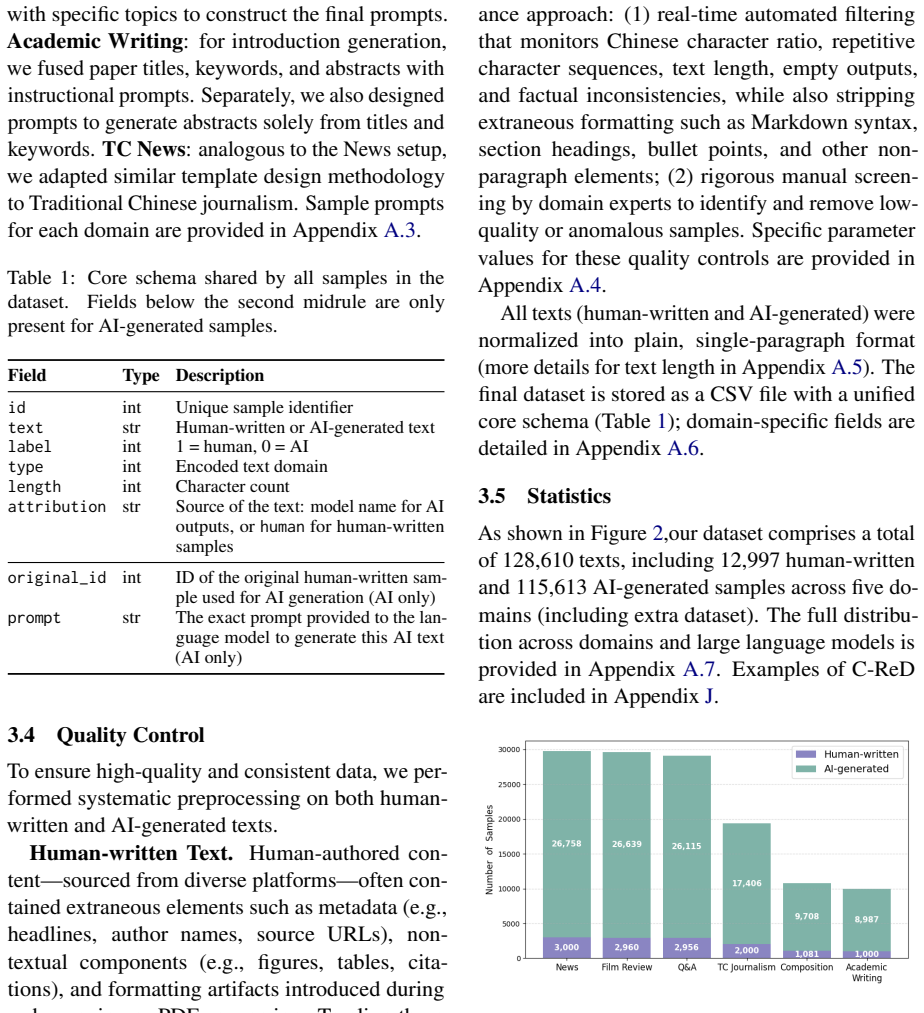
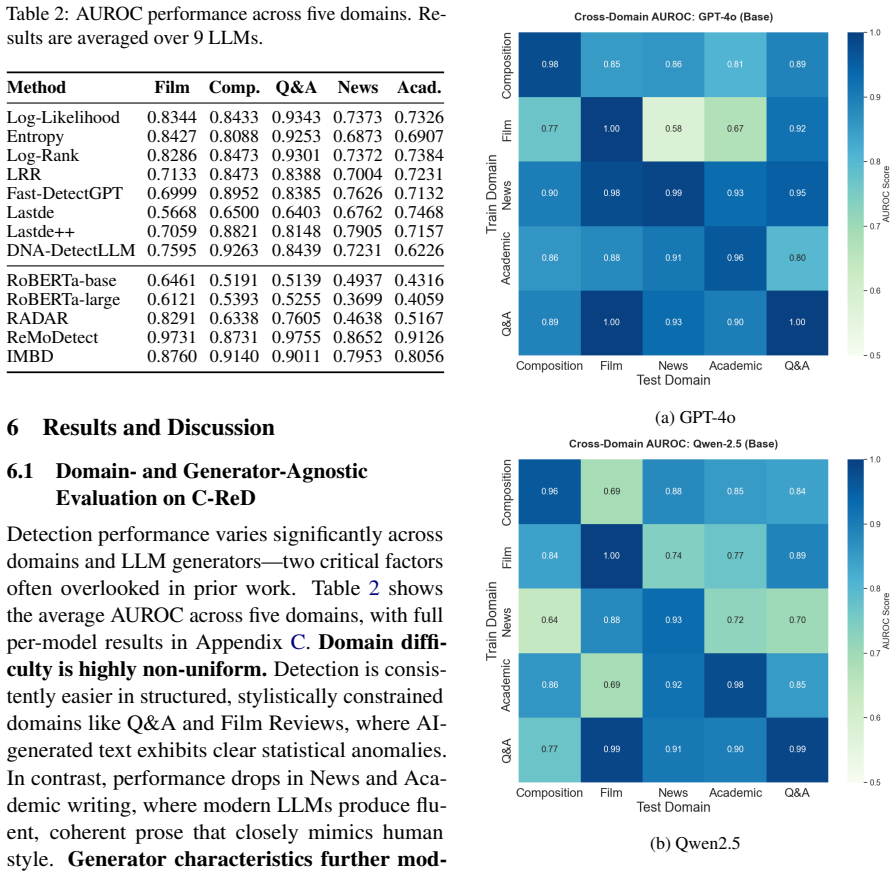
C-ReD is a comprehensive Chinese Real-prompt AI-generated Detection benchmark whose construction from diverse real-world prompts and multiple LLMs enables reliable in-domain detection while also supporting strong generalization to unseen LLMs and external Chinese datasets.
What carries the argument
C-ReD, the benchmark dataset built by pairing real-world Chinese prompts with outputs from a range of large language models.
If this is right
- Detectors trained on C-ReD maintain high performance inside the benchmark's own distribution.
- The same detectors transfer to text produced by LLMs that were never seen during training.
- Performance also improves on other existing Chinese detection collections.
- The benchmark directly tackles prior limits on model variety, topic range, and prompt naturalness.
Where Pith is reading between the lines
- Similar real-prompt collection methods could be applied to create detection benchmarks for additional languages.
- The approach suggests that prompt realism may be more critical than simply increasing the number of generator models.
- Future work could test whether the same construction yields detectors that remain effective as newer LLMs appear.
Load-bearing premise
The chosen real-world prompts and the particular LLMs used to generate the data are representative enough to solve the homogeneity and narrow model coverage that plagued earlier Chinese benchmarks.
What would settle it
Detection accuracy drops sharply when the same models are tested on a fresh Chinese LLM or on an external Chinese dataset not used in the original construction.
Figures

read the original abstract
Recently, large language models (LLMs) are capable of generating highly fluent textual content. While they offer significant convenience to humans, they also introduce various risks, like phishing and academic dishonesty. Numerous research efforts have been dedicated to developing algorithms for detecting AI-generated text and constructing relevant datasets. However, in the domain of Chinese corpora, challenges remain, including limited model diversity and data homogeneity. To address these issues, we propose C-ReD: a comprehensive Chinese Real-prompt AI-generated Detection benchmark. Experiments demonstrate that C-ReD not only enables reliable in-domain detection but also supports strong generalization to unseen LLMs and external Chinese datasets-addressing critical gaps in model diversity, domain coverage, and prompt realism that have limited prior Chinese detection benchmarks. We release our resources at https://github.com/HeraldofLight/C-ReD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes C-ReD, a new benchmark dataset for detecting AI-generated Chinese text constructed from real-world prompts across multiple LLMs. It claims to address limitations in prior Chinese benchmarks such as limited model diversity, data homogeneity, and unrealistic prompts. Experiments are reported to show reliable in-domain detection performance as well as strong generalization to unseen LLMs and external Chinese datasets.
Significance. If the generalization results are robust, C-ReD would constitute a useful public resource for Chinese AIGC detection research, improving upon existing benchmarks by emphasizing real prompts and broader model coverage. The decision to release the dataset and code supports reproducibility.
major comments (2)
- [§3.2] §3.2: The central generalization claim requires explicit evidence that the 'unseen' test LLMs lie outside the distribution family of the training models. If the unseen models are drawn primarily from the same providers or share overlapping pre-training corpora with the training set, the reported cross-model F1 scores would reflect intra-family transfer rather than true out-of-distribution robustness; a table or analysis quantifying architectural and data overlap is needed.
- [§3.1] §3.1: The prompt collection must be shown to overcome the homogeneity problem identified in prior work. Without quantitative measures of domain diversity, length distribution, or source variety (e.g., a breakdown by topic or a comparison to existing Chinese prompt corpora), the representativeness assumption underlying both in-domain and generalization results remains unverified.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong generalization' should be accompanied by the specific metrics (e.g., F1, AUC) and the exact number of unseen LLMs and external datasets used.
- Ensure a dedicated table listing all LLMs (training and test), their versions, parameter counts, and providers to facilitate direct comparison with future work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3.2] §3.2: The central generalization claim requires explicit evidence that the 'unseen' test LLMs lie outside the distribution family of the training models. If the unseen models are drawn primarily from the same providers or share overlapping pre-training corpora with the training set, the reported cross-model F1 scores would reflect intra-family transfer rather than true out-of-distribution robustness; a table or analysis quantifying architectural and data overlap is needed.
Authors: We thank the referee for this important clarification on what constitutes genuine out-of-distribution generalization. In our experiments, the unseen models were deliberately chosen from providers and model families distinct from those used in training (e.g., including certain open-source Chinese models not present in the training set). To make this explicit, we will add a table in the revised Section 3.2 listing all models with their providers, architectures, parameter counts, and any publicly known information on pre-training data. We will also include a short discussion of potential overlaps, while noting that complete pre-training corpus details remain proprietary and unavailable. This will allow readers to assess the degree of distribution shift more precisely. revision: partial
-
Referee: [§3.1] §3.1: The prompt collection must be shown to overcome the homogeneity problem identified in prior work. Without quantitative measures of domain diversity, length distribution, or source variety (e.g., a breakdown by topic or a comparison to existing Chinese prompt corpora), the representativeness assumption underlying both in-domain and generalization results remains unverified.
Authors: We agree that quantitative evidence of diversity would strengthen the manuscript. While the current text describes the real-world sourcing process intended to increase variety, we did not provide supporting statistics. In the revision we will expand Section 3.1 (and add an appendix if space is limited) with prompt length distributions, a topic breakdown based on the collection sources, and a direct comparison of diversity metrics against existing Chinese prompt corpora. These additions will verify the improved representativeness underlying our in-domain and generalization results. revision: yes
Circularity Check
No circularity: empirical benchmark construction from external prompts and models
full rationale
The paper describes construction of the C-ReD benchmark by sourcing real-world Chinese prompts (§3.1) and generating text with a diverse set of LLMs (§3.2), followed by empirical evaluation of detectors for in-domain performance and cross-model generalization. No equations, fitted parameters, or derivations are presented that reduce to self-definition or internal fits. Claims rest on external data collection and held-out testing rather than any load-bearing self-citation chain or ansatz smuggled via prior work. The methodology is self-contained against the benchmark itself and does not invoke uniqueness theorems or rename known results as new derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs are capable of generating fluent Chinese text that can be difficult to distinguish from human writing
Forward citations
Cited by 1 Pith paper
-
Alignment Imprint: Zero-Shot AI-Generated Text Detection via Provable Preference Discrepancy
LAPD, derived from the provable preference discrepancy in aligned LLMs, improves zero-shot AI text detection by 45.82% over baselines with claimed statistical dominance over Fast-DetectGPT.
Reference graph
Works this paper leans on
-
[1]
Chinesenlpcorpus. https://github.com/ In- saneLife/ChineseNLPCorpus. Sonnet Anthropic. 2024. Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 son- net.URL https://api. semanticscholar. org/CorpusID, 273639283. Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. 2024. Fast-detectgpt: Effi- cient zero-shot detection of machine...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Detecting fake content with relative entropy scoring.Pan, 8(27-31):4. Hyunseok Lee, Jihoon Tack, and Jinwoo Shin. 2024. Remodetect: Reward models recognize aligned llm’s generations.Advances in Neural Information Pro- cessing Systems, 37:2886–2913. Jooyoung Lee, Thai Le, Jinghui Chen, and Dongwon Lee. 2023. Do language models plagiarize? In Proceedings of...
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining ap- proach.arXiv preprint arXiv:1907.11692. Dominik Macko, Robert Moro, Adaku Uchendu, Ja- son Samuel Lu...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Turingbench: A benchmark environment for tur- ing test in the age of neural text generation
Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text. InThe 2023 Conference on Empirical Methods in Natural Language Processing. Ruixiang Tang, Yu-Neng Chuang, and Xia Hu. 2024. The science of detecting llm-generated text.Commu- nications of the ACM, 67(4):50–59. Yiu-Kei Tsang, Ming Yan, Jinger Pan, and Megan Yin Ka...
-
[5]
that introduces conditional probability curvature as its core metric and uses a faster sampling approach. • Lastde / Lastde++(Xu et al., 2025): A training-free detection method that treats the sequence of token probabilities generated by a language language model as a time series. By analyzing this sequence, Lastde and Lastde++ identify distinctive patter...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.