Evaluating the Relevance of Uncertainty Estimators for LLM Hallucination
Pith reviewed 2026-06-29 18:28 UTC · model grok-4.3
The pith
Uncertainty estimators associate only weakly and variably with LLM hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The association between uncertainty estimators and hallucinations in LLMs is highly variable and often weak, depending on the hallucination type and the LLM under evaluation.
What carries the argument
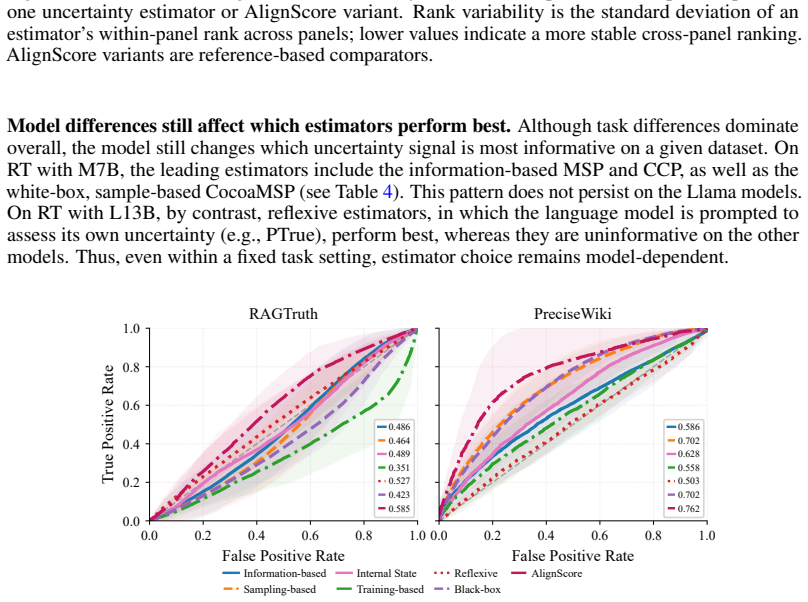
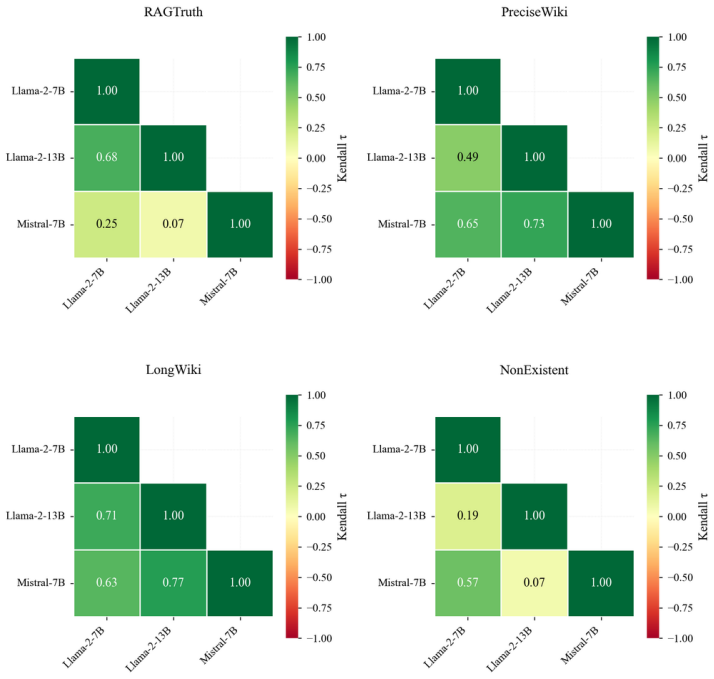
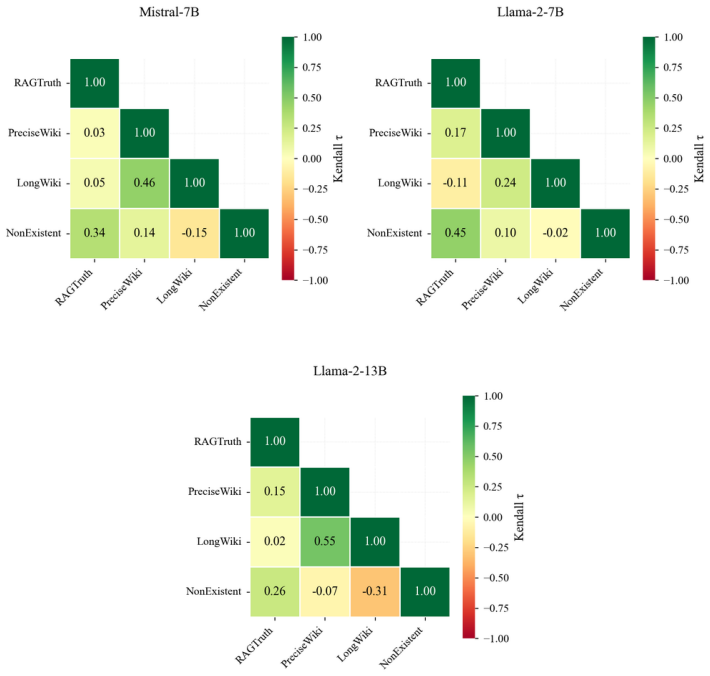
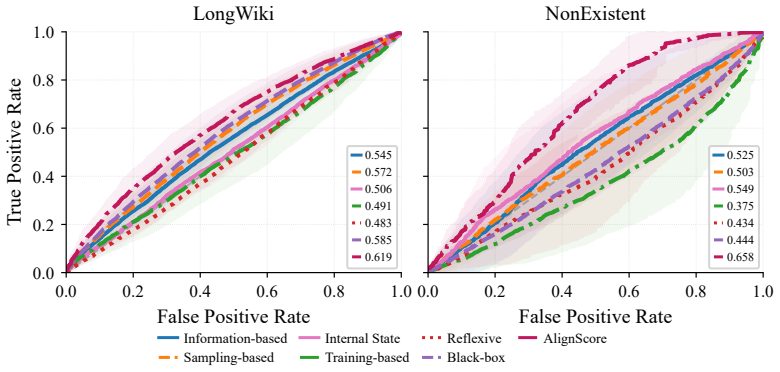
Systematic comparison of information-theoretic, sampling-based, and reflexive uncertainty estimators against hallucination annotations on RAGTruth, HalluLens, and two additional benchmarks for both intrinsic and extrinsic cases.
If this is right
- Uncertainty scores cannot be used as a reliable standalone signal that an output is hallucinated.
- Any practical hallucination mitigation strategy must incorporate information beyond uncertainty, such as type-specific checks.
- Performance of uncertainty methods should be reported separately for intrinsic versus extrinsic hallucinations rather than in aggregate.
- Model-specific tuning of uncertainty thresholds is required rather than assuming a universal relationship.
Where Pith is reading between the lines
- Deployment pipelines that currently gate outputs on uncertainty alone may need additional verification layers for different hallucination modes.
- Future work could test whether combining uncertainty with external retrieval or fact-checking steps restores a usable signal where uncertainty alone fails.
Load-bearing premise
The chosen benchmarks and the split between intrinsic and extrinsic hallucinations give a representative sample of actual hallucination behavior.
What would settle it
Finding a single uncertainty estimator that produces consistently high correlation with hallucination labels across all four benchmarks and multiple LLMs would falsify the claim of weak and variable association.
Figures



read the original abstract
Large language models (LLMs) are prone to hallucinations, i.e., statements unsupported by the input or training data, hindering reliable deployment. In parallel, numerous uncertainty estimation (UE) methods have been proposed to quantify model confidence and are often implicitly treated as proxies for model failure. However, the relationship between uncertainty and hallucinations remains insufficiently characterized. We present a systematic empirical study of the association between uncertainty estimators and hallucinations in LLMs. Rather than assuming this association, we evaluate directly when and to what extent it holds. We consider a diverse set of uncertainty estimators, including information-theoretic, sampling-based, and reflexive estimators, and examine their behavior across hallucination settings. Our experiments cover both intrinsic hallucinations (violations of input faithfulness) and extrinsic hallucinations (unsupported claims relative to training data), using four complementary benchmarks, including RAGTruth and HalluLens. We find that the association is highly variable and often weak, depending on the hallucination type and the LLM under evaluation. These results challenge the use of uncertainty as a direct signal of hallucination and clarify when it provides actionable information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical study of the relationship between uncertainty estimation (UE) methods—including information-theoretic, sampling-based, and reflexive estimators—and hallucinations in LLMs. It distinguishes intrinsic hallucinations (input faithfulness violations) from extrinsic ones (unsupported claims relative to training data), evaluates across four benchmarks (RAGTruth, HalluLens, and two others), and concludes that the association between UE and hallucinations is highly variable and often weak, depending on hallucination type and the specific LLM. This challenges the implicit treatment of UE as a direct proxy for hallucination detection.
Significance. If the empirical findings are robust, the work provides a valuable caution against over-reliance on uncertainty estimates for hallucination mitigation in LLM deployment. By directly testing the association rather than assuming it, and covering both intrinsic and extrinsic settings, the results clarify the limited actionable information provided by current UE methods and could steer research toward more targeted detection strategies.
major comments (2)
- [§4 (Benchmarks and Hallucination Definitions)] §4 (Benchmarks and Hallucination Definitions): The central claim that the UE-hallucination association is 'often weak' depends on the four chosen benchmarks and the intrinsic/extrinsic distinction constituting an unbiased probe. The manuscript provides no analysis of annotation protocols in RAGTruth or HalluLens (or the other two benchmarks) to show they do not systematically under-sample hallucinations that correlate with uncertainty or introduce labeling artifacts via the intrinsic/extrinsic split; without this, the variability finding risks being an artifact of the evaluation settings.
- [§5 (Results)] §5 (Results): The reported associations lack accompanying statistical significance tests, confidence intervals, or error bars on the correlation or AUC metrics across models and hallucination types. This makes it difficult to determine whether observed 'weak' associations are reliably distinguishable from noise or from stronger associations in other settings, undermining the strength of the 'highly variable and often weak' conclusion.
minor comments (2)
- The abstract and introduction would benefit from explicitly naming all four benchmarks and the exact LLMs evaluated, rather than referring to 'two others.'
- [§3] Notation for UE methods (e.g., how reflexive estimators are formalized) could be made more consistent between §3 and the experimental tables.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important aspects of our evaluation methodology and statistical reporting. We provide point-by-point responses below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§4 (Benchmarks and Hallucination Definitions)] §4 (Benchmarks and Hallucination Definitions): The central claim that the UE-hallucination association is 'often weak' depends on the four chosen benchmarks and the intrinsic/extrinsic distinction constituting an unbiased probe. The manuscript provides no analysis of annotation protocols in RAGTruth or HalluLens (or the other two benchmarks) to show they do not systematically under-sample hallucinations that correlate with uncertainty or introduce labeling artifacts via the intrinsic/extrinsic split; without this, the variability finding risks being an artifact of the evaluation settings.
Authors: We appreciate this concern regarding potential biases in the benchmarks. Our selection of RAGTruth, HalluLens, and the additional benchmarks was based on their established use in the literature for distinguishing intrinsic and extrinsic hallucinations, with labels provided by human annotators following documented protocols. While we did not conduct an independent audit of the annotation processes, the consistency of our findings across multiple independent benchmarks supports that the observed variability is not an artifact of a single evaluation setting. In the revision, we will add a subsection discussing the limitations of these benchmarks and the potential for annotation artifacts, including references to the original papers' annotation guidelines. revision: partial
-
Referee: [§5 (Results)] §5 (Results): The reported associations lack accompanying statistical significance tests, confidence intervals, or error bars on the correlation or AUC metrics across models and hallucination types. This makes it difficult to determine whether observed 'weak' associations are reliably distinguishable from noise or from stronger associations in other settings, undermining the strength of the 'highly variable and often weak' conclusion.
Authors: We agree that including statistical significance tests and confidence intervals would strengthen the presentation of our results. In the revised manuscript, we will recompute the correlations and AUC values with bootstrap confidence intervals and report p-values for the key comparisons to assess whether the weak associations are statistically distinguishable from stronger ones. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper performs direct empirical comparisons of uncertainty estimators against hallucination labels on four benchmarks (RAGTruth, HalluLens and two others), distinguishing intrinsic vs. extrinsic cases. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the derivation chain. The headline finding (variable and often weak association) is a statistical observation from the data, not a reduction to any fitted quantity or prior self-result. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abbasi-Yadkori, Y ., Kuzborskij, I., György, A., and Szepesvari, C. (2024). To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty. InNeurIPS
2024
-
[2]
L., Corney, D., DiResta, R., Ferrara, E., Hale, S., Halevy, A., Hovy, E., Ji, H., Menczer, F., Miguez, R., Nakov, P., Scheufele, D., Sharma, S., and Zagni, G
Augenstein, I., Baldwin, T., Cha, M., Chakraborty, T., Ciampaglia, G. L., Corney, D., DiResta, R., Ferrara, E., Hale, S., Halevy, A., Hovy, E., Ji, H., Menczer, F., Miguez, R., Nakov, P., Scheufele, D., Sharma, S., and Zagni, G. (2024). Factuality challenges in the era of large language models and opportunities for fact-checking.Nature Machine Intelligenc...
2024
-
[3]
F., Yaldiz, D
Bakman, Y . F., Yaldiz, D. N., Kang, S., Zhang, T., Buyukates, B., Avestimehr, S., and Karim- ireddy, S. P. (2025). Reconsidering LLM uncertainty estimation methods in the wild. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29531–29556
2025
-
[4]
Bang, Y ., Ji, Z., Schelten, A., Hartshorn, A., Fowler, T., Zhang, C., Cancedda, N., and Fung, P. (2025). HalluLens: LLM hallucination benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24128–24156
2025
-
[5]
Bengio, Y ., Mindermann, S., Privitera, D., Besiroglu, T., Bommasani, R., Casper, S., Choi, Y ., Fox, P., Garfinkel, B., Goldfarb, D., Heidari, H., Ho, A., Kapoor, S., Khalatbari, L., Longpre, S., Manning, S., Mavroudis, V ., Mazeika, M., Michael, J., Newman, J., Ng, K. Y ., Okolo, C. T., Raji, D., Sastry, G., Seger, E., Skeadas, T., South, T., Strubell, ...
-
[6]
S., Skarbrevik, D., Ra, H.-K., Bajaj, V ., and Ahmad, Z
Bouchard, D., Chauhan, M. S., Skarbrevik, D., Ra, H.-K., Bajaj, V ., and Ahmad, Z. (2026). UQLM: A Python Package for Uncertainty Quantification in Large Language Models.Journal of Machine Learning Research, 27(13):1–10
2026
-
[7]
Chen, C., Liu, K., Chen, Z., Gu, Y ., Wu, Y ., Tao, M., Fu, Z., and Ye, J. (2023). INSIDE: LLMs’ Internal States Retain the Power of Hallucination Detection. InInternational Conference on Learning Representations
2023
-
[8]
d., Suchanek, F
Chen, L., Melo, G. d., Suchanek, F. M., and Varoquaux, G. (2026). Query-Level Uncertainty in Large Language Models. InICLR
2026
-
[9]
Cover, T. M. and Thomas, J. A. (2001).Elements of information theory. Wiley-Interscience, Hoboken, NJ
2001
-
[10]
F., Hardt, M., and Mendler-Dünner, C
Cruz, A. F., Hardt, M., and Mendler-Dünner, C. (2024). Evaluating language models as risk scores. InProceedings of the 38th International Conference on Neural Information Processing Systems, volume 37, pages 97378–97407
2024
-
[11]
Darrin, M., Piantanida, P., and Colombo, P. (2023). Rainproof: An umbrella to shield text generator from out-of-distribution data. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 5831–5857. 10
2023
- [12]
-
[13]
Duan, J., Cheng, H., Wang, S., Zavalny, A., Wang, C., Xu, R., Kailkhura, B., and Xu, K. (2024). Shifting Attention to Relevance: Towards the Predictive Uncertainty Quantification of Free- Form Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5050–5063. Associati...
2024
-
[14]
Fadeeva, E., Rubashevskii, A., Shelmanov, A., Petrakov, S., Li, H., Mubarak, H., Tsymbalov, E., Kuzmin, G., Panchenko, A., Baldwin, T., Nakov, P., and Panov, M. (2024). Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification. InFindings of the Association for Computational Linguistics, pages 9367–9385
2024
-
[15]
Fadeeva, E., Vashurin, R., Tsvigun, A., Vazhentsev, A., Petrakov, S., Fedyanin, K., Vasilev, D., Goncharova, E., Panchenko, A., Panov, M., et al. (2023). Lm-polygraph: Uncertainty estimation for language models.Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations
2023
- [16]
-
[17]
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y . (2024). Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630
2024
-
[18]
Fomicheva, M., Sun, S., Yankovskaya, L., Blain, F., Guzmán, F., Fishel, M., Aletras, N., Chaudhary, V ., and Specia, L. (2020). Unsupervised quality estimation for neural machine translation.Transactions of the Association for Computational Linguistics, 8:539–555
2020
-
[19]
He, P., Liu, X., Gao, J., and Chen, W. (2021). DeBERTa: Decoding-enhanced BERT with disentangled attention. InInternational Conference on Learning Representations
2021
-
[20]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T. (2024a). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems
-
[21]
Huang, X., Li, S., Yu, M., Sesia, M., Hassani, H., Lee, I., Bastani, O., and Dobriban, E. (2024b). Uncertainty in Language Models: Assessment through Rank-Calibration. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 284–312
-
[22]
Ielanskyi, M., Schweighofer, K., Aichberger, L., and Hochreiter, S. (2025). Addressing Pitfalls in the Evaluation of Uncertainty Estimation Methods for Natural Language Generation. InICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI
2025
-
[23]
S., Madotto, A., and Fung, P
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y ., Ishii, E., Bang, Y ., Chen, D., Dai, W., Chan, H. S., Madotto, A., and Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12):1–38
2023
-
[24]
Joshi, M., Choi, E., Weld, D., and Zettlemoyer, L. (2017). TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601– 1611
2017
-
[25]
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield- Dodds, Z., DasSarma, N., Tran-Johnson, E., et al. (2022). Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Kang, S., Bakman, Y . F., Yaldiz, D. N., Buyukates, B., and Avestimehr, S. (2025). Uncertainty quantification for hallucination detection in large language models: Foundations, methodology, and future directions.arXiv 2510.12040. 11
-
[27]
Kuhn, L., Gal, Y ., and Farquhar, S. (2023). Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.International Conference on Learning Representations
2023
-
[28]
M., Uszkoreit, J., Le, Q., and Petrov, S
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.-W., Dai, A. M., Uszkoreit, J., Le, Q., and Petrov, S. (2019). Natural Questions: A Benchmark for Question Answering Research.Transactions of the Association for Computational L...
2019
-
[29]
Lee, K., Lee, K., Lee, H., and Shin, J. (2018). A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in neural information processing systems, 31
2018
-
[30]
Lin, C.-Y . (2004). ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81. Association for Computational Linguistics
2004
-
[31]
Lin, Z., Trivedi, S., and Sun, J. (2023). Generating with confidence: Uncertainty quantification for black-box large language models.Findings of ACL
2023
-
[32]
Lin, Z., Trivedi, S., and Sun, J. (2024a). Contextualized Sequence Likelihood: Enhanced Confidence Scores for Natural Language Generation. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 10351–10368
-
[33]
Lin, Z., Trivedi, S., and Sun, J. (2024b). Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models.Transactions on Machine Learning Research
-
[34]
and Gales, M
Malinin, A. and Gales, M. (2021). Uncertainty estimation in autoregressive structured prediction. International Conference on Learning Representations
2021
-
[35]
Moskvoretskii, V ., Marina, M., Salnikov, M., Ivanov, N., Pletenev, S., Galimzianova, D., Krayko, N., Konovalov, V ., Nikishina, I., and Panchenko, A. (2025). Adaptive Retrieval Without Self- Knowledge? Bringing Uncertainty Back Home. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6355–6384
2025
-
[36]
V ., Kossen, J., Gal, Y ., and Marttinen, P
Nikitin, A. V ., Kossen, J., Gal, Y ., and Marttinen, P. (2024). Kernel Language Entropy: Fine- grained Uncertainty Quantification for LLMs from Semantic Similarities. InAdvances in Neural Information Processing Systems
2024
-
[37]
Niu, C., Wu, Y ., Zhu, J., Xu, S., Shum, K., Zhong, R., Song, J., and Zhang, T. (2024). RAGTruth: A hallucination corpus for developing trustworthy retrieval-augmented language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10862–10878
2024
-
[38]
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318
2002
-
[39]
and Miikkulainen, R
Qiu, X. and Miikkulainen, R. (2024). Semantic Density: Uncertainty Quantification for Large Language Models through Confidence Measurement in Semantic Space. InAdvances in Neural Information Processing Systems
2024
-
[40]
G., Padhy, S., and Lakshminarayanan, B
Ren, J., Fort, S., Liu, J., Roy, A. G., Padhy, S., and Lakshminarayanan, B. (2021). A Simple Fix to Mahalanobis Distance for Improving Near-OOD Detection. arXiv:2106.09022 [cs]
-
[41]
Sahoo, P., Meharia, P., Ghosh, A., Saha, S., Jain, V ., and Chadha, A. (2024). A Comprehensive Survey of Hallucination in Large Language, Image, Video and Audio Foundation Models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 11709–11724
2024
-
[42]
Santilli, A., Golinski, A., Kirchhof, M., Danieli, F., Blaas, A., Xiong, M., Zappella, L., and Williamson, S. (2025). Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers...
2025
-
[43]
S., Saha, S., Kattakinda, P., and Feizi, S
Sriramanan, G., Bharti, S., Sadasivan, V . S., Saha, S., Kattakinda, P., and Feizi, S. (2024). LLM-Check: Investigating Detection of Hallucinations in Large Language Models. InNeurIPS
2024
-
[44]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C. (2023). Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 5433–5442
2023
- [45]
-
[46]
van der Poel, L., Cotterell, R., and Meister, C. (2022). Mutual Information Alleviates Hallucina- tions in Abstractive Summarization. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 5956–5965
2022
-
[47]
Vashurin, R., Fadeeva, E., Vazhentsev, A., Rvanova, L., Vasilev, D., Tsvigun, A., Petrakov, S., Xing, R., Sadallah, A., Grishchenkov, K., Panchenko, A., Baldwin, T., Nakov, P., Panov, M., and Shelmanov, A. (2025a). Benchmarking uncertainty quantification methods for large language models with LM-polygraph.Transactions of the Association for Computational ...
-
[48]
Vashurin, R., Goloburda, M., Ilina, A., Rubashevskii, A., Nakov, P., Shelmanov, A., and Panov, M. (2025b). CoCoA: A Minimum Bayes Risk Framework Bridging Confidence and Consistency for Uncertainty Quantification in LLMs. InNeurIPS
-
[49]
Vazhentsev, A., Kuzmin, G., Tsvigun, A., Panchenko, A., Panov, M., Burtsev, M., and Shel- manov, A. (2023). Hybrid Uncertainty Quantification for Selective Text Classification in Am- biguous Tasks. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11659–11681
2023
-
[50]
Vazhentsev, A., Rvanova, L., Kuzmin, G., Fadeeva, E., Lazichny, I., Panchenko, A., Panov, M., Baldwin, T., Sachan, M., Nakov, P., and Shelmanov, A. (2025). Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs.arXiv 2505.20045
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Wang, X., Zhang, Z., Chen, G., Li, Q., Luo, B., Han, Z., Wang, H., Li, Z., Gao, H., and Hu, M. (2025). UBench: Benchmarking Uncertainty in Large Language Models with Multiple Choice Questions. InFindings of the Association for Computational Linguistics, pages 8076–8107
2025
-
[52]
Measuring short-form factuality in large language models
Wei, J., Karina, N., Chung, H. W., Jiao, Y . J., Papay, S., Glaese, A., Schulman, J., and Fedus, W. (2024). Measuring short-form factuality in large language models. arXiv:2411.04368 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Williams, R. J. and Zipser, D. (1989). A Learning Algorithm for Continually Running Fully Recurrent Neural Networks.Neural Computation, 1(2):270–280
1989
- [54]
- [55]
-
[56]
Yao, Y ., Wu, H., Guo, Z., Biyan, Z., Gao, J., Luo, S., Hou, H., Fu, X., and Song, L. (2024). Learning From Correctness Without Prompting Makes LLM Efficient Reasoner. InCOLM
2024
-
[57]
Yoo, K., Kim, J., Jang, J., and Kwak, N. (2022). Detection of Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation. InFindings of the Association for Computational Linguistics, pages 3656–3672
2022
- [58]
-
[59]
Zhang, C., Liu, F., Basaldella, M., and Collier, N. (2024). LUQ: Long-text Uncertainty Quantification for LLMs. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N., editors,Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 5244–5262. 13
2024
-
[60]
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., Du, Y ., Yang, C., Chen, Y ., Chen, Z., Jiang, J., Ren, R., Li, Y ., Tang, X., Liu, Z., Liu, P., Nie, J.-Y ., and Wen, J.-R. (2025). A Survey of Large Language Models. arXiv:2303.18223 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
A., and Roy, S
Zhou, H., Wan, X., Proleev, L., Mincu, D., Chen, J., Heller, K. A., and Roy, S. (2023). Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering. InICLR. A Related works A.1 Evaluating uncertainty estimation methods Work on evaluating uncertainty estimation (UE) methods for LLMs has addressed three concerns: building infras...
2023
-
[62]
method A outperforms method B on benchmark X
implements a comprehensive estimator suite behind a single pipeline that computes greedy responses, token probabilities, sampled responses, and semantic relation matrices once and reuses them across estimators, controlling for implementation differences. Adjacent toolkits – UQLM [6], UNCERTAINTYZOO[ 54], and UBENCH[ 51] – provide complementary coverage or...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.