Information Dynamics of Language Communication
Pith reviewed 2026-06-30 06:07 UTC · model grok-4.3
The pith
Large language models enable quantification of directed semantic information flow between speakers in dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
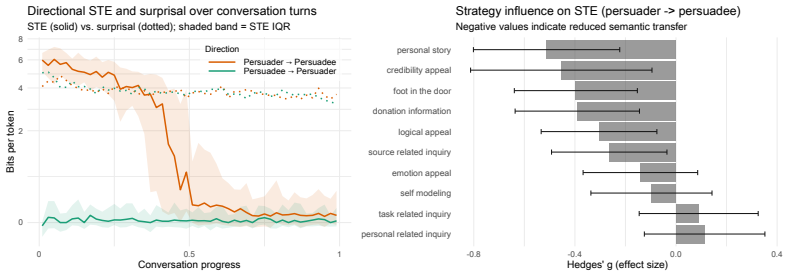
The authors claim that semantic transfer entropy and semantic partial information decomposition, estimated from large language model conditional probabilities, quantify directed semantic influence between interlocutors and decompose multi-source contributions into redundant, unique, and synergistic components, as shown across four experiments on cognitively rigid dialogue, persuasive discourse, psychotherapy sessions, and argumentative essays.
What carries the argument
Semantic transfer entropy (STE), which measures directed predictive influence between speakers, and semantic partial information decomposition (SPID), which resolves redundant, unique, and synergistic contributions from multiple sources, both using large language models as estimators of natural language probabilities.
If this is right
- Reduced information flow is detected in cognitively rigid dialogue.
- The dominant role of persuaders in shaping discourse is captured by the measures.
- High- from low-quality psychotherapy is distinguished by the directionality of information exchange.
- Synergistic premise contributions are revealed in argumentative essays.
Where Pith is reading between the lines
- The same measures could be applied to political debates or social media threads to track influence patterns at scale.
- Real-time versions might support feedback tools that encourage more balanced or synergistic exchanges in education or counseling.
- The framework could be extended to test whether information dynamics predict outcomes like persuasion success or therapeutic alliance strength.
Load-bearing premise
Large language models must supply sufficiently accurate conditional probability estimates of natural language semantics for the transfer entropy and partial information decomposition calculations to be meaningful.
What would settle it
Re-running the measures on a fresh corpus of psychotherapy transcripts independently rated for quality would falsify the central claim if directionality of therapist-client exchange shows no reliable difference between high- and low-quality sessions.
Figures


read the original abstract
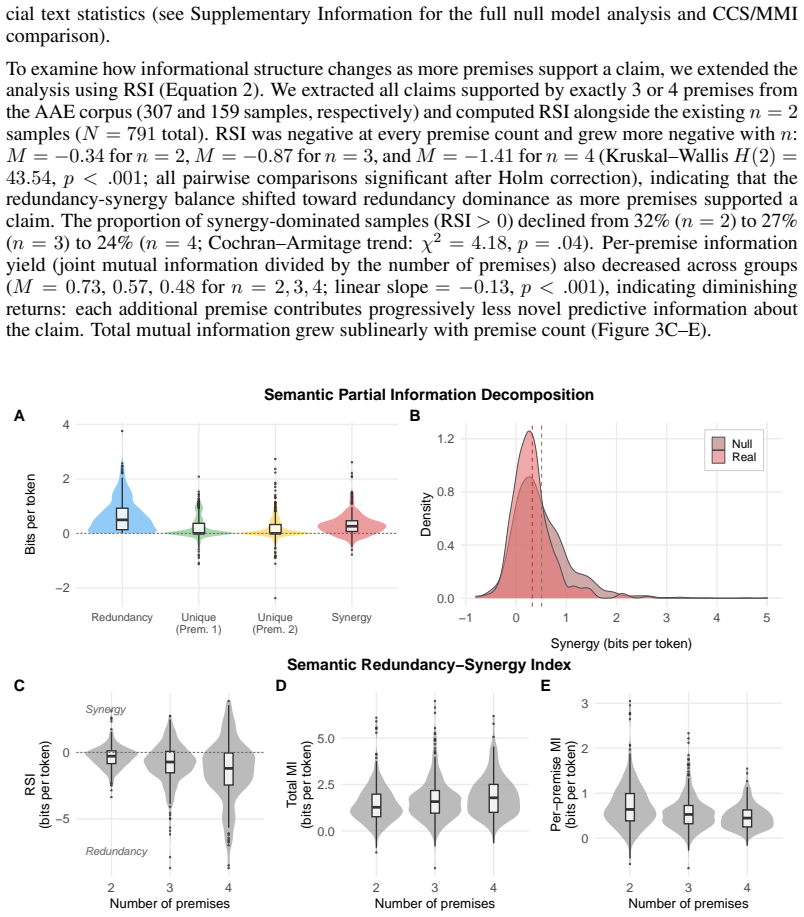
Quantifying how meaning propagates through communicative exchanges remains underdeveloped in computational linguistics. Here we introduce an information-theoretic framework that quantifies the directed flow of semantic content between interlocutors and decomposes multi-source contributions into redundant, unique, and synergistic components. Our approach leverages large language models as probabilistic estimators of natural language to compute two measures: semantic transfer entropy (STE), which captures directed predictive influence between speakers, and semantic partial information decomposition (SPID), which resolves how multiple sources jointly shape a target's language. Across four experiments we show that the framework detects reduced information flow in cognitively rigid dialogue, captures the dominant role of persuaders in shaping discourse, distinguishes high- from low-quality psychotherapy by the directionality of therapist-client information exchange, and reveals synergistic premise contributions in argumentative essays. This framework opens new avenues for studying information dynamics in digital discourse, pedagogical interactions, clinical dialogues, and any domain in which the structure of linguistic exchange is of research relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an information-theoretic framework that uses large language models as probabilistic estimators to compute semantic transfer entropy (STE) for directed predictive influence and semantic partial information decomposition (SPID) for resolving redundant, unique, and synergistic source contributions. It applies the framework in four experiments to detect reduced information flow in cognitively rigid dialogue, the dominant role of persuaders, directionality differences distinguishing high- versus low-quality psychotherapy, and synergistic premise contributions in argumentative essays.
Significance. If the LLM probability estimates can be shown to faithfully proxy semantic conditional distributions, the framework would provide a useful quantitative approach for analyzing directed semantic dynamics across communicative domains. The decomposition into redundant/unique/synergistic components via SPID is a conceptual strength that extends standard transfer entropy. The reported applications span clinically and educationally relevant settings, but the current lack of validation for the core proxy assumption limits the strength of the directional and synergy claims.
major comments (2)
- [Abstract] Abstract: the four directional and synergy findings all rest on the unvalidated assumption that LLM next-token probabilities p(w_{t+1}|context) serve as faithful proxies for semantic conditional distributions; without independent validation against human semantic judgments or held-out semantic tasks, the psychotherapy directionality and essay synergy results cannot be interpreted as semantic information flow.
- No section reports an ablation or correlation study comparing LLM-derived STE/SPID values against human-annotated semantic predictability or alternative estimators (e.g., n-gram or embedding-based baselines), which is load-bearing for all claims.
minor comments (2)
- The abstract and methods description omit the specific LLM(s), tokenization details, context window sizes, and exact corpora used in each of the four experiments, hindering reproducibility.
- Equations for STE and SPID should be stated explicitly with all conditioning variables defined, rather than left at the level of high-level description.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback emphasizing the need for validation of the LLM proxy. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the four directional and synergy findings all rest on the unvalidated assumption that LLM next-token probabilities p(w_{t+1}|context) serve as faithful proxies for semantic conditional distributions; without independent validation against human semantic judgments or held-out semantic tasks, the psychotherapy directionality and essay synergy results cannot be interpreted as semantic information flow.
Authors: The framework defines STE and SPID using LLM next-token probabilities explicitly as estimators of the conditional distributions over linguistic forms. We view this as a reasonable proxy given that LLMs are trained to model human language distributions at scale. The manuscript does not include independent human validation studies, as the contribution centers on formalizing the measures and demonstrating their application. We can add explicit language to the abstract and a limitations paragraph noting the modeling assumption if requested. revision: partial
-
Referee: No section reports an ablation or correlation study comparing LLM-derived STE/SPID values against human-annotated semantic predictability or alternative estimators (e.g., n-gram or embedding-based baselines), which is load-bearing for all claims.
Authors: No such ablation or correlation study appears in the manuscript. N-gram estimators are limited to short contexts and cannot capture the long-range semantic dependencies central to our definitions, while standard embedding approaches do not supply the probabilistic estimates required for the information-theoretic quantities. The LLM choice aligns with the semantic focus of the work; comparative baselines remain a direction for future research. revision: no
- Direct empirical validation of LLM next-token probabilities as proxies for semantic conditional distributions against human judgments or alternative estimators.
Circularity Check
No circularity in derivation chain
full rationale
The paper defines STE and SPID directly from LLM-derived conditional probabilities applied to new dialogue and essay corpora. No equations or sections reduce a claimed prediction to a fitted input by construction, no self-citation chain supports a uniqueness theorem or ansatz, and no renaming of known results occurs. The framework is presented as a novel application of existing information-theoretic tools to LLM probability estimates, with all empirical results arising from independent dataset analyses rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be treated as unbiased estimators of natural language conditional probabilities for semantic content.
Reference graph
Works this paper leans on
-
[1]
Luppi, Pedro A
Edoardo Chidichimo, Andrea I. Luppi, Pedro A. M. Mediano, Victoria Leong, Guillaume Du- mas, Andr´es Canales-Johnson, and Richard A. I. Bethlehem. Towards an informational account of interpersonal coordination.Nature Reviews Neuroscience, 27(2):121–137, February 2026
2026
-
[2]
Word association norms, mutual information, and lexicography
Kenneth Ward Church and Patrick Hanks. Word association norms, mutual information, and lexicography. InProceedings of the 27th annual meeting on Association for Computational Linguistics -, pages 76–83, Vancouver, British Columbia, Canada, 1989. Association for Com- putational Linguistics
1989
-
[3]
Dumais, George W
Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. Indexing by latent semantic analysis.Journal of the American Society for Infor- mation Science, 41(6):391–407, September 1990
1990
-
[4]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, August 2023. arXiv:1706.03762 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North, pages 4171–4186, Minneapolis, Minnesota, 2019. Association for Computational Linguistics
2019
-
[6]
Measuring information transfer.Physical Review Letters, 85(2):461–464, July 2000
Thomas Schreiber. Measuring information transfer.Physical Review Letters, 85(2):461–464, July 2000
2000
-
[7]
Williams and Randall D
Paul L. Williams and Randall D. Beer. Nonnegative decomposition of multivariate information
-
[8]
Xiaohan Ding, Michael Horning, and Eugenia H. Rho. Same Words, Different Meanings: Semantic Polarization in Broadcast Media Language Forecasts Polarity in Online Public Dis- course.Proceedings of the International AAAI Conference on Web and Social Media, 17:161– 172, June 2023
2023
-
[9]
Syntactic Structure from Deep Learning.Annual Review of Linguistics, 7(1):195–212, January 2021
Tal Linzen and Marco Baroni. Syntactic Structure from Deep Learning.Annual Review of Linguistics, 7(1):195–212, January 2021
2021
-
[10]
Semantic Structure in Deep Learning.Annual Review of Linguistics, 8(1):447– 471, January 2022
Ellie Pavlick. Semantic Structure in Deep Learning.Annual Review of Linguistics, 8(1):447– 471, January 2022
2022
-
[11]
Luppi, Fernando E
Andrea I. Luppi, Fernando E. Rosas, Pedro A.M. Mediano, David K. Menon, and Em- manuel A. Stamatakis. Information decomposition and the informational architecture of the brain.Trends in Cognitive Sciences, 28(4):352–368, April 2024
2024
-
[12]
Quantifying synergistic mutual information
Virgil Griffith and Christof Koch. Quantifying synergistic mutual information, March 2014. arXiv:1205.4265 [cs, math, q-bio]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Quantifying redundant information in predicting a target random variable.Entropy, 17(12):4644–4653, July 2015
Virgil Griffith and Tracey Ho. Quantifying redundant information in predicting a target random variable.Entropy, 17(12):4644–4653, July 2015
2015
-
[14]
Adam B. Barrett. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems.Physical Review E, 91(5):052802, May 2015
2015
-
[15]
Strong, Roland Koberle, William Bialek, and Rob R
Naama Brenner, Steven P. Strong, Roland Koberle, William Bialek, and Rob R. De Ruyter Van Steveninck. Synergy in a Neural Code.Neural Computation, 12(7):1531–1552, July 2000
2000
-
[16]
Elad Schneidman, William Bialek, and Michael J. Berry. Synergy, Redundancy, and Indepen- dence in Population Codes.The Journal of Neuroscience, 23(37):11539–11553, December 2003
2003
-
[17]
Aaron J. Gutknecht, Fernando E. Rosas, David A. Ehrlich, Abdullah Makkeh, Pedro A. M. Mediano, and Michael Wibral. Shannon invariants: A scalable approach to information de- composition, April 2025. arXiv:2504.15779 [cs.IT]. 24
-
[18]
Penguin Viking, London, 2025
Leor Zmigrod.The Ideological brain: a radical science of susceptible minds. Penguin Viking, London, 2025
2025
-
[19]
Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good, January 2020
Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good, January 2020. arXiv:1906.06725 [cs]
-
[20]
Stephen Rollnick and William R. Miller. What is Motivational Interviewing?Behavioural and Cognitive Psychotherapy, 23(4):325–334, October 1995
1995
-
[21]
Miller and Stephen Rollnick.Motivational interviewing: helping people change
William R. Miller and Stephen Rollnick.Motivational interviewing: helping people change. Applications of motivational interviewing. Guilford Press, New York, NY London, third edi- tion edition, 2013
2013
-
[22]
Moyers and Tim Martin
Theresa B. Moyers and Tim Martin. Therapist influence on client language during motivational interviewing sessions.Journal of Substance Abuse Treatment, 30(3):245–251, April 2006
2006
-
[23]
Apodaca, Kristina M
Timothy R. Apodaca, Kristina M. Jackson, Brian Borsari, Molly Magill, Richard Longabaugh, Nadine R. Mastroleo, and Nancy P. Barnett. Which Individual Therapist Behaviors Elicit Client Change Talk and Sustain Talk in Motivational Interviewing?Journal of Substance Abuse Treatment, 61:60–65, February 2016
2016
-
[24]
Moyers, Tim Martin, Jon M
Theresa B. Moyers, Tim Martin, Jon M. Houck, Paulette J. Christopher, and J. Scott Tonigan. From in-session behaviors to drinking outcomes: A causal chain for motivational interviewing. Journal of Consulting and Clinical Psychology, 77(6):1113–1124, December 2009
2009
-
[25]
Apodaca, Brian Borsari, Jacques Gaume, Ariel Hoadley, Rebecca E
Molly Magill, Timothy R. Apodaca, Brian Borsari, Jacques Gaume, Ariel Hoadley, Rebecca E. F. Gordon, J. Scott Tonigan, and Theresa Moyers. A meta-analysis of motivational inter- viewing process: Technical, relational, and conditional process models of change.Journal of Consulting and Clinical Psychology, 86(2):140–157, February 2018
2018
-
[26]
Miller, R
William R. Miller, R. Gayle Benefield, and J. Scott Tonigan. Enhancing motivation for change in problem drinking: A controlled comparison of two therapist styles.Journal of Consulting and Clinical Psychology, 61(3):455–461, 1993
1993
-
[27]
Anno-MI: A Dataset of Expert-Annotated Counselling Dialogues
Zixiu Wu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Ehud Reiter, Diego Reforgiato Recu- pero, and Daniele Riboni. Anno-MI: A Dataset of Expert-Annotated Counselling Dialogues. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 6177–6181, Singapore, Singapore, May 2022. IEEE
2022
-
[28]
Parsing Argumentation Structures in Persuasive Essays
Christian Stab and Iryna Gurevych. Parsing Argumentation Structures in Persuasive Essays, July 2016. arXiv:1604.07370 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
SimCSE: Simple Contrastive Learning of Sen- tence Embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple Contrastive Learning of Sen- tence Embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics
2021
-
[30]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3980–3990, Hong Kong, China, 2019. Association for Computational Linguistics
2019
-
[31]
Enrico Caprioglio, Pedro A. M. Mediano, and Luc Berthouze. Synergistic Motifs in Gaussian Systems.Physical Review Letters, 136(12):127401, March 2026
2026
-
[32]
High frequency word entrainment in spoken dia- logue.Proceedings of ACL-08, Proceedings of ACL-08: HLT, Short Papers:169–172, 2008
A Nenkova, A Gravano, and J Hirschberg. High frequency word entrainment in spoken dia- logue.Proceedings of ACL-08, Proceedings of ACL-08: HLT, Short Papers:169–172, 2008
2008
-
[33]
Cristian Danescu-Niculescu-Mizil and Lillian Lee. Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs, June 2011. arXiv:1106.3077 [cs]. 25
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[34]
Chang, Caleb Chiam, Liye Fu, Andrew Wang, Justine Zhang, and Cristian Danescu-Niculescu-Mizil
Jonathan P. Chang, Caleb Chiam, Liye Fu, Andrew Wang, Justine Zhang, and Cristian Danescu-Niculescu-Mizil. ConvoKit: A Toolkit for the Analysis of Conversations. InPro- ceedings of SIGDIAL, 2020
2020
-
[35]
Tausczik and James W
Yla R. Tausczik and James W. Pennebaker. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods.Journal of Language and Social Psychology, 29(1):24– 54, March 2010
2010
-
[36]
Landauer and Susan T
Thomas K. Landauer and Susan T. Dumais. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge.Psychological Review, 104(2):211–240, April 1997
1997
-
[37]
D. M. Blei, A. Y . Ng, and M. I. Jordan. Latent dirichlet allocation.J. Mach. Learn. Res., pages 993–1022, 2003
2003
-
[38]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space, September 2013. arXiv:1301.3781 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Sumers, Takateru Yamakoshi, Ariel Goldstein, Uri Hasson, Ken- neth A
Sreejan Kumar, Theodore R. Sumers, Takateru Yamakoshi, Ariel Goldstein, Uri Hasson, Ken- neth A. Norman, Thomas L. Griffiths, Robert D. Hawkins, and Samuel A. Nastase. Shared functional specialization in transformer-based language models and the human brain.Nature Communications, 15(1):5523, June 2024
2024
-
[40]
Ariel Goldstein, Zaid Zada, Eliav Buchnik, Mariano Schain, Amy Price, Bobbi Aubrey, Samuel A. Nastase, Amir Feder, Dotan Emanuel, Alon Cohen, Aren Jansen, Harshvardhan Gazula, Gina Choe, Aditi Rao, Catherine Kim, Colton Casto, Lora Fanda, Werner Doyle, Daniel Friedman, Patricia Dugan, Lucia Melloni, Roi Reichart, Sasha Devore, Adeen Flinker, Liat Hasenfra...
2022
-
[41]
De Lange
Micha Heilbron, Kristijan Armeni, Jan-Mathijs Schoffelen, Peter Hagoort, and Floris P. De Lange. A hierarchy of linguistic predictions during natural language comprehension.Pro- ceedings of the National Academy of Sciences, 119(32):e2201968119, August 2022
2022
-
[42]
Nastase, and Uri Hasson
Zaid Zada, Ariel Goldstein, Sebastian Michelmann, Erez Simony, Amy Price, Liat Hasenfratz, Emily Barham, Asieh Zadbood, Werner Doyle, Daniel Friedman, Patricia Dugan, Lucia Mel- loni, Sasha Devore, Adeen Flinker, Orrin Devinsky, Samuel A. Nastase, and Uri Hasson. A shared model-based linguistic space for transmitting our thoughts from brain to brain in na...
2024
-
[43]
Predicting Long-Term Citations from Short-Term Linguistic Influence
Sandeep Soni, David Bamman, and Jacob Eisenstein. Predicting Long-Term Citations from Short-Term Linguistic Influence. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 5700–5716, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics
2022
-
[44]
Nasir, Sandeep Nallan Chakravarthula, Brian R.W
Md. Nasir, Sandeep Nallan Chakravarthula, Brian R.W. Baucom, David C. Atkins, Panayio- tis Georgiou, and Shrikanth Narayanan. Modeling Interpersonal Linguistic Coordination in Conversations Using Word Mover’s Distance. InInterspeech 2019, pages 1423–1427. ISCA, September 2019
2019
-
[45]
Information-Theoretic Measures of Influence Based on Content Dynamics
Greg Ver Steeg and Aram Galstyan. Information-Theoretic Measures of Influence Based on Content Dynamics, February 2013. arXiv:1208.4475 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[46]
Network toxicity analysis: an information-theoretic approach to studying the social dynamics of online toxicity.Journal of Computational Social Science, 7(1):305–330, April 2024
Rupert Kiddle, Petter T ¨ornberg, and Damian Trilling. Network toxicity analysis: an information-theoretic approach to studying the social dynamics of online toxicity.Journal of Computational Social Science, 7(1):305–330, April 2024
2024
-
[47]
Conor Finn and Joseph T. Lizier. Quantifying Information Modification in Cellular Automata using Pointwise Partial Information Decomposition. InThe 2018 Conference on Artificial Life, pages 386–387, Tokyo, Japan, 2018. MIT Press. 26
2018
-
[48]
Mediano, Mart ´ın Ugarte, and Henrik J
Fernando Rosas, Pedro A.M. Mediano, Mart ´ın Ugarte, and Henrik J. Jensen. An Information- Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Cou- pled Dynamical Systems.Entropy, 20(10):793, October 2018
2018
-
[49]
Beer and Paul L
Randall D. Beer and Paul L. Williams. Information Processing and Dynamics in Minimally Cognitive Agents.Cognitive Science, 39(1):1–38, January 2015
2015
-
[50]
The partial information decomposition of generative neural network models.Entropy, 19(9):474, September 2017
Tycho Tax, Pedro Mediano, and Murray Shanahan. The partial information decomposition of generative neural network models.Entropy, 19(9):474, September 2017
2017
-
[51]
Schneider, David A
Abdullah Makkeh, Marcel Graetz, Andreas C. Schneider, David A. Ehrlich, Viola Priesemann, and Michael Wibral. A general framework for interpretable neural learning based on lo- cal information-theoretic goal functions.Proceedings of the National Academy of Sciences, 122(10):e2408125122, March 2025
2025
-
[52]
Varley and Patrick Kaminski
Thomas F. Varley and Patrick Kaminski. Untangling Synergistic Effects of Intersecting Social Identities with Partial Information Decomposition.Entropy, 24(10):1387, September 2022
2022
-
[53]
Inferring spatial and signaling relationships between cells from single cell transcriptomic data.Nature Communications, 11(1):2084, April 2020
Zixuan Cang and Qing Nie. Inferring spatial and signaling relationships between cells from single cell transcriptomic data.Nature Communications, 11(1):2084, April 2020
2084
-
[54]
Pedro A. M. Mediano, Fernando E. Rosas, Andrea I. Luppi, Robin L. Carhart-Harris, Daniel Bor, Anil K. Seth, and Adam B. Barrett. Toward a unified taxonomy of information dynamics via Integrated Information Decomposition.Proceedings of the National Academy of Sciences, 122(39):e2423297122, September 2025
2025
-
[55]
Pedro Urbina-Rodriguez, Zafeirios Fountas, Fernando E. Rosas, Jun Wang, Andrea I. Luppi, Haitham Bou-Ammar, Murray Shanahan, and Pedro A. M. Mediano. A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning, January 2026. arXiv:2601.06851 [cs]
-
[56]
Eden, Loren M
Uri T. Eden, Loren M. Frank, and Long Tao. Characterizing complex, multi-scale neural phenomena using state-space models. In Zhe Chen and Sridevi V . Sarma, editors,Dynamic Neuroscience, pages 29–52. Springer International Publishing, Cham, 2018
2018
-
[57]
Hongbin Na, Yining Hua, Zimu Wang, Tao Shen, Beibei Yu, Lilin Wang, Wei Wang, John Torous, and Ling Chen. A Survey of Large Language Models in Psychotherapy: Current Landscape and Future Directions, June 2025. arXiv:2502.11095 [cs]
-
[58]
Collective deliberation driven by AI.Nature Computational Science, 4(11):802–802, November 2024
Fernando Chirigati. Collective deliberation driven by AI.Nature Computational Science, 4(11):802–802, November 2024
2024
-
[59]
Entropy-Lens: Uncovering Decision Strategies in LLMs, February 2026
Riccardo Ali, Francesco Caso, Christopher Irwin, and Pietro Li `o. Entropy-Lens: Uncovering Decision Strategies in LLMs, February 2026. arXiv:2502.16570 [cs.LG]
-
[60]
Mechanistic Interpretability for AI Safety – A Review,
Leonard Bereska and Efstratios Gavves. Mechanistic Interpretability for AI Safety – A Review,
-
[61]
How to use and interpret activation patching, April
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, April
-
[62]
arXiv:2404.15255 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Dretske.Knowledge & the flow of information
Fred I. Dretske.Knowledge & the flow of information. A Bradford book. MIT Pr, Cambridge, Mass, 4. print edition, 1986
1986
-
[64]
On Calibration of Modern Neural Networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On Calibration of Modern Neural Networks, August 2017. arXiv:1706.04599 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[65]
Byung-Doh Oh and William Schuler. Why Does Surprisal From Larger Transformer-Based Language Models Provide a Poorer Fit to Human Reading Times?Transactions of the Associ- ation for Computational Linguistics, 11:336–350, March 2023
2023
-
[66]
right reasons
Tong Liu, Iza ˇSkrjanec, and Vera Demberg. Temperature-scaling surprisal estimates improve fit to human reading times – but does it do so for the “right reasons”? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9598–9619, Bangkok, Thailand, 2024. Association for Computational Linguistics. 27
2024
-
[67]
On the Entropy Calibration of Language Mod- els, January 2026
Steven Cao, Gregory Valiant, and Percy Liang. On the Entropy Calibration of Language Mod- els, January 2026. arXiv:2511.11966 [cs]
-
[68]
Ali Shojaie and Emily B. Fox. Granger Causality: A Review and Recent Advances.Annual Review of Statistics and Its Application, 9(1):289–319, March 2022
2022
-
[69]
GPT-5 nano, August 2025
OpenAI. GPT-5 nano, August 2025
2025
-
[70]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Rosas, Robin L
Alberto Liardi, Fernando E. Rosas, Robin L. Carhart-Harris, George Blackburne, Daniel Bor, and Pedro A. M. Mediano. Null models for comparing information decomposition across complex systems.PLOS Computational Biology, 21(11):e1013629, November 2025
2025
-
[72]
Measuring multivariate redundant information with pointwise common change in surprisal.Entropy, 19(7):318, June 2017
Robin Ince. Measuring multivariate redundant information with pointwise common change in surprisal.Entropy, 19(7):318, June 2017
2017
-
[73]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, S ´ebastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ee Lacroix, and William El Sayed. Mistral 7B, October 2023. arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.