Less Context, More Accuracy: A Bi-Temporal Memory Engine for LLM Agents Where a Lean Retrieved Context Beats the Full History
Pith reviewed 2026-06-27 21:48 UTC · model grok-4.3
The pith
A bi-temporal memory engine lets LLM agents answer more accurately from a compact retrieved slice than from the full conversation history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Engram's dual-process engine appends lossless episodes in a fast path and asynchronously builds a bi-temporal knowledge graph of subject-predicate-object facts with contradiction resolution via invalidation. Its hybrid read path fuses dense, lexical, graph, and recency signals under a point-in-time filter to produce a compact, provenance-tagged context that outperforms full-history prompting on accuracy while using far fewer tokens.
What carries the argument
The bi-temporal knowledge graph combined with a hybrid read path that fuses dense, lexical, graph, and recency signals to assemble a point-in-time context.
If this is right
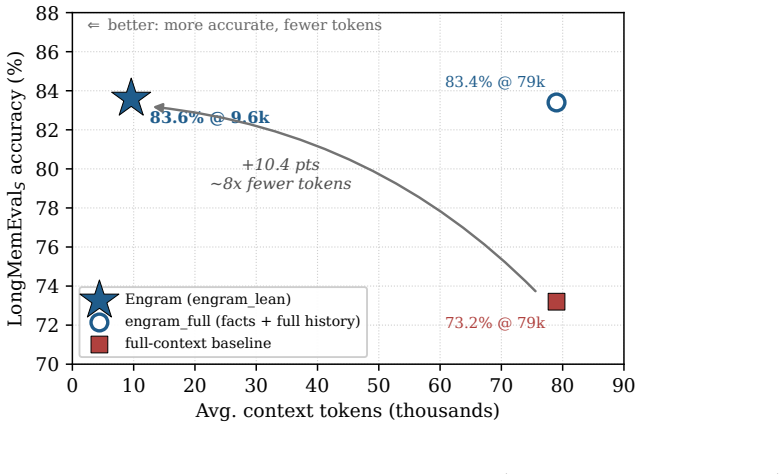
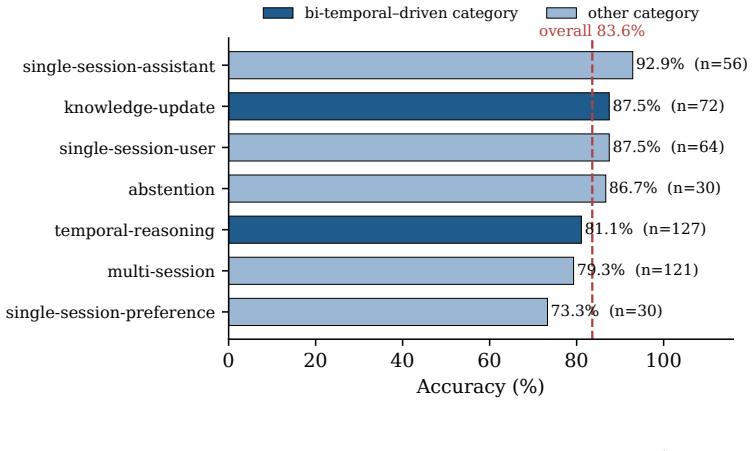
- Accuracy on LongMemEval_S rises from 73.2% with full context to 83.6% with the lean retrieved slice.
- Token consumption drops from 79k to 9.6k per query while maintaining or improving performance.
- The hybrid fusion of signals is required, as atomic facts alone reduce recall.
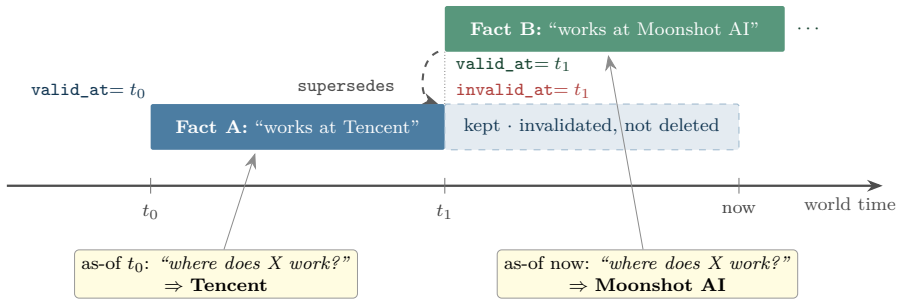
- Every fact retains provenance and a supersession chain through invalidation rather than deletion.
- Reproducible evaluation is enabled by the contributed in-repo harness with official judge.
Where Pith is reading between the lines
- Agent systems could default to retrieved contexts rather than full histories in production deployments.
- Similar bi-temporal models might apply to other domains requiring temporal consistency like legal or medical records.
- Further gains could come from tuning the signal weights in the hybrid read path on domain-specific data.
Load-bearing premise
The combination of atomic fact extraction and hybrid retrieval signals produces a context that remains sufficiently complete despite being much smaller than the full history.
What would settle it
A replication on LongMemEval_S or another long-context agent benchmark where the lean configuration scores no higher than the full-history baseline.
Figures

read the original abstract
Long-term memory is the missing layer for LLM agents: across sessions they forget, and the common workaround -- replaying the whole history into the prompt -- is expensive, slow, and, as distractors accumulate, less accurate. Most memory systems win on cost or latency but still lose to the full-context baseline on accuracy, and benchmark numbers are reported on inconsistent, non-reproducible harnesses, so one system appears at wildly different scores across sources. We present Engram, an open-source, dual-process memory engine on a bi-temporal data model. A fast write path appends lossless episodes with no LLM on the critical path; an asynchronous path extracts atomic (subject, predicate, object) facts, builds a bi-temporal knowledge graph, and resolves contradictions without an LLM call per fact -- invalidating, never deleting, so every fact keeps provenance and a supersession chain. A hybrid read path fuses dense, lexical, graph, and recency/salience signals, applies a point-in-time ("as-of") filter, and assembles a compact, provenance-tagged context. On the full 500-question LongMemEval_S, graded by the official category-specific judge, Engram's lean configuration -- answering from a ~9.6k-token retrieved slice, never the full history -- scores 83.6% vs. 73.2% for full-context (+10.4 points, McNemar p < 10^-6) at ~8x fewer tokens (9.6k vs. 79k), with 0/500 errored. The gain needs a hybrid read path: facts alone lose recall, while facts plus retrieved chunks recover detail. We also contribute a neutral, in-repo evaluation harness with the official judge baked in and the full-context baseline in every table, publish the raw per-question logs, and document the measurement-integrity pitfalls (truncation, home-grown judges, full-history leaks) that silently distort memory benchmarks. Every number ships with a command to reproduce it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Engram, an open-source dual-process memory engine on a bi-temporal data model for LLM agents. A fast write path appends lossless episodes; an asynchronous path extracts atomic facts, builds a bi-temporal KG with supersession chains for contradiction resolution without per-fact LLM calls, and a hybrid read path fuses dense/lexical/graph/recency signals with point-in-time filtering to produce a compact ~9.6k-token context. On the full 500-question LongMemEval_S benchmark using the official judge, the lean configuration scores 83.6% vs. 73.2% for full-context (+10.4 points, McNemar p < 10^-6) at ~8x fewer tokens, with 0/500 errors; the paper also contributes a neutral in-repo harness with raw logs and documents measurement pitfalls.
Significance. If the central empirical result holds, the work is significant because it provides concrete evidence that a carefully constructed lean context can outperform full history on accuracy (not just cost/latency), directly challenging the replay-whole-history workaround. The bi-temporal model with invalidation chains and provenance is a substantive modeling contribution. The reproducible harness, official-judge integration, and public raw logs address a documented weakness in the memory-systems literature and enable direct comparison.
minor comments (2)
- [Abstract] Abstract: the statement that 'the gain needs a hybrid read path: facts alone lose recall, while facts plus retrieved chunks recover detail' is central to interpreting the +10.4 point result, yet no quantitative ablation numbers or section reference are supplied in the abstract itself; add a parenthetical cross-reference to the relevant table or subsection.
- [Evaluation section (inferred from abstract)] The manuscript repeatedly cites the ~9.6k vs. 79k token comparison and the 500-question set; ensure every table that reports accuracy also explicitly lists the token budget and error count for the same configuration to avoid any ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive summary of our work on Engram, the assessment of its significance, and the recommendation for minor revision. No major comments were enumerated in the report.
Circularity Check
No significant circularity; empirical result stands on external benchmark
full rationale
The paper advances an empirical claim that a hybrid-retrieved ~9.6k-token slice outperforms the 79k-token full history on the external LongMemEval_S benchmark (83.6% vs 73.2%, official judge, McNemar p < 10^-6). No equations, parameter-fitting steps, or derivation chain appear in the provided text; the hybrid read path (dense + lexical + graph + recency) is described as an implemented design whose completeness is asserted via the observed accuracy gain rather than defined circularly or justified solely by self-citation. The contributed harness and full-context baseline are independent of the result itself. No load-bearing step reduces to a self-referential input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Atomic (subject, predicate, object) facts can be extracted from episodes with sufficient accuracy to support the hybrid read path
invented entities (1)
-
bi-temporal knowledge graph with supersession chains
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-Gallery: Benchmarking multimodal long-term conversational memory for MLLM agents.arXiv preprint arXiv:2601.03515, 2026
arXiv 2026
-
[2]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[3]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd 10 International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759, 2009
2009
-
[4]
Pengfei Du. Memory for autonomous LLM agents: Mechanisms, evaluation, and emerging frontiers.arXiv preprint arXiv:2603.07670, 2026
arXiv 2026
-
[5]
Teachers College, Columbia University, 1913
Hermann Ebbinghaus.Memory: A Contribution to Experimental Psychology. Teachers College, Columbia University, 1913. Original work published 1885
1913
-
[6]
HippoRAG: Neurobiologically inspired long-term memory for large language models
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically inspired long-term memory for large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[7]
From RAG to memory: Non-parametric continual learning for large language models
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From RAG to memory: Non-parametric continual learning for large language models. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[8]
Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[9]
Memory OS of AI agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[10]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
2020
-
[11]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[12]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics (TACL), 12:157–173, 2024
2024
-
[13]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[14]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[15]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[16]
Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025. 11
Pith/arXiv arXiv 2025
-
[17]
The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
2009
-
[18]
LongMemEval: Benchmarking chat assistants on long-term interactive memory.International Conference on Learning Representations (ICLR), 2025
DiWu, HongweiWang, WenhaoYu, YuweiZhang, Kai-WeiChang, andDongYu. LongMemEval: Benchmarking chat assistants on long-term interactive memory.International Conference on Learning Representations (ICLR), 2025
2025
-
[19]
Zhaofen Wu, Hanrong Zhang, Fulin Lin, Wujiang Xu, Xinran Xu, Yankai Chen, Henry Peng Zou, Shaowen Chen, Weizhi Zhang, Xue Liu, Philip S. Yu, and Hongwei Wang. GAM: Hierarchical graph-based agentic memory for LLM agents.arXiv preprint arXiv:2604.12285, 2026
Pith/arXiv arXiv 2026
-
[20]
C- Pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- Pack: Packed resources for general chinese embeddings. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024. Introduces the BGE embedding models, incl.bge-small-en-v1.5; arXiv:2309.07597
Pith/arXiv arXiv 2024
-
[21]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025. A Prompts For fullreproducibility wereproducethe exact promptsthe harness uses, verbatimfrom the repository (non-ASCII characters are normalised for typesetting). Theanswerersystem prompt (used with –reaso...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.