Decoupled Delay Compensation: Enhancing Pre-trained MARL Policies via Learned Dynamics Filtering
Pith reviewed 2026-06-29 18:59 UTC · model grok-4.3
The pith
A plug-in state estimator using a learned Gated transition model and Kalman filtering lets pre-trained MARL policies handle communication delays without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
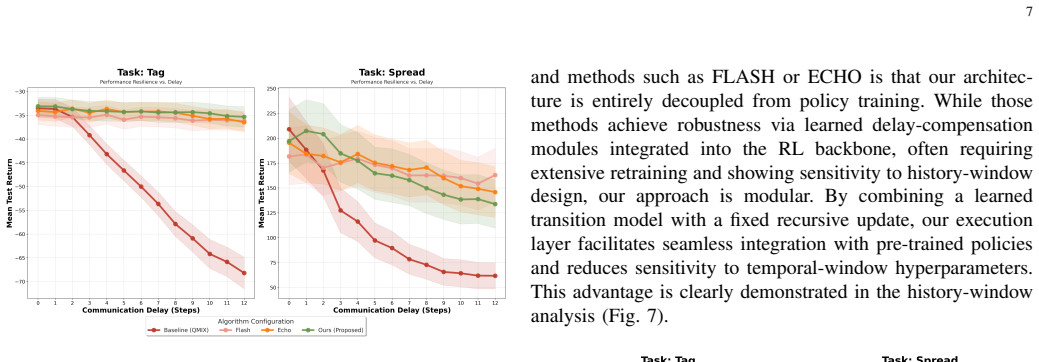
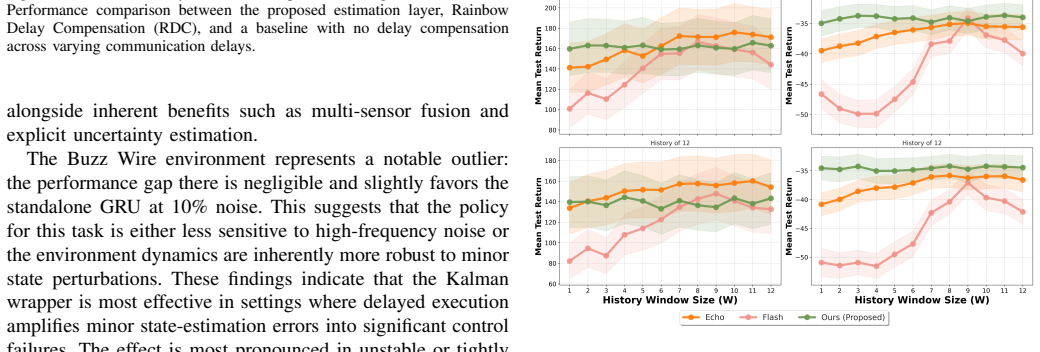
The central claim is that a decoupled execution-stage estimator built from a learned Gated transition model and recursive Kalman filtering can replace delayed communicated observations with accurate instantaneous state estimates, enabling pre-trained MARL policies to maintain performance under stochastic delays and message loss while remaining fully modular.
What carries the argument
Learned Gated transition model integrated with recursive Kalman filtering, which generates current belief-state estimates from asynchronous measurements as a plug-in replacement for delayed inputs.
If this is right
- The estimator attaches to any pre-trained MARL policy without altering the training algorithm, network architecture, or reward function.
- Robustness to latency and message loss improves consistently across multi-agent and continuous-control tasks.
- Largest gains appear in coordination-intensive and dynamically unstable environments where timing matters.
- Delayed measurements are replaced at runtime by current belief-state estimates produced by the filtering layer.
Where Pith is reading between the lines
- The same modular filter could be attached to single-agent policies facing asynchronous sensor data.
- Training-free robustness might reduce reliance on delay-augmented simulators during policy development.
- Online adaptation of the transition model could further improve estimates when network conditions drift.
Load-bearing premise
The learned Gated transition model combined with recursive Kalman filtering produces state estimates accurate enough for the unmodified pre-trained policy to achieve the reported robustness gains.
What would settle it
A controlled test in which the policy equipped with the estimator shows no improvement in returns over the baseline policy that directly uses delayed observations, on any benchmark with substantial communication latency or packet loss.
Figures


read the original abstract
Real-world multi-agent reinforcement learning (MARL) systems must often operate under stale observations, stochastic communication delays, and intermittent packet loss. Policies trained under idealized synchronous conditions frequently exhibit significant performance degradation in these regimes because they act on outdated feedback. We propose a modular execution-stage state-estimation layer that replaces delayed communicated observations with current belief-state estimates. The framework integrates a learned Gated transition model with a recursive Kalman filtering layer to estimate instantaneous states from asynchronous measurements. A primary advantage of this approach is its modularity, The estimator serves as a plug-in for pre-trained policies, requiring no modifications to the original MARL training algorithm, architecture, or reward structure. Evaluation across diverse multi-agent and continuous-control benchmarks demonstrates that the proposed layer consistently enhances robustness to communication latency and message loss. The most significant performance gains are observed in coordination-intensive and dynamically unstable tasks where temporal consistency is critical for control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modular execution-stage state-estimation layer for pre-trained MARL policies to handle stale observations due to communication delays and packet loss. It combines a learned Gated transition model with recursive Kalman filtering to produce current belief-state estimates from asynchronous measurements. The layer is presented as a plug-in module requiring no changes to the original policy, training algorithm, or rewards. The authors claim that this consistently improves robustness on diverse multi-agent and continuous-control benchmarks, with largest gains in coordination-intensive and dynamically unstable tasks.
Significance. If the estimator produces belief states whose error lies within the robustness margin of unmodified pre-trained policies, the decoupled modular design would be a practical contribution for real-world MARL deployment under imperfect communication, avoiding the expense of delay-aware retraining.
major comments (2)
- [Abstract and Evaluation] Abstract / Evaluation: The central claim requires that the Gated transition model + recursive Kalman filter produces state estimates accurate enough for an unmodified policy (trained on perfect observations) to retain performance. No quantitative characterization of estimation error (e.g., RMSE vs. ground-truth state under the exact delay/loss distributions) or ablation replacing the learned estimator with an oracle estimator is reported, leaving the source of any gains unisolated.
- [Abstract and Evaluation] Evaluation: The abstract states that the layer 'consistently enhances robustness' and reports 'most significant performance gains' in certain tasks, yet supplies no numerical results, baseline comparisons, training details for the gated model, or error analysis. This absence prevents assessment of whether the reported improvements are load-bearing or incidental.
minor comments (1)
- [Abstract] Abstract contains a sentence fragment: 'A primary advantage of this approach is its modularity, The estimator serves as a plug-in...' – this should be rephrased for grammatical correctness and flow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for clearer quantitative support of our claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract / Evaluation: The central claim requires that the Gated transition model + recursive Kalman filter produces state estimates accurate enough for an unmodified policy (trained on perfect observations) to retain performance. No quantitative characterization of estimation error (e.g., RMSE vs. ground-truth state under the exact delay/loss distributions) or ablation replacing the learned estimator with an oracle estimator is reported, leaving the source of any gains unisolated.
Authors: We agree that explicit RMSE characterization of estimation error under the evaluated delay and loss distributions would help readers assess estimator quality. The revised manuscript will include this analysis. Regarding an oracle ablation, we note that an oracle providing perfect instantaneous states is unavailable by definition in the target deployment regime of stale observations; such an ablation would therefore not reflect a realistic baseline. To isolate the learned component we will instead add comparisons against non-learned recursive filters (e.g., standard Kalman without the gated transition model) while retaining the end-to-end policy performance results as the primary validation metric. revision: partial
-
Referee: [Abstract and Evaluation] Evaluation: The abstract states that the layer 'consistently enhances robustness' and reports 'most significant performance gains' in certain tasks, yet supplies no numerical results, baseline comparisons, training details for the gated model, or error analysis. This absence prevents assessment of whether the reported improvements are load-bearing or incidental.
Authors: The current abstract is intentionally concise, but we accept that including representative numerical results would improve transparency. In the revision we will augment the abstract with key performance deltas and will expand the evaluation section to report baseline comparisons, gated-model training hyperparameters, and error analysis so that readers can directly judge the magnitude and reliability of the observed gains. revision: yes
Circularity Check
No circularity; estimator presented as independent module
full rationale
The paper introduces a learned Gated transition model + recursive Kalman filter as a modular plug-in layer for pre-trained policies. No equations, self-citations, or fitted parameters are shown to reduce the reported robustness gains to a quantity defined by the same evaluation data or by construction. The derivation chain remains self-contained against external benchmarks, consistent with the reader's assessment of score 1.0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption System dynamics can be captured by a learnable gated transition model from asynchronous measurements.
Reference graph
Works this paper leans on
-
[1]
Multi-agent deep reinforcement learning: a survey.Artificial Intelligence Review, 55(2):895–943, Febru- ary 2022
Sven Gronauer and Klaus Diepold. Multi-agent deep reinforcement learning: a survey.Artificial Intelligence Review, 55(2):895–943, Febru- ary 2022
2022
-
[2]
Longchao Da, Justin Turnau, Thirulogasankar Pranav Kutralingam, Al- varo Velasquez, Paulo Shakarian, and Hua Wei. A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models, March 2025. arXiv:2502.13187 [cs]
-
[3]
Revisiting State Augmentation methods for Reinforcement Learning with Stochastic Delays
Somjit Nath, Mayank Baranwal, and Harshad Khadilkar. Revisiting State Augmentation methods for Reinforcement Learning with Stochastic Delays. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 1346–1355, October
- [4]
-
[5]
Reinforcement Learning for Control Sys- tems with Time Delays: A Comprehensive Survey, January 2026
Armando Alves Neto. Reinforcement Learning for Control Sys- tems with Time Delays: A Comprehensive Survey, January 2026. arXiv:2602.00399 [stat]
-
[6]
Katsikopoulos and S.E
K.V . Katsikopoulos and S.E. Engelbrecht. Markov decision processes with delays and asynchronous cost collection.IEEE Transactions on Automatic Control, 48(4):568–574, April 2003
2003
-
[7]
A Survey of Learning in Multiagent Environ- ments: Dealing with Non-Stationarity, July 2017
Pablo Hernandez-Leal, Michael Kaisers, Tim Baarslag, and En- rique Munoz de Cote. A Survey of Learning in Multiagent Environ- ments: Dealing with Non-Stationarity, July 2017
2017
-
[8]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Ben- gio. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling, December 2014. arXiv:1412.3555 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
The Seminal Kalman Filter Paper (1960)
1960
-
[10]
Probabilistic Robotics
Josh Bongard. Probabilistic Robotics. Sebastian Thrun, Wolfram Bur- gard, and Dieter Fox. (2005, MIT Press.) 647 pages.Artificial Life, 14(2):227–229, April 2008
2005
-
[11]
Songchen Fu, Siang Chen, Shaojing Zhao, Letian Bai, Ta Li, and Yonghong Yan. Rainbow Delay Compensation: A Multi-Agent Re- inforcement Learning Framework for Mitigating Delayed Observation, November 2025. arXiv:2505.03586 [cs]
-
[12]
Deep Recurrent Q-Learning for Partially Observable MDPs
Matthew Hausknecht and Peter Stone. Deep Recurrent Q-Learning for Partially Observable MDPs, January 2017. arXiv:1507.06527 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Memory-based control with recurrent neural networks
Nicolas Heess, Jonathan J. Hunt, Timothy P. Lillicrap, and David Silver. Memory-based control with recurrent neural networks, December 2015. arXiv:1512.04455 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Delay-Aware Model-Based Reinforcement Learning for Continuous Control, May
Baiming Chen, Mengdi Xu, Liang Li, and Ding Zhao. Delay-Aware Model-Based Reinforcement Learning for Continuous Control, May
- [15]
-
[16]
Delay-Aware Reinforcement Learning: Insights From Delay Distributional Perspective
Zhuoru Yu, Chenchen Fu, Hengkai Zhong, Wanyuan Wang, Weiwei Wu, and Chun Jason Xue. Delay-Aware Reinforcement Learning: Insights From Delay Distributional Perspective. October 2024
2024
-
[17]
DA- COM: Learning Delay-Aware Communication for Multi-Agent Rein- forcement Learning, December 2022
Tingting Yuan, Hwei-Ming Chung, Jie Yuan, and Xiaoming Fu. DA- COM: Learning Delay-Aware Communication for Multi-Agent Rein- forcement Learning, December 2022. arXiv:2212.01619 [cs]
- [18]
- [19]
-
[20]
Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Nav- igation.Aerospace, 11(5):395, May 2024
Francesco Marino and Giorgio Guglieri. Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Nav- igation.Aerospace, 11(5):395, May 2024
2024
-
[21]
Armin Karamzade, Kyungmin Kim, J. B. Lanier, Davide Corsi, and Roy Fox. Model-Based Reinforcement Learning under Random Observation Delays. October 2025
2025
-
[22]
Li, Toryn Q
Andrew Wang, Andrew C. Li, Toryn Q. Klassen, Rodrigo Toro Icarte, and Sheila A. McIlraith. Learning belief representations for partially ob- servable deep RL. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofICML’23, pages 35970–35988, Honolulu, Hawaii, USA, July 2023. JMLR.org
2023
-
[23]
Remarks on stochastic cloning and delayed-state filtering
Tara Mina, Lindsey Marinello, and John Christian. Remarks on stochas- tic cloning and delayed-state filtering, August 2025. arXiv:2508.21260 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
Anusha Nagabandi, Gregory Kahn, Ronald S. Fearing, and Sergey Levine. Neural Network Dynamics for Model-Based Deep Rein- forcement Learning with Model-Free Fine-Tuning, December 2017. arXiv:1708.02596 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Griewank and A
A. Griewank and A. Walther.Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, Second Edition. Other Titles in Applied Mathematics. Society for Industrial and Applied Mathemat- ics, 2008
2008
-
[26]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, March 2020
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, March 2020. arXiv:1706.02275 [cs]
-
[27]
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder de Witt, Gre- gory Farquhar, Jakob Foerster, and Shimon Whiteson. QMIX: Mono- tonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning, June 2018. arXiv:1803.11485 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning, September 2022
Matteo Bettini, Ryan Kortvelesy, Jan Blumenkamp, and Amanda Prorok. VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning, September 2022. arXiv:2207.03530 [cs]
-
[29]
Schroeder de Witt, Pierre- Alexandre Kamienny, Philip H
Bei Peng, Tabish Rashid, Christian A. Schroeder de Witt, Pierre- Alexandre Kamienny, Philip H. S. Torr, Wendelin B ¨ohmer, and Shimon Whiteson. FACMAC: Factored Multi-Agent Centralised Policy Gradi- ents, May 2021. arXiv:2003.06709 [cs]
-
[30]
The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games, November 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games, November 2022. arXiv:2103.01955 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.