HNSW with Accuracy Guarantees Using Graph Spanners -- A Technical Report
Pith reviewed 2026-07-03 02:53 UTC · model grok-4.3
The pith
A Certify-then-Rectify framework adds worst-case correctness to HNSW searches by certifying heuristic results and escalating to exact recovery when needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the HNSW graph as a geometric spanner and applying Extreme Value Theory to bound its maximum empirical stretch factor, the framework obtains a distribution-free statistical certificate for the quality of a greedy HNSW traversal; when the certificate fails, the same bound makes an exact recovery step computationally feasible, yielding a method whose average-case cost matches HNSW while its worst-case output is always correct.
What carries the argument
The geometric-spanner reinterpretation of HNSW together with Extreme Value Theory estimation of its maximum stretch factor, which supplies the distance bounds used by the certifier.
If this is right
- Most queries finish at HNSW speed because the certifier passes in the common case.
- The exact-recovery step is invoked only when the stretch bound indicates the heuristic may have failed.
- The same certification logic can be applied to any HNSW index without rebuilding it.
- The resulting system outperforms prior attempts to add guarantees to HNSW on standard datasets.
Where Pith is reading between the lines
- The spanner-plus-EVT technique could be tested on other greedy graph indexes such as NSW or NSG to see whether similar bounds hold.
- Dynamic updates to the HNSW graph would require periodic re-estimation of the stretch factor to keep the certificate valid.
- Tighter stretch-factor estimators might reduce the frequency of escalation to the exact step.
Load-bearing premise
That the largest stretch factor observed in the HNSW graph can be estimated reliably enough by Extreme Value Theory to produce a valid upper bound on true nearest-neighbor distances.
What would settle it
A collection of queries on a benchmark graph where the certified HNSW output still misses a true nearest neighbor after the rectification step, or where measured distances exceed the EVT-derived bound.
Figures














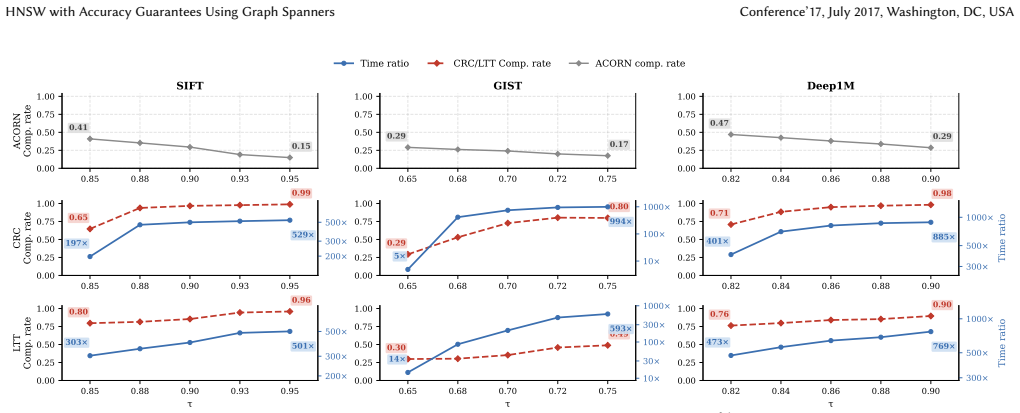
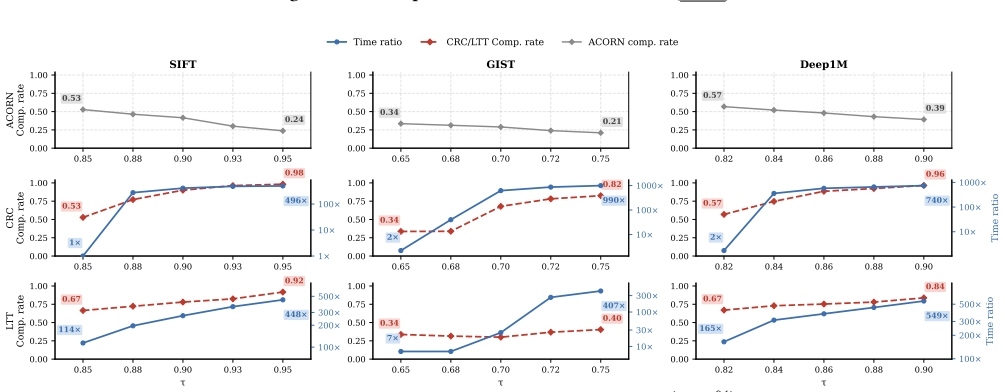


read the original abstract
Hierarchical Navigable Small World (HNSW) graphs serve as the industry standard due to their logarithmic complexity and strong empirical performance. However, HNSW relies on greedy graph traversal, a heuristic that provides no theoretical guarantees of correctness. In this paper, we propose a novel "Certify-then-Rectify" framework that bridges the gap between the speed of heuristic search and the rigor of exact retrieval. Rather than discarding HNSW, our approach first employs a distribution-free statistical certifier to dynamically evaluate the quality of a standard HNSW search with minimal overhead. If certification indicates that the retrieved neighbors are of low quality, the framework safely escalates to a rigorous exact recovery algorithm. To make this exact recovery computationally feasible, we reinterpret the HNSW graph as a geometric spanner and utilize Extreme Value Theory to stochastically estimate its maximum empirical stretch factor. This allows us to mathematically bound the maximum distance of true nearest neighbors. Extensive evaluations on benchmark datasets demonstrate that our tiered framework delivers the average-case speed of HNSW while ensuring the worst-case correctness of exact search and outperforming other applicable approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'Certify-then-Rectify' framework for HNSW graphs in approximate nearest neighbor search. A distribution-free statistical certifier evaluates the quality of standard HNSW greedy traversal results with low overhead; if quality is insufficient, the system escalates to an exact recovery procedure. To keep exact recovery tractable, the HNSW graph is reinterpreted as a geometric spanner whose maximum empirical stretch factor is estimated via Extreme Value Theory, yielding a mathematical bound on the distance to true nearest neighbors. Benchmark evaluations are claimed to show that the tiered approach retains HNSW average-case speed while delivering the worst-case correctness of exact search and outperforming alternatives.
Significance. If the derivations and empirical claims hold, the work would be significant for database and retrieval systems: it offers a practical route to attach correctness guarantees to the dominant heuristic ANN index without discarding its performance. The spanner reinterpretation combined with EVT for stretch estimation is a distinctive technical move that, if made rigorous, could generalize to other graph-based indexes.
major comments (2)
- [Abstract] Abstract: the central guarantee is stated as 'ensuring the worst-case correctness of exact search' via a 'mathematically bound' on true nearest-neighbor distances obtained by EVT estimation of the spanner stretch factor. EVT supplies high-probability tail bounds (statements of the form 'with probability 1-δ the stretch ≤ s') whose validity rests on domain-of-attraction assumptions; the supplied text contains no derivation converting this into a distribution-free, δ=0 deterministic bound that holds for every query and dataset. Consequently the escalation trigger remains probabilistic and the worst-case claim is not yet supported.
- [Abstract] Abstract (and implied § on Certify-then-Rectify): the certifier is described as 'distribution-free' yet the stretch estimation step invokes EVT, which is parametric in its tail model. No equation or section is visible that shows how the two components compose to a guarantee that is simultaneously distribution-free and worst-case; this composition is load-bearing for the tiered correctness claim.
minor comments (2)
- [Abstract] Abstract is overloaded; the framework, certifier, spanner reinterpretation, and EVT application are asserted without any equation or complexity statement, making it difficult to assess overhead or correctness.
- [Abstract] The phrase 'maximum empirical stretch factor' is used without a preceding definition or reference to the geometric-spanner literature; a short background paragraph would help readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the insightful comments highlighting the distinction between high-probability and deterministic guarantees. We agree that the abstract wording requires clarification to avoid overstating the nature of the bounds. We will revise the manuscript to precisely describe the probabilistic character of the EVT-based stretch estimation while preserving the distribution-free property of the certifier.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central guarantee is stated as 'ensuring the worst-case correctness of exact search' via a 'mathematically bound' on true nearest-neighbor distances obtained by EVT estimation of the spanner stretch factor. EVT supplies high-probability tail bounds (statements of the form 'with probability 1-δ the stretch ≤ s') whose validity rests on domain-of-attraction assumptions; the supplied text contains no derivation converting this into a distribution-free, δ=0 deterministic bound that holds for every query and dataset. Consequently the escalation trigger remains probabilistic and the worst-case claim is not yet supported.
Authors: We concur that the current abstract phrasing implies a deterministic worst-case guarantee, whereas the EVT step produces high-probability bounds on the empirical stretch factor. No derivation to a δ=0 deterministic bound exists in the manuscript because the method relies on tail estimation. We will revise the abstract and add explicit language in the Certify-then-Rectify section stating that the rectification bound holds with probability at least 1-δ (under the EVT domain-of-attraction assumption) rather than for every query. This will also clarify that the overall escalation decision is probabilistic. revision: yes
-
Referee: [Abstract] Abstract (and implied § on Certify-then-Rectify): the certifier is described as 'distribution-free' yet the stretch estimation step invokes EVT, which is parametric in its tail model. No equation or section is visible that shows how the two components compose to a guarantee that is simultaneously distribution-free and worst-case; this composition is load-bearing for the tiered correctness claim.
Authors: The certifier operates without distributional assumptions on the data or queries. The EVT component for stretch estimation is parametric in the tail model and yields probabilistic bounds. We will insert a dedicated paragraph (and, if space permits, an equation) in the framework section that composes the two: the distribution-free certification test decides whether to accept the HNSW result or invoke the spanner-based rectification whose distance bound holds with high probability. The revised text will not claim a fully deterministic, distribution-free worst-case guarantee but will accurately describe the hybrid probabilistic guarantee that results. revision: yes
Circularity Check
No circularity: framework uses external statistical tools without self-referential reduction
full rationale
The derivation chain reinterprets HNSW as a spanner and applies EVT for stretch estimation to support a certify-then-rectify procedure. No equations, fitted parameters, or self-citations are shown that reduce the claimed bounds or guarantees to the inputs by construction. The statistical certifier and EVT tail modeling are presented as independent methods whose validity does not depend on the target result itself. This is the common case of a self-contained proposal whose correctness may be debated on other grounds but exhibits no definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- certifier thresholds or parameters
axioms (2)
- domain assumption HNSW graph admits reinterpretation as a geometric spanner
- domain assumption Extreme Value Theory can be applied to estimate the maximum empirical stretch factor of the spanner
Reference graph
Works this paper leans on
-
[1]
Anas Ait Aomar, Karima Echihabi, Marco Arnaboldi, Ioannis Alagiannis, Damien Hilloulin, and Manal Cherkaoui. 2025. RWalks: Random Walks as At- tribute Diffusers for Filtered Vector Search.PACMMOD 3, 3 (2025)
2025
- [2]
-
[3]
Anastasios N Angelopoulos and Stephen Bates. 2021. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Angelopoulos, Stephen Bates, Emmanuel J
Anastasios N. Angelopoulos, Stephen Bates, Emmanuel J. Candès, and Michael I. Jordan. 2024. Conformal Risk Control. J. Amer. Statist. Assoc. 119, 548 (2024), 2386–2408. https://doi.org/10.1080/01621459.2024.2302500
-
[5]
Angelopoulos, Stephen Bates, Michael I
Anastasios N. Angelopoulos, Stephen Bates, Michael I. Jordan, and Jitendra Ma- lik. 2022. Learn then Test: Calibrating Predictive Algorithms to Achieve Risk Control. InICLR. OpenReview
2022
-
[6]
Jees Augustine, Suraj Shetiya, Mohammadreza Esfandiari, Senjuti Basu Roy, and Gautam Das. 2021. A Generalized Approach for Reducing Expensive Distance Calls for A Broad Class of Proximity Problems. InACM SIGMOD. 142–154
2021
-
[7]
Stephen Bates, Anastasios Angelopoulos, Lihua Lei, Jitendra Malik, and Michael Jordan. 2021. Distribution-free, Risk-controlling Prediction Sets.J. ACM 68, 6, Article 43 (Sept. 2021), 34 pages. https://doi.org/10.1145/3478535
-
[8]
Francesco Busolin, Claudio Lucchese, Franco Maria Nardini, Salvatore Orlando, Raffaele Perego, and Salvatore Trani. 2024. Early exit strategies for approximate k-NN search in dense retrieval. InCIKM. 3647–3652
2024
-
[9]
Yuzheng Cai, Jiayang Shi, Yizhuo Chen, and Weiguo Zheng. 2024. Navigating La- bels and Vectors: A Unified Approach to Filtered Approximate Nearest Neighbor Search.PACMMOD 2, 6 (2024)
2024
-
[10]
Matteo Ceccarello, Alexandra Levchenko, Ioana Ileana, and Themis Palpanas
-
[11]
InACM SIGKDD
Evaluating and Generating Query Workloads for High Dimensional Vector Similarity Search. InACM SIGKDD
-
[12]
Charikar
Moses S. Charikar. 2002. Similarity estimation techniques from rounding algo- rithms. InSTOC. 380–388
2002
-
[13]
Manos Chatzakis, Yannis Papakonstantinou, and Themis Palpanas. 2025. Darth: Declarative recall through early termination for approximate nearest neighbor search.PACMMOD 3, 4 (2025), 1–26
2025
-
[14]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-Efficient Billion-Scale Approximate Nearest Neighborhood Search. InAdvances in Neural Information Processing Systems, Vol. 34
2021
-
[15]
Yilun Chen, Zhiding Yu, Yukang Chen, Shiyi Lan, Anima Anandkumar, Jiaya Jia, and Jose M. Alvarez. 2023. FocalFormer3D: Focusing on Hard Instance for 3D Object Detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[16]
Yannis Chronis, Helena Caminal, Yannis Papakonstantinou, Fatma Özcan, and Anastasia Ailamaki. 2025. Filtered Vector Search: State-of-the-Art and Research Opportunities.PVLDB 18, 12 (2025), 5488–5492
2025
-
[17]
2001.An introduc- tion to statistical modeling of extreme values
Stuart Coles, Joanna Bawa, Lesley Trenner, and Pat Dorazio. 2001.An introduc- tion to statistical modeling of extreme values . Vol. 208. Springer
2001
-
[18]
Mirrokni
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni. 2004. Locality-sensitive hashing scheme based on p-stable distributions. InSCG. 253– 262
2004
-
[19]
Liwei Deng, Penghao Chen, Ximu Zeng, Tianfu Wang, Yan Zhao, and Kai Zheng. 2024. Efficient Data-Aware Distance Comparison Operations for High- Dimensional Approximate Nearest Neighbor Search.PVLDB 18, 3 (2024), 812– 821
2024
-
[20]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
R. A. Fisher and L. H. C. Tippett. 1928. Limiting forms of the frequency distribu- tion of the largest or smallest member of a sample.Mathematical Proceedings of the Cambridge Philosophical Society 24, 2 (1928), 180–190
1928
-
[23]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast approximate nearest neighbor search with the navigating spreading-out graph.PVLDB 12, 5 (2019), 461–474
2019
-
[24]
Jianyang Gao and Cheng Long. 2023. High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations. PACMMOD 1, 2 (2023)
2023
-
[25]
E. J. Gumbel. 1958. Statistics of Extremes. Columbia University Press, New York, Chichester, West Sussex.https://doi.org/10.7312/gumb92958
-
[26]
Sonia Horchidan, Fabian Zeiher, Henrik Boström, and Paris Carbone. 2026. Co- nANN: Conformal Approximate Nearest Neighbor Search.PVLDB 19, 1 (2026), 29–42
2026
-
[27]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared Di- Carlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas Godden, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter, Sz...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravis- hankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InNeurIPS, Vol. 32
2019
-
[29]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data 7, 3 (2019), 535–547
2019
-
[30]
Herve Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Machine Intelligence 33, 1 (2011), 117–128
2011
-
[31]
Conglong Li, Minjia Zhang, David G Andersen, and Yuxiong He. 2020. Improv- ing approximate nearest neighbor search through learned adaptive early termi- nation. InACM SIGMOD. 2539–2554
2020
-
[32]
Minghao Li, Raghav Mittal, Sanjivni Rana, Suraj Shetiya, Gautam Das, and Nick Koudas. 2026. Technical Report for Recall Certification for HNSW. https:// github.com/ming-afk/recall_certify_hnsw/blob/main/tr.pdfTechnical report
2026
- [33]
-
[34]
Zhaoheng Li, Silu Huang, Wei Ding, Yongjoo Park, and Jianjun Chen. 2025. SIEVE: Effective Filtered Vector Search with Collection of Indexes.PVLDB 18, 11 (2025), 4723–4736
2025
-
[35]
Anqi Liang, Pengcheng Zhang, Bin Yao, Zhongpu Chen, Yitong Song, and Guangxu Cheng. 2024. UNIFY: Unified Index for Range Filtered Approximate Nearest Neighbors Search.PVLDB 18, 4 (2024), 1118–1130
2024
-
[36]
Zhenxi Lin, Ziheng Zhang, Xian Wu, and Yefeng Zheng. 2023. Improving Biomedical Entity Linking with Retrieval-Enhanced Learning.arXiv preprint arXiv:2312.09806 (2023). https://doi.org/10.48550/arXiv.2312.09806
-
[37]
Qin Lv, William Josephson, Zhe Wang, Moses Charikar, and Kai Li. 2007. Multi- probe LSH: efficient indexing for high-dimensional similarity search. InVLDB. 950–961
2007
-
[38]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[39]
Information Systems 45 (2014), 61–68
Approximate nearest neighbor algorithm based on navigable small world graphs. Information Systems 45 (2014), 61–68
2014
-
[40]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions On Pattern Analysis And Machine Intelligence 42, 4 (2018), 824–836
2018
-
[41]
Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman
Jason Mohoney, Devesh Sarda, Mengze Tang, Shihabur Rahman Chowdhury, Anil Pacaci, Ihab F. Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman
-
[42]
InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25)
Quake: Adaptive Indexing for Vector Search. InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) . USENIX Association
-
[43]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Survey of vector database management systems.VLDB 33, 5 (2024), 1591–1615
2024
-
[44]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. ACORN: Per- formant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data.PACMMOD 2, 3 (2024), 1–27
2024
-
[45]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dy- namic Range-Filtering Approximate Nearest Neighbor Search.PVLDB 18, 10 (2025)
2025
-
[46]
2012.Computational Geometry: An Introduction
Franco P Preparata and Michael I Shamos. 2012.Computational Geometry: An Introduction. Springer Science & Business Media
2012
-
[47]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Lud- wig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. LAION-5B: An open large-scale dataset for training next generation image-text...
2022
-
[48]
Yitong Song, Pengcheng Zhang, Chao Gao, Bin Yao, Kai Wang, Zongyuan Wu, and Lin Qu. 2025. TRIM: Accelerating High-Dimensional Vector Similarity Search with Enhanced Triangle-Inequality-Based Pruning.PACMMOD 3, 6 (2025), 1–26
2025
-
[49]
Ziwen Song, Bin Wang, and Xiaochun Yang. 2025. Accelerating High- Dimensional ANN Search via Skipping Redundant Distance Computations. PACMMOD 3, 6 (2025), 1–29
2025
-
[50]
Tommaso Teofili and Jimmy Lin. 2025. Patience In Proximity: A Simple Early Ter- mination Strategy for HNSW Graph Traversal in Approximate k-Nearest Neigh- bor Search. InECIR. 401–407
2025
-
[51]
Toussaint
Godfried T. Toussaint. 1980. The relative neighbourhood graph of a finite planar set.Pattern Recognition 12, 4 (1980), 261–268
1980
- [52]
-
[53]
Zeyu Wang, Qitong Wang, Xiaoxing Cheng, Peng Wang, Themis Palpanas, and Wei Wang. 2024. Steiner-Hardness: A Query Hardness Measure for Graph-Based ANN Indexes. PVLDB 17, 13 (2024), 4668–4682
2024
-
[54]
Maciej Wiatrak, Eirini Arvaniti, Angus Brayne, Jonas Vetterle, and Aaron Sim
-
[55]
arXiv preprint arXiv:2301.13318 (2023)
Proxy-based Zero-Shot Entity Linking by Effective Candidate Retrieval. arXiv preprint arXiv:2301.13318 (2023). https://doi.org/10.48550/arXiv.2301. 13318
-
[56]
Qian Xu, Juan Yang, Feng Zhang, Junda Pan, Kang Chen, Youren Shen, Amelie Chi Zhou, and Xiaoyong Du. 2025. Tribase: A Vector Data Query En- gine for Reliable and Lossless Pruning Compression using Triangle Inequalities. PACMMOD 3, 1 (2025), 1–28
2025
-
[57]
Yuexuan Xu, Jianyang Gao, Yutong Gou, Cheng Long, and Christian S. Jensen
-
[58]
iRangeGraph: Improvising Range-dedicated Graphs for Range-filtering Nearest Neighbor Search.PACMMOD 2, 6 (2024)
2024
- [59]
-
[60]
Mingyu Yang, Wentao Li, Jiabao Jin, Xiaoyao Zhong, Xiangyu Wang, Zhitao Shen, Wei Jia, and Wei Wang. 2025. Effective and general distance computation for approximate nearest neighbor search. InIEEE ICDE. 1098–1110
2025
- [61]
-
[62]
Zili Zhang, Chao Jin, Linpeng Tang, Xuanzhe Liu, and Xin Jin. 2023. Fast, Ap- proximate Vector Queries on Very Large Unstructured Datasets. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX Association, 995–1011
2023
-
[63]
Xiaoyao Zhong, Haotian Li, Jiabao Jin, Mingyu Yang, Deming Chu, Xiangyu Wang, Zhitao Shen, Wei Jia, George Gu, Yi Xie, Xuemin Lin, Heng Tao Shen, Jingkuan Song, and Peng Cheng. 2025. VSAG: An Optimized Search Framework for Graph-Based Approximate Nearest Neighbor Search.PVLDB 18, 12 (2025), 5017–5030
2025
-
[64]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. SeRF: Segment Graph for Range-Filtering Approximate Nearest Neighbor Search. PACMMOD 2, 1 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.