Benchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems
Pith reviewed 2026-06-29 15:29 UTC · model grok-4.3
The pith
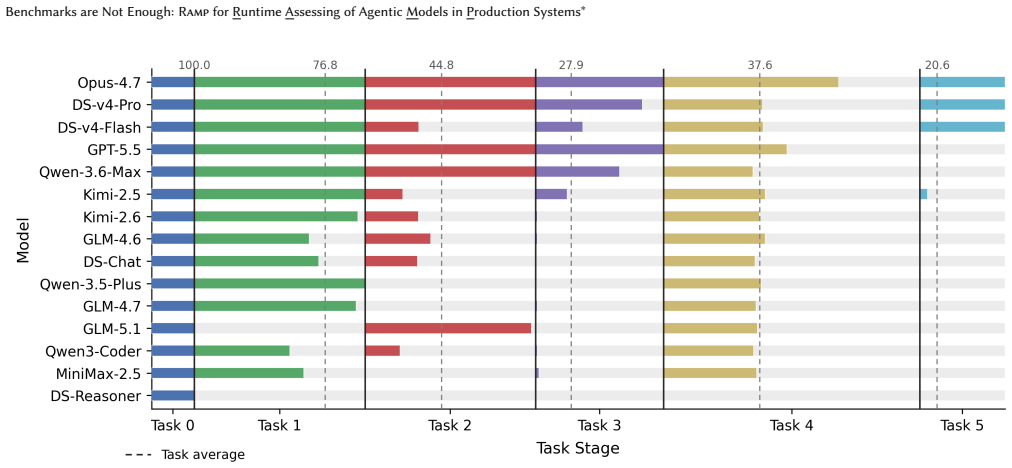
RAMP shows agentic models' performance collapses in long serial workflows, with none completing full pipelines despite benchmark success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
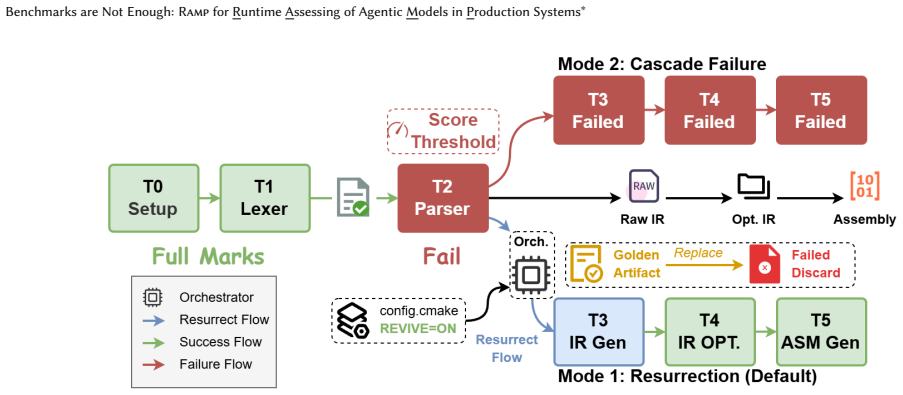
RAMP, built on the YatCC platform, uses standardized interfaces for long-horizon compiler-construction workloads and a staged recovery mechanism to evaluate agent performance under partial failures. Assessments of 15 models reveal progressive collapse in completion rates and up to three orders of magnitude difference in computational costs, with no model finishing the entire pipeline.
What carries the argument
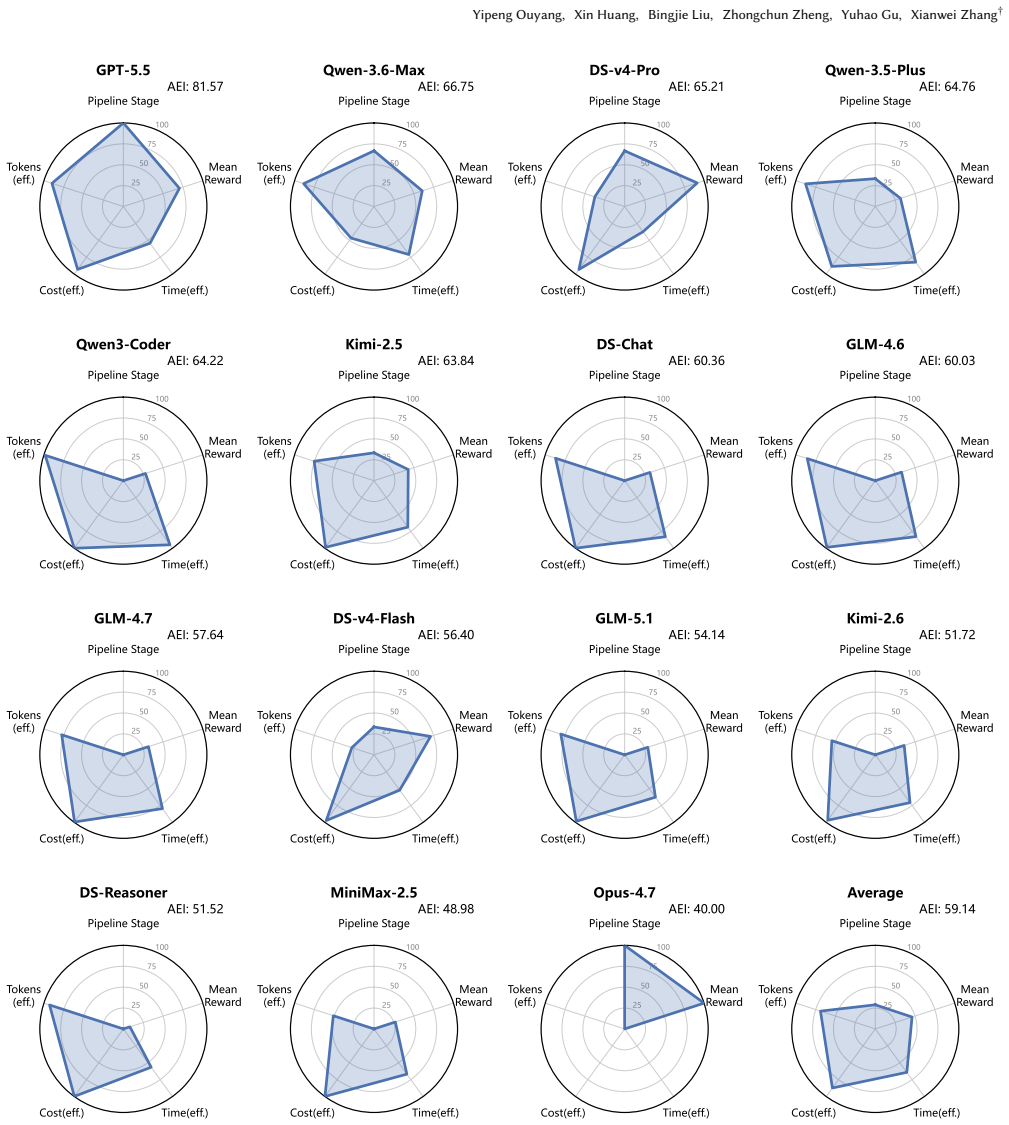
RAMP framework providing unified runtime assessment architecture with realistic workloads, staged recovery, and utility-oriented multi-dimensional metrics for outcome quality and process efficiency.
If this is right
- Task completion rates in serial workflows drop from 100% to 20% across stages.
- None of the 15 evaluated models complete the full pipeline.
- Computational costs vary by up to three orders of magnitude among models.
- Systematic failure propagation occurs in long execution chains.
Where Pith is reading between the lines
- Evaluation of agentic models may need to prioritize runtime observability over isolated benchmark scores.
- Production systems could benefit from incorporating staged recovery mechanisms to handle partial failures in agent workflows.
- Resource efficiency should be a core metric alongside task success in agent assessments.
Load-bearing premise
The chosen compiler-construction workloads with serial dependencies and complex toolchain interactions represent the dynamic complexity of real-world production software engineering workflows.
What would settle it
Running the same 15 models on a different set of long-horizon production tasks without the staged recovery mechanism and observing if completion rates still collapse to 20% or if any model completes the full pipeline.
Figures




read the original abstract
LLM agents are rapidly evolving from coding assistants into autonomous software engineering systems. However, existing evaluation methodologies remain largely centered on static, isolated, and short-horizon benchmarks that fail to capture the dynamic complexity of real-world production workflows. As a result, benchmark performance may poorly reflect practical capability under realistic runtime environments involving long execution chains, tool interactions, dependency management, and iterative feedback loops. We thus present RAMP, a production-grounded infrastructure for assessing long-horizon software engineering agents. Built upon the YatCC integrated platform, RAMP provides a unified runtime assessment architecture through standardized orchestration and execution interfaces. RAMP introduces realistic compiler-construction workloads with serial dependencies and complex toolchain interactions, together with a staged recovery mechanism for analyzing execution behavior under partial workflow failure. The framework further incorporates utility-oriented multi-dimensional metrics that jointly evaluate outcome quality and process efficiency. We conduct runtime assessments across 15 mainstream models and observe substantial capability degradation that remains largely invisible to conventional isolated benchmarks. Task completion rates progressively collapse across serial workflows, dropping from 100% in the initial stage to only 20% in the final stage, while none of the evaluated models successfully completes the entire pipeline. Runtime analysis reveals systematic failure propagation and significant resource inefficiencies, with computational costs differing by up to three orders of magnitude among comparable models. These findings suggest RAMP advances agentic model evaluation toward continuous, runtime-observable, and production-grounded assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that static benchmarks fail to capture the dynamic complexity of production software engineering workflows for LLM agents. It introduces RAMP, a runtime assessment infrastructure on the YatCC platform that uses compiler-construction workloads with serial dependencies and a staged recovery mechanism, along with multi-dimensional utility metrics. Runtime evaluation of 15 models shows task completion collapsing from 100% in the first stage to 20% in the final stage, with zero models completing the full pipeline, plus large variations in resource costs; the authors conclude that production-grounded runtime assessment is required.
Significance. If the workloads prove representative of broader production SE tasks, the observed progressive failure propagation and cost disparities would provide concrete evidence that isolated benchmarks underestimate long-horizon agent limitations, supporting a shift toward continuous runtime evaluation frameworks. The staged recovery analysis and joint outcome-process metrics are practical contributions that could be adopted by other agent evaluation efforts.
major comments (2)
- [Abstract and evaluation description] Abstract and the description of the evaluation: the central empirical claim of progressive collapse (100% to 20% completion, zero full-pipeline successes) is reported without model selection criteria, precise definitions of the utility-oriented metrics, handling of partial failures, or any error bars or statistical tests. These omissions make it impossible to assess whether the degradation pattern is robust or reproducible.
- [Workload design and framework sections] Workload design and framework sections: the broader conclusion that 'benchmarks are not enough' for production systems depends on the compiler-construction workloads with serial dependencies serving as a valid proxy. No validation is supplied (e.g., expert review, coverage of non-compiler domains such as distributed services, or comparison of dependency graphs to industry workflows), so the observed failure modes could be artifacts of the narrow domain rather than a general property of agentic SE.
minor comments (1)
- [Title] The phrase 'RAMP for Runtime Assessing' in the title is grammatically awkward and should be revised to 'RAMP for Runtime Assessment of Agentic Models'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with planned revisions to improve clarity, reproducibility, and framing of the claims.
read point-by-point responses
-
Referee: [Abstract and evaluation description] Abstract and the description of the evaluation: the central empirical claim of progressive collapse (100% to 20% completion, zero full-pipeline successes) is reported without model selection criteria, precise definitions of the utility-oriented metrics, handling of partial failures, or any error bars or statistical tests. These omissions make it impossible to assess whether the degradation pattern is robust or reproducible.
Authors: We agree that these details are required for readers to evaluate robustness. The revised manuscript will add: explicit model selection criteria (stratified sampling across open-source and proprietary models based on coding benchmark performance and availability); formal definitions and formulas for the utility-oriented metrics (joint outcome-process scores with explicit weighting); a precise description of partial-failure handling within the staged recovery mechanism; and error bars with statistical tests (binomial confidence intervals and McNemar tests for stage-wise completion rates). These additions will be placed in the evaluation section and abstract. revision: yes
-
Referee: [Workload design and framework sections] Workload design and framework sections: the broader conclusion that 'benchmarks are not enough' for production systems depends on the compiler-construction workloads with serial dependencies serving as a valid proxy. No validation is supplied (e.g., expert review, coverage of non-compiler domains such as distributed services, or comparison of dependency graphs to industry workflows), so the observed failure modes could be artifacts of the narrow domain rather than a general property of agentic SE.
Authors: We accept that stronger justification is needed for the proxy claim. The workloads were selected for their long serial dependency chains and toolchain interactions that mirror production SE characteristics, but the original submission did not supply external validation. The revision will expand the workload design section with: (1) explicit rationale linking dependency graphs to patterns observed in large open-source repositories, (2) a limitations paragraph acknowledging the compiler-construction focus and absence of coverage for domains such as distributed services, and (3) a call for future multi-domain studies. We will not claim generalizability beyond the evaluated setting. revision: partial
Circularity Check
No circularity: empirical framework with direct observations
full rationale
The paper introduces the RAMP framework and reports empirical results from runtime assessments of 15 models on compiler-construction workloads. No derivations, equations, fitted parameters, predictions, or self-citations are described that reduce the central claims to inputs by construction. The observed collapse in completion rates (100% to 20%, zero full pipelines) is presented as a direct measurement within the RAMP setup. The representativeness of the workloads is an unvalidated assumption but does not create circularity in any derivation chain. This is a standard empirical comparison paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Yizhe Chi, Deyao Hong, Dapeng Jiang, Tianwei Luo, Kaisen Yang, Boshi Zhang, Zhe Cao, Xiaoyan Fan, Bingxiang He, Han Hao, Weiyang Jin, Dianqiao Lei, Qingle Liu, Houde Qian, Bowen Wang, Situ Wang, Youjie Zheng, Yifan Zhou, Calvin Xiao, Eren Cai, and Qinhuai Na. 2026. Frontier-Eng: Benchmarking Self- Evolving Agents on Real-World Engineering Tasks with Gener...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. 2024. Introducing SWE-bench Verified. OpenAI Blog
2024
-
[5]
Fan Cui, Hongyuan Hou, Zizhang Luo, Chenyun Yin, and Yun Liang. 2026. HWE- Bench: Benchmarking LLM Agents on Real-World Hardware Bug Repair Tasks. arXiv:2604.14709 [cs.AI] https://arxiv.org/abs/2604.14709
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2025. SWE-Bench Pro: Can AI Agents Solve L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Shuangrui Ding, Xuanlang Dai, Long Xing, Shengyuan Ding, Ziyu Liu, Yang JingYi, Penghui Yang, Zhixiong Zhang, Xilin Wei, Xinyu Fang, Yubo Ma, Haodong Duan, Jing Shao, Jiaqi Wang, Dahua Lin, Kai Chen, and Yuhang Zang. 2026. WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation. arXiv:2605.10912 [cs.CL] https://arxiv.org/abs/2605.10912
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Laïla Elkoussy and Julien Perez. 2026. SWE-QA: A Dataset and Benchmark for Complex Code Understanding. arXiv:2604.24814 [cs.SE] https://arxiv.org/abs/ 2604.24814
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Yuhao Gu et al. 2026. YatCC: Yat Compiler Course. https://github.com/arcsysu/ YatCC
2026
-
[10]
Tingxu Han, Yi Zhang andWei Song, Chunrong Fang andZhenyu Chen, and Youcheng Sun andLijie Hu. 2026. SWE-Skills-Bench: Do Agent Skills Ac- tually Help in Real-World Software Engineering?arXiv preprint(2026). arXiv:2603.15401 [cs.SE] https://arxiv.org/abs/2603.15401 arXiv:2603.15401
- [11]
-
[12]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InThe Twelfth International Conference on Learning Representations. Oral presentation
2024
-
[13]
Chris Lattner and Vikram Adve. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis and Transformation. San Jose, CA, USA, 75–88
2004
-
[14]
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. 2025. FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation. arXiv:2503.06680 [cs.SE] https://arxiv.org/abs/2503.06680
-
[15]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench: Eval- uating LLMs as Agents. InThe Twelfth International Conference on ...
2024
-
[17]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Mari- anna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: A Benchmark for General AI Assistants. InThe Twelfth International Conference on Learning Representations
2024
-
[19]
OpenAI. 2026. OpenAI API Documentation. https://platform.openai.com/docs/ api-reference Chat Completions API v1 and Responses API v1 specifications
2026
-
[20]
Sun Yat sen University arcSYSu Lab YatCC Team. 2026. YatCC: Yat Compiler Course. https://github.com/arcsysu/YatCC
2026
-
[21]
Mehil B Shah, Mohammad Mehdi Morovati, Mohammad Masudur Rahman, and Foutse Khomh. 2026. Characterizing Faults in Agentic AI: A Taxonomy of Types, Symptoms, and Root Causes. arXiv:2603.06847 [cs.SE] https://arxiv.org/abs/ 2603.06847
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv:2504.01848 [cs.AI] https://arxiv.org/ abs/2504.01848
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Muxin Tian, Zhe Wang, Blair Yang, Zhenwei Tang, Kunlun Zhu, Honghua Dong, Hanchen Li, Xinni Xie, Guangjing Wang, and Jiaxuan You. 2026. SWE-Bench Mobile: Can Large Language Model Agents Develop Industry-Level Mobile Applications? arXiv:2602.09540 [cs.SE] https://arxiv.org/abs/2602.09540
-
[24]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models. InIntrinsically-Motivated and Open-Ended Learning Workshop @NeurIPS2023. https://openreview.net/forum?id=nfx5IutEed
2023
-
[25]
Xingyao Wang, Simon Rosenberg, Juan Michelini, Calvin Smith, Hoang Tran, Engel Nyst, Rohit Malhotra, Xuhui Zhou, Valerie Chen, Robert Brennan, and Graham Neubig. 2026. The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents. arXiv:2511.03690 [cs.SE] https://arxiv.org/abs/2511.03690 15 Yipeng Ouyang, Xin Huang, Bingji...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Hjalmar Wijk, Tao Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Josh Clymer, Jai Dhyani, Elena Ericheva, Katharyn Garcia, Brian Goodrich, Nikola Jurkovic, Holden Karnofsky, Megan Kinniment, Aron Lajko, Seraphina Nix, Lucas Sato, William Saunders, Maksym Taran, Ben West, and Elizabeth Barnes. 2025. RE-Bench: Eval...
- [27]
-
[28]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[29]
InAdvances in Neural Information Processing Systems, A
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 52040–52094. doi:10.52202/079017-1650
-
[30]
John Yang, Kilian Lieret, Jeffrey Ma, Parth Thakkar, Dmitrii Pedchenko, Sten Sootla, Emily McMilin, Pengcheng Yin, Rui Hou, Gabriel Synnaeve, Diyi Yang, and Ofir Press. 2026. ProgramBench: Can Language Models Rebuild Programs From Scratch? arXiv:2605.03546 [cs.SE] https://arxiv.org/abs/2605.03546
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv:2504.02605 [cs.SE] https://arxiv.org/abs/2504.02605
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Srid- har, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Build- ing Autonomous Agents. InInternational Conference on Learning Representa- tions, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.