LASER: A Corrective Lens for LVLMs via Visual Attention Preservation and Sink Suppression
Pith reviewed 2026-07-03 16:51 UTC · model grok-4.3
The pith
LASER uses two rewards to keep large vision-language models focused on visual evidence instead of drifting away during long reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
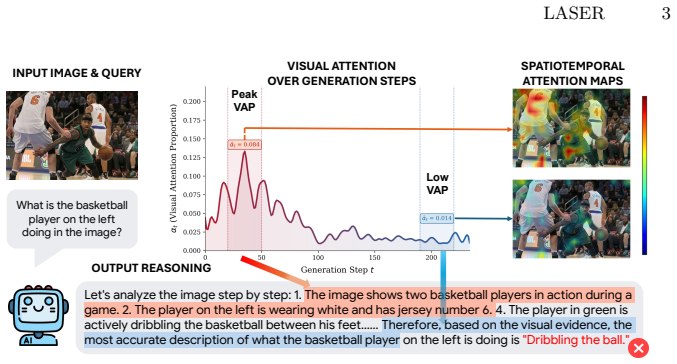
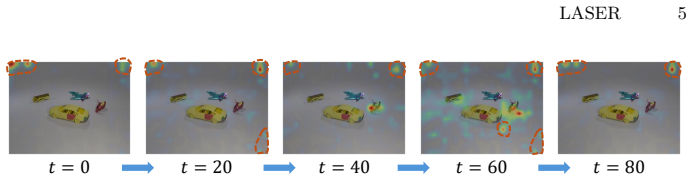
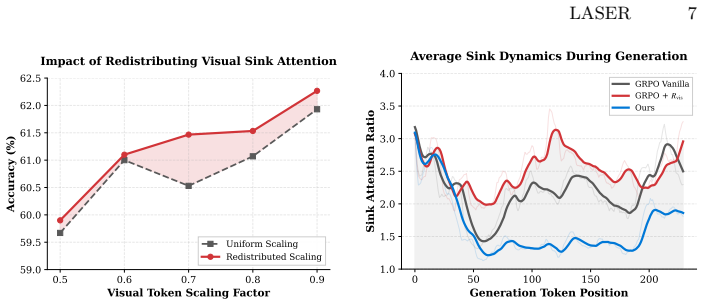
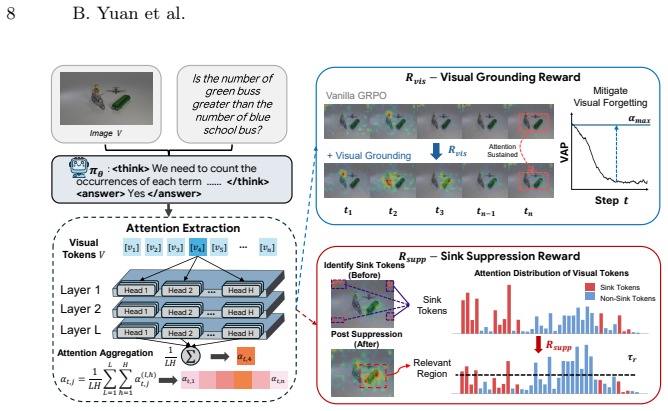
The central claim is that visual forgetting in LVLMs stems mainly from early-stage attention decay that blocks evidence acquisition and from attention concentrating on task-irrelevant visual sink tokens, and that applying a Visual Grounding Reward to maintain attention on salient visual tokens together with a Sink Suppression Reward to penalize excessive concentration on sinks during post-training corrects both issues, preserves the attention trajectory, and raises performance on downstream tasks.
What carries the argument
The pair of Visual Grounding Reward and Sink Suppression Reward that together enforce sustained attention on salient visual tokens and limit collapse onto sink tokens.
If this is right
- The model keeps attention on semantically salient visual tokens across the full decoding sequence.
- Attention no longer collapses onto a small set of task-irrelevant visual sink tokens.
- Performance rises above strong baselines on all eight evaluated benchmark datasets.
- Attention-aware post-training becomes a practical remedy for visual forgetting without altering model architecture.
Where Pith is reading between the lines
- The same reward structure could be tested on models that process longer image sequences or video to check whether early decay is equally dominant.
- Embedding these rewards might reduce reliance on inference-time attention interventions in other multimodal settings.
- The method opens a route to compare attention regularization against data curation as ways to improve grounding.
- If the sink tokens prove consistent across models, a shared suppression term could be developed once rather than per model.
Load-bearing premise
That early attention decay and concentration on sink tokens are the primary drivers of performance loss when visual forgetting occurs.
What would settle it
Training an LVLM with the two rewards yet finding that early-stage attention still decays away from visual tokens or that performance gains disappear on the same eight benchmarks.
Figures






read the original abstract
Large vision-language models (LVLMs) exhibit strong reasoning ability but suffer from visual forgetting during long-horizon decoding, where attention progressively drifts away from visual evidence. Existing methods largely treat this issue as a late-stage attention decay problem or attempt to mitigate it through heuristic reminders or post-hoc attention lifting. Through systematic empirical analysis, we find that performance degradation under visual forgetting is largely driven by two overlooked factors: early-stage attention decay disrupts evidence acquisition, and attention concentration on a subset of task-irrelevant visual sink tokens. Motivated by these insights, we propose LASER, a post-training framework that regulates both the visual attention trajectory and intra-visual token attention distribution during reasoning. Technically, LASER introduces two complementary rewards: a Visual Grounding Reward, which encourages the model to maintain attention on semantically salient visual tokens throughout decoding, and a Sink Suppression Reward, which penalizes excessive attention concentration on visual sink tokens. Together, these rewards preserve early-stage grounding while preventing attention collapse onto uninformative regions. Extensive experiments on eight benchmark datasets demonstrate that LASER consistently outperforms strong baselines, validating attention-aware training as an effective remedy for visual forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual forgetting in LVLMs during long-horizon decoding is largely driven by two factors identified via systematic empirical analysis: early-stage attention decay that disrupts evidence acquisition, and attention concentration on task-irrelevant visual sink tokens. Motivated by this, it introduces LASER, a post-training framework using two rewards—a Visual Grounding Reward to maintain attention on semantically salient visual tokens and a Sink Suppression Reward to penalize excessive concentration on sinks—resulting in consistent outperformance over strong baselines on eight benchmark datasets.
Significance. If the empirical analysis and results hold under scrutiny, the work would demonstrate that attention-aware post-training can effectively mitigate visual forgetting in LVLMs, offering a practical remedy beyond heuristic reminders or post-hoc fixes. The dual-reward design targeting both trajectory and distribution is a targeted contribution if the causal drivers are isolated.
major comments (2)
- [Abstract] Abstract: the central motivation rests on the claim that performance degradation 'is largely driven' by early-stage attention decay and sink concentration, identified through 'systematic empirical analysis.' However, the abstract supplies no description of the analysis (e.g., whether it includes controlled interventions that isolate these factors while holding model, prompt, and decoding fixed, versus purely observational attention-map vs. accuracy correlations). This is load-bearing because the two rewards are directly derived from these factors; if the analysis is only correlational, the rewards may target symptoms rather than primary causes.
- [Abstract] Abstract: the claim of 'consistent outperformance on eight benchmark datasets' is presented without any quantitative results, baseline specifications, ablation studies, dataset sizes, or error analysis. This prevents assessment of effect sizes or whether the gains are robust, directly undermining evaluation of the central claim that the proposed rewards are an 'effective remedy.'
minor comments (1)
- [Abstract] Abstract: 'visual sink tokens' is used without a definition or citation to prior work on attention sinks; this notation should be clarified on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address each major comment point by point below, focusing on the abstract's presentation of our empirical analysis and results. Where revisions to the abstract can improve clarity without exceeding length constraints, we indicate this explicitly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation rests on the claim that performance degradation 'is largely driven' by early-stage attention decay and sink concentration, identified through 'systematic empirical analysis.' However, the abstract supplies no description of the analysis (e.g., whether it includes controlled interventions that isolate these factors while holding model, prompt, and decoding fixed, versus purely observational attention-map vs. accuracy correlations). This is load-bearing because the two rewards are directly derived from these factors; if the analysis is only correlational, the rewards may target symptoms rather than primary causes.
Authors: The abstract is a high-level summary, but the full manuscript details the systematic empirical analysis in Section 3. There, we conduct controlled interventions that hold the model, prompts, and decoding strategy fixed while isolating the effects of early-stage attention decay (via attention trajectory interventions) and sink token concentration (via targeted masking experiments), directly measuring causal impacts on accuracy. This establishes the factors as primary drivers rather than mere correlations, motivating the dual-reward design. We will revise the abstract to briefly note that the analysis involves such controlled interventions. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance on eight benchmark datasets' is presented without any quantitative results, baseline specifications, ablation studies, dataset sizes, or error analysis. This prevents assessment of effect sizes or whether the gains are robust, directly undermining evaluation of the central claim that the proposed rewards are an 'effective remedy.'
Authors: Abstracts are space-constrained and conventionally omit specific numbers, tables, and detailed ablations, which are instead provided in the main text (Section 4, Table 1, and ablation studies in Section 4.3) along with dataset details and error analysis. These elements demonstrate the consistent gains and robustness. We can partially revise the abstract to include one or two key quantitative highlights (e.g., average improvement margins) if space permits, while preserving its summary nature. revision: partial
Circularity Check
No circularity; empirical post-training method with independent motivation
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivations. The two rewards are explicitly introduced as new constructs motivated by (but not defined in terms of) the empirical observations. No self-citation chains, uniqueness theorems, or ansatzes are referenced. The central claim rests on experimental validation rather than any reduction of outputs to inputs by construction. This is the most common honest non-finding for applied post-training papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: NeurIPS (2022)
Alayrac, J., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J.L., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Binkowski, M., Barreira, R., Vinyals, O., Zisserman, A., Si- monyan, K.: Flamingo:...
2022
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. CoRR (2025).https://doi.org/10.48550/ ARXIV.2502.13923,https://doi.org/1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Keysers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A.A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Bosnjak, M., Chen, X., Minderer, M., Voigtlaender, P., Bica, I., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.07726 2024
-
[4]
arXiv preprint arXiv:2502.00698 (2025)
Cai, H., Yang, Y., Hu, W.: Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models. arXiv preprint arXiv:2502.00698 (2025)
-
[5]
Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., et al.: Internlm2 technical report. CoRR (2024),https://doi.org/10.48550/arXiv.2403.17297
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.17297 2024
-
[6]
In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
Chen, J., Tang, J., Qin, J., Liang, X., Liu, L., Xing, E., Lin, L.: Geoqa: A geo- metric question answering benchmark towards multimodal numerical reasoning. In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. pp. 513–523 (2021)
2021
-
[7]
In: ECCV
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: ECCV. pp. 19–35. Springer (2024)
2024
-
[8]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., Zhao, F.: Are we on the right way for evaluating large vision-language models? In: NeurIPS (2024)
2024
-
[9]
ReVisual-R1: An open-source 7B multimodal large language model for deep reasoning
Chen, S., Guo, Y., Su, Z., Li, Y., Wu, Y., Chen, J., Chen, J., Wang, W., Qu, X., Cheng, Y.: Advancing multimodal reasoning: From optimized cold start to staged reinforcement learning. arXiv preprint arXiv:2506.04207 (2025)
-
[10]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q.V., Levine, S., Ma, Y.: Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161 (2025) 16 B. Yuan et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles
Deng, Y., Bansal, H., Yin, F., Peng, N., Wang, W., Chang, K.: Openvlthinker: An early exploration to complex vision-language reasoning via iterative self- improvement. CoRR (2025),https://doi.org/10.48550/arXiv.2503.17352
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.17352 2025
-
[13]
Frontiers of Computer Science (2026)
Du, J., Li, Y., Li, Y., Liao, L., Zhao, Z., Ye, G.: Medfuse: a multi-source data fusion framework for diabetic retinopathy lesion segmentation. Frontiers of Computer Science (2026)
2026
-
[14]
CoRR (2025),https://doi.org/10.48550/arXiv.2501.01904
Du, Y., Liu, Z., Li, Y., Zhao, W.X., Huo, Y., Wang, B., Chen, W., Liu, Z., Wang, Z., Wen, J.: Virgo: A preliminary exploration on reproducing o1-like MLLM. CoRR (2025),https://doi.org/10.48550/arXiv.2501.01904
-
[15]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al.: Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11198–11201 (2024)
2024
-
[16]
com/verl-project/verl(2025)
Engine, V.: verl: Volcano engine reinforcement learning for llms.https://github. com/verl-project/verl(2025)
2025
-
[17]
In: CVPR
Favero, A., Zancato, L., Trager, M., Choudhary, S., Perera, P., Achille, A., Swami- nathan, A., Soatto, S.: Multi-modal hallucination control by visual information grounding. In: CVPR. pp. 14303–14312. IEEE (2024)
2024
-
[18]
In: CVPR (2026)
Fu, Y., Zhang, Z., Zhang, Y., Wang, Z., Huang, Z., Luo, Y.: Mergevla: Cross-skill model merging toward a generalist vision-language-action agent. In: CVPR (2026)
2026
-
[19]
In: EMNLP
Gong, X., Ming, T., Wang, X., Wei, Z.: DAMRO: dive into the attention mechanism of LVLM to reduce object hallucination. In: EMNLP. pp. 7696–7712. Association for Computational Linguistics (2024)
2024
-
[20]
In: CVPR
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: CVPR. IEEE (2024)
2024
-
[21]
In: The Fourteenth International Conference on Learning Representations (ICLR) (2026)
Hao, Z., Li, Z., Li, W., Liu, F., Zhang, M., Li, J.: Echoes as anchors: Probabilistic costs and attention refocusing in llm reasoning. In: The Fourteenth International Conference on Learning Representations (ICLR) (2026)
2026
-
[22]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al.: Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3828–3850 (2024)
2024
-
[23]
In: NeurIPS (2024)
Hu, Y., Shi, W., Fu, X., Roth, D., Ostendorf, M., Zettlemoyer, L., Smith, N.A., Krishna, R.: Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. In: NeurIPS (2024)
2024
-
[24]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y., Lin, S.: Vision-r1: Incentivizing reasoning capability in multimodal large language models. CoRR (2025),https://doi.org/10.48550/arXiv.2503.06749
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.06749 2025
-
[25]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al.: Openai o1 system card. arXiv preprint arXiv:2412.16720 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Jian, P., Wu, J., Sun, W., Wang, C., Ren, S., Zhang, J.: Look again, think slowly: Enhancing visual reflection in vision-language models. CoRR (2025),https://doi. org/10.48550/arXiv.2509.12132 LASER 17
-
[27]
In: ICLR (2025)
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. In: ICLR (2025)
2025
-
[28]
Leng, S., Wang, J., Li, J., Zhang, H., Hu, Z., Zhang, B., Jiang, Y., Zhang, H., Li, X., Bing, L., et al.: Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources. arXiv preprint arXiv:2509.21268 (2025)
-
[29]
In: CVPR
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: CVPR. pp. 13872–13882. IEEE (2024)
2024
-
[30]
Advances in Neural Information Processing Systems (2026)
Li, Q., Zhang, Y., Mai, Z., Chen, Y., Huang, H., Zhang, J., Zhang, Z., Wen, Y., Li, W., Fu, H., et al.: Can large multimodal models understand agricultural scenes? benchmarking with agromind. Advances in Neural Information Processing Systems (2026)
2026
-
[31]
In: ACL (2026)
Li, X., et al.: Llm inductive reasoning through multi-agent enhanced monte carlo tree search. In: ACL (2026)
2026
-
[32]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Li, Z., Yu, W., Huang, C., Liu, R., Liang, Z., Liu, F., Che, J., Yu, D., Boyd- Graber, J.L., Mi, H., Yu, D.: Self-rewarding vision-language model via reasoning decomposition. CoRR (2025),https://doi.org/10.48550/arXiv.2508.19652
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19652 2025
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Lin, Z., Lin, M., Lin, L., Ji, R.: Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 5334–5342 (2025)
2025
-
[34]
In: CVPR
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR. IEEE (2024)
2024
-
[35]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) NeurIPS (2023)
2023
-
[36]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Liu, W., Pan, Q., Zhang, Y., Liu, Z., Wu, J., Zhou, J., Zhou, A., Chen, Q., Jiang, B., He, L.: Cmm-math: A chinese multimodal math dataset to evaluate and enhance the mathematics reasoning of large multimodal models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 12585–12591 (2025)
2025
-
[37]
Liu, Z., Liu, Y., Zhu, G., Xie, C., Li, Z., Yuan, J., Wang, X., Li, Q., Cheung, S.C., Zhang, S., et al.: Infi-mmr: Curriculum-based unlocking multimodal reasoning via phased reinforcement learning in multimodal small language models. arXiv preprint arXiv:2505.23091 (2025)
-
[38]
In: ICLR
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In: ICLR. OpenReview.net (2024)
2024
-
[39]
Lu, P., Gong, R., Jiang, S., Qiu, L., Huang, S., Liang, X., Zhu, S.C.: Inter-gps: In- terpretable geometry problem solving with formal language and symbolic reasoning. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers...
2021
-
[40]
Lu, P., Qiu, L., Chen, J., Xia, T., Zhao, Y., Zhang, W., Yu, Z., Liang, X., Zhu, S.C.: Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. arXiv preprint arXiv:2110.13214 (2021)
-
[41]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Meng, F., Du, L., Liu, Z., Zhou, Z., Lu, Q., Fu, D., Han, T., Shi, B., Wang, W., He, J., et al.: Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning. arXiv preprint arXiv:2503.07365 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
In: AAAI
Mondal, D., Modi, S., Panda, S., Singh, R., Rao, G.S.: Kam-cot: Knowledge augmented multimodal chain-of-thoughts reasoning. In: AAAI. pp. 18798–18806. AAAI Press (2024)
2024
-
[43]
OpenAI: Openai gpt-5 system card (2025),https://arxiv.org/abs/2601.03267 18 B. Yuan et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Qiao, R., Tan, Q., Dong, G., Wu, M., Sun, C., Song, X., Wang, J., Gongque, Z., Lei, S., Zhang, Y., Wei, Z., Zhang, M., Qiao, R., Zong, X., Xu, Y., Yang, P., Bao, Z., Diao, M., Li, C., Zhang, H.: We-math: Does your large multimodal model achieve human-like mathematical reasoning? In: ACL. pp. 20023–20070. Association for Computational Linguistics (2025)
2025
-
[45]
In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (eds.) EMNLP. pp. 4035–4045. Association for Computational Linguistics (2018)
2018
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. CoRR (2024),https://doi.org/10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[47]
CoRR (2025), https://doi.org/10.48550/arXiv.2504
Shen, H., Liu, P., Li, J., Fang, C., Ma, Y., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., Xu, R., Zhao, T.: VLM-R1: A stable and generalizable r1-style large vision-language model. CoRR (2025), https://doi.org/10.48550/arXiv.2504. 07615
-
[48]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Shi, W., Hu, Z., Bin, Y., Liu, J., Yang, Y., Ng, S.K., Bing, L., Lee, R.K.W.: Math- llava: Bootstrapping mathematical reasoning for multimodal large language models. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 4663–4680 (2024)
2024
-
[49]
Sun, H., Sun, Z., Peng, H., Ye, H.: Mitigating visual forgetting via take-along visual conditioning for multi-modal long cot reasoning. In: ACL. pp. 5158–5171. Association for Computational Linguistics (2025)
2025
-
[50]
arXiv (2024)
Sun, M., et al.: Massive activations in large language models. arXiv (2024)
2024
-
[51]
Team, G.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. CoRRabs/2507.06261 (2025),https://doi.org/10.48550/arXiv.2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[52]
Thawakar, O., Dissanayake, D., More, K.P., Thawkar, R., Heakl, A., Ahsan, N., Li, Y., Zumri, M., Lahoud, J., Anwer, R.M., Cholakkal, H., Laptev, I., Shah, M., Khan, F.S., Khan, S.H.: Llamav-o1: Rethinking step-by-step visual reasoning in llms. In: ACL. pp. 24290–24315. Association for Computational Linguistics (2025)
2025
-
[53]
CoRR (2025),https://doi.org/10.48550/arXiv.2509.25848
Tian,X.,Zou,S.,Yang,Z.,He,M.,Waschkowski,F.,Wesemann,L.,Tu,P.H.,Zhang, J.: More thought, less accuracy? on the dual nature of reasoning in vision-language models. CoRR (2025),https://doi.org/10.48550/arXiv.2509.25848
-
[54]
CoRR (2025),https://doi.org/10.48550/arXiv.2503.08342
Tu, C., Ye, P., Zhou, D., Bai, L., Yu, G., Chen, T., Ouyang, W.: Attention reallocation: Towards zero-cost and controllable hallucination mitigation of mllms. CoRR (2025),https://doi.org/10.48550/arXiv.2503.08342
-
[55]
arXiv preprint arXiv:2506.11595 (2025)
Unsal, M., Akkus, A.: Easyarc: Evaluating vision language models on true visual reasoning. arXiv preprint arXiv:2506.11595 (2025)
-
[56]
When to Commit? Towards Variable-Size Self-Contained Blocks for Discrete Diffusion Language Models
Wang, D., Qiu, R., Huang, Z.: When to commit? towards variable-size self-contained blocks for discrete diffusion language models. arXiv preprint arXiv:2604.23994 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Wang, H., Qu, C., Huang, Z., Chu, W., Lin, F., Chen, W.: Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. CoRR (2025), https://doi.org/10.48550/arXiv.2504.08837
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.08837 2025
-
[58]
In: NeurIPS (2024)
Wang, K., Pan, J., Shi, W., Lu, Z., Ren, H., Zhou, A., Zhan, M., Li, H.: Measuring multimodal mathematical reasoning with math-vision dataset. In: NeurIPS (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Yu, X., Luo, Y., Wang, Z., Zhang, P., Huang, Z.: Language-driven fine-grained retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2682–2692 (2026)
2026
-
[60]
In: Proceedings of LASER 19 the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Wang, Y., Wang, S., Cheng, Q., Fei, Z., Ding, L., Guo, Q., Tao, D., Qiu, X.: Visuo- think: Empowering lvlm reasoning with multimodal tree search. In: Proceedings of LASER 19 the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 21707–21719 (2025)
2025
-
[61]
NeurIPS35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. NeurIPS35, 24824–24837 (2022)
2022
-
[62]
CoRR (2025), https://doi.org/10.48550/arXiv.2502.11740
Wu, J., Xiong, Y., Li, X., Xia, Y., Wang, R., Wang, Y., Yu, T., Kim, S., Rossi, R.A., Yao, L., Shang, J., McAuley, J.J.: Mitigating visual knowledge forgetting in MLLM instruction-tuning via modality-decoupled gradient descent. CoRR (2025), https://doi.org/10.48550/arXiv.2502.11740
-
[63]
Xia, J., Zang, Y., Gao, P., Li, Y., Zhou, K.: Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning. CoRR (2025),https://doi.org/10. 48550/arXiv.2505.14677
-
[64]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Xiao, Y., Sun, E., Liu, T., Wang, W.: Logicvista: Multimodal LLM logical reasoning benchmark in visual contexts. CoRRabs/2407.04973(2024), https://doi.org/ 10.48550/arXiv.2407.04973
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.04973 2024
-
[66]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Xu, G., Jin, P., Li, H., Song, Y., Sun, L., Yuan, L.: Llava-cot: Let vision language models reason step-by-step. CoRR (2024), https://doi.org/10.48550/arXiv. 2411.10440
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[67]
arXiv preprint arXiv:2507.03019 (2025)
Yang, S., Niu, Y., Liu, Y., Ye, Y., Lin, B., Yuan, L.: Look-back: Implicit visual re-focusing in mllm reasoning. arXiv preprint arXiv:2507.03019 (2025)
-
[68]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yang, Y., He, X., Pan, H., Jiang, X., Deng, Y., Yang, X., Lu, H., Yin, D., Rao, F., Zhu, M., Zhang, B., Chen, W.: R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization. CoRR (2025),https://doi.org/10. 48550/arXiv.2503.10615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
arXiv preprint arXiv:2505.16673 (2025)
Yao, H., Yin, Q., Zhang, J., Yang, M., Wang, Y., Wu, W., Su, F., Shen, L., Qiu, M., Tao, D., et al.: R1-sharevl: Incentivizing reasoning capability of multimodal large language models via share-grpo. arXiv preprint arXiv:2505.16673 (2025)
-
[70]
In: Proceedings of the 33rd ACM International Conference on Multimedia (2025)
Yuan,B.,Song,S.,Fernandez,J.,Luo,Y.,Baktashmotlagh,M.,Wang,Z.:Wiswheat: A three-tiered vision-language dataset for wheat management. In: Proceedings of the 33rd ACM International Conference on Multimedia (2025)
2025
-
[71]
In: CVPR
Yue, X., Ni, Y., Zheng, T., Zhang, K., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., Wei, C., Yu, B., Yuan, R., Sun, R., Yin, M., Zheng, B., Yang, Z., Liu, Y., Huang, W., Sun, H., Su, Y., Chen, W.: MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. In: CVPR. pp. 9556–9567. IEEE (2024)
2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, C., Gao, F., Jia, B., Zhu, Y., Zhu, S.C.: Raven: A dataset for relational and analogical visual reasoning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5317–5327 (2019)
2019
-
[73]
Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K., Qiao, Y., Gao, P., Li, H.: MATHVERSE: does your multi-modal LLM truly see the diagrams in visual math problems? In: ECCV. pp. 169–186. Springer (2024)
2024
-
[74]
In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (2025)
Zhao, Z., Chen, Z., Huang, Z., Sadiq, S., Chen, T.: Continual text-to-video retrieval with frame fusion and task-aware routing. In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (2025)
2025
-
[75]
In: NeurIPS (2023) 20 B
Zheng, G., Yang, B., Tang, J., Zhou, H., Yang, S.: Ddcot: Duty-distinct chain- of-thought prompting for multimodal reasoning in language models. In: NeurIPS (2023) 20 B. Yuan et al
2023
-
[76]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., et al.: Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[77]
Zhou, Y., Li, W., Lu, Y., Li, J., Liu, F., Zhang, M., Wang, Y., He, D., LIU, H., Zhang, M.: Reflection on knowledge graph for large language models reasoning. In: Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) (2025) LASER 21 This supplementary material provides additional descriptions of the main paper. It is o...
2025
-
[78]
The image prominently features buses, including a pink double-decker bus in the foreground, which is a clear indicator of public transportation
-
[79]
There are other buses visible in the background, suggesting that the image is related to a scene involving buses
-
[80]
The presence of a car does not overshadow the buses in the image, as the buses are more central and occupy a larger portion of the frame
-
[81]
Considering the options provided: A
The question asks for the main topic, and given the prominence and number of buses in the image, the focus is clearly on buses rather than cars. Considering the options provided: A. Driving cars - This is not the main topic as cars are not the primary focus. B. Driving buses - This could be a strong contender, but the image shows stationary buses rather t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.