MONET: A Massive, Open, Non-redundant and Enriched Text-to-image dataset
Pith reviewed 2026-05-21 05:17 UTC · model grok-4.3
The pith
A 104.9 million pair open dataset, built from 2.9 billion raw images through filtering and re-captioning, supports training of a competitive 4-billion-parameter text-to-image model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, and re-captioning with multiple vision-language models covering short to long-form descriptions, and further augmented with synthetically generated samples, we produce an open dataset of approximately 104.9 million image-text pairs that, when used exclusively to train a 4B-parameter latent diffusion model, yields competitive GenEval and DPG scores.
What carries the argument
The multi-stage curation pipeline of safety filtering, domain filtering, exact and near-duplicate removal, and re-captioning by several vision-language models that converts 2.9 billion raw pairs into a non-redundant, enriched collection of 104.9 million pairs.
If this is right
- Any researcher can download the full dataset under an open license and reproduce large-scale text-to-image training without access to private corpora.
- Pre-computed embeddings and annotations shipped with each image shorten the time needed for downstream experiments and fine-tuning.
- The same curation sequence can be reapplied to future waves of public image data to keep the dataset current.
- Competitive benchmark scores achieved with an exclusively open dataset remove a practical obstacle to community-driven model development.
Where Pith is reading between the lines
- Similar staged curation could be tested on video or audio generation tasks to check whether the same quality gains appear in other modalities.
- The dataset's re-captioning step might be studied to measure how much caption style affects final model behavior on specific prompt types.
- Community extensions could add geographic or cultural tags to the existing annotations to test for improved fairness in generated outputs.
Load-bearing premise
The filtering, deduplication, and multi-model re-captioning steps preserve enough diversity and descriptive quality to train a high-performing model without major loss of information or introduction of new biases.
What would settle it
A direct side-by-side training run of the same 4B-parameter model on a version of the data that skips one or more of the described filtering or re-captioning stages, followed by measurement of the resulting drop in GenEval or DPG scores.
Figures




































read the original abstract
Training large text-to-image models requires high-quality, curated datasets with diverse content and detailed captions. Yet the cost and complexity of collecting, filtering, deduplicating, and re-captioning such corpora at scale hinders open and reproducible research in the field. We introduce MONET, an open Apache 2.0 dataset of approx. 104.9M image--text pairs collected from 2.9B raw pairs across heterogeneous open sources through successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, and re-captioning with multiple vision-language models covering short to long-form descriptions, and further augmented with synthetically generated samples. Each image is shipped with pre-computed embeddings and annotations to accelerate downstream use. To validate the effectiveness of MONET, we train a 4B-parameter latent diffusion model exclusively on it and reach competitive GenEval and DPG scores, demonstrating that our dataset lowers the barrier to large-scale, reproducible text-to-image research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MONET, an open Apache 2.0 dataset of approximately 104.9 million image-text pairs derived from 2.9 billion raw pairs collected from heterogeneous open sources. Construction proceeds through successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, re-captioning with multiple vision-language models (short to long-form), and augmentation with synthetic samples. Each image is accompanied by pre-computed embeddings and annotations. Effectiveness is validated by training a 4B-parameter latent diffusion model exclusively on the final dataset and reporting competitive GenEval and DPG scores, with the goal of lowering barriers to large-scale reproducible text-to-image research.
Significance. If the curation pipeline demonstrably yields a high-quality, diverse corpus without substantial information loss or introduced biases, MONET would constitute a valuable open resource for the computer vision community. It would enable reproducible training of large text-to-image models at scale and reduce dependence on closed datasets. The inclusion of embeddings and annotations further increases practical utility for downstream tasks.
major comments (2)
- [Abstract / Validation section] Abstract and validation experiment: the manuscript states that a 4B-parameter latent diffusion model trained exclusively on MONET reaches competitive GenEval and DPG scores, yet supplies no numerical benchmark values, no baseline comparisons against models trained on other open datasets, and no training hyperparameters or ablation results. This leaves the central effectiveness claim without visible quantitative support.
- [Dataset construction] Dataset construction pipeline: no ablations, retained-concept metrics, or bias measurements are reported that isolate the contribution of safety filtering, domain filtering, deduplication, or multi-VLM re-captioning. Without such controls it is impossible to verify that the successive stages improve quality or diversity rather than merely preserving scale from the 2.9 B starting corpus plus synthetic augmentation.
minor comments (2)
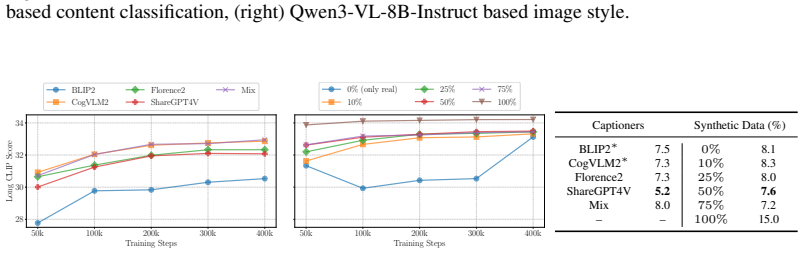
- [Dataset construction] A table summarizing the exact number of pairs retained after each filtering and re-captioning stage would improve transparency and allow readers to assess information loss quantitatively.
- [Dataset construction] Clarify whether the synthetic augmentation samples are generated from the filtered MONET captions or from an external model, and report their proportion in the final 104.9 M set.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address each major comment below with clarifications on the current manuscript content and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Validation section] Abstract and validation experiment: the manuscript states that a 4B-parameter latent diffusion model trained exclusively on MONET reaches competitive GenEval and DPG scores, yet supplies no numerical benchmark values, no baseline comparisons against models trained on other open datasets, and no training hyperparameters or ablation results. This leaves the central effectiveness claim without visible quantitative support.
Authors: We acknowledge that the abstract presents only a high-level statement of competitive performance. The full manuscript reports the specific GenEval and DPG scores achieved by the 4B model in the validation section, along with basic training details. However, we agree that explicit numerical comparisons to models trained on other open datasets (e.g., LAION subsets) and a fuller set of hyperparameters would provide stronger quantitative support. We will revise the validation section and add a comparison table in the next version. revision: yes
-
Referee: [Dataset construction] Dataset construction pipeline: no ablations, retained-concept metrics, or bias measurements are reported that isolate the contribution of safety filtering, domain filtering, deduplication, or multi-VLM re-captioning. Without such controls it is impossible to verify that the successive stages improve quality or diversity rather than merely preserving scale from the 2.9 B starting corpus plus synthetic augmentation.
Authors: We agree that isolating the contribution of each stage via ablations would be valuable. At the scale of the initial 2.9 billion pairs, however, training separate models on every intermediate dataset is computationally prohibitive. The manuscript does include overall statistics on size reduction after deduplication and filtering, as well as diversity indicators. We will expand the construction section with additional retained-concept and bias metrics drawn from our processing logs in the revision. revision: partial
Circularity Check
No circularity; validation uses independent external benchmarks
full rationale
The paper describes a curation pipeline of safety filtering, domain filtering, deduplication and multi-VLM re-captioning applied to 2.9B raw pairs, then trains a 4B LDM exclusively on the resulting 104.9M pairs and reports competitive scores on the standard GenEval and DPG benchmarks. These benchmarks are defined and computed outside the curation process and are not fitted to or defined by any pipeline parameter, so the reported performance constitutes an independent empirical check rather than a quantity that reduces to the inputs by construction. No self-citations, self-definitional loops, fitted predictions, or imported uniqueness theorems appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recaptioning with multiple vision-language models produces accurate, diverse, and unbiased descriptions that improve downstream model performance.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, and re-captioning with multiple vision-language models
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
train a 4B-parameter latent diffusion model exclusively on it and reach competitive GenEval and DPG scores
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fine-tuned vision transformer (vit) for nsfw image classification
Falcon AI. Fine-tuned vision transformer (vit) for nsfw image classification. https://huggingface. co/Falconsai/nsfw_image_detection, 2024. Accessed: 2026-04-16
work page 2024
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[5]
Bumble’s private detector model
Bumble-Tech. Bumble’s private detector model. https://github.com/bumble-ai/nsfw-image-d etection, 2024. Accessed: 2026-04-16
work page 2024
-
[6]
Coyo-700m: Image-text pair dataset.https://github.com/kakaobrain/coyo-dataset, 2022
Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset.https://github.com/kakaobrain/coyo-dataset, 2022
work page 2022
-
[7]
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer.arXiv preprint arXiv:2505.22705, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Extracting training data from diffusion models
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In32nd USENIX security symposium (USENIX Security 23), pages 5253–5270, 2023
work page 2023
-
[9]
Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InCVPR, 2021
work page 2021
-
[10]
Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, YU Jincheng, GE Chongjian, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[11]
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation.arXiv preprint arXiv:2403.04692, 2024
-
[12]
Deep compression autoencoder for efficient high-resolution diffusion models
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[13]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pages 370–387. Springer, 2024
work page 2024
-
[14]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[17]
Redcaps: Web-curated image-text data created by the people, for the people
Karan Desai, Gaurav Kaul, Zubin Trivadi Aysola, and Justin Johnson. Redcaps: Web-curated image-text data created by the people, for the people. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021. URL https://openreview.net/forum?i d=VjJxBi1p9zh. 13
work page 2021
-
[18]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jegou. The faiss library.arXiv preprint arXiv:2401.08281, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander T Toshev, and Vaishaal Shankar. Data filtering networks. InThe Twelfth International Conference on Learning Representations,
-
[21]
URLhttps://openreview.net/forum?id=KAk6ngZ09F
-
[22]
Thomas B Fitzpatrick. The validity and practicality of sun-reactive skin types I through VI.Archives of Dermatology, 124(6):869–871, 1988
work page 1988
-
[23]
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
work page 2023
-
[24]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
work page 2021
-
[26]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132– 52152, 2023
work page 2023
-
[27]
Aaron Gokaslan, A Feder Cooper, Jasmine Collins, Landan Seguin, Austin Jacobson, Mihir Patel, Jonathan Frankle, Cory Stephenson, and V olodymyr Kuleshov. Commoncanvas: An open diffusion model trained with creative-commons images.arXiv preprint arXiv:2310.16825, 2023
-
[28]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, pages 2672–2680, 2014
work page 2014
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
On memorization in diffusion models.Transactions on Machine Learning Research, 2025
Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. On memorization in diffusion models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=D3DBqvSDbj
work page 2025
-
[31]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[32]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
work page 2021
-
[33]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[34]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
CogVLM2: Visual Language Models for Image and Video Understanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, et al. Cogvlm2: Visual language models for image and video understanding. arXiv preprint arXiv:2408.16500, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Scaling up vision-language pre-training for image captioning
Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up vision-language pre-training for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17980–17989, 2022
work page 2022
-
[38]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
work page 2021
-
[41]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultralytics YOLOv8. https://github.com/ultraly tics/ultralytics, 2023
work page 2023
-
[43]
k-mktr. Improved FLUX prompts dataset. https://huggingface.co/datasets/k-mktr/improv ed-flux-prompts, 2024. Accessed: 2026-05-05
work page 2024
-
[44]
Deduplicating training data mitigates privacy risks in language models
Nikhil Kandpal, Eric Wallace, and Colin Raffel. Deduplicating training data mitigates privacy risks in language models. InInternational Conference on Machine Learning, pages 10697–10707. PMLR, 2022
work page 2022
-
[45]
Scaling up gans for text-to-image synthesis
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. Scaling up gans for text-to-image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10124–10134, 2023
work page 2023
-
[46]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Andreas Koukounas, Georgios Mastrapas, Michael Günther, Bo Wang, Scott Martens, Isabelle Mohr, Saba Sturua, Mohammad Kalim Akram, Joan Fontanals Martínez, Saahil Ognawala, et al. jina-clip-v2: Multilingual multimodal embeddings for text and images.arXiv preprint arXiv:2412.08802, 2024
-
[48]
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123(1):32–73, 2017
work page 2017
-
[49]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[50]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
work page 2025
-
[51]
Releasing re-laion-5b: transparent iteration on laion-5b with additional safety fixes
LAION. Releasing re-laion-5b: transparent iteration on laion-5b with additional safety fixes. https: //laion.ai/blog/relaion-5b/, 2024. Accessed: 30 aug, 2024
work page 2024
-
[52]
LAION-AI. Aesthetic predictor. https://github.com/christophschuhmann/improved-aesthet ic-predictor, 2022. Accessed: 2026-04-03
work page 2022
-
[53]
Deduplicating training data makes language models better
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language models better. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8424–8445, 2022
work page 2022
-
[54]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi. Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation.arXiv preprint arXiv:2402.17245, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[56]
vunderstanding and generation with masked discrete diffusion.arXiv preprint arXiv:2603.06577, 2026
Lijiang Li, Zuwei Long, Yunhang Shen, Heting Gao, Haoyu Cao, Xing Sun, Caifeng Shan, Ran He, and Chaoyou Fu. vunderstanding and generation with masked discrete diffusion.arXiv preprint arXiv:2603.06577, 2026. 15
-
[57]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding.arXiv preprint arXiv:2405.08748, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
work page 2014
-
[59]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[60]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[62]
MediaPipe: A Framework for Building Perception Pipelines
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. MediaPipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[63]
v: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. v: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7739–7751, 2025
work page 2025
-
[64]
OpenAI. Gpt-image-1, 2025. URL https://openai.com/zh-Hans-CN/index/introducing-4 o-image-generation/
work page 2025
-
[65]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
work page 2024
-
[66]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[67]
A self- supervised descriptor for image copy detection.Proc
Ed Pizzi, Sreya Dutta Roy, Sugosh Nagavara Ravindra, Priya Goyal, and Matthijs Douze. A self- supervised descriptor for image copy detection.Proc. CVPR, 2022
work page 2022
-
[68]
SSCD: A self-supervised descriptor for image copy detection – code and pretrained models
Ed Pizzi, Sreya Dutta Roy, Sugosh Nagavara Ravindra, Priya Goyal, and Matthijs Douze. SSCD: A self-supervised descriptor for image copy detection – code and pretrained models. https://github.c om/facebookresearch/sscd-copy-detection, 2022. Accessed: 2026-04-23
work page 2022
-
[69]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[70]
Lumina-image 2.0: A unified and efficient image generative framework
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Xinyue Li, Dongyang Liu, Xiangyang Zhu, et al. Lumina-image 2.0: A unified and efficient image generative framework. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20031–20042, 2025
work page 2025
-
[71]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[72]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[73]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
work page 2021
-
[74]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022. 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[75]
Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion
Anton Razzhigaev, Arseniy Shakhmatov, Anastasia Maltseva, Vladimir Arkhipkin, Igor Pavlov, Ilya Ryabov, Angelina Kuts, Alexander Panchenko, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Sys...
work page 2023
-
[76]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InCVPR, pages 779–788, 2016
work page 2016
-
[77]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[78]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015
work page 2015
-
[79]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
work page 2022
-
[80]
Stylegan-t: Unlocking the power of gans for fast large-scale text-to-image synthesis
Axel Sauer, Tero Karras, Samuli Laine, Andreas Geiger, and Timo Aila. Stylegan-t: Unlocking the power of gans for fast large-scale text-to-image synthesis. InInternational conference on machine learning, pages 30105–30118. PMLR, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.