Learning Process Rewards via Success Visitation Matching for Efficient RL
Pith reviewed 2026-06-26 09:18 UTC · model grok-4.3
The pith
A discriminator trained on successful versus unsuccessful episodes generates dense process rewards that accelerate RL while preserving the original optimal policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a discriminator to distinguish successful from unsuccessful episodes and deriving a reward from the discriminator that encourages the policy to match the state-action visitations of successful episodes, a sparse outcome reward can be converted into a dense process reward that supplies useful learning signal at every step while leaving the optimal policy for the original task unchanged.
What carries the argument
Success visitation matching reward produced by the discriminator, which scores how closely current state-action pairs resemble those from successful episodes.
If this is right
- The learned reward supplies progress feedback at every state visited, not only at task completion.
- Finetuning of robotic control policies reaches target performance in fewer episodes than sparse-reward baselines.
- The same optimal policy remains optimal after the reward transformation.
- The approach applies to both simulated and real-world manipulation tasks.
Where Pith is reading between the lines
- Periodic retraining of the discriminator may be needed once the policy begins to produce many new successful trajectories.
- The same visitation-matching idea could be tested in non-robotic sparse-reward domains such as navigation or game environments.
- If the discriminator is replaced by a learned model of successful state distributions, similar dense rewards might be obtained without explicit episode labeling.
Load-bearing premise
A discriminator fit to a fixed collection of earlier episodes will keep supplying an unbiased and useful visitation signal even as the policy distribution shifts during training.
What would settle it
An experiment in which a policy trained with the derived reward converges to a different set of behaviors than one trained directly on the original sparse reward, or shows no speed-up in reaching the same success rate.
Figures


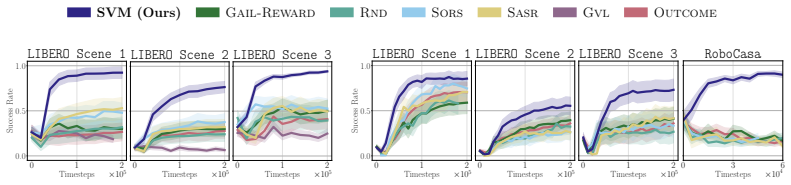
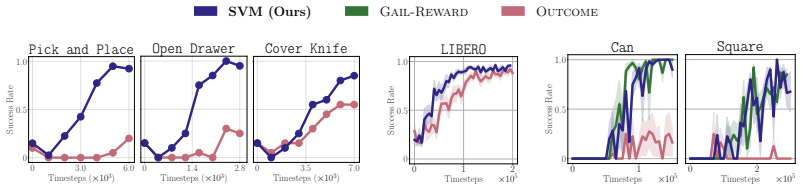

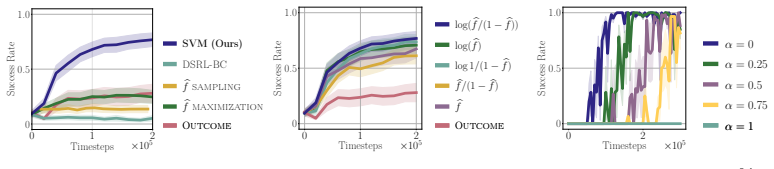





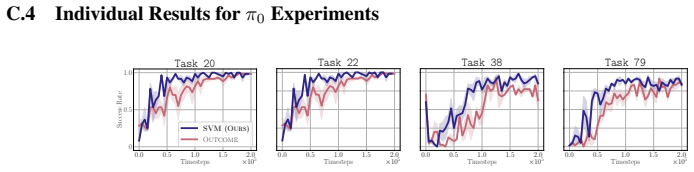




read the original abstract
In many modern applications of reinforcement learning (RL), the natural reward for a task of interest is inherently sparse: a reward of 0 is given everywhere except when the task is completed, when a reward of +1 is given. Training a policy to maximize such a sparse reward requires solving a challenging credit assignment problem, leading to slow or ineffective RL improvement. We propose a simple approach to transform a sparse outcome reward into a dense process reward. Our approach relies on training a discriminator to distinguish between previous successful and unsuccessful episodes, and using this discriminator to incentivize the RL-learned policy to match the state-action visitations of successful episodes, while avoiding those of unsuccessful episodes. By incentivizing the policy to match the visitations over all states, not just those that correspond to task success, this reward provides dense feedback on whether progress is being made towards task completion, and, we show, provably achieves this without changing the optimal policy. Focusing on finetuning of robotic control policies, we demonstrate that our approach leads to significantly faster RL finetuning performance on both simulated and real-world manipulation tasks, as compared to simply maximizing the sparse outcome reward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Success Visitation Matching (SVM), a technique to derive dense process rewards from sparse outcome rewards in RL. A discriminator is trained to differentiate successful from unsuccessful episodes, and its output is used to encourage the policy to replicate the state-action visitations of successful trajectories. The authors assert that this yields dense signals for progress toward task completion while provably leaving the optimal policy unchanged, and report improved finetuning performance on simulated and physical robotic manipulation tasks.
Significance. Should the theoretical guarantee extend to the online setting where the discriminator is periodically retrained, the approach could meaningfully advance efficient RL for sparse-reward problems in robotics by providing a simple, dense reward signal without altering the underlying objective. The combination of a claimed proof and real-robot experiments is a strength, though verification of the former is essential.
major comments (2)
- [Abstract and theoretical analysis] The abstract and theoretical analysis claim that the visitation-matching reward 'provably achieves this without changing the optimal policy.' This guarantee is typically shown via potential-based shaping for a fixed discriminator D. The method, however, retrains the discriminator on newly collected successful/unsuccessful episodes, making the reward non-stationary; the standard argument therefore does not directly apply and the central optimality claim requires an explicit extension or qualification.
- [Method and algorithm description] The algorithm description states that the discriminator is trained on previous episodes and used to shape rewards during RL. No analysis is provided on how the visitation-matching signal behaves under the shifting policy distribution, which directly affects whether the dense feedback remains useful and unbiased—the weakest assumption underlying both the proof and the reported empirical gains.
minor comments (1)
- [Abstract] The abstract could more precisely state the conditions under which the optimality result holds (fixed vs. retrained discriminator).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the theoretical claims and method details. We address each major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis] The abstract and theoretical analysis claim that the visitation-matching reward 'provably achieves this without changing the optimal policy.' This guarantee is typically shown via potential-based shaping for a fixed discriminator D. The method, however, retrains the discriminator on newly collected successful/unsuccessful episodes, making the reward non-stationary; the standard argument therefore does not directly apply and the central optimality claim requires an explicit extension or qualification.
Authors: The theoretical analysis establishes optimality preservation using potential-based shaping for a fixed discriminator D. We agree that periodic retraining renders the reward non-stationary, so the standard argument does not directly extend to the full online procedure. We will revise the abstract and theoretical section to explicitly qualify the claim, noting that the guarantee applies for fixed D while the online setting with retraining is supported by the empirical results on robotic tasks. revision: yes
-
Referee: [Method and algorithm description] The algorithm description states that the discriminator is trained on previous episodes and used to shape rewards during RL. No analysis is provided on how the visitation-matching signal behaves under the shifting policy distribution, which directly affects whether the dense feedback remains useful and unbiased—the weakest assumption underlying both the proof and the reported empirical gains.
Authors: The manuscript does not provide a formal analysis of the visitation-matching signal under shifting policy distributions. We will add a discussion paragraph in the method section addressing this assumption and its relation to the observed empirical gains in both simulated and real-robot experiments. revision: partial
- Extension of the optimality proof to the online setting with periodically retrained discriminator
Circularity Check
No circularity: optimality claim rests on external potential-based shaping theorem applied to independently defined reward
full rationale
The paper defines the process reward from a discriminator trained on observed successful/unsuccessful episodes to encourage visitation matching. The provable optimality preservation is obtained by showing the shaped reward matches the form of potential-based shaping (a standard external result), which holds for any fixed potential function and does not reduce to the discriminator parameters or training procedure by construction. No self-citation is load-bearing for the central theorem, no fitted quantity is relabeled as a prediction, and the derivation chain remains self-contained against the external shaping theorem and the data-driven discriminator.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bootstrapped reward shaping
Jacob Adamczyk, V olodymyr Makarenko, Stas Tiomkin, and Rahul V Kulkarni. Bootstrapped reward shaping. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 15302–15310, 2025
2025
-
[2]
Minttu Alakuijala, Reginald McLean, Isaac Woungang, Nariman Farsad, Samuel Kaski, Pekka Marttinen, and Kai Yuan. Video-language critic: Transferable reward functions for language- conditioned robotics.arXiv preprint arXiv:2405.19988, 2024
arXiv 2024
-
[3]
π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[4]
Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020
OpenAI: Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob Mc- Grew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020
2020
-
[5]
From imitation to refinement-residual rl for precise assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement-residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
2025
-
[6]
Update-free on-policy steering via verifiers
Maria Attarian, Ian Vyse, Claas V oelcker, Jasper Gerigk, Evgenii Opryshko, Anas Almasri, Sumeet Singh, Yilun Du, and Igor Gilitschenski. Update-free on-policy steering via verifiers. arXiv preprint arXiv:2603.10282, 2026
Pith/arXiv arXiv 2026
-
[7]
Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine
Philip J. Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data, 2023. URLhttps://arxiv.org/abs/2302.02948
arXiv 2023
-
[8]
Vision- language models as a source of rewards.arXiv preprint arXiv:2312.09187, 2023
Kate Baumli, Satinder Baveja, Feryal Behbahani, Harris Chan, Gheorghe Comanici, Sebastian Flennerhag, Maxime Gazeau, Kristian Holsheimer, Dan Horgan, Michael Laskin, et al. Vision- language models as a source of rewards.arXiv preprint arXiv:2312.09187, 2023
arXiv 2023
-
[9]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[10]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[11]
Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
Pith/arXiv arXiv 2018
-
[12]
Annie S Chen, Suraj Nair, and Chelsea Finn. Learning generalizable robotic reward functions from" in-the-wild" human videos.arXiv preprint arXiv:2103.16817, 2021
arXiv 2021
-
[13]
Qianzhong Chen, Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, and Philipp Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation.arXiv preprint arXiv:2509.25358, 2025
Pith/arXiv arXiv 2025
-
[14]
Yuhui Chen, Shuai Tian, Shugao Liu, Yingting Zhou, Haoran Li, and Dongbin Zhao. Con- rft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[15]
Process reward models for llm agents: Practical framework and directions
Sanjiban Choudhury. Process reward models for llm agents: Practical framework and directions. arXiv preprint arXiv:2502.10325, 2025. 11
arXiv 2025
-
[16]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[17]
Process reinforcement through implicit rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
Pith/arXiv arXiv 2025
-
[18]
The ingredients for robotic diffusion transformers, 2024
Sudeep Dasari, Oier Mees, Sebastian Zhao, Mohan Kumar Srirama, and Sergey Levine. The ingredients for robotic diffusion transformers, 2024. URL https://arxiv.org/abs/2410. 10088
2024
-
[19]
Bert: Pre-training of deep bidirectional transformers for language understanding, 2019
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019. URLhttps://arxiv.org/ abs/1810.04805
Pith/arXiv arXiv 2019
-
[20]
Expo: Stable reinforcement learning with expressive policies.arXiv preprint arXiv:2507.07986, 2025
Perry Dong, Qiyang Li, Dorsa Sadigh, and Chelsea Finn. Expo: Stable reinforcement learning with expressive policies.arXiv preprint arXiv:2507.07986, 2025
Pith/arXiv arXiv 2025
-
[21]
Perry Dong, Suvir Mirchandani, Dorsa Sadigh, and Chelsea Finn. What matters for batch online reinforcement learning in robotics?arXiv preprint arXiv:2505.08078, 2025
arXiv 2025
-
[22]
Vision-language models as success detectors.arXiv preprint arXiv:2303.07280, 2023
Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando De Freitas, and Serkan Cabi. Vision-language models as success detectors.arXiv preprint arXiv:2303.07280, 2023
arXiv 2023
-
[23]
Adversarial intrinsic motivation for reinforcement learning.Advances in Neural Information Processing Systems, 34:8622–8636, 2021
Ishan Durugkar, Mauricio Tec, Scott Niekum, and Peter Stone. Adversarial intrinsic motivation for reinforcement learning.Advances in Neural Information Processing Systems, 34:8622–8636, 2021
2021
-
[24]
Chelsea Finn, Paul Christiano, Pieter Abbeel, and Sergey Levine. A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models. arXiv preprint arXiv:1611.03852, 2016
Pith/arXiv arXiv 2016
-
[25]
Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adversarial inverse reinforcement learning.arXiv preprint arXiv:1710.11248, 2017
Pith/arXiv arXiv 2017
-
[26]
Variational inverse control with events: A general framework for data-driven reward definition.Advances in neural information processing systems, 31, 2018
Justin Fu, Avi Singh, Dibya Ghosh, Larry Yang, and Sergey Levine. Variational inverse control with events: A general framework for data-driven reward definition.Advances in neural information processing systems, 31, 2018
2018
-
[27]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[28]
Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen-Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision-language-action model with online reinforcement learning.arXiv preprint arXiv:2501.16664, 2025
arXiv 2025
-
[29]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[30]
Few-shot preference learning for human-in-the-loop rl
Donald Joseph Hejna III and Dorsa Sadigh. Few-shot preference learning for human-in-the-loop rl. InConference on Robot Learning, pages 2014–2025. PMLR, 2023
2014
-
[31]
Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
2016
-
[32]
Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning
Jiaheng Hu, Rose Hendrix, Ali Farhadi, Aniruddha Kembhavi, Roberto Martín-Martín, Peter Stone, Kuo-Hao Zeng, and Kiana Ehsani. Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3617–3624. IEEE, 2025. 12
2025
-
[33]
Residual reinforcement learning for robot control, 2018
Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, and Sergey Levine. Residual reinforcement learning for robot control, 2018. URLhttps://arxiv.org/abs/1812.03201
Pith/arXiv arXiv 2018
-
[34]
Tobias Jülg, Wolfram Burgard, and Florian Walter. Refined policy distillation: From vla generalists to rl experts.arXiv preprint arXiv:2503.05833, 2025
arXiv 2025
-
[35]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[36]
Affordance-guided reinforcement learning via visual prompting.arXiv preprint arXiv:2407.10341, 2024
Olivia Y Lee, Annie Xie, Kuan Fang, Karl Pertsch, and Chelsea Finn. Affordance-guided reinforcement learning via visual prompting.arXiv preprint arXiv:2407.10341, 2024
arXiv 2024
-
[37]
Tony Lee, Andrew Wagenmaker, Karl Pertsch, Percy Liang, Sergey Levine, and Chelsea Finn. Roboreward: General-purpose vision-language reward models for robotics.arXiv preprint arXiv:2601.00675, 2026
arXiv 2026
-
[38]
Learning to coordinate manipulation skills via skill behavior diversification
Youngwoon Lee, Jingyun Yang, and Joseph J Lim. Learning to coordinate manipulation skills via skill behavior diversification. InInternational conference on learning representations, 2019
2019
-
[39]
End-to-end training of deep visuomotor policies.Journal of Machine Learning Research, 17(39):1–40, 2016
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies.Journal of Machine Learning Research, 17(39):1–40, 2016
2016
-
[40]
Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection
Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. The International journal of robotics research, 37(4-5):421–436, 2018
2018
-
[41]
Mural: Meta-learning uncertainty-aware rewards for outcome-driven reinforcement learning
Kevin Li, Abhishek Gupta, Ashwin Reddy, Vitchyr H Pong, Aurick Zhou, Justin Yu, and Sergey Levine. Mural: Meta-learning uncertainty-aware rewards for outcome-driven reinforcement learning. InInternational conference on machine learning, pages 6346–6356. PMLR, 2021
2021
-
[42]
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S Huang, Luke Zettlemoyer, Dieter Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
Pith/arXiv arXiv 2026
-
[43]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[44]
Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https: //arxiv.org/abs/2306.03310
Pith/arXiv arXiv 2023
-
[45]
What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789, 2025
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789, 2025
arXiv 2025
-
[46]
Guanxing Lu, Wenkai Guo, Chubin Zhang, Yuheng Zhou, Haonan Jiang, Zifeng Gao, Yansong Tang, and Ziwei Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
Pith/arXiv arXiv 2025
-
[47]
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical rea- soning for large language models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583, 2023
Pith/arXiv arXiv 2023
-
[48]
Serl: A software suite for sample- efficient robotic reinforcement learning
Jianlan Luo, Zheyuan Hu, Charles Xu, You Liang Tan, Jacob Berg, Archit Sharma, Stefan Schaal, Chelsea Finn, Abhishek Gupta, and Sergey Levine. Serl: A software suite for sample- efficient robotic reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024. 13
2024
-
[49]
Precise and dexterous robotic manip- ulation via human-in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
Jianlan Luo, Charles Xu, Jeffrey Wu, and Sergey Levine. Precise and dexterous robotic manip- ulation via human-in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[50]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
Pith/arXiv arXiv 2024
-
[51]
Tung Minh Luu, Younghwan Lee, Donghoon Lee, Sunho Kim, Min Jun Kim, and Chang D Yoo. Enhancing rating-based reinforcement learning to effectively leverage feedback from large vision-language models.arXiv preprint arXiv:2506.12822, 2025
arXiv 2025
-
[52]
Haozhe Ma, Zhengding Luo, Thanh Vinh V o, Kuankuan Sima, and Tze-Yun Leong. Highly effi- cient self-adaptive reward shaping for reinforcement learning.arXiv preprint arXiv:2408.03029, 2024
arXiv 2024
-
[53]
Reward shaping for reinforcement learning with an assistant reward agent
Haozhe Ma, Kuankuan Sima, Thanh Vinh V o, Di Fu, and Tze-Yun Leong. Reward shaping for reinforcement learning with an assistant reward agent. InForty-first international conference on machine learning, 2024
2024
-
[54]
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
Pith/arXiv arXiv 2022
-
[55]
Liv: Language-image representations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language-image representations and rewards for robotic control. InInternational Conference on Machine Learning, pages 23301–23320. PMLR, 2023
2023
-
[56]
Vision language models are in-context value learners
Yecheng Jason Ma, Joey Hejna, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, et al. Vision language models are in-context value learners. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[57]
What matters in learning from offline human demonstrations for robot manipulation, 2021
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation, 2021. URL https://arxiv.org/ abs/2108.03298
Pith/arXiv arXiv 2021
-
[58]
Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, and Aviral Kumar. Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone.arXiv preprint arXiv:2412.06685, 2024
arXiv 2024
-
[59]
Self- supervised online reward shaping in sparse-reward environments
Farzan Memarian, Wonjoon Goo, Rudolf Lioutikov, Scott Niekum, and Ufuk Topcu. Self- supervised online reward shaping in sparse-reward environments. In2021 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 2369–2375. IEEE, 2021
2021
-
[60]
Russell Mendonca, Emmanuel Panov, Bernadette Bucher, Jiuguang Wang, and Deepak Pathak. Continuously improving mobile manipulation with autonomous real-world rl.arXiv preprint arXiv:2409.20568, 2024
arXiv 2024
-
[61]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816, 2024
arXiv 2024
-
[62]
Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024. URLhttps://arxiv.org/abs/2406.02523
Pith/arXiv arXiv 2024
-
[63]
Policy invariance under reward transforma- tions: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InIcml, volume 99, pages 278–287. Citeseer, 1999
1999
-
[64]
Deep exploration via bootstrapped dqn.Advances in neural information processing systems, 29, 2016
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped dqn.Advances in neural information processing systems, 29, 2016. 14
2016
-
[65]
Malayandi Palan, Nicholas C Landolfi, Gleb Shevchuk, and Dorsa Sadigh. Learning reward func- tions by integrating human demonstrations and preferences.arXiv preprint arXiv:1906.08928, 2019
Pith/arXiv arXiv 1906
-
[66]
Jongjin Park, Younggyo Seo, Jinwoo Shin, Honglak Lee, Pieter Abbeel, and Kimin Lee. Surf: Semi-supervised reward learning with data augmentation for feedback-efficient preference-based reinforcement learning.arXiv preprint arXiv:2203.10050, 2022
arXiv 2022
-
[67]
Curiosity-driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InInternational conference on machine learning, pages 2778–
-
[68]
Yuxiao Qu, Matthew YR Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, and Aviral Kumar. Optimizing test-time compute via meta reinforcement fine-tuning.arXiv preprint arXiv:2503.07572, 2025
arXiv 2025
-
[69]
Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
Pith/arXiv arXiv 2024
-
[70]
Reinforcement learning for robot soccer.Autonomous Robots, 27(1):55–73, 2009
Martin Riedmiller, Thomas Gabel, Roland Hafner, and Sascha Lange. Reinforcement learning for robot soccer.Autonomous Robots, 27(1):55–73, 2009
2009
-
[71]
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. Vision- language models are zero-shot reward models for reinforcement learning.arXiv preprint arXiv:2310.12921, 2023
arXiv 2023
-
[72]
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning.arXiv preprint arXiv:2410.08146, 2024
Pith/arXiv arXiv 2024
-
[73]
Concept2robot: Learning manipulation concepts from instructions and human demonstrations.The International Journal of Robotics Research, 40(12-14):1419–1434, 2021
Lin Shao, Toki Migimatsu, Qiang Zhang, Karen Yang, and Jeannette Bohg. Concept2robot: Learning manipulation concepts from instructions and human demonstrations.The International Journal of Robotics Research, 40(12-14):1419–1434, 2021
2021
-
[74]
Legged robots that keep on learning: Fine-tuning locomotion policies in the real world
Laura Smith, J Chase Kew, Xue Bin Peng, Sehoon Ha, Jie Tan, and Sergey Levine. Legged robots that keep on learning: Fine-tuning locomotion policies in the real world. In2022 international conference on robotics and automation (ICRA), pages 1593–1599. IEEE, 2022
2022
-
[75]
Laura Smith, Ilya Kostrikov, and Sergey Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning.arXiv preprint arXiv:2208.07860, 2022
arXiv 2022
-
[76]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[77]
Roboclip: One demonstration is enough to learn robot policies.Advances in Neural Information Processing Systems, 36:55681–55693, 2023
Sumedh Sontakke, Jesse Zhang, Séb Arnold, Karl Pertsch, Erdem Bıyık, Dorsa Sadigh, Chelsea Finn, and Laurent Itti. Roboclip: One demonstration is enough to learn robot policies.Advances in Neural Information Processing Systems, 36:55681–55693, 2023
2023
-
[78]
Learning intrinsic rewards as a bi-level optimiza- tion problem
Bradly Stadie, Lunjun Zhang, and Jimmy Ba. Learning intrinsic rewards as a bi-level optimiza- tion problem. InConference on Uncertainty in Artificial Intelligence, pages 111–120. PMLR, 2020
2020
-
[79]
Huajie Tan, Sixiang Chen, Yijie Xu, Zixiao Wang, Yuheng Ji, Cheng Chi, Yaoxu Lyu, Zhongxia Zhao, Xiansheng Chen, Peterson Co, Shaoxuan Xie, Guocai Yao, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Robo-dopamine: General process reward modeling for high- precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[80]
# exploration: A study of count-based exploration for deep reinforcement learning.Advances in neural information processing systems, 30, 2017
Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, OpenAI Xi Chen, Yan Duan, John Schulman, Filip DeTurck, and Pieter Abbeel. # exploration: A study of count-based exploration for deep reinforcement learning.Advances in neural information processing systems, 30, 2017. 15
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.