COMBINER: Composed Image Retrieval Guided by Attribute-based Neighbor Relations
Pith reviewed 2026-06-28 06:40 UTC · model grok-4.3
The pith
COMBINER improves composed image retrieval by using attribute prototypes to address visually similar but attribute-unrelated samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
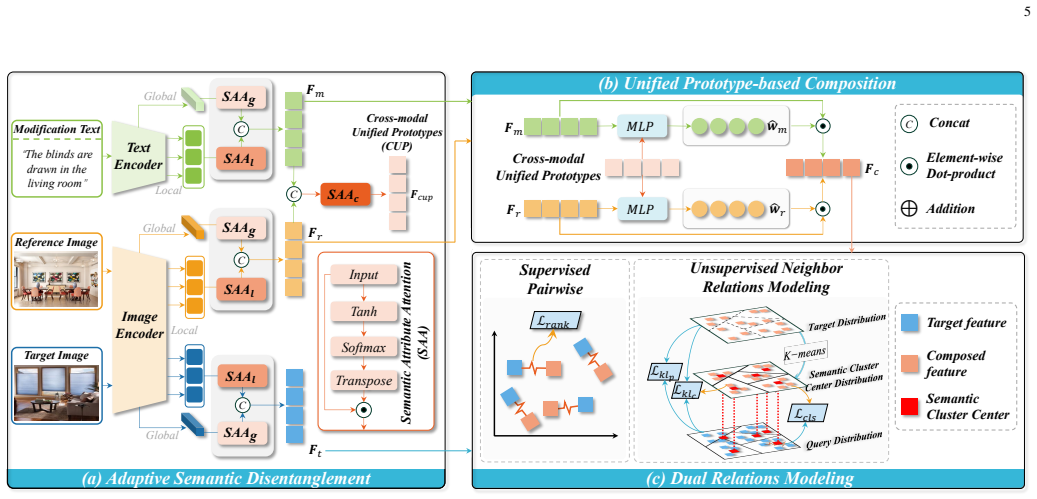
COMBINER represents the first study addressing visually similar but attribute-unrelated samples in composed image retrieval. It achieves this by an attribute prototype-based similarity metric that mines dual relations, implemented through Adaptive Semantic Disentanglement for separating attribute features, Unified Prototype-based Composition for building cross-modal unified prototypes, and Dual Relations Modeling for capturing attribute-based pairwise and neighbor relations.
What carries the argument
Attribute prototype-based similarity metric in the Dual Relations Modeling module, which distinguishes samples by attribute similarity rather than visual appearance alone.
Load-bearing premise
The three core issues of attribute entanglement, modality inconsistency, and missing supervision can be resolved by the three modules without external supervision or new inconsistencies.
What would settle it
A test set of image pairs that are visually similar but differ in attributes, where retrieval accuracy does not exceed that of baseline methods using standard visual or text similarity.
Figures





read the original abstract
Composed Image Retrieval (CIR) represents a challenging retrieval task that targets locating specific images through multimodal inputs. Despite recent progress in CIR techniques, prior approaches often overlook cases where images appear visually alike yet differ in attributes, potentially undermining both multimodal feature fusion and similarity modeling. To mitigate this limitation, we design a unified representation of cross-modal features based on attribute prototypes. Nevertheless, the task is far from straightforward, owing to three core issues: (1) entanglement in attribute-level semantics, (2) inconsistency across modalities, and (3) supervised signal missing. To tackle the above obstacles, we introduce a COMposed image retrieval network guided By attrIbute-based NEighbor Relations (COMBINER). Specifically, we first design an Adaptive Semantic Disentanglement module, which is capable of disentangling attribute features based on multimodal primitive features. Secondly, we propose a Unified Prototype-based Composition module, which can construct cross-modal unified prototypes (CUP) and facilitate multimodal feature composition. Finally, we introduce a Dual Relations Modeling module, which can mine pairwise and neighbor relations based on attribute similarity. Compared to traditional neighbor relations modeling CIR methods, COMBINER represents the first study addressing the phenomenon of visually similar but attribute-unrelated samples. It achieves a more accurate understanding of the semantic relations among samples by employing an attribute prototype-based similarity metric. Comprehensive experiments conducted on three benchmark datasets confirm the effectiveness of our proposed COMBINER. The implementation of our method will be accessed at https://github.com/Lee-zixu/COMBINER
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes COMBINER, a composed image retrieval (CIR) network that targets the phenomenon of visually similar but attribute-unrelated samples. It introduces an attribute-prototype representation and three modules—Adaptive Semantic Disentanglement, Unified Prototype-based Composition (constructing cross-modal unified prototypes), and Dual Relations Modeling (mining pairwise and neighbor relations via attribute similarity)—to address attribute-level entanglement, cross-modal inconsistency, and missing supervision signals. The work claims to be the first to explicitly handle this phenomenon via an attribute prototype-based similarity metric and reports effectiveness on three benchmark datasets, with code to be released.
Significance. If the modules deliver disentanglement and unified prototypes that improve semantic relation modeling without new inconsistencies, the approach could advance CIR by providing a more accurate handling of attribute differences in visually similar images. The explicit code release is a strength for reproducibility.
major comments (3)
- [Abstract, §3] Abstract and §3: The central claim that the three modules jointly resolve the three core issues (entanglement, inconsistency, missing signals) without introducing new modality conflicts or implicit supervision is load-bearing for the 'first study' assertion, yet the manuscript provides only high-level module descriptions with no equations, loss terms, or architectural constraints shown to guarantee the promised disentanglement and unified prototypes (CUP).
- [§3.3] §3.3 (Dual Relations Modeling): The attribute prototype-based similarity metric is presented as enabling more accurate neighbor relations than traditional methods, but without the explicit definition or derivation of how this metric differs from the attribute prototypes themselves, it is unclear whether reported gains reduce to the prototype construction rather than new relational modeling.
- [Experiments] Experiments section: The claim of effectiveness on three benchmarks is asserted, but without ablations isolating each module's contribution to the three core issues (or controls for whether the modules introduce cross-modal inconsistencies), the support for the central performance claims remains incomplete.
minor comments (1)
- [Abstract] The abstract states 'The implementation of our method will be accessed at https://github.com/Lee-zixu/COMBINER' but the manuscript should include a direct link or DOI in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional technical detail and experimental rigor will strengthen the manuscript. We address each major comment below and commit to revisions that provide the requested equations, derivations, and ablations while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract and §3: The central claim that the three modules jointly resolve the three core issues (entanglement, inconsistency, missing signals) without introducing new modality conflicts or implicit supervision is load-bearing for the 'first study' assertion, yet the manuscript provides only high-level module descriptions with no equations, loss terms, or architectural constraints shown to guarantee the promised disentanglement and unified prototypes (CUP).
Authors: We agree that the current high-level descriptions are insufficient to fully substantiate the joint resolution of the three issues. In the revised manuscript we will insert the full mathematical formulations for Adaptive Semantic Disentanglement (including the disentanglement loss and attribute-level constraints), the construction of cross-modal unified prototypes (CUP) with its composition equations, and the overall training objective. We will also add explicit architectural constraints and a short analysis showing that the modules do not introduce new cross-modal inconsistencies or rely on implicit supervision beyond the provided attribute labels. revision: yes
-
Referee: §3.3 (Dual Relations Modeling): The attribute prototype-based similarity metric is presented as enabling more accurate neighbor relations than traditional methods, but without the explicit definition or derivation of how this metric differs from the attribute prototypes themselves, it is unclear whether reported gains reduce to the prototype construction rather than new relational modeling.
Authors: We will revise §3.3 to include the precise definition of the attribute prototype-based similarity metric, its derivation from the unified prototypes, and a clear separation between the prototype construction step and the subsequent pairwise/neighbor relation modeling. This will demonstrate that the metric incorporates both attribute similarity and neighbor structure in a manner distinct from the prototypes used for composition alone. revision: yes
-
Referee: Experiments section: The claim of effectiveness on three benchmarks is asserted, but without ablations isolating each module's contribution to the three core issues (or controls for whether the modules introduce cross-modal inconsistencies), the support for the central performance claims remains incomplete.
Authors: We acknowledge that the current experiments lack module-specific ablations tied directly to the three core issues and explicit checks for introduced inconsistencies. The revised manuscript will add targeted ablation tables that measure each module's impact on attribute disentanglement, cross-modal consistency, and supervision signal quality, together with controls (e.g., modality-wise retrieval gaps and consistency regularization metrics) to verify that no new cross-modal conflicts are introduced. revision: yes
Circularity Check
No significant circularity; proposal of new modules remains independent of its inputs
full rationale
The abstract states three core issues and introduces three named modules (Adaptive Semantic Disentanglement, Unified Prototype-based Composition, Dual Relations Modeling) to address them, plus an attribute-prototype similarity metric. No equations, loss functions, or derivation steps are supplied that would allow any claimed performance gain or 'first study' status to reduce by construction to the module definitions themselves. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear. The central claim is therefore a standard architectural proposal whose correctness must be judged by external benchmarks rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
invented entities (2)
-
attribute prototypes
no independent evidence
-
cross-modal unified prototypes (CUP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zixu Li, Yupeng Hu, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Weili Guan, and Liqiang Nie. Tempret: Temporal enhancement and two- stage reranking for cvpr 2026 epic-kitchens-100 multi-instance retrieval challenge.arXiv preprint arXiv:2605.24470, 2026
Pith/arXiv arXiv 2026
-
[2]
Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality-robustness.IEEE TKDE, 2026
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, and Liqiang Nie. Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality-robustness.IEEE TKDE, 2026
2026
-
[3]
Erase: Bypassing collaborative detection of ai counterfeit via comprehensive artifacts elimination.IEEE TDSC, pages 1–18, Mar
Qianyun Yang, Peizhuo Lv, Yingjiu Li, Shengzhi Zhang, Yuxuan Chen, Zhiwei Chen, Zixu Li, and Yupeng Hu. Erase: Bypassing collaborative detection of ai counterfeit via comprehensive artifacts elimination.IEEE TDSC, pages 1–18, Mar. 2026
2026
-
[4]
User: Unified semantic enhancement with momentum contrast for image-text retrieval.IEEE Transactions on Image Processing, 33:595–609, 2024
Yan Zhang, Zhong Ji, Di Wang, Yanwei Pang, and Xuelong Li. User: Unified semantic enhancement with momentum contrast for image-text retrieval.IEEE Transactions on Image Processing, 33:595–609, 2024
2024
-
[5]
Deep boosting learning: a brand-new cooperative approach for image- text matching.IEEE Transactions on Image Processing, 2024
Haiwen Diao, Ying Zhang, Shang Gao, Xiang Ruan, and Huchuan Lu. Deep boosting learning: a brand-new cooperative approach for image- text matching.IEEE Transactions on Image Processing, 2024
2024
-
[6]
Decoupled cross-modal phrase-attention network for image- sentence matching.IEEE Transactions on Image Processing, 33:1326– 1337, 2022
Zhangxiang Shi, Tianzhu Zhang, Xi Wei, Feng Wu, and Yongdong Zhang. Decoupled cross-modal phrase-attention network for image- sentence matching.IEEE Transactions on Image Processing, 33:1326– 1337, 2022
2022
-
[7]
Semantics disentangling for cross-modal retrieval.IEEE Trans- actions on Image Processing, 33:2226–2237, 2024
Zheng Wang, Xing Xu, Jiwei Wei, Ning Xie, Yang Yang, and Heng Tao Shen. Semantics disentangling for cross-modal retrieval.IEEE Trans- actions on Image Processing, 33:2226–2237, 2024
2024
-
[8]
Refine: Composed video retrieval via shared and differential semantics enhancement.ACM ToMM, 2026
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Composed video retrieval via shared and differential semantics enhancement.ACM ToMM, 2026
2026
-
[9]
Composing text and image for image retrieval - an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval - an empirical odyssey. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6439–6448. IEEE, 2019
2019
-
[10]
Hint: Composed image retrieval with dual-path compositional contextualized network
Mingyu Zhang, Zixu Li, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Jiajia Nie, Yinwei Wei, and Yupeng Hu. Hint: Composed image retrieval with dual-path compositional contextualized network. InICASSP, pages 13002–13006. IEEE, 2026
2026
-
[11]
Melt: Improve composed image retrieval via the modification frequentation-rarity balance network
Guozhi Qiu, Zhiwei Chen, Zixu Li, Qinlei Huang, Zhiheng Fu, Xuemeng Song, and Yupeng Hu. Melt: Improve composed image retrieval via the modification frequentation-rarity balance network. InICASSP, pages 13007–13011. IEEE, 2026
2026
-
[12]
Zhiheng Fu, Yupeng Hu, Qianyun Yang, Shiqi Zhang, Zhiwei Chen, and Zixu Li. Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval.arXiv preprint arXiv:2604.19386, 2026
Pith/arXiv arXiv 2026
-
[13]
Zixu Li, Yupeng Hu, Zhiwei Chen, Mingyu Zhang, Zhiheng Fu, and Liqiang Nie. Conesep: Cone-based robust noise-unlearning com- positional network for composed image retrieval.arXiv preprint arXiv:2604.20358, 2026
Pith/arXiv arXiv 2026
-
[14]
Yang Shi, Yifeng Xie, Minzhe Guo, Liangsi Lu, Mingxuan Huang, Jingchao Wang, Zhihong Zhu, Boyan Xu, and Zhiqi Huang. Mmerror: A benchmark for erroneous reasoning in vision-language models.arXiv preprint arXiv:2601.03331, 2026
Pith/arXiv arXiv 2026
-
[15]
Zhiheng Fu, Zixu Li, Zhiwei Chen, Fangxu Liu, Yupeng Hu, Weili Guan, and Liqiang Nie. Egoaction: Egocentric action composition with reliability-aware temporal fusion for the epic-kitchens action detection challenge at cvpr 2026.arXiv preprint arXiv:2605.24496, 2026
Pith/arXiv arXiv 2026
-
[16]
Detecting congestion-related attacks via fine-grained queue diagnosis
Rui Dai, Dan Tang, Zheng Qin, Kai Chen, Keqin Li, and Jiliang Zhang. Detecting congestion-related attacks via fine-grained queue diagnosis. IEEE Transactions on Cognitive Communications and Networking, 2025
2025
-
[17]
Taozhe Li and Wei Sun. Mlp-slam: Multilayer perceptron-based simul- taneous localization and mapping.arXiv preprint arXiv:2410.10669, 2024
arXiv 2024
-
[18]
Mwd-cfm: Detection and mitigation of ddos attack against sdn flow tables.IEEE Transactions on Networking, 34:4269–4282, 2026
Dan Tang, Chenguang Zuo, Xinmeng Li, Siyuan Wang, Wei Liang, Keqin Li, and Jiliang Zhang. Mwd-cfm: Detection and mitigation of ddos attack against sdn flow tables.IEEE Transactions on Networking, 34:4269–4282, 2026
2026
-
[19]
Event-triggered adaptive tracking control for usv based on enhanced optimized backstepping technique.ISA transactions, 2025
Hugan Zhang, Xianku Zhang, Yongjin Liu, Shihang Gao, and Daocheng Ma. Event-triggered adaptive tracking control for usv based on enhanced optimized backstepping technique.ISA transactions, 2025
2025
-
[20]
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Guozhi Qiu, Weili Guan, and Liqiang Nie. Egoadapt: A multi-scene egocentric adaptation method for cvpr 2026 hd-epic vqa challenge.arXiv preprint arXiv:2605.24500, 2026
Pith/arXiv arXiv 2026
-
[21]
Zixu Li, Zhiwei Chen, Zhiheng Fu, Wenbo Wang, Yupeng Hu, Weili Guan, and Liqiang Nie. Omniego-r 2: A routed reasoning framework for the 1st cross-domain egocross challenge at cvpr 2026.arXiv preprint arXiv:2605.24481, 2026
Pith/arXiv arXiv 2026
-
[22]
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Weili Guan, and Liqiang Nie. R 3: Composed video retrieval via reasoning-guided recalling and re-ranking.arXiv preprint arXiv:2606.01113, 2026
Pith/arXiv arXiv 2026
-
[23]
Core-mmrag: Cross-source knowledge reconciliation for multimodal rag
Yang Tian, Fan Liu, Jingyuan Zhang, Yupeng Hu, Liqiang Nie, et al. Core-mmrag: Cross-source knowledge reconciliation for multimodal rag. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32967– 32982, 2025
2025
-
[24]
Chordedit: One-step low-energy transport for image editing
Liangsi Lu, Xuhang Chen, Minzhe Guo, Shichu Li, Jingchao Wang, and Yang Shi. Chordedit: One-step low-energy transport for image editing. arXiv preprint arXiv:2602.19083, 2026
arXiv 2026
-
[25]
Semantic collaborative learning for cross-modal moment localization
Yupeng Hu, Kun Wang, Meng Liu, Haoyu Tang, and Liqiang Nie. Semantic collaborative learning for cross-modal moment localization. 15 ACM Transactions on Information Systems, 42(2):1–26, 2023
2023
-
[26]
Infor- mation guided levy flight for robot search in unknown environments
Weitao Zhao, Zati Hakim Azizul, Xin Lyu, and Weijie Kuang. Infor- mation guided levy flight for robot search in unknown environments. Journal of King Saud University Computer and Information Sciences, 2026
2026
-
[27]
Coarse-to-fine semantic alignment for cross-modal moment localization.IEEE Transactions on Image Processing, 30:5933– 5943, 2021
Yupeng Hu, Liqiang Nie, Meng Liu, Kun Wang, Yinglong Wang, and Xian-Sheng Hua. Coarse-to-fine semantic alignment for cross-modal moment localization.IEEE Transactions on Image Processing, 30:5933– 5943, 2021
2021
-
[28]
Grain: Gravity-resistance adaptive framework for identifying influential nodes using multi-order structural diversity.Information Processing & Management, 63(4):104618, 2026
Yirun Ruan, Xinghua Qin, Sizheng Liu, Mengmeng Zhang, Jun Tang, Yanming Guo, and Tianyuan Yu. Grain: Gravity-resistance adaptive framework for identifying influential nodes using multi-order structural diversity.Information Processing & Management, 63(4):104618, 2026
2026
-
[29]
Angel or devil: Discriminating hard samples and anomaly contaminations for unsupervised time series anomaly detection.Neural Networks, page 108532, 2026
Ruyi Zhang, Hongzuo Xu, Songlei Jian, Yusong Tan, Haifang Zhou, and Rulin Xu. Angel or devil: Discriminating hard samples and anomaly contaminations for unsupervised time series anomaly detection.Neural Networks, page 108532, 2026
2026
-
[30]
Video moment localization via deep cross-modal hashing.IEEE Transactions on Image Processing, 30:4667–4677, 2021
Yupeng Hu, Meng Liu, Xiaobin Su, Zan Gao, and Liqiang Nie. Video moment localization via deep cross-modal hashing.IEEE Transactions on Image Processing, 30:4667–4677, 2021
2021
-
[31]
Progressive learning for image retrieval with hybrid-modality queries
Yida Zhao, Yuqing Song, and Qin Jin. Progressive learning for image retrieval with hybrid-modality queries. InProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1012–1021, 2022
2022
-
[32]
Sentence-level prompts benefit composed image retrieval
Xinxing Xu, Yong Liu, Salman Khan, Fahad Khan, Wangmeng Zuo, Rick Siow Mong Goh, Chun-Mei Feng, et al. Sentence-level prompts benefit composed image retrieval. InInternational Conference on Learning Representations, 2024
2024
-
[33]
Decomposing semantic shifts for composed image re- trieval
Xingyu Yang, Daqing Liu, Heng Zhang, Yong Luo, Chaoyue Wang, and Jing Zhang. Decomposing semantic shifts for composed image re- trieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 6576–6584, 2024
2024
-
[34]
Xu Zhang, Zhedong Zheng, Xiaohan Wang, and Yi Yang. Relieving triplet ambiguity: Consensus network for language-guided image re- trieval.arXiv preprint arXiv:2306.02092, 2023
arXiv 2023
-
[35]
Ranking-aware uncertainty for text- guided image retrieval.arXiv preprint arXiv:2308.08131, 2023
Junyang Chen and Hanjiang Lai. Ranking-aware uncertainty for text- guided image retrieval.arXiv preprint arXiv:2308.08131, 2023
arXiv 2023
-
[36]
Target-guided composed image retrieval
Haokun Wen, Xian Zhang, Xuemeng Song, Yinwei Wei, and Liqiang Nie. Target-guided composed image retrieval. InProceedings of the ACM International Conference on Multimedia, pages 915–923, 2023
2023
-
[37]
Semantic distil- lation from neighborhood for composed image retrieval
Yifan Wang, Wuliang Huang, Lei Li, and Chun Yuan. Semantic distil- lation from neighborhood for composed image retrieval. InProceedings of the ACM International Conference on Multimedia, 2024
2024
-
[38]
Learn- ing attribute-driven disentangled representations for interactive fashion retrieval
Yuxin Hou, Eleonora Vig, Michael Donoser, and Loris Bazzani. Learn- ing attribute-driven disentangled representations for interactive fashion retrieval. InProceedings of the IEEE/CVF International conference on computer vision, pages 12147–12157, 2021
2021
-
[39]
Face image retrieval with attribute manipulation
Alireza Zaeemzadeh, Shabnam Ghadar, Baldo Faieta, Zhe Lin, Nazanin Rahnavard, Mubarak Shah, and Ratheesh Kalarot. Face image retrieval with attribute manipulation. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 12116–12125, 2021
2021
-
[40]
Generative attribute manipulation scheme for flexible fashion search
Xin Yang, Xuemeng Song, Xianjing Han, Haokun Wen, Jie Nie, and Liqiang Nie. Generative attribute manipulation scheme for flexible fashion search. InProceedings of the 43rd international acm sigir conference on research and development in information retrieval, pages 941–950, 2020
2020
-
[41]
Composed image retrieval via cross relation network with hierarchical aggregation transformer.IEEE Transactions on Image Processing, 2023
Qu Yang, Mang Ye, Zhaohui Cai, Kehua Su, and Bo Du. Composed image retrieval via cross relation network with hierarchical aggregation transformer.IEEE Transactions on Image Processing, 2023
2023
-
[42]
Composed image retrieval via explicit erasure and replenishment with semantic alignment.IEEE Transactions on Image Processing, 31:5976– 5988, 2022
Gangjian Zhang, Shikui Wei, Huaxin Pang, Shuang Qiu, and Yao Zhao. Composed image retrieval via explicit erasure and replenishment with semantic alignment.IEEE Transactions on Image Processing, 31:5976– 5988, 2022
2022
-
[43]
Multimodal composition example mining for composed query image retrieval.IEEE Transactions on Image Processing, 33:1149–1161, 2024
Gangjian Zhang, Shikun Li, Shikui Wei, Shiming Ge, Na Cai, and Yao Zhao. Multimodal composition example mining for composed query image retrieval.IEEE Transactions on Image Processing, 33:1149–1161, 2024
2024
-
[44]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie. Finecir: Explicit parsing of fine-grained modification se- mantics for composed image retrieval.https://arxiv.org/abs/2503.21309, 2025
arXiv 2025
-
[45]
Pair: Complementarity-guided disentan- glement for composed image retrieval
Zhiheng Fu, Zixu Li, Zhiwei Chen, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Pair: Complementarity-guided disentan- glement for composed image retrieval. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, pages 1–5. IEEE, 2025
2025
-
[46]
Median: Adaptive intermediate-grained aggregation network for composed image retrieval
Qinlei Huang, Zhiwei Chen, Zixu Li, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Median: Adaptive intermediate-grained aggregation network for composed image retrieval. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, pages 1–5. IEEE, 2025
2025
-
[47]
Candi- date set re-ranking for composed image retrieval with dual multi-modal encoder.Transactions on Machine Learning Research, 2024
Zheyuan Liu, Weixuan Sun, Damien Teney, and Stephen Gould. Candi- date set re-ranking for composed image retrieval with dual multi-modal encoder.Transactions on Machine Learning Research, 2024
2024
-
[48]
Simple but effective raw-data level multimodal fusion for composed image retrieval
Haokun Wen, Xuemeng Song, Xiaolin Chen, Yinwei Wei, Liqiang Nie, and Tat-Seng Chua. Simple but effective raw-data level multimodal fusion for composed image retrieval. InProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 229–239, 2024
2024
-
[49]
Language-only training of zero-shot composed image retrieval
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, , Yoohoon Kang, and Sangdoo Yun. Language-only training of zero-shot composed image retrieval. InConference on Computer Vision and Pattern Recognition, 2024
2024
-
[50]
Semantic editing increment benefits zero-shot composed image retrieval
Zhenyu Yang, Shengsheng Qian, Dizhan Xue, Jiahong Wu, Fan Yang, Weiming Dong, and Changsheng Xu. Semantic editing increment benefits zero-shot composed image retrieval. InProceedings of the ACM International Conference on Multimedia, pages 1245–1254, 2024
2024
-
[51]
MagicLens: Self-supervised image retrieval with open-ended instructions
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. MagicLens: Self-supervised image retrieval with open-ended instructions. InProceedings of the International Conference on Machine Learning, pages 59403–59420, 2024
2024
-
[52]
Offset: Segmentation-based focus shift revision for composed image retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. Offset: Segmentation-based focus shift revision for composed image retrieval. InProceedings of the ACM International Conference on Multimedia, page 61136122, 2025
2025
-
[53]
Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan. Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval. InProceedings of the ACM International Conference on Multimedia, page 61436152, 2025
2025
-
[54]
Composed image retrieval with text feedback via multi-grained uncertainty regularization
Yiyang Chen, Zhedong Zheng, Wei Ji, Leigang Qu, and Tat-Seng Chua. Composed image retrieval with text feedback via multi-grained uncertainty regularization. InInternational Conference on Learning Representations, 2024
2024
-
[55]
Cosmo: Content- style modulation for image retrieval with text feedback
Seungmin Lee, Dongwan Kim, and Bohyung Han. Cosmo: Content- style modulation for image retrieval with text feedback. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 802–812. IEEE, 2021
2021
-
[56]
Comprehensive linguistic-visual composition network for image retrieval
Haokun Wen, Xuemeng Song, Xin Yang, Yibing Zhan, and Liqiang Nie. Comprehensive linguistic-visual composition network for image retrieval. InProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1369–
-
[57]
Self-training boosted multi-factor matching network for composed image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
Haokun Wen, Xuemeng Song, Jianhua Yin, Jianlong Wu, Weili Guan, and Liqiang Nie. Self-training boosted multi-factor matching network for composed image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[58]
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Yongqi Li, and Liqiang Nie. Tema: Anchor the image, follow the text for multi-modification composed image retrieval.arXiv preprint arXiv:2604.21806, 2026
Pith/arXiv arXiv 2026
-
[59]
Habit: Chrono-synergia robust progressive learning framework for composed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono-synergia robust progressive learning framework for composed image retrieval. InAAAI, volume 40, pages 6762–6770, 2026
2026
-
[60]
Set of diverse queries with uncertainty regularization for composed image retrieval.IEEE Transactions on Circuits and Systems for Video Technology, 2024
Yahui Xu, Jiwei Wei, Yi Bin, Yang Yang, Zeyu Ma, and Heng Tao Shen. Set of diverse queries with uncertainty regularization for composed image retrieval.IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[61]
Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. InAAAI, vol- ume 40, pages 20463–20471, 2026
2026
-
[62]
Retrack: Evidence-driven dual-stream directional anchor calibration network for composed video retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. Retrack: Evidence-driven dual-stream directional anchor calibration network for composed video retrieval. InAAAI, volume 40, pages 23373–23381, 2026
2026
-
[63]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[64]
Effective conditioned and composed image retrieval com- bining clip-based features
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Effective conditioned and composed image retrieval com- bining clip-based features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21466–21474, 2022
2022
-
[65]
High reliability multi-input converter with low input current ripple based on sepic for solar-powered unmanned aerial vehicle.IEEE Transactions on 16 Consumer Electronics, 2026
Binxin Zhu, Wenxin Liao, Xiaoli She, and Jinhai An. High reliability multi-input converter with low input current ripple based on sepic for solar-powered unmanned aerial vehicle.IEEE Transactions on 16 Consumer Electronics, 2026
2026
-
[66]
Training-free multi- style fusion through reference-based adaptive modulation, 2025
Xu Liu, Yibo Lu, Xinxian Wang, and Xinyu Wu. Training-free multi- style fusion through reference-based adaptive modulation, 2025
2025
-
[67]
Don’t let the information slip away.arXiv preprint arXiv:2602.22595, 2026
Taozhe Li. Don’t let the information slip away.arXiv preprint arXiv:2602.22595, 2026
arXiv 2026
-
[68]
Dnsgreen: A comprehensive defense system against bounce-style dns ddos attacks with p4.IEEE Transactions on Computers, 2025
Dan Tang, Xiaocai Wang, Pei Tan, Zheng Qin, Keqin Li, and Jiliang Zhang. Dnsgreen: A comprehensive defense system against bounce-style dns ddos attacks with p4.IEEE Transactions on Computers, 2025
2025
-
[69]
Prompt-guided dual latent steering for inversion problems, 2025
Yichen Wu, Xu Liu, Chenxuan Zhao, and Xinyu Wu. Prompt-guided dual latent steering for inversion problems, 2025
2025
-
[70]
Machine learning-driven simulation and optimization of phosphate adsorption on metal-organic frameworks
Jie Huang, Ziang Zong, Penghui Wang, Yuxuan Zhang, Degui Gao, Yingqi Wang, and Zhanjun Li. Machine learning-driven simulation and optimization of phosphate adsorption on metal-organic frameworks. Separation and Purification Technology, page 137479, 2026
2026
-
[71]
Attribute prototype network for zero-shot learning.Advances in Neural Information Processing Systems, 33:21969–21980, 2020
Wenjia Xu, Yongqin Xian, Jiuniu Wang, Bernt Schiele, and Zeynep Akata. Attribute prototype network for zero-shot learning.Advances in Neural Information Processing Systems, 33:21969–21980, 2020
2020
-
[72]
Prototype-guided saliency feature learning for person search
Hanjae Kim, Sunghun Joung, Ig-Jae Kim, and Kwanghoon Sohn. Prototype-guided saliency feature learning for person search. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4865–4874, 2021
2021
-
[73]
Robust classification with convolutional prototype learning
Hong-Ming Yang, Xu-Yao Zhang, Fei Yin, and Cheng-Lin Liu. Robust classification with convolutional prototype learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3474–3482, 2018
2018
-
[74]
Prototypical matching and open set rejection for zero-shot semantic segmentation
Hui Zhang and Henghui Ding. Prototypical matching and open set rejection for zero-shot semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6974– 6983, 2021
2021
-
[75]
Prototypical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
2017
-
[76]
Intermediate prototype mining transformer for few-shot semantic segmentation.Ad- vances in Neural Information Processing Systems, 35:38020–38031, 2022
Yuanwei Liu, Nian Liu, Xiwen Yao, and Junwei Han. Intermediate prototype mining transformer for few-shot semantic segmentation.Ad- vances in Neural Information Processing Systems, 35:38020–38031, 2022
2022
-
[77]
Interactive segmentation with prototype learning for few-shot root annotation.IEEE Transactions on Geoscience and Remote Sensing, 2025
Xiaolei Guo, Alina Zare, Lisa Anthony, and Felix B Fritschi. Interactive segmentation with prototype learning for few-shot root annotation.IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[78]
Rethinking semantic segmentation: A prototype view
Tianfei Zhou, Wenguan Wang, Ender Konukoglu, and Luc Van Gool. Rethinking semantic segmentation: A prototype view. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2582–2593, 2022
2022
-
[79]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[80]
Conditioned and composed image retrieval combining and partially fine-tuning clip-based features
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Conditioned and composed image retrieval combining and partially fine-tuning clip-based features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4959–4968, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.