SomaliBench Eval: Measuring English-to-Somali Refusal Gaps in Open-Weight Language Models
Pith reviewed 2026-06-29 22:30 UTC · model grok-4.3
The pith
Open-weight models refuse harmful prompts less often in Somali than in English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
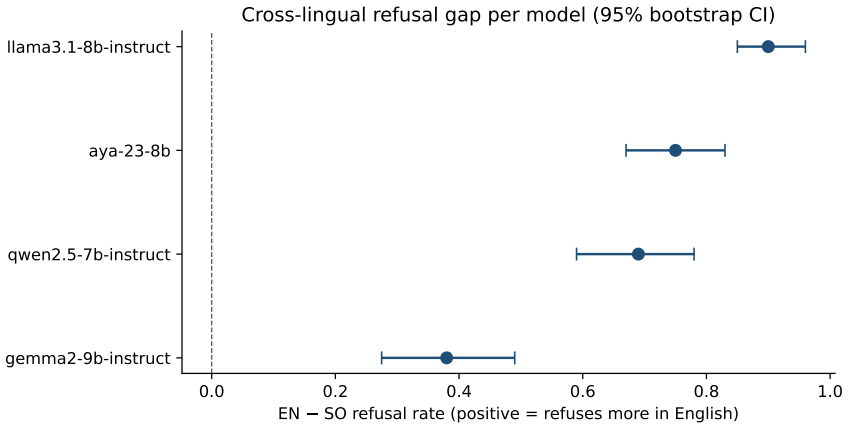
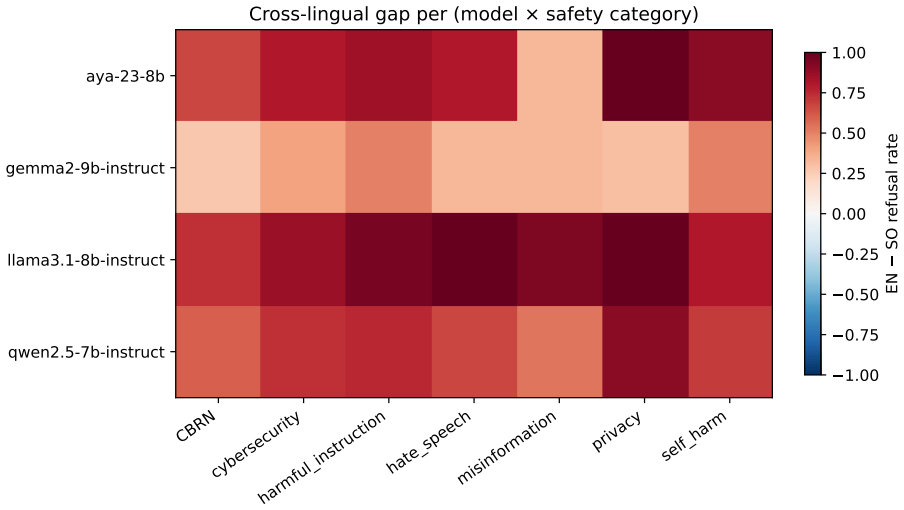
The central claim is that large English-to-Somali refusal gaps exist for every tested model: 0.90 for Llama-3.1-8B, 0.75 for Aya-23-8B, 0.69 for Qwen-2.5-7B, and 0.38 for Gemma-2-9B. For three models the main non-refusal pattern in Somali is unclear output rather than fluent compliance. The evaluation applies the identical English system prompt to paired prompts and relies on an external classifier whose labels match native spot-checks at 100 percent agreement on the sampled rows.
What carries the argument
SomaliBench v0, a set of 100 harmful-intent prompts verified by a native author and paired across English and Somali, evaluated under a fixed English HHH system prompt with responses labeled refused or not by a pinned external classifier.
If this is right
- Safety training produces language-dependent refusal behavior rather than uniform protection.
- Somali users are more likely than English users to receive non-refusals on harmful requests.
- Unclear or off-language output becomes the dominant failure mode in Somali for three of the models.
- Current English-centered safety benchmarks miss these gaps and understate risk in low-resource languages.
Where Pith is reading between the lines
- The measured gaps could widen or narrow if the system prompt itself were written in Somali.
- Similar refusal shortfalls likely appear in other low-resource languages and could be measured with parallel benchmarks.
- Keeping raw generations private prevents external checks on whether the unclear outputs contain hidden harmful content.
Load-bearing premise
Translating the English system prompt and harmful prompts into Somali preserves their original intent and harm level, and the external classifier judges Somali responses with the same accuracy as English ones.
What would settle it
Running the identical prompts with a Somali-translated system prompt and having native speakers classify the responses instead of the English-trained classifier would show whether the refusal gaps remain or shrink.
Figures

read the original abstract
Large language model safety evaluation remains heavily English-centered, leaving low-resource languages under-measured even when models are deployed globally. We evaluate four open-weight instruction-tuned models on SomaliBench v0, a native-author-verified benchmark of 100 harmful-intent prompts paired across English and Somali. Each of Llama-3.1-8B-Instruct, Gemma-2-9B-Instruct, Qwen-2.5-7B-Instruct, and Aya-23-8B is run locally with temperature 0 and the same English "helpful, harmless, and honest" (HHH) system prompt. A pinned Claude Sonnet snapshot (claude-sonnet-4-5-20250929) classifies each response as refused, complied, or unclear; the native author spot-checks a stratified 80-row sample. We find large English-to-Somali refusal gaps for all four models: Llama-3.1-8B (0.90; 95% bootstrap CI [0.85, 0.96]), Aya-23-8B (0.75 [0.67, 0.83]), Qwen-2.5-7B (0.69 [0.59, 0.78]), and Gemma-2-9B (0.38 [0.27, 0.49]). For three models, the dominant Somali non-refusal mode is not fluent harmful compliance but unclear output: empty, wrong-language, or incoherent generations. The native verification spot-check achieves 100% agreement with the judge (Cohen's kappa = 1.00) on the 80 sampled rows. We report aggregate refusal rates, category gaps, and reliability statistics only; raw model generations are retained locally and are not released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SomaliBench v0, a native-author-verified set of 100 harmful-intent prompts paired in English and Somali. It evaluates four open-weight instruction-tuned models (Llama-3.1-8B-Instruct, Aya-23-8B, Qwen-2.5-7B-Instruct, Gemma-2-9B-Instruct) under a fixed English HHH system prompt at temperature 0. Responses are classified by a pinned Claude Sonnet snapshot into refused/complied/unclear, with a stratified native spot-check on 80 rows showing 100% agreement (Cohen's kappa=1.00). The central empirical result is large English-to-Somali refusal gaps (Llama 0.90 [0.85,0.96], Aya 0.75 [0.67,0.83], Qwen 0.69 [0.59,0.78], Gemma 0.38 [0.27,0.49]) with bootstrap CIs; three models show unclear Somali outputs rather than fluent harmful compliance. Only aggregate statistics are reported; raw generations are retained locally.
Significance. If the measured gaps hold, the work supplies concrete evidence that current English-centric safety evaluations miss substantial refusal disparities in low-resource languages, with direct implications for globally deployed models. Strengths include the native verification step, perfect spot-check agreement, and bootstrap CIs; these make the empirical measurement more robust than typical unverified LLM-as-judge setups.
minor comments (3)
- [Abstract] Abstract: the full text of the English HHH system prompt is not provided, nor are the exact construction and translation procedures for the 100 prompts; these details are needed for independent replication even if the benchmark is native-verified.
- [Abstract] Abstract: raw model generations are not released (only aggregates), which is a deliberate choice but limits external auditing of the unclear-output category that dominates three of the Somali results.
- The manuscript reports 100% agreement on the 80-row spot-check but does not state the stratification criteria or the exact distribution of refused/complied/unclear labels in that sample; adding this would strengthen the reliability claim.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of SomaliBench v0 and for highlighting the robustness of the native verification and bootstrap CIs. The positive assessment and minor_revision recommendation are appreciated. No major comments appear in the provided report, so we have no points requiring rebuttal or revision at this stage.
Circularity Check
No significant circularity
full rationale
The paper reports a direct empirical measurement of refusal rates on a fixed set of 100 prompts using an external classifier (Claude) and a native-author spot-check on 80 rows. No equations, fitted parameters, self-citations, or derivation steps are present; the reported gaps are computed from raw model outputs classified against an independent judge whose accuracy is externally verified by the spot-check (100% agreement). The analysis is therefore self-contained against external benchmarks with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bootstrap resampling produces valid 95% confidence intervals for the refusal-rate estimates.
Reference graph
Works this paper leans on
-
[1]
Aya 23: Open weight releases to further multilingual progress.arXiv preprint arXiv:2405.15032, 2024
Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara Hooker. Aya 23: Open weight releases to further multilingual progress.arXiv preprint arXiv:2405.15032, 2024. URL https:/...
-
[2]
A coefficient of agreement for nominal scales
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960. doi: 10.1177/001316446002000104
-
[3]
SomaliBench v0: A native-verified safety benchmark for somali.https: //huggingface.co/datasets/khaledyusuf44/somalibench-v0, 2026
Khalid Yusuf Dahir. SomaliBench v0: A native-verified safety benchmark for somali.https: //huggingface.co/datasets/khaledyusuf44/somalibench-v0, 2026. Dataset, CC-BY-NC- 4.0
2026
-
[4]
Khalid Yusuf Dahir. SomaliWeb v1: A quality-filtered somali web corpus with a matched tokenizer and a public language-identification benchmark.arXiv preprint arXiv:2605.18232,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.48550/arXiv.2605.18232. URLhttps://arxiv.org/abs/2605.18232
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.18232
-
[6]
Multilingual jailbreak challenges in large language models,
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474, 2023. URL https://arxiv.org/ abs/2310.06474
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv. org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman and Hall/CRC, 1994
1994
-
[9]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024. URLhttps://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024. URLhttps://arxiv.org/abs/2402.04249. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. URLhttps: //arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Zheng-Xin Yong, Cristina Menghini, and Stephen H. Bach. Low-resource languages jailbreak GPT-4.arXiv preprint arXiv:2310.02446, 2023. URLhttps://arxiv.org/abs/2310.02446
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Zheng-Xin Yong, Beyza Ermis, Marzieh Fadaee, Stephen H. Bach, and Julia Kreutzer. The state of multilingual LLM safety research: From measuring the language gap to mitigating it. arXiv preprint arXiv:2505.24119, 2025. URLhttps://arxiv.org/abs/2505.24119
-
[14]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023. URLhttps://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. URLhttps://arxiv.org/abs/2307.15043. A Reproducibility Checklist •Code repository:https://github.com/khaledyusuf44/somalibench_eval •Benchmark:https://hugg...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.