MultiToP: Learning to Patch Visual Tokens to Mitigate Hallucinations in Video Large Multimodal Models
Pith reviewed 2026-06-27 10:00 UTC · model grok-4.3
The pith
MultiToP mitigates hallucinations in video large multimodal models by selectively replacing unreliable visual tokens with a dynamic global patch token before response generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
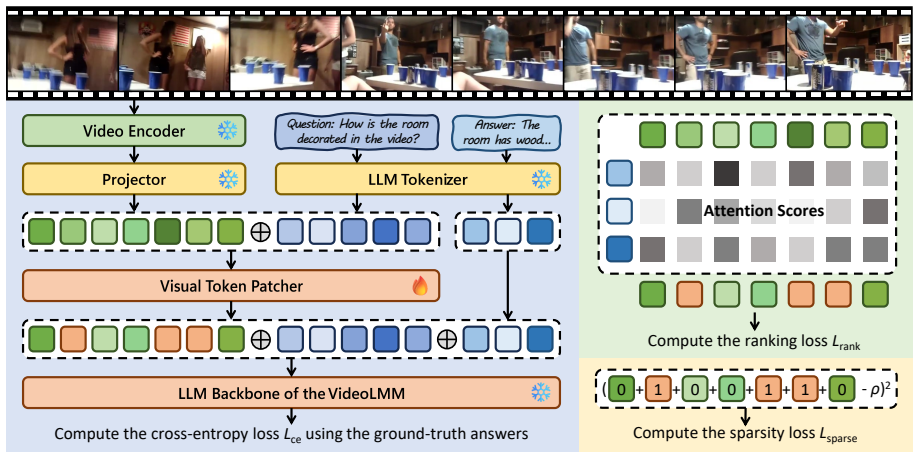
MultiToP is a multimodal-context-aware visual token patching framework that introduces a Visual Token Patcher to predict token-level replacement distributions and selectively substitute unreliable visual tokens with a dynamic global patch token; it is trained with information-guided rank calibration that uses answer-conditioned frame-level information cues from the backbone, combined with ground-truth answer supervision and sparsity regularization, enabling localized visual evidence refinement without modifying the original model.
What carries the argument
The Visual Token Patcher, a lightweight module that outputs token-level replacement distributions conditioned on multimodal context to decide substitutions with a dynamic global patch token.
If this is right
- Hallucination rates drop on dedicated benchmarks such as Vript-HAL.
- Accuracy on general video question-answering tasks such as ActivityNet-QA stays the same or improves.
- The base model requires no architectural changes or retraining.
- Inference cost stays nearly identical to the original model.
- Refinement stays localized to specific tokens rather than affecting the entire visual stream.
Where Pith is reading between the lines
- The same patching logic could be tested on static-image multimodal models to check whether the video-specific frame cues are essential.
- If the calibration step works across different base models, it might reduce reliance on expensive full-model alignment procedures for factuality.
- Token-level replacement might interact with existing video compression or sampling strategies, suggesting a combined system that chooses both which frames and which tokens to keep.
- A natural next test is whether the dynamic global patch token can be made content-adaptive rather than fixed across all videos.
Load-bearing premise
The assumption that answer-conditioned frame-level information cues from the backbone can reliably indicate which visual tokens are unreliable and guide their replacement without creating new biases or hurting results on varied video content.
What would settle it
An experiment on a new video set where the answer-conditioned cues systematically point to the wrong tokens, causing MultiToP to produce more hallucinations or lower accuracy than the unmodified base model.
Figures









read the original abstract
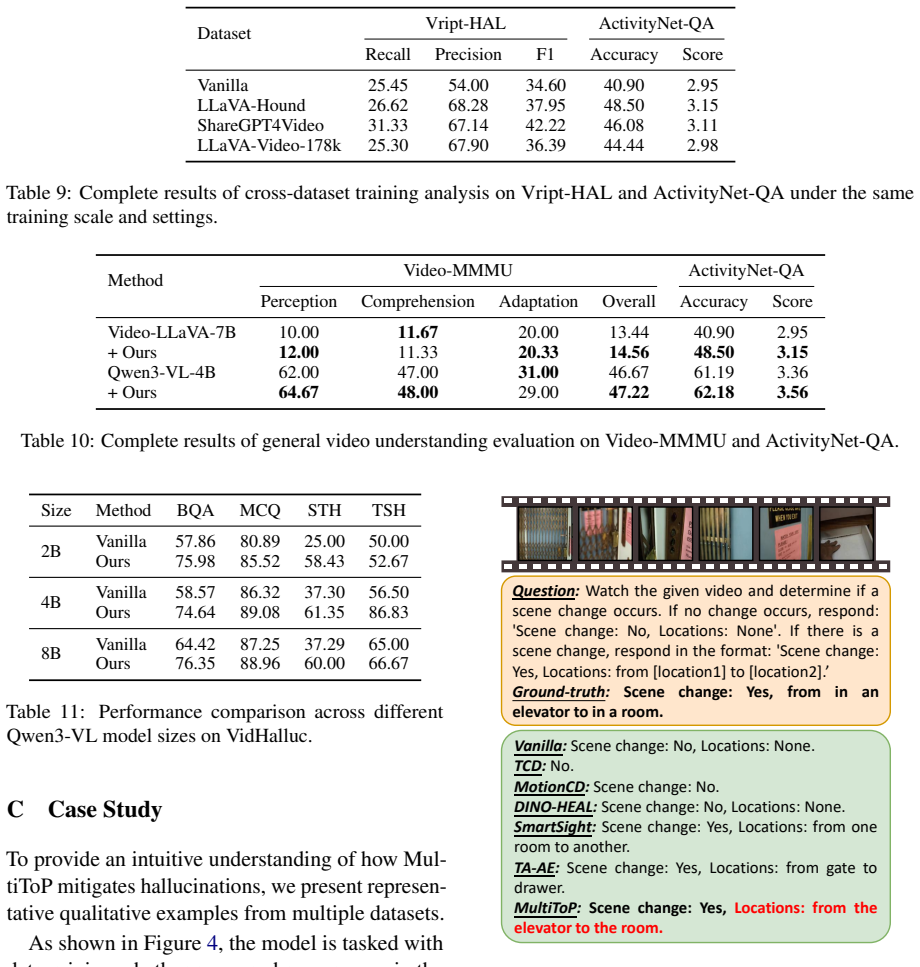
Video Large Multimodal Models have achieved remarkable progress in video understanding, yet they remain prone to hallucinations, where generated responses are not faithfully supported by the input video. In this paper, we propose MultiToP, a multimodal-context-aware visual token patching framework that mitigates hallucinations by refining unreliable visual tokens before language generation. MultiToP introduces a lightweight Visual Token Patcher to predict token-level replacement distributions and selectively substitute unreliable visual tokens with a dynamic global patch token. To train the patcher effectively, we further propose information-guided rank calibration, which uses answer-conditioned frame-level information cues derived from the backbone to guide token replacement. Combined with ground-truth answer supervision and sparsity regularization, MultiToP enables localized visual evidence refinement without modifying the original model. Extensive experiments demonstrate that MultiToP effectively reduces hallucinations on Vript-HAL with negligible inference overhead, improving the F1 scores of Qwen3-VL-4B-Instruct by 50.60% over the vanilla model. Meanwhile, MultiToP preserves general video understanding ability, yielding an 18.58% relative accuracy gain on ActivityNet-QA for Video-LLaVA-7B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MultiToP, a framework to mitigate hallucinations in video large multimodal models (LMMs) without modifying the backbone. It introduces a lightweight Visual Token Patcher that predicts token-level replacement distributions and substitutes unreliable visual tokens with a dynamic global patch token. Training uses information-guided rank calibration that conditions on answer-derived frame-level cues from the backbone, combined with ground-truth answer supervision and sparsity regularization. Experiments claim a 50.60% F1 improvement on Vript-HAL for Qwen3-VL-4B-Instruct and an 18.58% relative accuracy gain on ActivityNet-QA for Video-LLaVA-7B, with negligible inference overhead while preserving general video understanding.
Significance. If the central claim holds—that localized visual token patching guided solely by the proposed method reduces hallucinations without answer information at inference—the approach would offer a practical, model-agnostic way to improve reliability of existing video LMMs at low cost. The emphasis on preserving general capabilities and the lightweight design are strengths that could support broader adoption if the gains are shown to stem from genuine visual evidence refinement rather than training-time supervision patterns.
major comments (2)
- [Abstract / Method] Abstract / Method description: The information-guided rank calibration explicitly conditions token replacement on answer-conditioned frame-level information cues derived from the backbone plus ground-truth answer supervision. For the claim that 'visual-token patching alone reduces hallucinations' to hold at inference (where answers are unavailable), the manuscript must demonstrate that these cues surface only visual unreliability and do not allow the patcher to exploit answer-specific patterns during training; otherwise the reported 50.60% F1 gain on Vript-HAL could be an artifact of leakage.
- [Experiments / Results] Experiments / Results: The abstract states specific percentage improvements (50.60% F1 on Vript-HAL for Qwen3-VL-4B-Instruct; 18.58% accuracy on ActivityNet-QA for Video-LLaVA-7B) yet supplies no information on experimental controls, baseline comparisons, statistical significance, data exclusion rules, or how the vanilla model was evaluated. This prevents assessment of whether the numbers support the central claim of effective hallucination mitigation via token patching.
minor comments (1)
- [Abstract] The term 'dynamic global patch token' is introduced without an explicit definition or formulation in the provided abstract, which could be clarified for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the training-inference separation and experimental reporting while committing to revisions where needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract / Method description: The information-guided rank calibration explicitly conditions token replacement on answer-conditioned frame-level information cues derived from the backbone plus ground-truth answer supervision. For the claim that 'visual-token patching alone reduces hallucinations' to hold at inference (where answers are unavailable), the manuscript must demonstrate that these cues surface only visual unreliability and do not allow the patcher to exploit answer-specific patterns during training; otherwise the reported 50.60% F1 gain on Vript-HAL could be an artifact of leakage.
Authors: We agree this distinction is critical. The answer-conditioned cues and ground-truth supervision are used exclusively during training of the Visual Token Patcher to calibrate which tokens are unreliable for correct answer generation. At inference the trained patcher receives only the video input and the backbone's internal frame-level representations; no answer information is provided. To directly address potential leakage concerns, we will add an ablation in the revised manuscript that trains the patcher without answer-derived cues and reports the resulting performance on Vript-HAL, thereby showing that gains derive from learned visual unreliability detection. revision: yes
-
Referee: [Experiments / Results] Experiments / Results: The abstract states specific percentage improvements (50.60% F1 on Vript-HAL for Qwen3-VL-4B-Instruct; 18.58% accuracy on ActivityNet-QA for Video-LLaVA-7B) yet supplies no information on experimental controls, baseline comparisons, statistical significance, data exclusion rules, or how the vanilla model was evaluated. This prevents assessment of whether the numbers support the central claim of effective hallucination mitigation via token patching.
Authors: The full manuscript provides the requested details in the Experiments section, including baseline definitions (vanilla models evaluated under identical settings), benchmark protocols, and implementation choices. We acknowledge that the abstract itself is terse on these points. We will revise the abstract to include a concise statement of the evaluation setup, benchmarks, and controls, and will verify that statistical significance and data-handling procedures are explicitly stated in the main text. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The provided abstract and description contain no equations, fitted parameters presented as predictions, or self-citations that bear the central claim. The method trains a patcher using answer-conditioned cues plus ground-truth supervision, but this is an empirical training procedure rather than a self-referential derivation where outputs reduce to inputs by construction. No load-bearing step matches any of the enumerated circularity patterns, and the performance claims rest on experimental results rather than a closed mathematical loop.
Axiom & Free-Parameter Ledger
invented entities (1)
-
dynamic global patch token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
Video-llama: An instruction-tuned audio-visual language model for video understanding , author=. Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
2023
-
[2]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Video-chatgpt: Towards detailed video understanding via large vision and language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Chat-univi: Unified visual representation empowers large language models with image and video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
European Conference on Computer Vision , pages=
Llama-vid: An image is worth 2 tokens in large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[6]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Pllava: Parameter-free llava extension from images to videos for video dense captioning , author=. arXiv preprint arXiv:2404.16994 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Video understanding with large language models: A survey , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
A comprehensive survey of hallucination in large language, image, video and audio foundation models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[9]
Exploring hallucination of large multimodal models in video understanding: Benchmark, analysis and mitigation , author=. arXiv preprint arXiv:2503.19622 , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
VideoCon: Robust Video-Language Alignment via Contrast Captions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of Multimodal Large Language Models: A Survey , author=. arXiv preprint arXiv:2404.18930 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2602.00559 , year=
Learning to Decode Against Compositional Hallucination in Video Multimodal Large Language Models , author=. arXiv preprint arXiv:2602.00559 , year=
-
[13]
arXiv preprint arXiv:2409.16597 , year=
Eventhallusion: Diagnosing event hallucinations in video llms , author=. arXiv preprint arXiv:2409.16597 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Discovering compositional hallucinations in LVLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vidhalluc: Evaluating temporal hallucinations in multimodal large language models for video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Advances in Neural Information Processing Systems , volume=
Videohallu: Evaluating and mitigating multi-modal hallucinations on synthetic video understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2406.16338 , year=
Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models , author=. arXiv preprint arXiv:2406.16338 , year=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ARGUS: Hallucination and Omission Evaluation in Video-LLMs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
Advances in Neural Information Processing Systems , volume=
Vript: A video is worth thousands of words , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2508.21496 , year=
Elv-halluc: Benchmarking semantic aggregation hallucinations in long video understanding , author=. arXiv preprint arXiv:2508.21496 , year=
-
[21]
arXiv preprint arXiv:2504.13122 , year=
VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models , author=. arXiv preprint arXiv:2504.13122 , year=
-
[22]
arXiv preprint arXiv:2504.05810 , year=
Pami-vdpo: Mitigating video hallucinations by prompt-aware multi-instance video preference learning , author=. arXiv preprint arXiv:2504.05810 , year=
-
[23]
arXiv preprint arXiv:2512.24271 , year=
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation , author=. arXiv preprint arXiv:2512.24271 , year=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mhbench: Demystifying motion hallucination in videollms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=
Mitigating Hallucination in Large Video-Language Models with Injected Semantics , author=. 2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=. 2025 , organization=
2025
-
[27]
Advances in Neural Information Processing Systems , volume=
Mitigating hallucination in videollms via temporal-aware activation engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Smartsight: Mitigating hallucination in video-llms without compromising video understanding via temporal attention collapse , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
arXiv preprint arXiv:2601.10010 , year=
VERHallu: Evaluating and Mitigating Event Relation Hallucination in Video Large Language Models , author=. arXiv preprint arXiv:2601.10010 , year=
-
[30]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Internvideo2. 5: Empowering video mllms with long and rich context modeling , author=. arXiv preprint arXiv:2501.12386 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Damro: Dive into the attention mechanism of lvlm to reduce object hallucination , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[32]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Don’t miss the forest for the trees: Attentional vision calibration for large vision language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mitigating hallucinations in large vision-language models by adaptively constraining information flow , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
On Epistemic Uncertainty of Visual Tokens for Object Hallucinations in Large Vision-Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
arXiv preprint arXiv:2502.03628 , year=
The hidden life of tokens: Reducing hallucination of large vision-language models via visual information steering , author=. arXiv preprint arXiv:2502.03628 , year=
-
[37]
Categorical Reparameterization with Gumbel-Softmax
Categorical reparameterization with gumbel-softmax , author=. arXiv preprint arXiv:1611.01144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Adaptive keyframe sampling for long video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[39]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
International Conference on Learning Representations , volume=
Towards interpreting visual information processing in vision-language models , author=. International Conference on Learning Representations , volume=
-
[42]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos , author=. arXiv preprint arXiv:2501.13826 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Activitynet-qa: A dataset for understanding complex web videos via question answering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
arXiv preprint arXiv:2404.01258 , year=
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward , author=. arXiv preprint arXiv:2404.01258 , year=
-
[46]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume=
Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Advances in Neural Information Processing Systems , volume=
Sharegpt4video: Improving video understanding and generation with better captions , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Llava-video: Video instruction tuning with synthetic data , author=. arXiv preprint arXiv:2410.02713 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2026 , eprint=
Enhancing Video Representations with Spatiotemporal-Semantic Residual to Mitigate Hallucinations in Video Large Multimodal Models , author=. 2026 , eprint=
2026
-
[51]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[52]
Proceedings of the ACM Web Conference 2026 , pages=
Boosting Large Language Models for Mental Manipulation Detection via Data Augmentation and Distillation , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[53]
Proceedings of the ACM Web Conference 2026 , pages=
Kardia-r1: Unleashing llms to reason toward understanding and empathy for emotional support via rubric-as-judge reinforcement learning , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[54]
Frontiers of Computer Science , volume=
A survey of large language models , author=. Frontiers of Computer Science , volume=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.