LLM-ACES: Closed-Loop Discovery of Dynamical Systems with LLM-Guided Adaptive Search
Pith reviewed 2026-06-25 23:33 UTC · model grok-4.3
The pith
LLM-ACES recovers governing ODEs by letting an LLM partition the search space and using model disagreement to select new trajectories in a closed loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
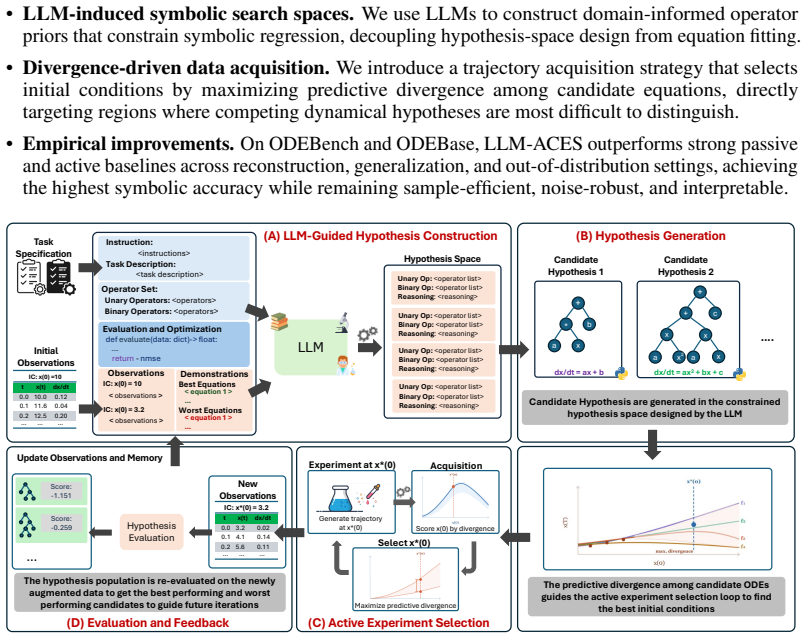
LLM-ACES jointly optimizes symbolic hypothesis construction and adaptive data acquisition: the LLM proposes operator priors that partition the large search space into distinct regions; candidate equations are fit to the observed data inside each region; disagreement among these candidates guides the acquisition of informative new trajectories; the process repeats, refining both the hypothesis space and the recovered dynamics.
What carries the argument
LLM-proposed operator priors that partition the search space, combined with disagreement among fitted candidates to select the next trajectories in a feedback loop.
If this is right
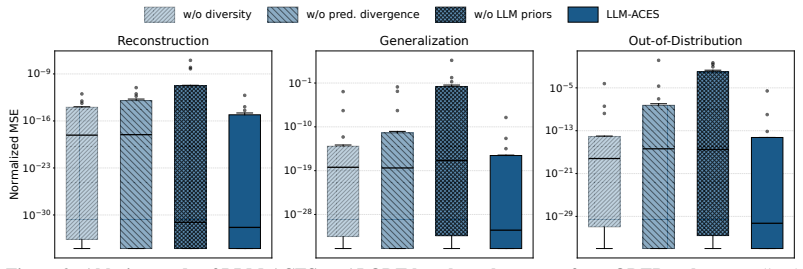
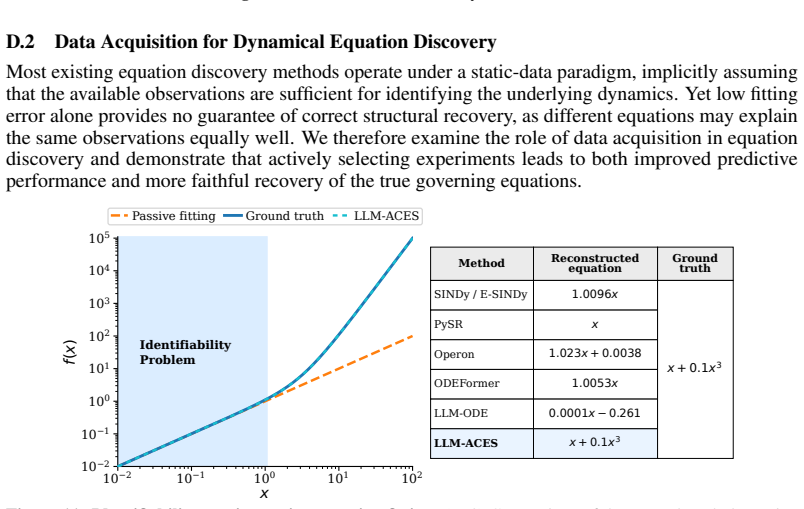
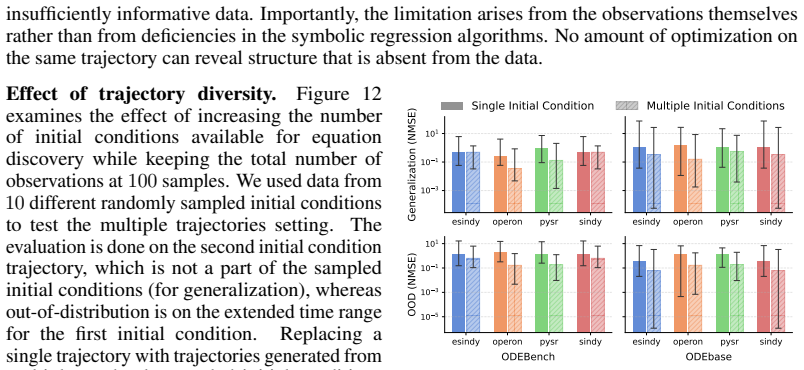
- The closed loop yields the lowest median NMSE across the 122 systems while reaching 46.2 percent and 52.4 percent symbolic accuracy on the two benchmark collections.
- Performance stays superior when only one-tenth the usual data volume is supplied.
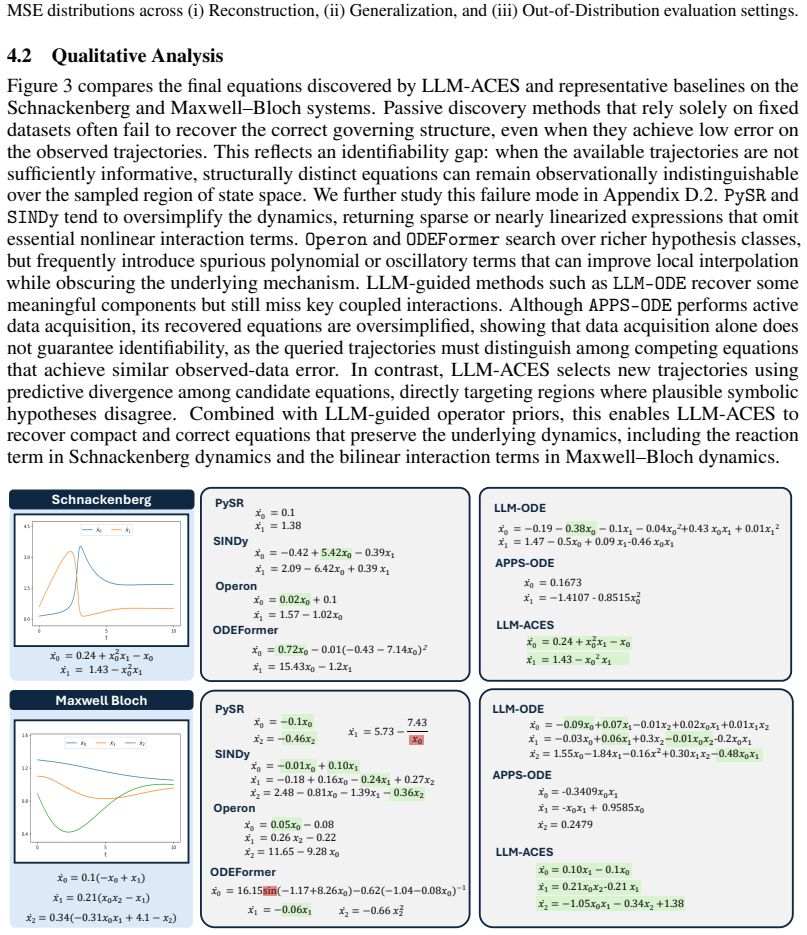
- Under added noise the method recovers the true symbolic structure instead of introducing spurious terms that fit locally.
Where Pith is reading between the lines
- The same disagreement signal could be used to decide when to stop collecting data rather than running a fixed budget.
- The operator-prior partitioning step may transfer to discovering other classes of governing equations such as delay differential equations or stochastic differential equations.
- Because the loop explicitly targets identifiability gaps, it could be paired with experimental design methods that already optimize for parameter uncertainty.
Load-bearing premise
LLM-proposed operator priors meaningfully partition the search space and disagreement among fitted candidates reliably identifies the most informative next trajectories.
What would settle it
On the same 122 ODE systems and identical data budgets, replace the LLM-guided acquisition step with random or fixed sampling and measure whether median NMSE and symbolic accuracy remain within one order of magnitude of the reported LLM-ACES results.
Figures




read the original abstract
Recovering governing Ordinary Differential Equations (ODEs) from data is a central challenge in modeling dynamical systems across scientific domains. Existing approaches cast discovery as a static inference problem over fixed datasets, assuming that the observed trajectories are sufficiently informative. However, dynamical systems evolve over large state spaces, and limited data can make multiple equations observationally indistinguishable, leading to identifiability gaps and the recovery of incorrect governing equations. To address this, we introduce LLM-ACES, or LLM-guided Active Closed-loop Equation Search, a closed-loop framework that jointly optimizes symbolic hypothesis construction and adaptive data acquisition. In LLM-ACES, a large language model (LLM) proposes operator priors that partition the large search space into distinct regions, within which candidate equations are fit to the observed data. The disagreement among these candidates guides the acquisition of informative trajectories, creating a feedback loop that iteratively refines both the hypothesis space and the discovered dynamics. On 122 ODE systems spanning ODEBench and ODEBase, LLM-ACES achieves the lowest median NMSE, outperforming state-of-the-art baselines by several orders of magnitude while achieving a high symbolic accuracy of 46.2% and 52.4%, respectively. Our analysis further shows that LLM-ACES is sample-efficient, achieving better performance with one-tenth the data. Furthermore, LLM-ACES's feedback-driven data acquisition makes it robust to noise and recovers the correct symbolic structure, while baselines introduce spurious terms that fit the data locally but obscure the true governing relationships.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLM-ACES, a closed-loop framework for ODE discovery that uses an LLM to propose operator priors partitioning the search space, fits candidate equations within regions, and employs candidate disagreement to drive adaptive trajectory acquisition. On 122 systems from ODEBench and ODEBase it reports the lowest median NMSE (outperforming baselines by several orders of magnitude), symbolic accuracies of 46.2% and 52.4%, improved sample efficiency with one-tenth the data, and greater robustness to noise than baselines.
Significance. If the performance gains prove reproducible and the closed-loop mechanism is shown to be responsible rather than implementation differences, the work would offer a notable advance by demonstrating how LLM-generated priors combined with disagreement-driven active sampling can mitigate identifiability gaps in dynamical-system discovery. The emphasis on sample efficiency and noise robustness addresses practical constraints in experimental settings.
major comments (2)
- [Abstract] Abstract: the central empirical claim of orders-of-magnitude lower median NMSE and 46–52% symbolic accuracy on 122 systems is presented without any description of the experimental protocol, baseline implementations, statistical tests, data-generation details, or selection criteria for the 122 systems, rendering the quantitative results unverifiable.
- [Abstract] Abstract: the mechanism that LLM-proposed operator priors create distinct regions and that candidate disagreement reliably selects informative trajectories is asserted as the source of the performance gap, yet no ablation is described that holds the acquisition strategy fixed while removing the LLM prior step, nor any quantitative correlation between disagreement and reduction in posterior entropy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and provide additional supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of orders-of-magnitude lower median NMSE and 46–52% symbolic accuracy on 122 systems is presented without any description of the experimental protocol, baseline implementations, statistical tests, data-generation details, or selection criteria for the 122 systems, rendering the quantitative results unverifiable.
Authors: We agree that the abstract's brevity omits these details. The full manuscript describes the experimental protocol, baseline implementations, statistical tests, data-generation process, and selection criteria for the 122 systems in Sections 4.1, 4.2, and 5. We will revise the abstract to include a concise summary of the experimental setup and direct readers to the relevant sections, thereby improving verifiability while respecting length limits. revision: yes
-
Referee: [Abstract] Abstract: the mechanism that LLM-proposed operator priors create distinct regions and that candidate disagreement reliably selects informative trajectories is asserted as the source of the performance gap, yet no ablation is described that holds the acquisition strategy fixed while removing the LLM prior step, nor any quantitative correlation between disagreement and reduction in posterior entropy.
Authors: Section 6 of the manuscript includes ablations examining the LLM priors and disagreement-driven acquisition. However, we acknowledge that a targeted ablation holding the acquisition strategy fixed while removing only the LLM prior step is not explicitly presented, nor is a direct quantitative correlation between disagreement and posterior entropy reduction. We will add this specific ablation and the requested correlation analysis (including a new figure) in the revised manuscript to better substantiate the claimed mechanism. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper describes LLM-ACES as a procedural framework that uses an LLM to propose operator priors, fits candidate equations within partitioned regions, and employs candidate disagreement to drive adaptive trajectory acquisition. All reported results consist of comparative performance metrics (median NMSE, symbolic accuracy) measured on the fixed external benchmark collections ODEBench and ODEBase across 122 systems. No equation, theorem, or performance claim is shown to reduce by construction to a quantity defined inside the method itself; the evaluation remains independent of the fitted parameters or LLM proposals. Any self-citations that may exist are peripheral and do not carry the central empirical claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated operator priors can usefully partition the space of possible ODEs
invented entities (1)
-
LLM-ACES framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ensemble-sindy: Robust sparse model discovery in the low-data, high-noise limit, with active learning and control.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 478(2260), 2022
2022
-
[2]
Nikhil Abhyankar, Sanchit Kabra, Saaketh Desai, and Chandan K. Reddy. LLEMA: Evolutionary search with LLMs for multi-objective materials discovery. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[3]
Microsoft Research AI4Science and Microsoft Azure Quantum. The impact of large language models on scientific discovery: a preliminary study using gpt-4.arXiv preprint arXiv:2311.07361, 2023
arXiv 2023
-
[4]
Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal
Jordan T. Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. InInternational Conference on Learning Representations, 2020
2020
-
[5]
Mdbench: Benchmarking data-driven methods for model discovery
Amirmohammad Ziaei Bideh, Aleksandra Georgievska, and Jonathan Gryak. Mdbench: Benchmarking data-driven methods for model discovery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 19746–19754, 2026
2026
-
[6]
Amirmohammad Ziaei Bideh and Jonathan Gryak. Llm-ode: Data-driven discovery of dynamical systems with large language models.arXiv preprint arXiv:2603.20910, 2026
Pith/arXiv arXiv 2026
-
[7]
Neural symbolic regression that scales
Luca Biggio, Tommaso Bendinelli, Alexander Neitz, Aurelien Lucchi, and Giambattista Parascandolo. Neural symbolic regression that scales. InInternational conference on machine learning, pages 936–945. Pmlr, 2021
2021
-
[8]
Dynamic models of large-scale brain activity.Nature neuroscience, 20(3):340–352, 2017
Michael Breakspear. Dynamic models of large-scale brain activity.Nature neuroscience, 20(3):340–352, 2017
2017
-
[9]
Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the national academy of sciences, 113(15):3932–3937, 2016
Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the national academy of sciences, 113(15):3932–3937, 2016
2016
-
[10]
Active learning for regression based on query by committee
Robert Burbidge, Jem J Rowland, and Ross D King. Active learning for regression based on query by committee. InInternational conference on intelligent data engineering and automated learning, pages 209–218. Springer, 2007
2007
-
[11]
Operon c++ an efficient genetic programming framework for symbolic regression
Bogdan Burlacu, Gabriel Kronberger, and Michael Kommenda. Operon c++ an efficient genetic programming framework for symbolic regression. InProceedings of the 2020 genetic and evolutionary computation conference companion, pages 1562–1570, 2020
2020
-
[12]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[13]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
2018
-
[14]
Interpretable machine learning for science with pysr and symbolicregression
Miles Cranmer. Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582, 2023
Pith/arXiv arXiv 2023
-
[15]
ODEFormer: Symbolic regression of dynamical systems with transformers
Stéphane d’Ascoli, Sören Becker, Philippe Schwaller, Alexander Mathis, and Niki Kilbertus. ODEFormer: Symbolic regression of dynamical systems with transformers. InThe Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[16]
Symbolic regression with a learned concept library.Advances in Neural Information Processing Systems, 37:44678–44709, 2024
Arya Grayeli, Atharva Sehgal, Omar Costilla-Reyes, Miles Cranmer, and Swarat Chaudhuri. Symbolic regression with a learned concept library.Advances in Neural Information Processing Systems, 37:44678–44709, 2024
2024
-
[17]
Sok: Memorization in general-purpose large language models.arXiv preprint arXiv:2310.18362, 2023
Valentin Hartmann, Anshuman Suri, Vincent Bindschaedler, David Evans, Shruti Tople, and Robert West. Sok: Memorization in general-purpose large language models.arXiv preprint arXiv:2310.18362, 2023
arXiv 2023
-
[18]
Active learning improves performance on symbolic regression tasks in stackgp
Nathan Haut, Wolfgang Banzhaf, and Bill Punch. Active learning improves performance on symbolic regression tasks in stackgp. InProceedings of the Genetic and Evolutionary Computation Conference Companion, pages 550–553, 2022
2022
-
[19]
Active learning in genetic programming: Guiding efficient data collection for symbolic regression.IEEE Transactions on Evolutionary Computation, 29(4):1100–1111, 2024
Nathan Haut, Wolfgang Banzhaf, and Bill Punch. Active learning in genetic programming: Guiding efficient data collection for symbolic regression.IEEE Transactions on Evolutionary Computation, 29(4):1100–1111, 2024
2024
-
[20]
Active learning informs symbolic regression model development in genetic programming
Nathan Haut, Bill Punch, and Wolfgang Banzhaf. Active learning informs symbolic regression model development in genetic programming. InProceedings of the Companion Conference on Genetic and Evolutionary Computation, pages 587–590, 2023
2023
-
[21]
Taylor genetic programming for symbolic regression
Baihe He, Qiang Lu, Qingyun Yang, Jake Luo, and Zhiguang Wang. Taylor genetic programming for symbolic regression. InProceedings of the genetic and evolutionary computation conference, pages 946–954, 2022
2022
-
[22]
Active symbolic discovery of ordinary differential equations via phase portrait sketching
Nan Jiang, Md Nasim, and Yexiang Xue. Active symbolic discovery of ordinary differential equations via phase portrait sketching. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17626–17634, 2025
2025
-
[23]
Sanchit Kabra, Nikhil Abhyankar, Saaketh Desai, Prasad Iyer, and Chandan K Reddy. Llm- autoscilab: Closed-loop scientific discovery via active experimentation with llms.arXiv preprint arXiv:2605.24043, 2026
Pith/arXiv arXiv 2026
-
[24]
End-to-end symbolic regression with transformers.Advances in Neural Information Processing Systems, 35:10269–10281, 2022
Pierre-Alexandre Kamienny, Stéphane d’Ascoli, Guillaume Lample, and François Charton. End-to-end symbolic regression with transformers.Advances in Neural Information Processing Systems, 35:10269–10281, 2022
2022
-
[25]
Springer, 2018
Clement Kleinstreuer.Modern fluid dynamics. Springer, 2018
2018
-
[26]
Cosmology and controversy: The historical development of two theories of the universe
Helge Kragh. Cosmology and controversy: The historical development of two theories of the universe. 2021
2021
-
[27]
Large language models as evolution strategies
Robert Lange, Yingtao Tian, and Yujin Tang. Large language models as evolution strategies. InProceedings of the Genetic and Evolutionary Computation Conference Companion, pages 579–582, 2024
2024
-
[28]
Nicolas Le Novere, Benjamin Bornstein, Alexander Broicher, Melanie Courtot, Marco Donizelli, Harish Dharuri, Lu Li, Herbert Sauro, Maria Schilstra, Bruce Shapiro, et al. Biomodels database: a free, centralized database of curated, published, quantitative kinetic models of biochemical and cellular systems.Nucleic acids research, 34(suppl_1):D689–D691, 2006
2006
-
[29]
Evolution through large models
Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O Stanley. Evolution through large models. InHandbook of Evolutionary Machine Learning, pages 331–366. Springer, 2023
2023
-
[30]
Transformer-based model for symbolic regression via joint supervised learning
Wenqiang Li, Weijun Li, Linjun Sun, Min Wu, Lina Yu, Jingyi Liu, Yanjie Li, and Songsong Tian. Transformer-based model for symbolic regression via joint supervised learning. InThe eleventh international conference on learning representations, 2022
2022
-
[31]
Large language models as evolutionary optimizers
Shengcai Liu, Caishun Chen, Xinghua Qu, Ke Tang, and Yew-Soon Ong. Large language models as evolutionary optimizers. In2024 IEEE Congress on Evolutionary Computation (CEC), pages 1–8. IEEE, 2024
2024
-
[32]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024. 12
Pith/arXiv arXiv 2024
-
[33]
Odebase: a repository of ode systems for systems biology.Bioinformatics Advances, 2(1):vbac027, 2022
Christoph Lüders, Thomas Sturm, and Ovidiu Radulescu. Odebase: a repository of ode systems for systems biology.Bioinformatics Advances, 2(1):vbac027, 2022
2022
-
[34]
Eureka: Human-level reward design via coding large language models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[35]
Jordan, and Benjamin Recht
Horia Mania, Michael I. Jordan, and Benjamin Recht. Active learning for nonlinear system identification with guarantees.Journal of Machine Learning Research, 23(32):1–30, 2022
2022
-
[36]
In-context symbolic regression: Leveraging large language models for function discovery
Matteo Merler, Katsiaryna Haitsiukevich, Nicola Dainese, and Pekka Marttinen. In-context symbolic regression: Leveraging large language models for function discovery. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop), pages 427–444, 2024
2024
-
[37]
Weak sindy: Galerkin-based data-driven model selection.Multiscale Modeling & Simulation, 19(3):1474–1497, 2021
Daniel A Messenger and David M Bortz. Weak sindy: Galerkin-based data-driven model selection.Multiscale Modeling & Simulation, 19(3):1474–1497, 2021
2021
-
[38]
Sympy: symbolic computing in python.PeerJ Computer Science, 3:e103, jan 2017
Aaron Meurer et al. Sympy: symbolic computing in python.PeerJ Computer Science, 3:e103, jan 2017
2017
-
[39]
D-CODE: Discovering closed-form ODEs from observed trajectories
Zhaozhi Qian, Krzysztof Kacprzyk, and Mihaela van der Schaar. D-CODE: Discovering closed-form ODEs from observed trajectories. InInternational Conference on Learning Representations, 2022
2022
-
[40]
Towards scientific discovery with generative AI: Progress, opportunities, and challenges
Chandan K Reddy and Parshin Shojaee. Towards scientific discovery with generative AI: Progress, opportunities, and challenges. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 28601–28609, 2025
2025
-
[41]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
2024
-
[42]
Active learning literature survey
Burr Settles. Active learning literature survey. 2009
2009
-
[43]
Transformer- based planning for symbolic regression.Advances in Neural Information Processing Systems, 36:45907–45919, 2023
Parshin Shojaee, Kazem Meidani, Amir Barati Farimani, and Chandan Reddy. Transformer- based planning for symbolic regression.Advances in Neural Information Processing Systems, 36:45907–45919, 2023
2023
-
[44]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K. Reddy. LLM-SR: Scientific equation discovery via programming with large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[45]
Llm-srbench: A new benchmark for scientific equation discovery with large language models
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K Reddy. Llm-srbench: A new benchmark for scientific equation discovery with large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[46]
Westview press, 2001
Steven H Strogatz.Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering (studies in nonlinearity), volume 1. Westview press, 2001
2001
-
[47]
Optimistic active exploration of dynamical systems.Advances in Neural Information Processing Systems, 36:38122–38153, 2023
Bhavya Sukhija, Lenart Treven, Cansu Sancaktar, Sebastian Blaes, Stelian Coros, and Andreas Krause. Optimistic active exploration of dynamical systems.Advances in Neural Information Processing Systems, 36:38122–38153, 2023
2023
-
[48]
Symbolic physics learner: Discovering governing equations via monte carlo tree search
Fangzheng Sun, Yang Liu, Jian-Xun Wang, and Hao Sun. Symbolic physics learner: Discovering governing equations via monte carlo tree search. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[49]
Ai feynman: A physics-inspired method for symbolic regression.Science advances, 6(16):eaay2631, 2020
Silviu-Marian Udrescu and Max Tegmark. Ai feynman: A physics-inspired method for symbolic regression.Science advances, 6(16):eaay2631, 2020
2020
-
[50]
Mojtaba Valipour, Bowen You, Maysum Panju, and Ali Ghodsi. Symbolicgpt: A generative transformer model for symbolic regression.arXiv preprint arXiv:2106.14131, 2021. 13
arXiv 2021
-
[51]
Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
Pauli Virtanen, Ralf Gommers, Travis E Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, et al. Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
2020
-
[52]
Active learning for identification of linear dynamical systems
Andrew Wagenmaker and Kevin Jamieson. Active learning for identification of linear dynamical systems. In Jacob Abernethy and Shivani Agarwal, editors,Proceedings of Thirty Third Conference on Learning Theory, volume 125 ofProceedings of Machine Learning Research, pages 3487–3582. PMLR, 09–12 Jul 2020
2020
-
[53]
Springer Science & Business Media, 2013
John A Walker.Dynamical systems and evolution equations: theory and applications. Springer Science & Business Media, 2013
2013
-
[54]
Efficient evolutionary search over chemical space with large language models
Haorui Wang, Marta Skreta, Cher Tian Ser, Wenhao Gao, Lingkai Kong, Felix Strieth-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, Yuanqi Du, Alan Aspuru-Guzik, Kirill Neklyudov, and Chao Zhang. Efficient evolutionary search over chemical space with large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[55]
Inferring the structure of ordinary differential equations.arXiv preprint arXiv:2107.07345, 2021
Juliane Weilbach, Sebastian Gerwinn, Christian Weilbach, and Melih Kandemir. Inferring the structure of ordinary differential equations.arXiv preprint arXiv:2107.07345, 2021
arXiv 2021
-
[56]
Adaptive sampling methods for learning dynamical systems
Zichen Zhao and Qianxiao Li. Adaptive sampling methods for learning dynamical systems. In Bin Dong, Qianxiao Li, Lei Wang, and Zhi-Qin John Xu, editors,Proceedings of Mathematical and Scientific Machine Learning, volume 190 ofProceedings of Machine Learning Research, pages 335–350. PMLR, 15–17 Aug 2022
2022
-
[57]
unary_0": [
Tianshi Zheng, Kelvin Kiu Wai Tam, Newt Nguyen Kim Hue Nam, Baixuan Xu, Zhaowei Wang, Cheng Jiayang, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, Yangqiu Song, Ginny Wong, and Simon See. Newtonbench: Benchmarking generalizable scientific law discovery in LLM agents. InThe Fourteenth International Conference on Learning Representations, 2026. Re...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.