Systematic Exploration of 4-Expert Heterogeneous Mixture-of-Experts via Automated Pipeline Search
Pith reviewed 2026-06-26 10:40 UTC · model grok-4.3
The pith
Automated search for 4-expert heterogeneous MoE models shows entire space anchored to AirNet family by alphabetical enumeration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
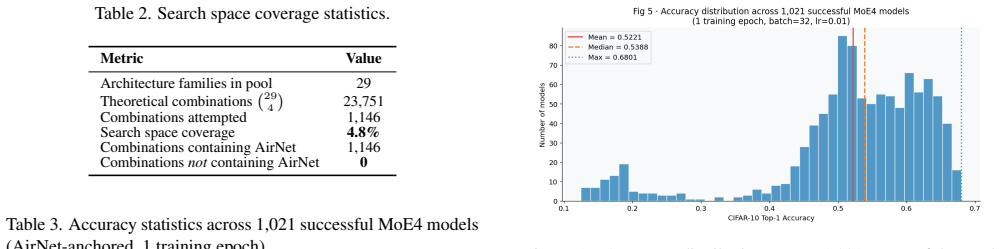
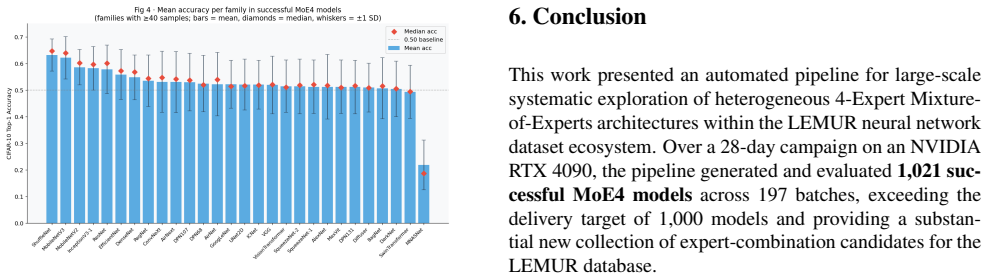
The deterministic code-assembly generator enumerates every 4-family combination in alphabetical order via itertools.combinations, so every tuple in the 4463-candidate campaign includes the AirNet family as its first member and the explored search space is therefore anchored to AirNet. This produces a precise coverage of 4.8 percent of the 23751 possible 4-family combinations. Inside that biased scope, ShuffleNet and MobileNetV3 families repeatedly yield the highest-accuracy MoE4 ensembles (mean accuracy up to 0.632), whereas FractalNet and MNASNet are low-yield and can be excluded. All models use a convolutional gating network with temperature scaling, mixup augmentation, and cosine-annealed
What carries the argument
The deterministic code-assembly generator that systematically combines LEMUR base architecture families into 4-expert MoE ensembles controlled by a convolutional gating network.
If this is right
- ShuffleNet and MobileNetV3 families should be retained in future 4-expert MoE ensembles because they consistently produce the highest accuracies in the evaluated set.
- FractalNet and MNASNet families can be dropped from subsequent searches because they yield low-performing combinations.
- The released stratified random sampling generator removes the alphabetical anchoring and permits unbiased coverage of the remaining 95.2 percent of 4-family combinations.
- The open pipeline and analysis artefacts allow direct reproduction of the 1021 evaluated models and extension to larger expert counts.
Where Pith is reading between the lines
- Alphabetical enumeration bias may affect other combinatorial neural-architecture-search pipelines that rely on similar deterministic generators without added randomization.
- If the LEMUR families do not cover important architectural variants outside the database, the observed performance ordering may shift when new families are added.
- The temperature scaling and mixup components of the gating network might interact differently with family combinations once the search is no longer forced to include AirNet in every model.
Load-bearing premise
The LEMUR database families form a representative and sufficient set of base architectures for heterogeneous 4-expert MoE search.
What would settle it
Running the corrected stratified random sampling generator across the full combination space and checking whether the highest-accuracy models still require AirNet or produce different family rankings would test whether the anchoring effect is real.
Figures
read the original abstract
We present an automated large-scale search pipeline for heterogeneous 4-Expert Mixture-of-Experts (MoE4) architectures within the LEMUR neural network dataset ecosystem. Building on a hand-crafted heterogeneous MoE reference model, we replace manual design with a deterministic code-assembly generator that systematically combines base architecture families drawn from the LEMUR database into MoE4 ensembles, each governed by a convolutional gating network with temperature scaling, mixup augmentation, and cosine-annealed learning rate scheduling. Over a 28-day campaign on an NVIDIA RTX 4090, the pipeline generated 4,463 candidate models across 197 batches, of which 1,021 were evaluated successfully. A critical finding emerged from the campaign: due to alphabetical enumeration via itertools.combinations, the entire explored search space (4.8% of the theoretical 23,751 possible 4-family combinations) is anchored to a single family, AirNet. We characterise this coverage bias precisely, identify the root cause in the generator, and propose a stratified random sampling fix. Within the AirNet anchored scope, ShuffleNet and MobileNetV3 consistently co-produce the highest-accuracy ensembles (mean accuracy up to 0.632), while FractalNet and MNASNet are identified as low-yield families warranting exclusion in future campaigns. The pipeline, analysis artefacts, and corrected generator are released as part of the open-source NNGPT project at https://github.com/ABrain-One/nn-gpt
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an automated pipeline for large-scale search of heterogeneous 4-expert Mixture-of-Experts (MoE4) architectures by combinatorially assembling base families from the LEMUR database. The pipeline generated 4,463 candidate models (4.8% of the 23,751 possible 4-family combinations) over 197 batches on a single RTX 4090, successfully evaluating 1,021 of them. The central finding is that alphabetical ordering combined with itertools.combinations anchors the entire explored subspace to the AirNet family; the authors precisely characterize this coverage bias, trace its root cause to the generator implementation, report all performance results strictly within the anchored scope (noting highest mean accuracy of 0.632 for ShuffleNet+MobileNetV3 ensembles), and release a stratified-sampling correction along with the full pipeline and artifacts under the NNGPT project.
Significance. If the bias characterization holds, the work provides a concrete, self-contained demonstration of how a standard library call can systematically skew combinatorial architecture search, with direct implications for reproducibility in neural architecture search and automated ML pipelines. Explicit credit is due for the release of the corrected generator, analysis artefacts, and reproducible code, which turns a methodological observation into an immediately usable contribution. The paper does not claim the LEMUR families are exhaustive or representative beyond the reported scope, keeping the central claim internally consistent.
minor comments (2)
- Abstract and results sections: the reported mean accuracy of 0.632 (and other performance figures) for specific family combinations lacks error bars, standard deviations, baseline comparisons to non-MoE models, or statistical significance tests; adding these would strengthen the secondary empirical claims without altering the bias analysis.
- The manuscript should explicitly state the precise stopping criterion or ordering that produced exactly the first 4,463 combinations out of 23,751, to allow readers to reproduce the anchored subspace without re-running the generator.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its significance in demonstrating enumeration bias in combinatorial NAS pipelines, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical observations only
full rationale
The paper reports results from running an automated search pipeline on trained models and directly observes an enumeration bias caused by itertools.combinations on an alphabetically ordered list. This is a methodological finding about their own generator code, verified by the released artifacts and the explicit count of 4,463 combinations anchored to AirNet. No equations, fitted parameters, or derivations reduce to inputs by construction. No self-citation load-bearing theorems or ansatzes are invoked. The LEMUR database assumption is stated as a scope limitation rather than a derived result. All outcomes are direct measurements, consistent with the reader's assessment of score 1.0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard training practices (mixup augmentation, cosine-annealed learning rate, temperature-scaled gating) transfer effectively to heterogeneous MoE4 models.
Reference graph
Works this paper leans on
-
[1]
Biased mix- ture of experts for efficient inference of deep neural net- works.IEEE Transactions on Image Processing, 29:7402– 7417, 2020
Taimoor Abbas and Yiannis Andreopoulos. Biased mix- ture of experts for efficient inference of deep neural net- works.IEEE Transactions on Image Processing, 29:7402– 7417, 2020
2020
-
[2]
Santosh Premi Adhikari, Radu Timofte, and Dmitry Ig- natov. Convergence theory for iterative llm-based neu- ral architecture search: A parametric cross-entropy frame- work with closed-form proxy reliability.arXiv preprint, arXiv:2605.30103, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Delta-Based Neural Architecture Search: LLM Fine-Tuning via Code Diffs
Santosh Premi Adhikari, Radu Timofte, and Dmitry Ignatov. Delta-based neural architecture search: LLM fine-tuning via code diffs.arXiv preprint, arXiv:2605.04903, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Network of experts for large-scale image categorization
Faisal Ahmed and Lorenzo Torresani. Network of experts for large-scale image categorization. InEuropean Confer- ence on Computer Vision (ECCV), pages 516–532. Springer, 2016
2016
-
[5]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
DeepSeek-AI. Deepseek-v2: A strong, economical, and ef- ficient mixture-of-experts language model.arXiv preprint arXiv:2401.06066, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025
Saif U Din, Muhammad Ahsan Hussain, Mohsin Ikram, Dmitry Ignatov, and Radu Timofte. AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025
2025
-
[7]
Enhancing LLM-based neural network generation: Few-shot prompting and efficient vali- dation for automated architecture design
Raghuvir Duvvuri, Chandini Vysyaraju, Avi Goyal, Dmitry Ignatov, and Radu Timofte. Enhancing LLM-based neural network generation: Few-shot prompting and efficient vali- dation for automated architecture design. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3242–3251, 2026
2026
-
[8]
LEMUR Neural Network Dataset: Towards Seamless AutoML
Arash Torabi Goodarzi, Roman Kochnev, Waleed Khalid, Furui Qin, Tolgay Atinc Uzun, Yashkumar Sanjaybhai Dhameliya, Yash Kanubhai Kathiriya, Zofia Antonina Ben- tyn, Dmitry Ignatov, and Radu Timofte. LEMUR neural net- work dataset: Towards seamless AutoML.arXiv preprint, arXiv:2504.10552, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Hard mix- ture of experts for large scale weakly supervised vision
Sam Gross, Michael Wilber, and Serge Belongie. Hard mix- ture of experts for large scale weakly supervised vision. In European Conference on Computer Vision (ECCV) Work- shops, 2017
2017
-
[10]
Resource- efficient iterative LLM-based NAS with feedback memory
Xiaojie Gu, Dmitry Ignatov, and Radu Timofte. Resource- efficient iterative LLM-based NAS with feedback memory. arXiv preprint, arXiv:2603.12091, 2026
-
[11]
Krunal Jesani, Dmitry Ignatov, and Radu Timofte. LLM as a neural architect: Controlled generation of image cap- tioning models under strict API contracts.arXiv preprint, arXiv:2512.14706, 2025
-
[12]
Real image denoising with knowl- edge distillation for high-performance mobile NPUs
Faraz Kayani, Sarmad Kayani, Asad Ahmed, Radu Timo- fte, and Dmitry Ignatov. Real image denoising with knowl- edge distillation for high-performance mobile NPUs. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3792– 3800, 2026
2026
-
[13]
A Retrieval-Augmented Generation Approach to Extracting Algorithmic Logic from Neural Networks
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. A retrieval-augmented generation approach to extracting al- gorithmic logic from neural networks.arXiv preprint, arXiv:2512.04329, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
From memorization to creativity: LLM as a designer of novel neu- ral architectures
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. From memorization to creativity: LLM as a designer of novel neu- ral architectures. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 3252–3261, 2026
2026
-
[15]
Roman Kochnev, Arash Torabi Goodarzi, Zofia Antonina Bentyn, Dmitry Ignatov, and Radu Timofte. Optuna vs code llama: Are LLMs a new paradigm for hyperparameter tun- ing? InProceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops (ICCVW), pages 5664– 5674, 2025
2025
-
[16]
NNGPT: Rethinking AutoML with large language models
Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chan- dini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Igna- tov, and Radu Timofte. NNGPT: Rethinking AutoML with large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 5664–5...
2026
-
[17]
MobileAgeNet: Lightweight facial age estimation for mobile deployment
Arun Kumar, Aswathy Baiju, Radu Timofte, and Dmitry Ig- natov. MobileAgeNet: Lightweight facial age estimation for mobile deployment. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 3810–3818, 2026
2026
-
[18]
Random search and repro- ducibility for neural architecture search
Liam Li and Ameet Talwalkar. Random search and repro- ducibility for neural architecture search. InUncertainty in Artificial Intelligence, pages 367–377, 2020
2020
-
[19]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. InInternational Confer- ence on Learning Representations, 2019
2019
-
[20]
Yash Mittal, Dmitry Ignatov, and Radu Timofte. Prepara- tion of fractal-inspired computational architectures for ad- vanced large language model analysis.arXiv preprint, arXiv:2511.07329, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Soft moe: Differentiable sparse mixture of experts.arXiv preprint arXiv:2306.09603, 2023
Joan Puigcerver, Carlos Riquelme, and Neil Houlsby. Soft moe: Differentiable sparse mixture of experts.arXiv preprint arXiv:2306.09603, 2023
-
[22]
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V . Le. Regularized evolution for image classifier architecture search. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4780–4789, 2019
2019
-
[23]
Scaling vision with sparse mixture of ex- perts
Carlos Riquelme, Joan Puigcerver, Alexander Kolesnikov, and Neil Houlsby. Scaling vision with sparse mixture of ex- perts. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[24]
Usha Shrestha, Dmitry Ignatov, and Radu Timofte. From brute force to semantic insight: Performance-guided data transformation design with LLMs.arXiv preprint, arXiv:2601.03808, 2026
-
[25]
Closed-loop LLM discovery of non-standard channel priors in vision models
Tolgay Atinc Uzun, Dmitry Ignatov, and Radu Timofte. Closed-loop LLM discovery of non-standard channel priors in vision models. InProceedings of the International Con- ference on Pattern Recognition (ICPR), 2026. to appear
2026
-
[26]
LEMUR 2: Unlocking neural net- work diversity for AI
Tolgay Atinc Uzun, Waleed Khalid, Saif U Din, Sai Re- vanth Mulukuledu, Akashdeep Singh, Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Yashkumar Rajeshbhai Lukhi, Ahsan Hussain, Krunal Jesani, Usha Shrestha, Yash Mittal, Roman Kochnev, Pritam Kadam, Mohsin Ikram, 7 Harsh Rameshbhai Moradiya, Alice Arslanian, Dmitry Ig- natov, and Radu Timofte. LEMUR 2:...
2026
-
[27]
Deep mixture of experts via shallow embedding
Guolong Wang, Tianlong Wang, Pengtao Xie, and Philip S Yu. Deep mixture of experts via shallow embedding. In Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), 2020
2020
-
[28]
Le, and J Ngiam
Brandon Yang, Gabriel Bender, Quoc V . Le, and J Ngiam. Condconv: Conditionally parameterized convolutions for ef- ficient inference. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2019
2019
-
[29]
Barret Zoph and Quoc V . Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2017. 8
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.