Fully Differentiable Neural Forced Alignment via Soft Dynamic Programming
Pith reviewed 2026-06-25 19:58 UTC · model grok-4.3
The pith
A fully differentiable neural model using soft dynamic programming outperforms HMM-GMM systems on phoneme alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an encoder-decoder network whose decoder implements alignment via trainable soft dynamic programming, when optimized end-to-end with a contrastive loss that pushes apart steady phoneme segments and boundary regions, produces higher-accuracy phoneme alignments than current state-of-the-art methods on hand-annotated English data, yields strong word-level generalization, and transfers to languages unseen during training.
What carries the argument
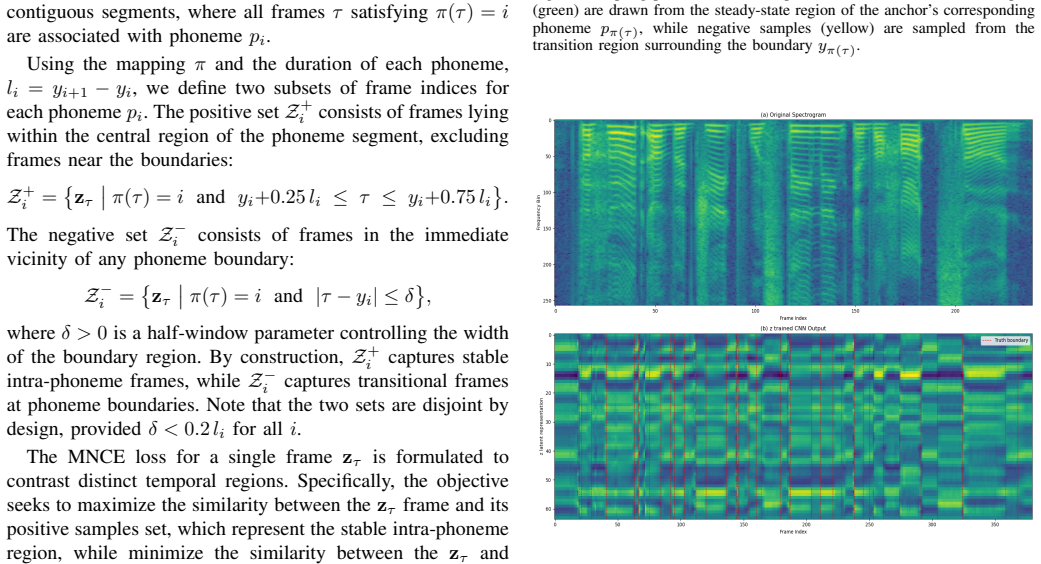
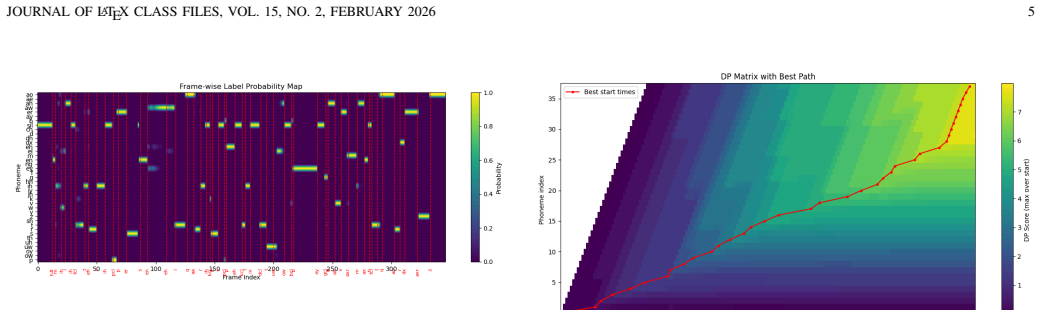
The trainable soft dynamic programming decoder that computes alignment paths in a differentiable manner so gradients can flow through the entire model.
If this is right
- Phoneme alignment accuracy exceeds current HMM-GMM systems on hand-annotated English benchmarks.
- The same model produces usable alignments at the word level without additional training.
- Alignment quality remains high on languages absent from the training data.
- Because the entire pipeline is differentiable, it can be inserted into larger end-to-end neural speech systems.
Where Pith is reading between the lines
- The architecture could be adapted to align other sequential units such as syllables or words without changing the loss or decoder structure.
- Integration with modern self-supervised audio encoders might further reduce the need for labeled alignment data.
- The soft dynamic programming component may serve as a drop-in differentiable replacement for alignment steps in other sequence-to-sequence tasks.
Load-bearing premise
The contrastive loss will produce sufficiently clear separation between steady-state phoneme regions and transition boundaries for the soft dynamic programming decoder to recover accurate alignments.
What would settle it
A direct comparison on a standard hand-annotated English benchmark such as TIMIT showing that the neural model does not exceed the alignment accuracy of the strongest HMM-GMM baseline would falsify the performance claim.
Figures



read the original abstract
Recent advances in sequence modeling have significantly improved ASR systems, bringing them close to human-level recognition accuracy and enhancing robustness across diverse acoustic conditions and languages. In contrast, Forced Alignment has not experienced comparable progress, and traditional HMM-GMM frameworks remain widely adopted and highly competitive. To address this gap, we propose an end-to-end, fully differentiable neural architecture specifically designed for phoneme alignment. The model consists of an encoder that processes the input signal and a decoder that produces alignment decisions. The encoder is structured into two complementary branches: one dedicated to phoneme identity verification and the other to phoneme boundary detection. The decoder is implemented as a trainable module based on differentiable soft dynamic programming. The entire system is optimized end-to-end using a novel contrastive loss that encourages clear separation between steady-state phoneme regions and transition boundaries. The proposed approach outperforms the current state of the art in phoneme alignment on hand-annotated English benchmarks, achieves strong word-level generalization results, and demonstrates generalization on unseen languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fully differentiable end-to-end neural architecture for phoneme forced alignment. It consists of a dual-branch encoder (one branch for phoneme identity verification, one for boundary detection), a decoder implemented via trainable soft dynamic programming, and end-to-end optimization with a novel contrastive loss that separates steady-state phoneme regions from transition boundaries. The central claims are outperformance versus state-of-the-art methods on hand-annotated English benchmarks, strong word-level generalization, and generalization to unseen languages.
Significance. If the performance claims hold under detailed experimental scrutiny, the work would be significant: it would supply the first fully differentiable neural replacement for traditional HMM-GMM forced aligners, enabling direct integration with modern sequence models and potentially improving robustness across languages and acoustic conditions.
major comments (2)
- [Abstract] Abstract: the claim that the approach 'outperforms the current state of the art in phoneme alignment on hand-annotated English benchmarks' is presented without any quantitative results, baselines, error metrics, or experimental protocol. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the reported gains are real or reducible to the fitted quantities.
- [Abstract] Abstract: no equations, loss formulation, or architectural hyperparameters are supplied for the contrastive loss, the soft dynamic programming decoder, or the dual-branch encoder. Without these details it is impossible to verify the differentiability claim or to determine whether the separation between steady-state and boundary regions is achieved by construction rather than by the proposed loss.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. Both points identify areas where the abstract can be strengthened for clarity and verifiability while preserving its concise nature. We will revise the abstract accordingly and ensure the central claims are better supported at the summary level. Full technical details and results remain in the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'outperforms the current state of the art in phoneme alignment on hand-annotated English benchmarks' is presented without any quantitative results, baselines, error metrics, or experimental protocol. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the reported gains are real or reducible to the fitted quantities.
Authors: We agree that the abstract would benefit from including quantitative support for the performance claim. In the revised manuscript we will add a concise statement of key results (e.g., phoneme boundary error rates versus MFA and other neural baselines on the hand-annotated English test sets) together with a brief reference to the evaluation protocol. The complete experimental setup, metrics, and tables appear in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract: no equations, loss formulation, or architectural hyperparameters are supplied for the contrastive loss, the soft dynamic programming decoder, or the dual-branch encoder. Without these details it is impossible to verify the differentiability claim or to determine whether the separation between steady-state and boundary regions is achieved by construction rather than by the proposed loss.
Authors: Abstracts conventionally omit equations and hyperparameters; these are fully specified in Sections 2 (dual-branch encoder), 3 (soft dynamic programming decoder), and the loss definition. To improve standalone readability we will expand the abstract with a short qualitative description of the contrastive loss objective and the end-to-end differentiability of the soft DP module. The precise formulations and hyperparameter values stay in the technical sections. revision: partial
Circularity Check
No significant circularity identified
full rationale
The abstract and summary describe a coherent end-to-end architecture consisting of a dual-branch encoder, a trainable soft dynamic programming decoder, and a novel contrastive loss, with performance claims on external hand-annotated benchmarks. No equations, self-citations, fitted parameters renamed as predictions, or load-bearing uniqueness theorems are provided in the given text that would allow any claimed result to reduce to its inputs by construction. The central claims remain empirically testable against independent data and are not shown to be self-definitional or forced by prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Montreal Forced Aligner: Trainable text-speech alignment using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal Forced Aligner: Trainable text-speech alignment using Kaldi,” inProceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech), Aug. 2017, pp. 498– 502
2017
-
[2]
Discriminative pronunciation modeling: A large-margin, feature-rich approach,
H. Tang, J. Keshet, and K. Livescu, “Discriminative pronunciation modeling: A large-margin, feature-rich approach,” inProceedings of the 50th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2012, pp. 194–203
2012
-
[3]
Insights into spoken lan- guage gleaned from phonetic transcription of the switchboard corpus,
S. Greenberg, J. Hollenback, and D. Ellis, “Insights into spoken lan- guage gleaned from phonetic transcription of the switchboard corpus,” inProceedings of the International Conference on Spoken Langugae Processing, vol. 96, 1996, pp. 24–27
1996
-
[4]
wav2vec 2.0: a framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representations,” in Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[5]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
2021
-
[6]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,”arXiv preprint arXiv:2212.04356, 2022
Pith/arXiv arXiv 2022
-
[7]
Tradition or innova- tion: A comparison of modern ASR methods for forced alignment,
R. Rousso, E. Cohen, J. Keshet, and E. Chodroff, “Tradition or innova- tion: A comparison of modern ASR methods for forced alignment,” in The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024
2024
-
[8]
WhisperX: Time-accurate speech transcription of long-form audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time-accurate speech transcription of long-form audio,” inProceedings of the 24th An- nual Conference of the International Speech Communication Association (Interspeech), 2023
2023
-
[9]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandiet al., “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Re- search, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[10]
M. Sekoyan, N. R. Koluguri, N. Tadevosyan, P. Zelasko, T. Bartley, N. Karpov, J. Balam, and B. Ginsburg, “Canary-1b-v2 & parakeet-tdt- 0.6b-v3: Efficient and high-performance models for multilingual asr and ast,”arXiv preprint arXiv:2509.14128, 2025
arXiv 2025
-
[11]
Connec- tionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,
A. Graves, S. Fernandez, F. Gomez, and J. Schmidhuber, “Connec- tionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,”Proceedings of the 23rd International Conference on Machine Learning, pp. 369–376, 2006
2006
-
[12]
Self-supervised contrastive learning for unsupervised phoneme segmentation,
F. Kreuk, J. Keshet, and Y . Adi, “Self-supervised contrastive learning for unsupervised phoneme segmentation,” inProceedings of the 21th Annual Conference of the International Speech Communication Association (Interspeech), 2020
2020
-
[13]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[14]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,”arXiv preprint arXiv:1904.05862, 2019
arXiv 1904
-
[15]
A large margin algorithm for speech-to-phoneme and music-to-score alignment,
J. Keshet, S. Shalev-Shwartz, Y . Singer, and D. Chazan, “A large margin algorithm for speech-to-phoneme and music-to-score alignment,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 8, pp. 2373–2382, Oct. 2007
2007
-
[16]
Soft-dtw: a differentiable loss function for time-series,
M. Cuturi and M. Blondel, “Soft-dtw: a differentiable loss function for time-series,” inInternational conference on machine learning. PMLR, 2017, pp. 894–903
2017
-
[17]
DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM. NIST speech disc 1-1.1,
J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, and D. S. Pallett, “DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM. NIST speech disc 1-1.1,” NASA, Tech. Rep. 93, Feb. 1993
1993
-
[18]
The Buckeye corpus of conversational speech: labeling conventions and a test of transcriber reliability,
M. A. Pitt, K. Johnson, E. Hume, S. Kiesling, and W. Raymond, “The Buckeye corpus of conversational speech: labeling conventions and a test of transcriber reliability,”Speech Communication, vol. 45, no. 1, pp. 89–95, Jan. 2005
2005
-
[19]
Phoneme boundary detec- tion using learnable segmental features,
F. Kreuk, Y . Sheena, J. Keshet, and Y . Adi, “Phoneme boundary detec- tion using learnable segmental features,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 8089–8093
2020
-
[20]
The IFA corpus: A phonemically segmented Dutch open source speech database,
R. V . Son, D. Binnenpoorte, H. van den Heuvel, and L. Pols, “The IFA corpus: A phonemically segmented Dutch open source speech database,” inProc. EUROSPEECH 2001, Aalborg, Denmark, vol. 3, 2001, pp. 2051–2054. [Online]. Available: https://zenodo.org/records/14904090
arXiv 2001
-
[21]
Theoretical principles concerning segmentation, labelling strategies and levels of categorical annotation for spoken language database systems,
H. G. Tillmann and B. Pompino-Marschall, “Theoretical principles concerning segmentation, labelling strategies and levels of categorical annotation for spoken language database systems,” inProc. Eurospeech 1993, 1993, pp. 1691–1694
1993
-
[22]
Automatic tools for analyzing spoken hebrew,
A. Ben-Shalom, D. Modan, A. Laufer, and J. Keshet, “Automatic tools for analyzing spoken hebrew,” inThe 2014 Afeka Conference for Speech Processing, 2014. JOURNAL OF LATEX CLASS FILES, VOL. 15, NO. 2, FEBRUARY 2026 10
2014
-
[23]
Rectifier nonlinearities improve neural network acoustic models,
A. L. Maas, A. Y . Hannun, A. Y . Nget al., “Rectifier nonlinearities improve neural network acoustic models,” inProc. icml, vol. 30, no. 1. Atlanta, GA, 2013, p. 3
2013
-
[24]
Speaker-independent phone recognition using hidden markov models,
K.-F. Lee and H.-W. Hon, “Speaker-independent phone recognition using hidden markov models,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 11, pp. 1641–1648, 1989
1989
-
[25]
Panphon: A resource for mapping IPA segments to articulatory feature vectors,
D. R. Mortensen, P. Littell, A. Bharadwaj, K. Goyal, C. Dyer, and L. S. Levin, “Panphon: A resource for mapping IPA segments to articulatory feature vectors,” inProceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. ACL, 2016, pp. 3475–3484
2016
-
[26]
Pynini: A python library for weighted finite-state grammar compilation,
K. Gorman, “Pynini: A python library for weighted finite-state grammar compilation,” inProceedings of the ACL Workshop on Statistical NLP and Weighted Automata, 2016, pp. 75–80
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.