Optimal Rates for Differentially Private Hypothesis Testing with E-values
Pith reviewed 2026-06-29 11:21 UTC · model grok-4.3
The pith
An explicit algorithm achieves the exact optimal e-power rate for ε-differentially private hypothesis testing of P against Q.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given two distributions P and Q, the maximum achievable e-power for testing X ~ P^n against X ~ Q^n with e-values that satisfy ε-differential privacy is characterized by an optimal rate, and there exists an algorithm that matches this rate exactly. In the sequential setting, when observations arrive one-by-one and the analyst chooses when to halt, matching upper and lower bounds are given on the stopping times of any private e-process.
What carries the argument
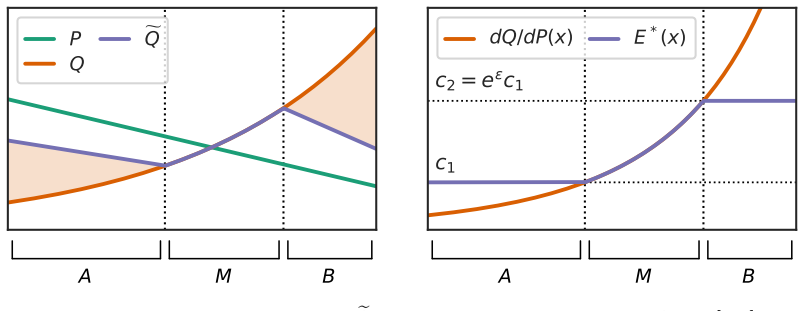
The ε-differentially private e-value construction that attains the characterized optimal e-power rate for distinguishing P from Q.
If this is right
- The minimal number of samples required to reach a target e-power level under ε-privacy is now known exactly.
- Sequential private testing procedures have stopping times that cannot be improved beyond the matching bounds without violating privacy or validity.
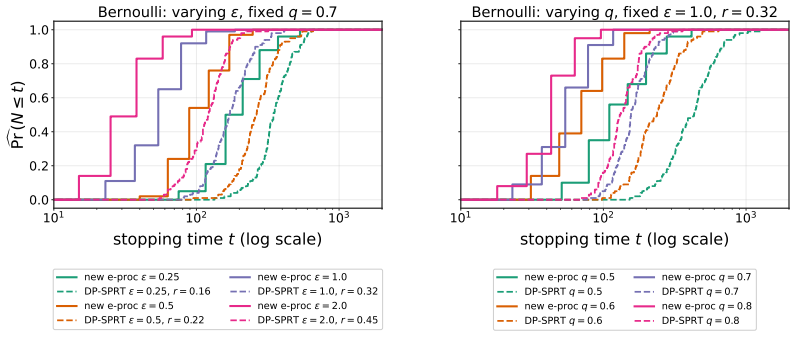
- The supplied algorithm requires fewer samples than DP-SPRT across tested sequential problems and privacy levels.
- The same rate and bounds apply uniformly to any pair of distributions P and Q.
Where Pith is reading between the lines
- The optimality result may extend to composite or nonparametric hypotheses if similar privacy-preserving constructions can be found.
- The bounds could inform privacy-utility trade-offs in other e-value applications such as multiple testing or change-point detection.
- In deployment, the explicit rate gives a concrete way to set sample sizes for private anytime-valid tests in domains requiring both validity and privacy.
Load-bearing premise
The e-values are constructed from n i.i.d. samples drawn from either P or Q while satisfying the ε-differential privacy definition.
What would settle it
Finding an ε-differentially private e-value whose e-power grows faster than the characterized optimal rate for some fixed P, Q and ε, or a private e-process whose stopping time falls below the derived lower bound, would falsify the optimality claim.
Figures
read the original abstract
E-values have attracted considerable interest in recent years as flexible tools for enabling anytime-valid and adaptive data analysis. Hypothesis testing is at the core of many of these applications, which can often involve private or sensitive data. In this work, we answer a simple but important question: given two distributions $\mathbb{P}$ and $\mathbb{Q}$, what is the maximum achievable e-power when testing $X\sim \mathbb{P}^n$ against $X\sim\mathbb{Q}^n$ with e-values that satisfy $\varepsilon$-differential privacy? We characterize the optimal rate for this problem and provide an algorithm which matches it exactly. In the sequential setting, when observations arrive one-by-one and the analyst chooses when to halt, we give matching upper and lower bounds on the stopping times of any private e-process. Numerical experiments confirm the practicality of our algorithms, which require less data than the recently proposed DP-SPRT across a range of sequential testing problems and privacy levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper characterizes the optimal e-power rate achievable by ε-differentially private e-values for simple hypothesis testing between two fixed distributions P and Q on the basis of n i.i.d. samples. It supplies an explicit algorithm attaining this rate exactly. In the sequential setting it derives matching upper and lower bounds on the stopping times of any ε-DP e-process. Numerical experiments are reported showing that the proposed procedures require fewer samples than DP-SPRT across several privacy levels.
Significance. If the claimed characterization and matching bounds hold, the work supplies the first tight information-theoretic limits for private e-value testing together with explicit, practical mechanisms. The combination of batch optimality, sequential stopping-time bounds, and empirical outperformance of prior methods constitutes a substantive contribution to the intersection of differential privacy and anytime-valid inference.
minor comments (2)
- [Abstract] The abstract states that the algorithm 'matches it exactly'; the main text should explicitly state whether this is with respect to the leading constant or only the asymptotic rate (e.g., §3 or §4).
- [Section 3] Notation for the privacy parameter is introduced as ε but the dependence on ε is not displayed in the displayed rate expressions; adding the explicit functional dependence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive and accurate summary of our work, as well as their recommendation to accept the manuscript. We are pleased that the contributions on optimal e-power rates, the explicit algorithm, sequential stopping-time bounds, and empirical comparisons were viewed as substantive.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper characterizes optimal e-power rates for ε-DP hypothesis testing between P^n and Q^n by deriving matching upper and lower bounds from standard change-of-measure arguments and privacy-loss accounting applied to the external definitions of e-power (expectation under the alternative) and ε-differential privacy. The sequential stopping-time bounds follow similarly from these primitives without reducing any claimed optimum to a fitted quantity or self-citation chain internal to the paper. No load-bearing step equates a result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math E-values are non-negative random variables whose expectation is at most 1 under the null hypothesis
- standard math The mechanism producing the e-value must satisfy ε-differential privacy
Reference graph
Works this paper leans on
-
[1]
John M. Abowd. The U.S. census bureau adopts differential privacy. InInternational Conference on Knowledge Discovery & Data Mining, page 2867. ACM, 2018. doi: 10.1145/3219819. 3226070. URLhttps://doi.org/10.1145/3219819.3226070
-
[2]
Scientists rise up against statistical significance.Nature, 567(7748):305–307, 2019
Valentin Amrhein, Sander Greenland, and Blake McShane. Scientists rise up against statistical significance.Nature, 567(7748):305–307, 2019
2019
-
[3]
Duchi, Saminul Haque, Zewei Li, and Feng Ruan
Hilal Asi, John C. Duchi, Saminul Haque, Zewei Li, and Feng Ruan. Universally instance- optimal mechanisms for private statistical estimation. InConference on Learning Theory, volume 247 ofProceedings of Machine Learning Research, pages 221–259. PMLR, 2024
2024
-
[4]
Differentially Private Best-Arm Identification
Achraf Azize, Marc Jourdan, Aymen Al Marjani, and Debabrota Basu. Differentially private best-arm identification, 2026. URLhttps://arxiv.org/abs/2406.06408
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Privacy amplification by subsampling: Tight analyses via couplings and divergences
Borja Balle, Gilles Barthe, and Marco Gaboardi. Privacy amplification by subsampling: Tight analyses via couplings and divergences. InConference on Neural Information Processing Sys- tems, volume 31, 2018. URL https://proceedings.neurips.cc/paper_files/paper/ 2018/file/3b5020bb891119b9f5130f1fea9bd773-Paper.pdf
2018
-
[6]
The structure of optimal private tests for simple hypotheses
Clément L Canonne, Gautam Kamath, Audra McMillan, Adam Smith, and Jonathan Ullman. The structure of optimal private tests for simple hypotheses. InSymposium on Theory of Computing, pages 310–321, 2019. doi: 10.1145/3313276.3316336
-
[7]
Auditing fair- ness by betting
Ben Chugg, Santiago Cortes-Gomez, Bryan Wilder, and Aaditya Ramdas. Auditing fair- ness by betting. InConference on Neural Information Processing Systems, volume 36, pages 6070–6091, 2023. URL https://proceedings.neurips.cc/paper_files/paper/ 2023/file/1338c277525011f20166cf740952bb47-Paper-Conference.pdf. 11
2023
-
[8]
E-values as statistical evidence: A compari- son to bayes factors, likelihoods, and p-values, 2026
Ben Chugg, Aaditya Ramdas, and Peter Grünwald. E-values as statistical evidence: A compari- son to bayes factors, likelihoods, and p-values, 2026. URL https://arxiv.org/abs/2603. 24421
2026
-
[9]
Unbiased statistical esti- mation and valid confidence intervals under differential privacy.Statistica Sinica, 35:651–670, 2025
Christian Covington, Xi He, James Honaker, and Gautam Kamath. Unbiased statistical esti- mation and valid confidence intervals under differential privacy.Statistica Sinica, 35:651–670, 2025
2025
-
[10]
Differentially private e-values
Daniel Csillag and Diego Mesquita. Differentially private e-values. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. doi: 10.48550/arXiv.2510.18654. URLhttps://openreview.net/forum?id=8Tvn60M7jV
-
[11]
Differentially private change-point detection
Rachel Cummings, Sara Krehbiel, Yajun Mei, Rui Tuo, and Wanrong Zhang. Differentially private change-point detection. InConference on Neural Information Processing Systems, page 10848–10857, Red Hook, NY , USA, 2018. Curran Associates Inc
2018
-
[12]
Geometrizing rates of convergence, ii.The Annals of Statistics, 19, 06 1991
David Donoho and Richard Liu. Geometrizing rates of convergence, ii.The Annals of Statistics, 19, 06 1991. doi: 10.1214/aos/1176348114
-
[13]
John C. Duchi, Michael I. Jordan, and Martin J. Wainwright. Local privacy and statistical minimax rates. InSymposium on Foundations of Computer Science, pages 429–438, 2013. doi: 10.1109/FOCS.2013.53
-
[14]
The algorithmic foundations of differential privacy.Found
Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy.Found. Trends Theor. Comput. Sci., 9(3-4):211–407, 2014. doi: 10.1561/0400000042. URL https: //doi.org/10.1561/0400000042
-
[15]
Emerald Group Publishing, 2025
Ferdinando Fioretto and Pascal Van Hentenryck.Differential Privacy in Artificial Intelligence: From Theory to Practice. Emerald Group Publishing, 2025
2025
-
[16]
Sequentially auditing differential privacy
Tomás González, Mateo Dulce Rubio, Aaditya Ramdas, and Mónica Ribero. Sequentially auditing differential privacy. InConference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=tlmKcZFAtL
2026
-
[17]
Peter Grünwald, Rianne de Heide, and Wouter M. Koolen. Safe Testing. In2020 Information Theory and Applications Workshop (ITA), pages 1–54, feb 2020. doi: 10.1109/ITA50056.2020. 9244948. URL https://ieeexplore.ieee.org/document/9244948/. ISSN: 2642-7338
-
[18]
Shan Huang and David Goretzko. Controlling the false discovery rate in dif detection with e- values: Evidence from multidimensional and testlet simulations.Educational and Psychological Measurement, page 00131644261433236, 2026
2026
-
[19]
Peter J. Huber. A robust version of the probability ratio test.The Annals of Mathematical Statistics, 36(6):1753–1758, 1965. ISSN 00034851. URL http://www.jstor.org/stable/ 2239116
1965
-
[21]
Peter J. Huber and V olker Strassen. Minimax tests and the neyman-pearson lemma for capacities. The Annals of Statistics, 1(2):251–263, 1973. ISSN 00905364, 21688966. URL http://www. jstor.org/stable/2958011
-
[22]
Extremal mechanisms for local differential privacy.Journal of Machine Learning Research, 17(1):492–542, January 2016
Peter Kairouz, Sewoong Oh, and Pramod Viswanath. Extremal mechanisms for local differential privacy.Journal of Machine Learning Research, 17(1):492–542, January 2016. ISSN 1532- 4435
2016
-
[23]
What can we learn privately?SIAM Journal on Computing, 40(3):793–826, 2011
Shiva Prasad Kasiviswanathan, Homin K Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. What can we learn privately?SIAM Journal on Computing, 40(3):793–826, 2011. doi: 10.1137/090756090
-
[24]
The test of tests: a framework for differentially private hypothesis testing
Zeki Kazan, Kaiyan Shi, Adam Groce, and Andrew Bray. The test of tests: a framework for differentially private hypothesis testing. InInternational Conference on Machine Learning, ICML’23. JMLR.org, 2023. 12
2023
-
[25]
Vector-valued self-normalized concentration inequalities beyond sub-gaussianity
Diego Martinez-Taboada, Tomás González, and Aaditya Ramdas. Vector-valued self-normalized concentration inequalities beyond sub-gaussianity. InInternational Conference on Algorithmic Learning Theory, 2026. URLhttps://openreview.net/forum?id=Y98zW0bDL0
2026
-
[26]
Instance-optimal differentially private estima- tion, 2022
Audra McMillan, Adam Smith, and Jon Ullman. Instance-optimal differentially private estima- tion, 2022. URLhttps://arxiv.org/abs/2210.15819
-
[27]
DP-SPRT: differentially private sequential probability ratio tests.CoRR, abs/2508.06377, 2025
Thomas Michel, Debabrota Basu, and Emilie Kaufmann. DP-SPRT: differentially private sequential probability ratio tests.CoRR, abs/2508.06377, 2025. doi: 10.48550/arXiv.2508. 06377. URLhttps://doi.org/10.48550/arXiv.2508.06377
-
[28]
Cambridge University Press, 2005
Michael Mitzenmacher and Eli Upfal.Probability and Computing: Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, 2005. ISBN 978-0-521-83540-4. doi: 10.1017/CBO9780511813603. URLhttps://doi.org/10.1017/CBO9780511813603
-
[29]
Konstantinos E. Nikolakakis, Dionysios S. Kalogerias, Or Sheffet, and Anand D. Sarwate. Quantile multi-armed bandits: Optimal best-arm identification and a differentially private scheme.IEEE J. Sel. Areas Inf. Theory, 2(2):534–548, 2021. doi: 10.1109/JSAIT.2021.3081525. URLhttps://doi.org/10.1109/JSAIT.2021.3081525
-
[30]
Cambridge university press, 2025
Yury Polyanskiy and Yihong Wu.Information theory: From coding to learning. Cambridge university press, 2025
2025
-
[31]
Hypothesis Testing with E-values.Foundations and Trends in Statistics, Vol
Aaditya Ramdas and Ruodu Wang. Hypothesis Testing with E-values.Foundations and Trends in Statistics, Vol. 1: No. 1-2, pp 1-390, 2025. doi: 10.1561/3600000002
-
[32]
Admissible anytime-valid sequential inference must rely on nonnegative martingales, nov 2022
Aaditya Ramdas, Johannes Ruf, Martin Larsson, and Wouter Koolen. Admissible anytime-valid sequential inference must rely on nonnegative martingales, nov 2022. URL http://arxiv. org/abs/2009.03167. arXiv:2009.03167 [math]
-
[33]
Aaditya Ramdas, Peter Grünwald, Vladimir V ovk, and Glenn Shafer. Game-Theoretic Statistics and Safe Anytime-Valid Inference.Statistical Science, 38(4):576 – 601, 2023. doi: 10.1214/ 23-STS894. URLhttps://doi.org/10.1214/23-STS894
-
[34]
A New Class of Private Chi-Square Hypothesis Tests
Ryan Rogers and Daniel Kifer. A New Class of Private Chi-Square Hypothesis Tests. In International Conference on Artificial Intelligence and Statistics, volume 54 ofProceedings of Machine Learning Research, pages 991–1000. PMLR, 20–22 Apr 2017. URL https: //proceedings.mlr.press/v54/rogers17a.html
2017
-
[35]
Optimal e-variables under constraints
Aytijhya Saha and Aaditya Ramdas. Optimal e-variables under constraints, 2026. URL https://arxiv.org/abs/2604.21680
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Testing by betting: A strategy for statistical and scientific communication
Glenn Shafer. Testing by betting: A strategy for statistical and scientific communication. Journal of the Royal Statistical Society: Series A (Statistics in Society), 184:407–431, 04 2021. doi: 10.1111/rssa.12647
-
[37]
Jaehyeok Shin, Aaditya Ramdas, and Alessandro Rinaldo. E-detectors: A nonparametric framework for sequential change detection.The New England Journal of Statistics in Data Science, 2(2):229–260, 2024. ISSN 2693-7166. doi: 10.51387/23-NEJSDS51
-
[38]
E-values for adaptive clinical trials: Anytime-valid monitoring in practice, 2026
Alexandra Sokolova and Vadim Sokolov. E-values for adaptive clinical trials: Anytime-valid monitoring in practice, 2026. URLhttps://arxiv.org/abs/2602.06379
-
[39]
Marika Swanberg, Ira Globus-Harris, Iris Griffith, Anna Ritz, Adam Groce, and Andrew Bray. Improved differentially private analysis of variance.Privacy Enhancing Technologies, 2019: 310–330, 07 2019. doi: 10.2478/popets-2019-0049
-
[40]
Judith ter Schure and Peter Grünwald. Accumulation bias in meta-analysis: the need to consider time in error control.F1000Research, 8:962, 2019. ISSN 2046-1402. doi: 10.12688/ f1000research.19375.1. URLhttp://dx.doi.org/10.12688/f1000research.19375.1
-
[41]
Vladimir V ovk and Ruodu Wang. Merging sequential e-values via martingales.Electronic Journal of Statistics, 18(1):1185 – 1205, 2024. doi: 10.1214/24-EJS2228. URL https: //doi.org/10.1214/24-EJS2228. 13
-
[42]
Differential privacy for clinical trial data: Preliminary evaluations
Duy Vu and Aleksandra Slavkovic. Differential privacy for clinical trial data: Preliminary evaluations. InIEEE International Conference on Data Mining Workshops, pages 138–143,
-
[43]
doi: 10.1109/ICDMW.2009.52
-
[44]
A. Wald. Sequential Tests of Statistical Hypotheses.The Annals of Mathematical Statistics, 16(2):117 – 186, 1945. doi: 10.1214/aoms/1177731118. URL https://doi.org/10.1214/ aoms/1177731118
-
[45]
Optimum character of the sequential probability ratio test
Abraham Wald and Jacob Wolfowitz. Optimum character of the sequential probability ratio test. The Annals of Mathematical Statistics, pages 326–339, 1948
1948
-
[46]
Revisiting Differentially Private Hypothesis Tests for Categorical Data
Yue Wang, Jaewoo Lee, and Daniel Kifer. Revisiting differentially private hypothesis tests for categorical data, 2017. URLhttps://arxiv.org/abs/1511.03376
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Ian Waudby-Smith, Philip B. Stark, and Aaditya Ramdas. Rilacs: Risk limiting audits via confidence sequences. InElectronic Voting, pages 124–139, Cham, 2021. Springer International Publishing. ISBN 978-3-030-86942-7. doi: 10.1007/978-3-030-86942-7_9
-
[48]
Nonparametric extensions of randomized response for private confidence sets
Ian Waudby-Smith, Zhiwei Steven Wu, and Aaditya Ramdas. Nonparametric extensions of randomized response for private confidence sets. InInternational Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 36748–36789. PMLR, 2023. doi: 10.48550/arXiv.2202.08728. URL https://proceedings.mlr.press/ v202/waudby-smith23a.html
-
[49]
Ian Waudby-Smith, Lili Wu, Aaditya Ramdas, Nikos Karampatziakis, and Paul Mineiro. Anytime-valid off-policy inference for contextual bandits.ACM / IMS Journal of Data Science, 1(3), May 2024. doi: 10.1145/3643693. URLhttps://doi.org/10.1145/3643693
-
[50]
Online multiple testing with e-values
Ziyu Xu and Aaditya Ramdas. Online multiple testing with e-values. InInternational Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learning Research, pages 3997–4005. PMLR, 02–04 May 2024. URL https://proceedings.mlr. press/v238/xu24a.html
2024
-
[51]
group privacy
Wanrong Zhang, Yajun Mei, and Rachel Cummings. Private sequential hypothesis testing for statisticians: Privacy, error rates, and sample size. InInternational Conference on Artificial Intelligence and Statistics, pages 11356–11373. PMLR, 2022. URL https://proceedings. mlr.press/v151/zhang22g.html. A Useful technical lemmas and definitions In this appendix...
2022
-
[52]
NmaxX t=1 (wt +a t){N≥t} # ≤E Q
Then by Lemma A.0.1, M(Pn)(A)≥e −nεM(Qn)>0 , and so M(Qn)≪ M(P n). Next, EM(X) is ε-DP by post-processing, and it is an e-variable because EPn [EM(X)] =R O(dM(Qn)/dM(Pn))dM(P n) = R O dM(Qn) = 1 . Finally, EQn [logE M(X)] = KL(M(Qn)∥ M(P n)) by the definition of KL-divergence, and as a likelihood ratio, EM is log- optimal for testingM(Q n)againstM(P n)by ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.