GEM: GPU-Variability-Aware Expert to GPU Mapping for MoE Systems
Pith reviewed 2026-05-20 04:27 UTC · model grok-4.3
The pith
Mapping experts in MoE models to GPUs while accounting for speed differences reduces straggler delays in synchronized token batches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
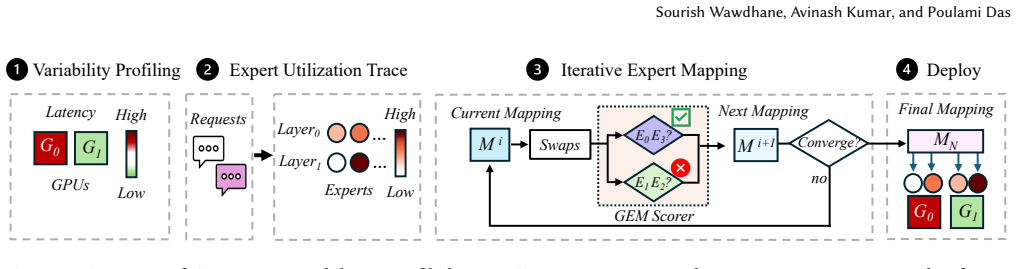
GEM gathers GPU variability profiles and per-task token load distributions, classifies experts into consistent and temporal types based on usage frequency and co-occurrence, and maps them so that simultaneously active consistent and temporal experts land on different GPUs while slower GPUs receive lighter loads; this equalizes finish times across the set of GPUs and thereby shortens the synchronization barrier that limits MoE throughput.
What carries the argument
The classification of experts into consistent (high-frequency) and temporal (co-occurring) types together with GPU speed profiling, which guides a static assignment that equalizes per-layer completion times.
If this is right
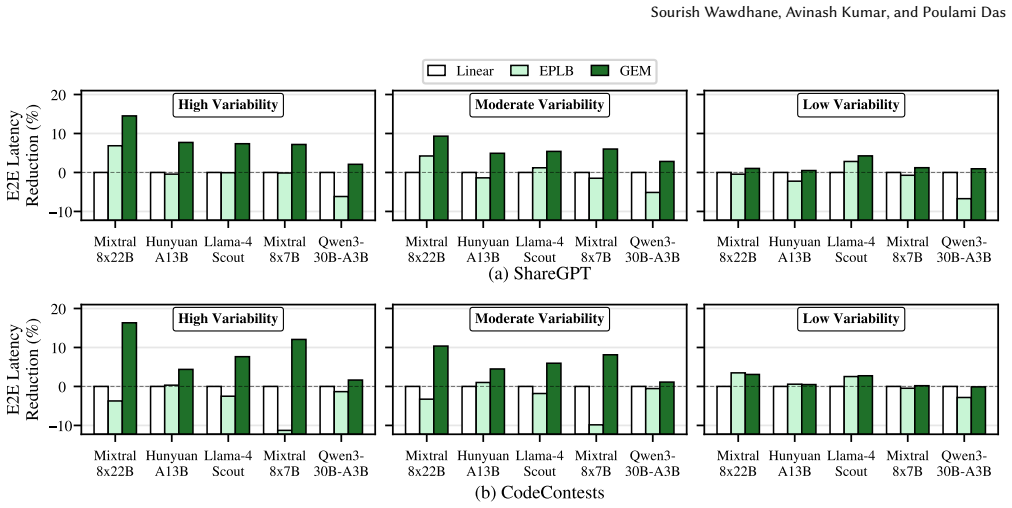
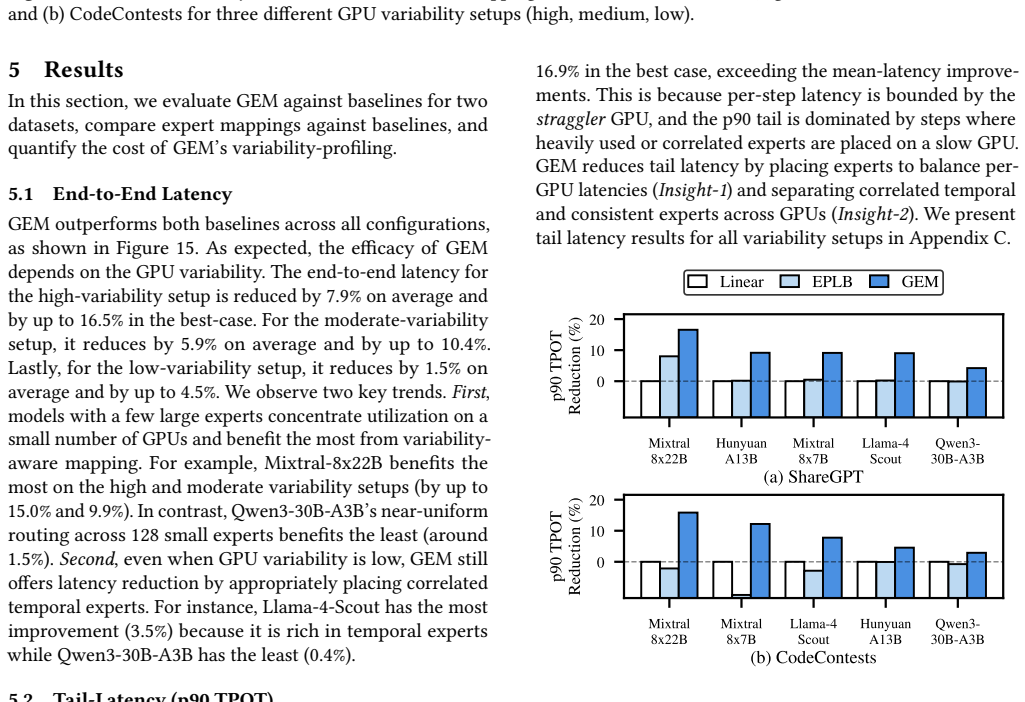
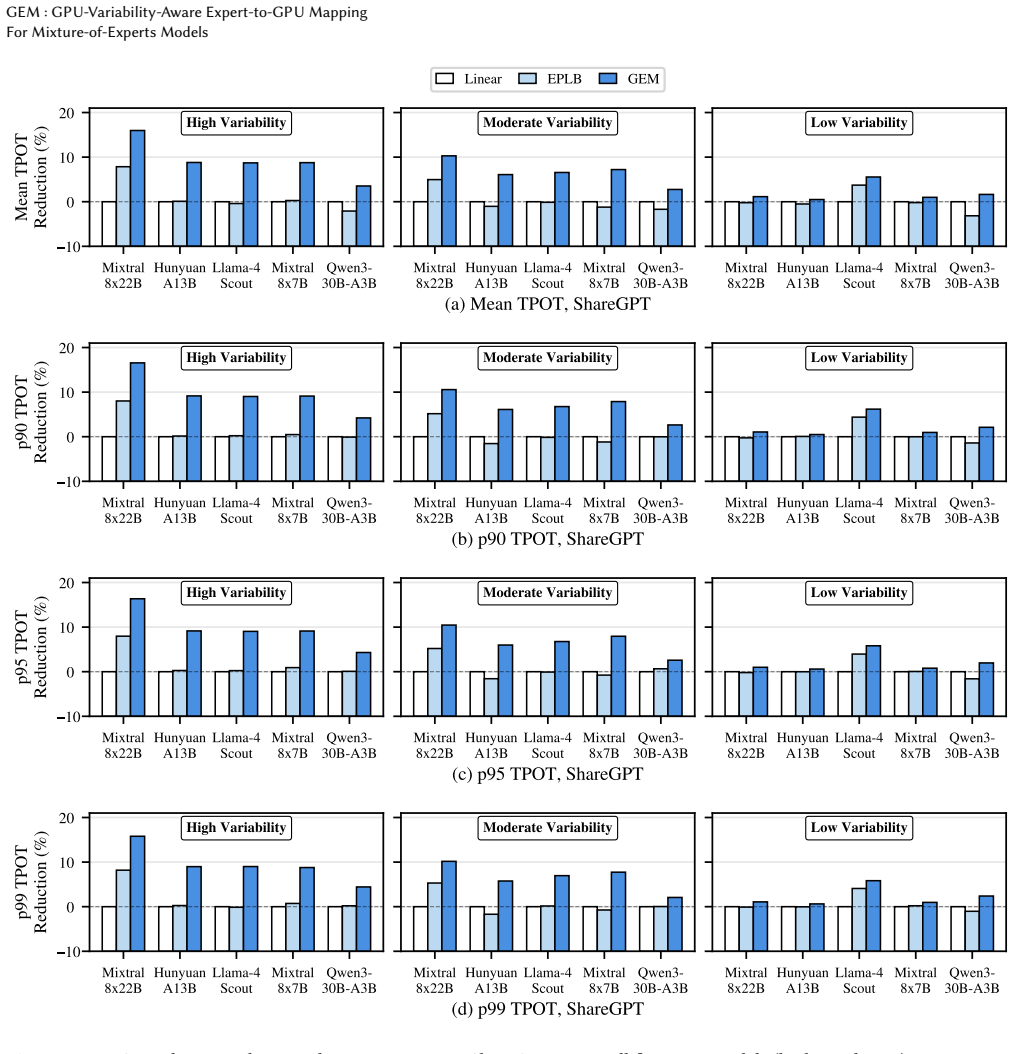
- End-to-end latency falls 7.9 percent on average and as much as 16.5 percent relative to load-balancing baselines that ignore GPU variability.
- Placing consistent and temporal experts on separate GPUs prevents any single device from accumulating both frequent and bursty loads at the same moment.
- Avoiding the slowest GPUs for heavily used experts removes the worst-case stragglers that dominate synchronized batches.
- The mapping is computed once from measured variability profiles and token-load statistics for the target model and task.
Where Pith is reading between the lines
- If the consistent-temporal split remains stable across additional MoE architectures, the same profiling step could be reused for other sparse activation patterns.
- A single upfront variability scan per hardware cluster might support periodic remapping when workload mixes change.
- The same separation principle could reduce tail latency in other distributed systems that synchronize across heterogeneous accelerators.
Load-bearing premise
Expert usage patterns reliably divide into two stable categories whose co-occurrence rules allow a fixed mapping to equalize GPU finish times when consistent and temporal experts are kept apart and slow GPUs are avoided.
What would settle it
Measure layer completion times across GPUs under the GEM mapping versus a pure load-balanced baseline; the claim holds if the maximum finish-time spread shrinks and end-to-end latency drops by roughly the reported margins.
Figures











read the original abstract
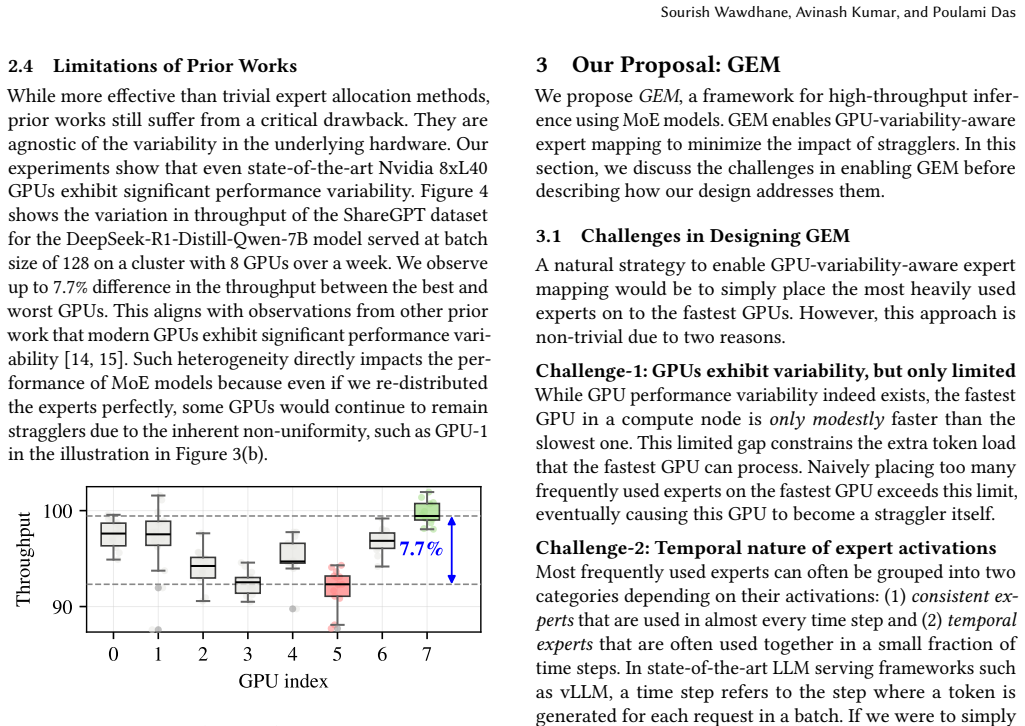
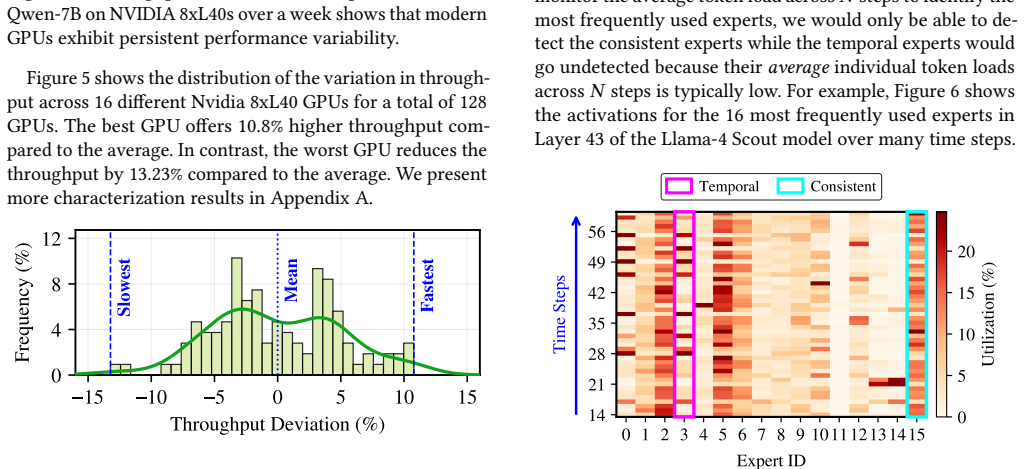
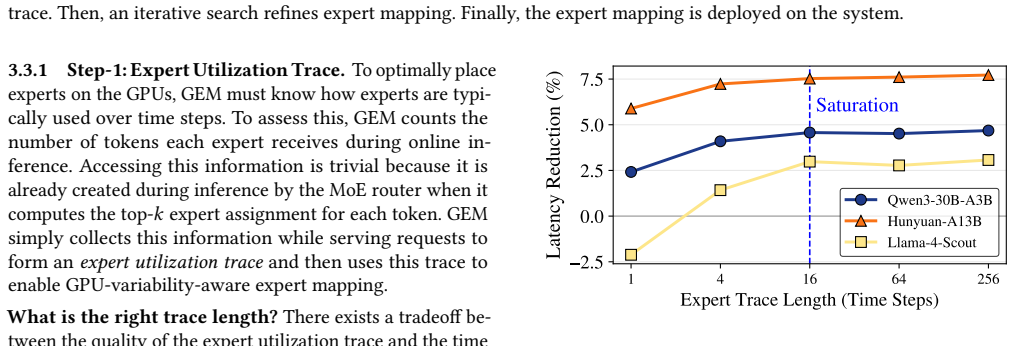
Mixture-of-Expert (MoE) models enable efficient inference by employing smaller experts and activating only a subset of them per token. MoE serving engines distribute experts across multiple GPUs and route tokens to appropriate GPUs at inference time based on experts activated. They process tokens in lock-step fashion, where tokens within a batch must finish processing before proceeding to the next layer. This synchronization barrier acts as a critical bottleneck because the performance of MoE models is limited by the straggler GPU that finishes last. Stragglers emerge when too many heavily used experts are placed on the same GPU or the slowest GPU. While prior works place experts that balance token loads across GPUs, they all overlook GPU variability and often place highly used experts on the slowest GPUs. We propose GEM, GPU-variability-aware Expert Mapping, a framework for GPU variability-aware expert to GPU mapping for MoE models. GEM exploits two insights. First, we must place experts such that each GPU receives non-uniform token loads based on their variability and they all finish processing a layer at about the same time. Our studies show that there are two types of experts: consistent that are used most of the time and temporal that are often used together for the remaining time. Our second insight is that we must place simultaneously used consistent and temporal experts on different GPUs and avoid placing them on slower GPUs to reduce slowdown. GEM gathers the variability profile of GPUs for each model and task and uses the token load distributions per task to map experts to GPUs. Our experiments show that GEM improves end-to-end latency by 7.9% on average and by up to 16.5% compared to the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GEM, a GPU-variability-aware expert-to-GPU mapping framework for Mixture-of-Experts (MoE) inference. It identifies two expert types—consistent experts used most of the time and temporal experts often co-activated together—and proposes mapping them to separate GPUs while avoiding slower GPUs, using gathered GPU variability profiles and per-task token load distributions. The central claim is that this reduces stragglers from synchronization barriers and yields 7.9% average and up to 16.5% maximum end-to-end latency improvement over baselines.
Significance. If the experimental claims are substantiated, GEM targets a practical bottleneck in MoE serving on heterogeneous GPU hardware by combining expert activation patterns with hardware variability awareness. This could improve inference efficiency in production clusters where GPU performance varies, extending beyond standard load-balancing approaches.
major comments (2)
- The description of studies identifying consistent and temporal expert types provides no quantitative definition (e.g., usage-frequency threshold, co-activation metric, or clustering method) nor stability analysis across batch sizes or input distributions. This partition is load-bearing for the mapping that places consistent and temporal experts on different GPUs to equalize layer completion times; without it, the strategy reduces to conventional balancing and the reported gains do not necessarily follow.
- The experiments section asserts 7.9% average and 16.5% maximum latency improvements but supplies no details on experimental setup, models, GPU configurations, baselines, number of runs, or statistical controls. This prevents assessment of whether the results support the central claim.
minor comments (1)
- The abstract refers to 'our studies' without citing the specific section containing the expert-type analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: The description of studies identifying consistent and temporal expert types provides no quantitative definition (e.g., usage-frequency threshold, co-activation metric, or clustering method) nor stability analysis across batch sizes or input distributions. This partition is load-bearing for the mapping that places consistent and temporal experts on different GPUs to equalize layer completion times; without it, the strategy reduces to conventional balancing and the reported gains do not necessarily follow.
Authors: We agree that the manuscript would benefit from explicit quantitative definitions and stability analysis for the consistent/temporal expert partition. In the revised version we will add a new subsection that specifies the usage-frequency threshold, co-activation metric, and clustering procedure used in our profiling studies, together with empirical stability results across batch sizes and input distributions. These additions will make the mapping strategy and its performance gains fully reproducible. revision: yes
-
Referee: The experiments section asserts 7.9% average and 16.5% maximum latency improvements but supplies no details on experimental setup, models, GPU configurations, baselines, number of runs, or statistical controls. This prevents assessment of whether the results support the central claim.
Authors: We acknowledge the absence of these experimental details in the submitted manuscript. The revised experiments section will include the evaluated models, heterogeneous GPU configurations and variability profiles, baseline implementations, number of runs with statistical reporting, and controls used to obtain the reported latency improvements. revision: yes
Circularity Check
No significant circularity; mapping derives from independent GPU profiles and empirical studies
full rationale
The paper's core proposal rests on gathering GPU variability profiles and per-task token-load distributions as independent inputs, then applying an expert-to-GPU mapping informed by observed usage patterns labeled 'consistent' and 'temporal' from separate studies. No equations, fitted parameters, or self-citations are shown that would make the reported 7.9–16.5% latency gains tautological with those inputs; the end-to-end improvements are presented as experimental outcomes against a baseline rather than a derived quantity forced by construction. The classification of experts is framed as an empirical insight rather than a self-definitional loop, and the synchronization-barrier argument follows directly from the described lock-step execution model without reducing to prior results by the same authors. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our studies show that there are two types of experts: consistent that are used most of the time and temporal that are often used together for the remaining time.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GEM places experts such that each GPU receives non-uniform token loads based on their variability and they all finish processing a layer at about the same time.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Analytical FFN-to-MoE Restructuring via Activation Pattern Analysis
Zehua Pei, Lancheng Zou, Hui-Ling Zhen, Xianzhi Yu, Wulong Liu, Sinno Jialin Pan, Mingxuan Yuan, and Bei Yu. Cmoe: Converting mixture-of-experts from dense to accelerate llm inference.arXiv preprint arXiv:2502.04416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Trans- former feed-forward layers are key-value memories, 2021
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Trans- former feed-forward layers are key-value memories, 2021
work page 2021
-
[3]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guil- laume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Tev...
work page 2024
-
[4]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page 2025
-
[5]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[6]
Meta AI. The Llama 4 herd: The beginning of a new era of natively mul- timodal AI innovation.https://ai.meta.com/blog/llama-4-multimodal- intelligence/, April 2025. Accessed: 2026-05-06
work page 2025
-
[7]
Hunyuan-large: An open-source MoE model with 52 billion activated parameters by tencent, 2024
Xingwu Sun, Yanfeng Chen, Yiqing Huang, Ruobing Xie, Jiaqi Zhu, Kai Zhang, Shuaipeng Li, Zhen Yang, Jonny Han, Xiaobo Shu, Jiahao Bu, Zhongzhi Chen, Xuemeng Huang, Fengzong Lian, Saiyong Yang, Jianfeng Yan, Yuyuan Zeng, Xiaoqin Ren, Chao Yu, Lulu Wu, Yue Mao, Tao Yang, Suncong Zheng, Kan Wu, Dian Jiao, Jinbao Xue, Xipeng Zhang, Decheng Wu, Kai Liu, Dengpe...
work page 2024
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
OLMoE: Open Mixture-of-Experts Language Models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, et al. Olmoe: Open mixture-of-experts language models. arXiv preprint arXiv:2409.02060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Deepseek- moe: Towards ultimate expert specialization in mixture-of-experts language models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseek- moe: Towards ultimate expert specialization in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 1280–1297, 2024
work page 2024
-
[11]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[12]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional compu- tation and automatic sharding.arXiv preprint:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[13]
Craft: Cost-aware expert replica allocation with fine-grained layerwise estimations, 2026
Adrian Zhao, Zhenkun Cai, Zhenyu Song, Lingfan Yu, Haozheng Fan, Jun Wu, Yida Wang, and Nandita Vijaykumar. Craft: Cost-aware expert replica allocation with fine-grained layerwise estimations, 2026
work page 2026
-
[14]
Not all gpus are created equal: characterizing variability in large-scale, accelerator-rich systems
Prasoon Sinha, Akhil Guliani, Rutwik Jain, Brandon Tran, Matthew D Sinclair, and Shivaram Venkataraman. Not all gpus are created equal: characterizing variability in large-scale, accelerator-rich systems. In SC22, pages 01–15. IEEE, 2022. 13 Sourish Wawdhane, Avinash Kumar, and Poulami Das
work page 2022
-
[15]
Sinclair, and Shivaram Venkataraman
Rutwik Jain, Brandon Tran, Keting Chen, Matthew D. Sinclair, and Shivaram Venkataraman. Pal: A variability-aware policy for schedul- ing ml workloads in gpu clusters, 2024
work page 2024
-
[16]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. arXiv preprint arXiv:2408.15664, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Adaptive mixtures of local experts.Neural computation, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 1991
work page 1991
-
[18]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
A survey on mixture of experts in large language models
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models. IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[20]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[21]
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Shwai He, Weilin Cai, Jiayi Huang, and Ang Li. Capacity-aware inference: Mitigating the straggler effect in mixture of experts.arXiv preprint arXiv:2503.05066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
HarMoEny: Efficient multi-gpu inference of MoE models.arXiv preprint arXiv:2506.12417, 2025
Zachary Doucet, Rishi Sharma, Martijn de Vos, Rafael Pires, Anne- Marie Kermarrec, and Oana Balmau. HarMoEny: Efficient multi-gpu inference of MoE models.arXiv preprint arXiv:2506.12417, 2025
-
[23]
MoETuner: Optimized mixture of expert serving with balanced expert placement and token routing,
Seokjin Go and Divya Mahajan. Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing. arXiv preprint arXiv:2502.06643, 2025
-
[24]
Jaehoon Yang, Yushin Kim, Seokwon Moon, Yeonhong Park, and Jae W. Lee. Libra: Effective yet efficient load balancing for large-scale moe inference. InThe 14th ICLR, 2026
work page 2026
-
[25]
Ac- celerating distributed MoE training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Ac- celerating distributed MoE training and inference with lina. In2023 USENIX ATC, pages 945–959. USENIX Association, 2023
work page 2023
-
[26]
2026.Semantic Parallelism: Redefining Efficient MoE Inference via Model-Data Co-Scheduling
Yan Li, Pengfei Zheng, Shuang Chen, Zewei Xu, Yuanhao Lai, Yunfei Du, and Zhengang Wang. Speculative moe: Communication effi- cient parallel moe inference with speculative token and expert pre- scheduling.arXiv preprint arXiv:2503.04398, 2025
-
[27]
Shuqing Luo, Pingzhi Li, Jie Peng, Hanrui Wang, Yang, Zhao, Yu, Cao, Yu Cheng, and Tianlong Chen. Occult: Optimizing collaborative communication across experts for accelerated parallel moe training and inference. 2025
work page 2025
-
[28]
Haiyang Huang, Newsha Ardalani, Anna Sun, Liu Ke, Hsien-Hsin S Lee, Shruti Bhosale, Carole-Jean Wu, and Benjamin Lee. Toward effi- cient inference for mixture of experts.Advances in Neural Information Processing Systems, 37:84033–84059, 2024
work page 2024
-
[29]
Zihan Qiu, Zeyu Huang, Bo Zheng, Kaiyue Wen, Zekun Wang, Rui Men, Ivan Titov, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Demons in the detail: On implementing load balancing loss for train- ing specialized mixture-of-expert models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 5005–5018, 2025
work page 2025
-
[30]
Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K DK Panda. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference. InIPDPS. IEEE, 2024
work page 2024
-
[31]
Mathematical contributions to the theory of evolution
Karl Pearson. Mathematical contributions to the theory of evolution. iii. regression, heredity, and panmixia.Philosophical Transactions of the Royal Society of London. Series A, 187:253–318, 1896
-
[32]
Sharegpt, 2023.https://sharegpt.com
work page 2023
-
[33]
Characterizing power management opportunities for LLMs in the cloud
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh Warrier, Nithish Mahalingam, and Ricardo Bianchini. Characterizing power management opportunities for LLMs in the cloud. InProceed- ings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024
work page 2024
-
[34]
MegaBlocks: Efficient sparse training with mixture-of-experts
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. MegaBlocks: Efficient sparse training with mixture-of-experts. In Proceedings of Machine Learning and Systems (MLSys), 2023
work page 2023
-
[35]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in NeurIPS, 2022
work page 2022
-
[36]
Yuxin Wang, Yuhan Chen, Zeyu Li, Zhenheng Tang, Rui Guo, Xin Wang, Qiang Wang, Amelie Chi Zhou, and Xiaowen Chu. Burstgpt: A real-world workload dataset to optimize llm serving systems.arXiv preprint arXiv:2401.17644, 2024
-
[37]
Amant, Chetan Bansal, Victor Rühle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St. Amant, Chetan Bansal, Victor Rühle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan. Sageserve: Optimizing llm serving on cloud data centers with forecast aware auto-scaling.Proceedings of the ACM on Measurement and Analysis of Computing Systems, 9(3), 2025
work page 2025
-
[38]
Adam Krzywaniak, Paweł Czarnul, and Jerzy Proficz. GPU power capping for energy-performance trade-offs in training of deep con- volutional neural networks for image recognition. InProceedings of ICCS, pages 123–133. Springer, 2022
work page 2022
-
[39]
Reducing energy bloat in large model training
Jae-Won Chung, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, and Mosharaf Chowdhury. Reducing energy bloat in large model training. InProceedings of the 30th SOSP, 2024
work page 2024
-
[40]
Nicholas Metropolis and Stanislaw Ulam. The monte carlo method. Journal of the American Statistical Association, 44(247):335–341, 1949
work page 1949
-
[41]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrit- twieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Mas- son d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Jo- hannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson,...
work page 2022
-
[42]
Mixture-of-experts with expert choice routing, 2022
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vin- cent Zhao, Andrew Dai, Zhifeng Chen, Quoc Le, and James Laudon. Mixture-of-experts with expert choice routing, 2022
work page 2022
-
[43]
Analyzing performance and power-efficiency variations among nvidia gpus
Kohei Yoshida, Rio Sageyama, Shinobu Miwa, Hayato Yamaki, and Hi- roki Honda. Analyzing performance and power-efficiency variations among nvidia gpus. InProceedings of the 51st ICPP, pages 1–12, 2022
work page 2022
-
[44]
Abhishek Tiwari, Smruti R Sarangi, and Josep Torrellas. Recycle: Pipeline adaptation to tolerate process variation.ACM SIGARCH Computer Architecture News, 35(2):323–334, 2007
work page 2007
-
[45]
Lit Silicon: A Case Where Thermal Imbalance Couples Concurrent Execution in Multiple GPUs
Marco Kurzynski, Shaizeen Aga, and Di Wu. Lit silicon: A case where thermal imbalance couples concurrent execution in multiple gpus. arXiv preprint arXiv:2511.09861, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Analysis of large-scale multi- tenant gpu clusters for dnn training workloads
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. Analysis of large-scale multi- tenant gpu clusters for dnn training workloads. InUSENIX ATC, 2019
work page 2019
-
[47]
Quan Chen, Hailong Yang, Jason Mars, and Lingjia Tang. Baymax: Qos awareness and increased utilization for non-preemptive accelerators in warehouse scale computers.ACM SIGPLAN Notices, 51(4), 2016
work page 2016
-
[48]
Quan Chen, Hailong Yang, Minyi Guo, Ram Srivatsa Kannan, Jason Mars, and Lingjia Tang. Prophet: Precise qos prediction on non- preemptive accelerators to improve utilization in warehouse-scale computers. InASPLOS, pages 17–32, 2017
work page 2017
-
[49]
Xin Xu, Na Zhang, Michael Cui, Michael He, and Ridhi Surana. Char- acterization and prediction of performance interference on mediated passthrough gpus for interference-aware scheduler. In11th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 19), 2019
work page 2019
-
[50]
Splitwise: Efficient gener- ative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient gener- ative llm inference using phase splitting. In51st ISCA. IEEE, 2024. 14 GEM: GPU-Variability-Aware Expert-to-GPU Mapping For Mixture-of-Experts Models 1.44% 4.68%15.86% (a) (b) (c) Figure 20.Aggregated TPOT variability ac...
work page 2024
-
[51]
The median deviation between the best (GPU 7) and the worst (GPU 5) increases with batch size, showing that larger batches widen performance variability across GPUs within the same node. A Variability in GPU Systems Modern GPU-accelerated systems exhibit significant perfor- mancevariability, so devices running identical workloads can produce measurably di...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.