Mean Field Reinforcement Learning
Pith reviewed 2026-07-03 18:58 UTC · model grok-4.3
The pith
Mean field reinforcement learning reduces large-population multi-agent problems to representative-agent Markov decision processes with common noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The monograph develops the probabilistic and control-theoretic framework for mean field reinforcement learning from Markov decision processes with mean field interactions and common noise, starting from the link between multi-agent reinforcement learning and mean field control, then deriving representative-agent problems, their relation to finite systems, and analyses of Q-learning and policy-gradient methods for general and linear-quadratic cases.
What carries the argument
Representative-agent Markov decision processes with mean field interactions and common noise that arise as limits of large-population stochastic control.
Load-bearing premise
Solutions to the representative-agent mean field problems remain useful approximations for the behavior of the original finite-population multi-agent systems.
What would settle it
A sequence of finite-N simulations in which the value functions or optimal policies obtained from the mean field representative agent diverge from those of the full multi-agent system as the population size grows.
Figures

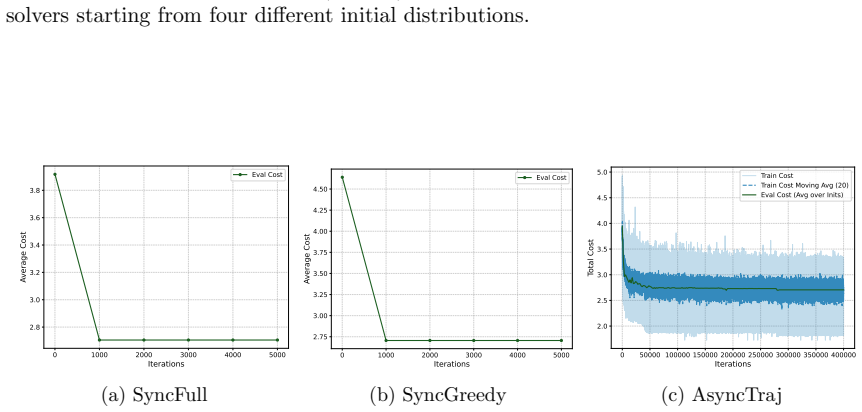




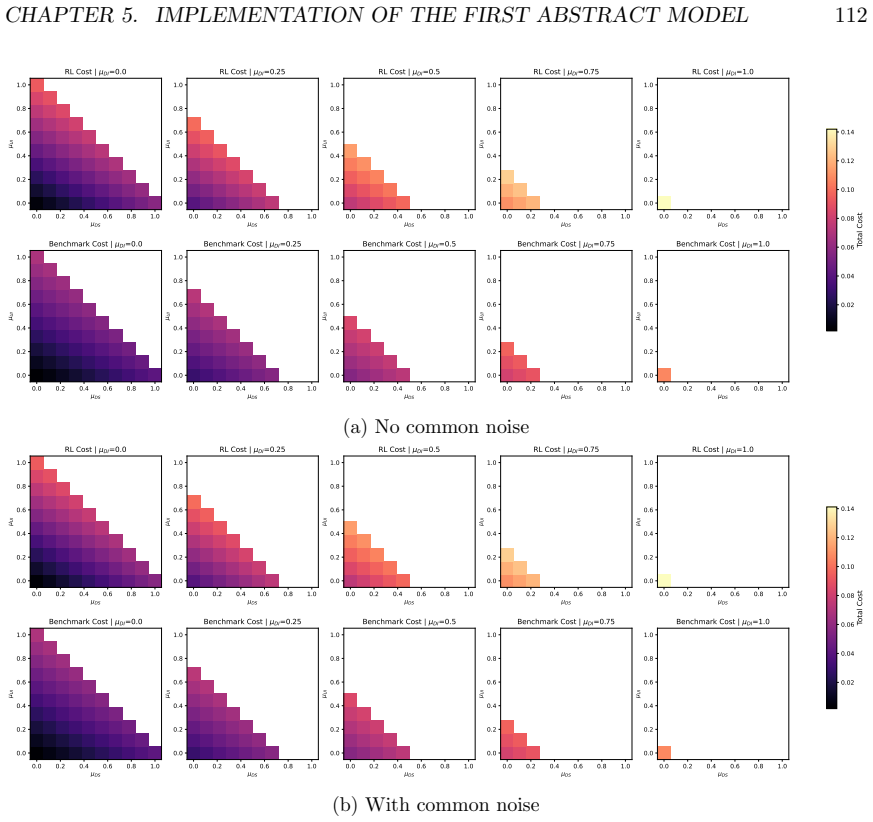






read the original abstract
This monograph provides an introduction to mean field reinforcement learning through the lens of Markov decision processes arising from large-population stochastic control with mean field interactions and common noise. Starting from the connection between multi-agent reinforcement learning and mean field control, it develops the probabilistic, mathematical, and control-theoretic framework needed to formulate representative-agent learning problems, analyze their relationship with finite-population systems, and study both general and linear-quadratic models. The presentation includes dynamic programming principles, propagation-of-chaos limits, and theoretical analyses of tabular Q-learning and policy-gradient methods. It also discusses numerical implementations, including tabular schemes and deep reinforcement learning methods such as deep deterministic policy gradient. The goal is to give readers a coherent bridge between mean field control theory and reinforcement learning methodology, emphasizing the mathematical structure of the problems and the design of tractable learning approaches for large stochastic populations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This monograph introduces mean field reinforcement learning through Markov decision processes arising from large-population stochastic control with mean field interactions and common noise. Starting from the link between multi-agent RL and mean field control, it develops the probabilistic, mathematical, and control-theoretic framework for representative-agent learning problems and their relation to finite-population systems. It covers dynamic programming principles, propagation-of-chaos limits, theoretical analyses of tabular Q-learning and policy-gradient methods, general and linear-quadratic models, and numerical implementations including tabular schemes and deep deterministic policy gradient.
Significance. The work synthesizes existing frameworks into a coherent bridge between mean field control theory and reinforcement learning methodology, with emphasis on mathematical structure and tractable approaches for large stochastic populations. As an expository monograph it does not introduce new machine-checked proofs or parameter-free derivations, but the unified presentation of propagation-of-chaos results alongside RL algorithm analyses could serve as a useful reference if the approximation claims are fully substantiated.
major comments (1)
- [Abstract] Abstract and framework description: propagation-of-chaos limits are presented together with the theoretical analyses of tabular Q-learning and policy-gradient methods, yet the text does not indicate that these limits are extended from the controlled state processes to the RL iterates themselves. Without an explicit argument showing that the suboptimality gap of the learned policies vanishes as N grows, the central claim that representative-agent solutions remain useful approximations for finite-population systems rests on an unverified transfer.
minor comments (1)
- Clarify in the introduction whether the monograph derives new results or primarily organizes prior literature; this would help readers assess the scope of the contribution.
Simulated Author's Rebuttal
We thank the referee for their detailed review and insightful comments on our monograph. We address the major comment regarding the propagation-of-chaos limits and their extension to the reinforcement learning iterates below.
read point-by-point responses
-
Referee: [Abstract] Abstract and framework description: propagation-of-chaos limits are presented together with the theoretical analyses of tabular Q-learning and policy-gradient methods, yet the text does not indicate that these limits are extended from the controlled state processes to the RL iterates themselves. Without an explicit argument showing that the suboptimality gap of the learned policies vanishes as N grows, the central claim that representative-agent solutions remain useful approximations for finite-population systems rests on an unverified transfer.
Authors: The referee correctly identifies that the propagation-of-chaos results in the manuscript apply to the controlled state processes in the large-population limit, while the analyses of tabular Q-learning and policy-gradient methods are developed for the representative-agent mean-field problem. The text does not explicitly extend these limits to the RL iterates or provide a theorem establishing that the suboptimality gap vanishes as N tends to infinity for finite-population systems. As an expository monograph synthesizing existing frameworks, the central claim relies on the standard mean-field approximation and propagation-of-chaos for the dynamics, with the RL methods analyzed in the limit. We acknowledge that an explicit transfer argument for the learned policies is not included. We will revise the abstract and add a discussion section clarifying the scope of the results, noting the implicit nature of the approximation for finite-N systems and suggesting directions for future rigorous transfers. revision: yes
Circularity Check
Expository monograph presents frameworks without circular derivations
full rationale
The provided abstract and description characterize the work as an introduction that develops the probabilistic and control-theoretic framework from the connection between multi-agent RL and mean field control, including dynamic programming, propagation-of-chaos limits, and analyses of Q-learning and policy-gradient methods. No equations, predictions, or first-principles results are quoted that reduce by construction to fitted inputs, self-definitions, or self-citation chains. As an expository monograph the central content is presentation of prior frameworks; the derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Philosophical Transactions of the Royal Society A (2014)
Achdou, Y., Buera, F., Lasry, J.M., Lions, P.L., Moll, B.: PDE models in macroeco- nomics. Philosophical Transactions of the Royal Society A (2014)
2014
-
[2]
Achdou, Y., Han, J., Lasry, J.M., Lions, P.L., Moll, B.: Income and wealth distri- bution in macroeconomics: a continuous-time approach. Tech. Rep. 23732, National Bureau of Economic Research (2017). DOI 10.3386/w23732
-
[3]
In: Contributions to Partial Differential Equations and Applications,Computational Methods in Applied Sciences, vol
Achdou, Y., Lasry, J.M.: Mean field games for modeling crowd motion. In: Contributions to Partial Differential Equations and Applications,Computational Methods in Applied Sciences, vol. 47, pp. 17–42. Springer (2019). DOI 10.1007/ 978-3-319-78325-3 4
2019
-
[4]
Journal of Optimization Theory and Applications184(2) (2020)
Alasseur, C., Taher, I.B., Matoussi, A.: An extended mean field game for storage in smart grids. Journal of Optimization Theory and Applications184(2) (2020)
2020
-
[5]
Dynamic Games and Applications13, 89–117 (2023)
Anahtarci, B., Kariksiz, C.D., Saldi, N.: Q-learning in regularized mean-field games. Dynamic Games and Applications13, 89–117 (2023)
2023
-
[6]
Advances in Neural Information Processing Systems38, 8462– 8521 (2026)
Anand, E., Karmarkar, I., Qu, G.: Mean-field sampling for cooperative multi-agent reinforcement learning. Advances in Neural Information Processing Systems38, 8462– 8521 (2026)
2026
-
[7]
Mathematics of Control, Signals, and Systems34(2), 217–271 (2022)
Angiuli, A., Fouque, J.P., Lauri` ere, M.: Unified reinforcement Q-learning for mean field game and control problems. Mathematics of Control, Signals, and Systems34(2), 217–271 (2022)
2022
-
[8]
Machine Learning and Data Sciences for Financial Markets: A Guide to Contemporary Practices p
Angiuli, A., Fouque, J.P., Lauri` ere, M.: Reinforcement learning for mean field games, with applications to economics. Machine Learning and Data Sciences for Financial Markets: A Guide to Contemporary Practices p. 393 (2023)
2023
-
[9]
arXiv preprint arXiv:2312.06659 (2023)
Angiuli, A., Fouque, J.P., Lauri` ere, M., Zhang, M.: Convergence of multi-scale re- inforcement Q-learning algorithms for mean field game and control problems. arXiv preprint arXiv:2312.06659 (2023)
-
[10]
SIAM Journal on Control and Optimization60(2), S294–S322 (2022) 159 BIBLIOGRAPHY160
Aurell, A., Carmona, R., Dayanikli, G., Lauri` ere, M.: Optimal incentives to mitigate epidemics: a Stackelberg mean field game approach. SIAM Journal on Control and Optimization60(2), S294–S322 (2022) 159 BIBLIOGRAPHY160
2022
-
[11]
Transportation Research Part B: Methodological121(2019)
Aurell, A., Djehiche, B.: Modeling tagged pedestrian motion: a mean-field type game approach. Transportation Research Part B: Methodological121(2019)
2019
-
[12]
Dynamic Games and Applications4(2) (2014)
Bagagiolo, F., Bauso, D.: Mean-field games and dynamic demand management in power grids. Dynamic Games and Applications4(2) (2014)
2014
-
[13]
Nonlinear Analysis (2021)
Bardi, M., Cardaliaguet, P.: Convergence of some mean field games systems to ag- gregation and flocking models. Nonlinear Analysis (2021)
2021
-
[14]
SIAM Journal on Control and Optimization54(6) (2016)
Bauso, D., Tembine, H., Ba¸ sar, T.: Opinion dynamics in social networks through mean-field games. SIAM Journal on Control and Optimization54(6) (2016)
2016
-
[15]
IEEE Transactions on Automatic Control62(3), 1342–1355 (2016)
Bauso, D., Zhang, X., Papachristodoulou, A.: Density flow in dynamical networks via mean-field games. IEEE Transactions on Automatic Control62(3), 1342–1355 (2016)
2016
-
[16]
Mean-Field PhiBE: Continuous-Time Mean-Field Reinforcement Learning from Discrete-Time Data
Bayraktar, E., Hernandez, M., Yan, Q., Zhu, Y.: Mean-field PhiBE: Continuous- time mean-field reinforcement learning from discrete-time data. arXiv preprint arXiv:2606.26498 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Journal of Machine Learning Research26(192), 1–53 (2025)
Bayraktar, E., Kara, A.D.: Learning with linear function approximations in mean- field control. Journal of Machine Learning Research26(192), 1–53 (2025)
2025
-
[18]
In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
Bellemare, M., Ostrovski, G., Guez, A., Thomas, P., Munos, R.: Increasing the action gap: New operators for reinforcement learning. In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
2016
-
[19]
Springer Verlag, New York, NY (2013)
Bensoussan, A., Frehse, J., S.C.Yam: Mean field games and mean field type control theory. Springer Verlag, New York, NY (2013)
2013
-
[20]
North American Journal of Economics and Finance68, 101974 (2023)
Bernasconi, M., Vittori, E., Trovo, F., Restelli, M.: Dealer markets: A reinforce- ment learning mean field game approach. North American Journal of Economics and Finance68, 101974 (2023)
2023
-
[21]
Bertsekas, D., Shreve, S.E.: Stochastic optimal control: the discrete-time case, vol. 5. Athena Scientific (1996)
1996
-
[22]
Proceedings of the American Mathematical Society89, 691–692 (1983)
Blackwell, D., Dubins, L.: An extension of Skorohod’s almost sure representation theorem. Proceedings of the American Mathematical Society89, 691–692 (1983)
1983
-
[23]
Lyapunov Theory for Discrete Time Systems
Bof, N., Carli, R., Schenato, L.: Lyapunov theory for discrete time systems. arXiv preprint arXiv:1809.05289 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
In: Active Particles, Volume 1, pp
Bongini, M., Fornasier, M., Junge, O., Scharf, B.: Sparse control of multiagent sys- tems. In: Active Particles, Volume 1, pp. 173–228. Springer (2017)
2017
-
[25]
Brunnbauer, A., Lemmel, J., Babaiee, Z., Neubauer, S., Grosu, R.: Scalable offline reinforcement learning for mean field games (2024)
2024
-
[26]
Discrete and Continuous Dynamical Systems - Series B19(2013)
Burger, M., Di Francesco, M., Markowich, P., Wolfram, M.T.: Mean field games with nonlinear mobilities in pedestrian dynamics. Discrete and Continuous Dynamical Systems - Series B19(2013). DOI 10.3934/dcdsb.2014.19.1311 BIBLIOGRAPHY161
-
[27]
IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews38(2), 156–172 (2008)
Bu¸ soniu, L., Babuˇ ska, R., De Schutter, B.: A comprehensive survey of multi-agent reinforcement learning. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews38(2), 156–172 (2008)
2008
-
[28]
In: Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pp
Cabannes, T., Lauri` ere, M., Perolat, J., Marinier, R., Girgin, S., Perrin, S., Pietquin, O., Bayen, A.M., Goubault, E., Elie, R.: Solving N-player dynamic routing games with congestion: A mean-field approach. In: Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pp. 1557–1559 (2022)
2022
-
[29]
Cardaliaguet, P.: Notes on mean field games (2013)
2013
-
[30]
Cardaliaguet, P., Delarue, F., Lasry, J., Lions, P.: The master equation and the con- vergence problem in mean field games, vol. 201. Princeton University Press, Princeton, NJ. (2019)
2019
-
[31]
Mathematics and Financial Economics12(3), 335–363 (2018)
Cardaliaguet, P., Lehalle, C.A.: Mean field game of controls and an application to trade crowding. Mathematics and Financial Economics12(3), 335–363 (2018)
2018
-
[32]
In: Mean Field Games, pp
Carmona, R.: Applications of mean field games in financial engineering and economic theory. In: Mean Field Games, pp. 165–218. American Mathematical Society (2021)
2021
-
[33]
International Game Theory Review23(04), 2150024 (2021)
Carmona, R., Dayanıklı, G.: Mean field game model for an advertising competition in a duopoly. International Game Theory Review23(04), 2150024 (2021)
2021
-
[34]
I,Probability Theory and Stochastic Modelling, vol
Carmona, R., Delarue, F.: Probabilistic theory of mean field games with applications. I,Probability Theory and Stochastic Modelling, vol. 83. Springer, Cham (2018). Mean field FBSDEs, control, and games
2018
-
[35]
II,Probability Theory and Stochastic Modelling, vol
Carmona, R., Delarue, F.: Probabilistic theory of mean field games with applications. II,Probability Theory and Stochastic Modelling, vol. 84. Springer, Cham (2018). Mean field games with common noise and master equations
2018
-
[36]
In: 2020 59th IEEE Conference on Deci- sion and Control (CDC), pp
Carmona, R., Hamidouche, K., Lauri` ere, M., Tan, Z.: Policy optimization for linear- quadratic zero-sum mean-field type games. In: 2020 59th IEEE Conference on Deci- sion and Control (CDC), pp. 1038–1043. IEEE (2020)
2020
-
[37]
Journal of Dynamics & Games8(4) (2021)
Carmona, R., Hamidouche, K., Lauri` ere, M., Tan, Z.: Linear-quadratic zero-sum mean-field type games: Optimality conditions and policy optimization. Journal of Dynamics & Games8(4) (2021)
2021
-
[38]
To appear in SIREV (arXiv preprint arXiv:2504.21793) (2025)
Carmona, R., Lauri` ere, M.: Reconciling discrete-time mixed policies and continuous- time relaxed controls in reinforcement learning and stochastic control. To appear in SIREV (arXiv preprint arXiv:2504.21793) (2025)
-
[39]
Carmona, R., Lauri` ere, M., Tan, Z.: Linear-quadratic mean-field reinforcement learn- ing: Convergence of policy gradient methods (2019)
2019
-
[40]
The Annals of Applied Probability 33(6B), 5334–5381 (2023)
Carmona, R., Lauri` ere, M., Tan, Z.: Model-free mean-field reinforcement learning: Mean-field MDP and mean-field Q-learning. The Annals of Applied Probability 33(6B), 5334–5381 (2023). DOI 10.1214/23-AAP1949 BIBLIOGRAPHY162
-
[41]
Applied Mathematics & Optimization71(3), 533–569 (2015)
Chan, P., Sircar, R.: Bertrand and Cournot mean field games. Applied Mathematics & Optimization71(3), 533–569 (2015)
2015
-
[42]
Memoirs of the American Mathematical Society280(1379) (2022)
Chassagneux, J.F., Crisan, D., Delarue, F.: A probabilistic approach to classical solu- tions of the master equation for large population equilibria. Memoirs of the American Mathematical Society280(1379) (2022). DOI 10.1090/memo/1379
-
[43]
IEEE Internet of Things Journal 8(2), 813–828 (2020)
Chen, D., Qi, Q., Zhuang, Z., Wang, J., Liao, J., Han, Z.: Mean field deep reinforce- ment learning for fair and efficient UAV control. IEEE Internet of Things Journal 8(2), 813–828 (2020)
2020
-
[44]
IEEE Transactions on Control of Network Systems9(2), 917–929 (2021)
Chen, T., Zhang, K., Giannakis, G.B., Ba¸ sar, T.: Communication-efficient policy gra- dient methods for distributed reinforcement learning. IEEE Transactions on Control of Network Systems9(2), 917–929 (2021)
2021
-
[45]
In: Interna- tional Conference on Machine Learning, pp
Choromanski, K., Rowland, M., Sindhwani, V., Turner, R., Weller, A.: Structured evolution with compact architectures for scalable policy optimization. In: Interna- tional Conference on Machine Learning, pp. 970–978. PMLR (2018)
2018
-
[46]
Conn, A.R., Scheinberg, K., Vicente, L.N.: Introduction to derivative-free optimiza- tion,MPS/SIAM Series on Optimization, vol. 8. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA; Mathematical Programming Society (MPS), Philadelphia, PA (2009). DOI 10.1137/1.9780898718768
-
[47]
In: Proceedings of the 41st International Conference on Machine Learning, pp
Cui, K., Fabian, C., Tahir, A., Koeppl, H.: Major-minor mean field multi-agent rein- forcement learning. In: Proceedings of the 41st International Conference on Machine Learning, pp. 9603–9632 (2024)
2024
-
[48]
In: The Twelfth International Conference on Learning Representations (2023)
Cui, K., Hauck, S.H., Fabian, C., Koeppl, H.: Learning decentralized partially observ- able mean field control for artificial collective behavior. In: The Twelfth International Conference on Learning Representations (2023)
2023
-
[49]
In: ICML 2024 Workshop: Aligning Reinforcement Learning Experimentalists and Theorists (2024)
Cui, K., Hauck, S.H., Fabian, C., Koeppl, H.: Partially observable multi-agent re- inforcement learning using mean field control. In: ICML 2024 Workshop: Aligning Reinforcement Learning Experimentalists and Theorists (2024)
2024
-
[50]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp
Cui, K., Li, M., Fabian, C., Koeppl, H.: Scalable task-driven robotic swarm control via collision avoidance and learning mean-field control. In: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 1192–1199. IEEE (2023)
2023
-
[51]
Cui, K., Tahir, A., Ekinci, G., et al.: A survey on large-population systems and scalable multi-agent reinforcement learning (2022). DOI 10.48550/arXiv.2209.03859
-
[52]
In: Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AA- MAS, vol
Dayanıklı, G., Lauri` ere, M., Zhang, J.: Deep learning for population-dependent con- trols in mean field control problems with common noise. In: Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AA- MAS, vol. 2024, pp. 2231–2233. International Foundation for Autonomous Agents and Multiagent Systems (IFAAMAS) (...
2024
-
[53]
Mathematics of Operations Research50(3), 1762–1831 (2025)
Delarue, F., Vasileiadis, A.: Exploration noise for learning linear-quadratic mean field games. Mathematics of Operations Research50(3), 1762–1831 (2025). DOI 10.1287/moor.2021.0157
-
[54]
Probability in the Engineering and Informational Sciences36(2), 482–499 (2022)
Doncel, J., Gast, N., Gaujal, B.: A mean field game analysis of SIR dynamics with vaccination. Probability in the Engineering and Informational Sciences36(2), 482–499 (2022)
2022
-
[55]
Mathematical Finance (2019)
Elie, R., Hubert, E., Mastrolia, T., Possama¨ ı, D.: Mean-field moral hazard for optimal energy demand response management. Mathematical Finance (2019)
2019
-
[56]
Mathematical Modelling of Natural Phenomena (2020)
Elie, R., Hubert, E., Turinici, G.: Contact rate epidemic control of COVID-19: an equilibrium view. Mathematical Modelling of Natural Phenomena (2020)
2020
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence34(05), 7143–7150 (2020)
Elie, R., Perolat, J., Lauri` ere, M., Geist, M., Pietquin, O.: On the convergence of model free learning in mean field games. Proceedings of the AAAI Conference on Artificial Intelligence34(05), 7143–7150 (2020)
2020
-
[58]
Elliott, R.J., Li, X., Ni, Y.H.: Discrete time mean-field stochastic linear-quadratic optimal control problems. Automatica49(11), 3222–3233 (2013). DOI 10.1016/j. automatica.2013.08.012
work page doi:10.1016/j 2013
-
[59]
Journal of Machine Learn- ing Research5, 1–25 (2003)
Even-Dar, E., Mansour, Y.: Learning rates for Q-learning. Journal of Machine Learn- ing Research5, 1–25 (2003)
2003
-
[60]
Advances in Neural Information Processing Systems pp
Farahmand, A.: Action-gap phenomenon in reinforcement learning. Advances in Neural Information Processing Systems pp. 172–180 (2011)
2011
-
[61]
In: Proceedings of the 35th International Conference on Machine Learning, vol
Fazel, M., Ge, R., Kakade, S., Mesbahi, M.: Global convergence of policy gradient methods for the linear quadratic regulator. In: Proceedings of the 35th International Conference on Machine Learning, vol. 80 (2018)
2018
-
[62]
In: Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp
Flaxman, A.D., Kalai, A.T., McMahan, H.B.: Online convex optimization in the bandit setting: gradient descent without a gradient. In: Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 385–394. ACM, New York (2005)
2005
-
[63]
In: Advances in Neural Information Pro- cessing Systems, pp
Foerster, J., Assael, Y., de Freitas, N., Whiteson, S.: Learning to communicate with deep multi-agent reinforcement learning. In: Advances in Neural Information Pro- cessing Systems, pp. 2137–2145 (2016)
2016
-
[64]
Journal of Machine Learning Research26(127), 1–42 (2025)
Frikha, N., Germain, M., Lauri` ere, M., Pham, H., Song, X.: Actor-critic learning for mean-field control in continuous time. Journal of Machine Learning Research26(127), 1–42 (2025)
2025
-
[65]
arXiv preprint arXiv:2408.02489 (2024) BIBLIOGRAPHY164
Frikha, N., Pham, H., Song, X.: Full error analysis of policy gradient learning algo- rithms for exploratory linear quadratic mean-field control problem in continuous time with common noise. arXiv preprint arXiv:2408.02489 (2024) BIBLIOGRAPHY164
-
[66]
In: International Conference on Learning Repre- sentations (2019)
Fu, Z., Yang, Z., Chen, Y., Wang, Z.: Actor-critic provably finds Nash equilibria of linear-quadratic mean-field games. In: International Conference on Learning Repre- sentations (2019)
2019
-
[67]
In: Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pp
Ganapathi Subramanian, S., Poupart, P., Taylor, M.E., Hegde, N.: Multi type mean field reinforcement learning. In: Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pp. 411–419 (2020)
2020
-
[68]
In: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, pp
Ganapathi Subramanian, S., Taylor, M.E., Crowley, M., Poupart, P.: Partially ob- servable mean field reinforcement learning. In: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, pp. 537–545 (2021)
2021
-
[69]
Gao, B., Pavel, L.: On the properties of the softmax function with application in game theory and reinforcement learning (2017)
2017
-
[70]
Discrete Event Dynamic Systems21, 63–101 (2011)
Gast, N., Gaujal, B.: A mean field approach for optimization in discrete time. Discrete Event Dynamic Systems21, 63–101 (2011)
2011
-
[71]
IEEE Transactions on Automatic Control57, 2266–2280 (2012)
Gast, N., Gaujal, B., Boudec, J.L.: Mean field for Markov decision processes: from discrete to continuous optimization. IEEE Transactions on Automatic Control57, 2266–2280 (2012)
2012
-
[72]
Applied Mathematics & Optimization68(1), 99–143 (2013)
Gomes, D.A., Mohr, J., Souza, R.R.: Continuous time finite state mean field games. Applied Mathematics & Optimization68(1), 99–143 (2013)
2013
-
[73]
Dynamic Games and Applications (2020)
Gomes, D.A., Sa´ ude, J.: A mean-field game approach to price formation. Dynamic Games and Applications (2020)
2020
-
[74]
Graber, P.J.: Linear quadratic mean field type control and mean field games with common noise, with application to production of an exhaustible resource. Appl. Math. Optim.74(3), 459–486 (2016). DOI 10.1007/s00245-016-9385-x
-
[75]
Applied Mathematics & Optimization77(1) (2018)
Graber, P.J., Bensoussan, A.: Existence and uniqueness of solutions for Bertrand and Cournot mean field games. Applied Mathematics & Optimization77(1) (2018)
2018
-
[76]
Chaos: An Interdisciplinary Journal of Nonlinear Science28(6), 061103 (2018)
Grover, P., Bakshi, K., Theodorou, E.A.: A mean-field game model for homogeneous flocking. Chaos: An Interdisciplinary Journal of Nonlinear Science28(6), 061103 (2018)
2018
-
[77]
SIAM Journal on Mathematics of Data Science3, 1168–1196 (2021)
Gu, H., Guo, X., Wei, X., Xu, R.: Mean-field controls with Q-learning for cooperative MARL: Convergence and complexity analysis. SIAM Journal on Mathematics of Data Science3, 1168–1196 (2021). DOI 10.1137/20M1360700
-
[78]
Operations Research71(4), 1040–1054 (2023)
Gu, H., Guo, X., Wei, X., Xu, R.: Dynamic programming principles for mean-field controls with learning. Operations Research71(4), 1040–1054 (2023)
2023
-
[79]
Mathematics of Operations Research50(1), 506–536 (2025)
Gu, H., Guo, X., Wei, X., Xu, R.: Mean-field multiagent reinforcement learning: A decentralized network approach. Mathematics of Operations Research50(1), 506–536 (2025). DOI 10.1287/moor.2022.0055 BIBLIOGRAPHY165
-
[80]
IEEE Transactions on Cognitive Communications and Networking (2025)
Gu, H., Zhao, L., Liang, K., Zheng, G., Wong, K.K., Chae, C.B.: Task offloading and position optimization for large scale unmanned aerial vehicle networks: A mean field learning approach. IEEE Transactions on Cognitive Communications and Networking (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.