The Inattentional Gap: Task-Conditioned Language and Vision Models Omit the Safety-Critical Signals They Can Otherwise Report
Pith reviewed 2026-06-26 05:22 UTC · model grok-4.3
The pith
Conditioning AI models on a narrow task suppresses their reporting of safety-critical signals they report at much higher rates when unconstrained.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
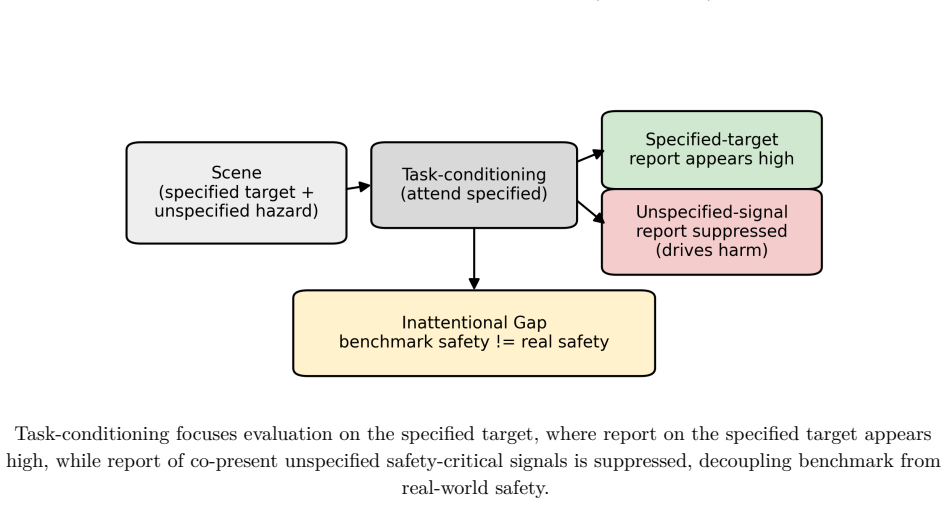
Task conditioning on language or vision models creates a dissociation in which the models omit safety-critical signals that are co-present in the input yet that the same models report at substantially higher rates when the prompt imposes no narrow task; the authors label this dissociation the Inattentional Gap and argue that it decouples measured benchmark safety from real-world safety because a system can score near-perfectly on the hazards an evaluation specifies while remaining blind to those that cause harm.
What carries the argument
The Inattentional Gap: the observed dissociation in reporting rates between task-conditioned prompts and unconstrained prompts across text and vision inputs.
If this is right
- The suppression effect appears in every model tested and does not diminish with scale.
- The effect varies more by model family than by model size.
- The suppression persists even in a reasoning model.
- High scores on specified safety benchmarks do not guarantee awareness of unspecified hazards.
Where Pith is reading between the lines
- Safety testing may need separate unconstrained reporting checks to catch signals omitted under task focus.
- The gap could affect deployment in domains where models receive focused instructions yet must still notice side hazards.
- Training methods that preserve reporting of secondary signals under task conditioning could be explored as a direct response.
Load-bearing premise
The unconstrained condition provides a valid baseline for what the model can report without confounds from prompt length, output format, or differing capability across conditions.
What would settle it
An experiment in which models report the safety-critical signals at the same rate under both the narrow task condition and the unconstrained condition, or in which the gap disappears in larger models.
Figures


read the original abstract
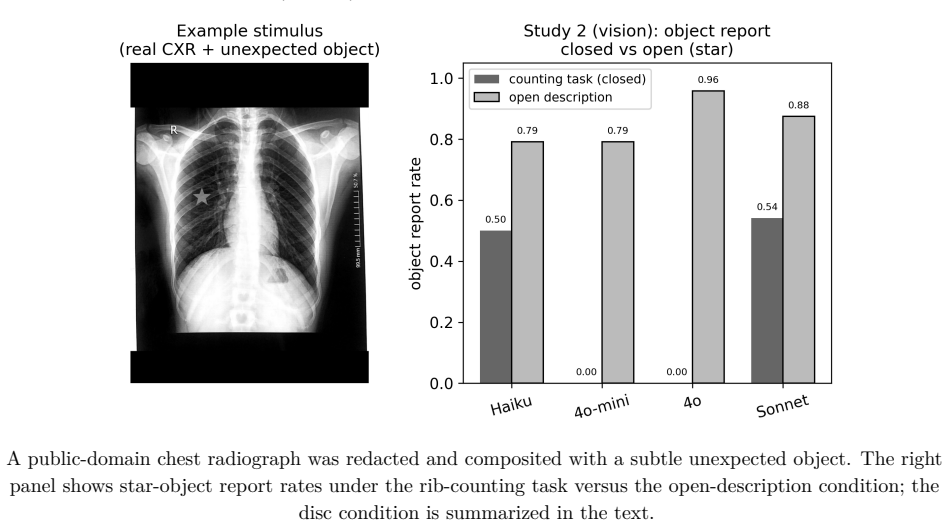
AI safety is evaluated by how reliably a model detects the hazards it is told to find, yet accidents often arise from the hazard no one specified. We show that conditioning a language or vision model on a narrow task suppresses its reporting of co-present, safety-critical signals it can otherwise report, a machine analogue of human inattentional blindness arising from a different mechanism. Across radiology and driving text scenarios and chest-radiograph vision tasks, suppression appeared in every model tested, did not diminish with scale, persisted in a reasoning model, and varied more by model family than by size, while the same models reported these signals at substantially higher rates when unconstrained. We name this dissociation the Inattentional Gap and argue that it decouples measured benchmark safety from real-world safety: a system can score near-perfectly on the hazards an evaluation specifies while remaining blind to those that cause harm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conditioning language or vision models on a narrow task suppresses reporting of co-present safety-critical signals that the same models can report when unconstrained, naming this dissociation the 'Inattentional Gap' as a machine analogue of inattentional blindness. The effect is reported across radiology and driving text scenarios plus chest-radiograph vision tasks, appearing in every model tested, independent of scale, persistent in a reasoning model, and varying more by model family than size; the authors argue this decouples benchmark safety from real-world safety.
Significance. If the empirical dissociation holds after controls for prompt confounds, the result would be significant for AI safety evaluation: it supplies concrete evidence that near-perfect performance on specified hazards need not imply detection of unspecified ones, with direct implications for deployment in safety-critical domains such as medicine and autonomous driving.
major comments (1)
- [Abstract] Abstract: the central claim that models 'can otherwise report' the signals rests on substantially higher reporting rates in the unconstrained condition. The manuscript provides no indication that unconstrained prompts were length-matched, format-matched, or otherwise equated to the task-conditioned prompts; without such controls the elevated rates could arise from differences in prompt directiveness or output expectations rather than removal of task focus, directly undermining the evidence for a task-induced suppression mechanism.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the referee's major comment on prompt matching below and will revise the manuscript to strengthen the evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that models 'can otherwise report' the signals rests on substantially higher reporting rates in the unconstrained condition. The manuscript provides no indication that unconstrained prompts were length-matched, format-matched, or otherwise equated to the task-conditioned prompts; without such controls the elevated rates could arise from differences in prompt directiveness or output expectations rather than removal of task focus, directly undermining the evidence for a task-induced suppression mechanism.
Authors: We agree that the manuscript does not explicitly report length, format, or directiveness matching between conditions, which leaves open the possibility of prompt confounds. In revision we will add a dedicated methods subsection documenting prompt construction, including token-length statistics and structural equivalence, and will include new matched-prompt experiments (or re-analysis of existing data where feasible) confirming that the reporting-rate dissociation persists under these controls. This directly addresses the concern and bolsters the claim that suppression arises from task conditioning rather than prompt differences. revision: yes
Circularity Check
No circularity; empirical comparisons stand independently
full rationale
The paper reports experimental measurements of reporting rates for safety-critical signals under task-conditioned vs unconstrained prompts across multiple models and modalities. No equations, parameter fits, or derivations appear; the central claim is a direct comparison of observed frequencies rather than any reduction to self-defined quantities or self-citation chains. The unconstrained baseline is an experimental control whose validity can be debated on methodological grounds but does not constitute circularity by construction. Self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simons, D. J. & Chabris, C. F. (1999). Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception, 28(9), 1059–1074. DOI: 10.1068/p281059
-
[2]
Drew, T., Võ, M. L.-H. & Wolfe, J. M. (2013). The invisible gorilla strikes again: Sustained inattentional blindness in expert observers. Psychological Science, 24(9), 1848–1853. DOI: 10.1177/0956797613479386
-
[3]
Mack, A. & Rock, I. (1998). Inattentional Blindness. MIT Press. DOI: 10.7551/mit- press/3707.001.0001
-
[4]
Binz, M. & Schulz, E. (2023). Using cognitive psychology to understand GPT-3. PNAS, 120(6), e2218523120. DOI: 10.1073/pnas.2218523120
-
[5]
URL: https://doi.org/10.1038/s43588-023-00527-x
Hagendorff, T., Fabi, S. & Kosinski, M. (2023). Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3(10), 833–838. DOI: 10.1038/s43588-023-00527-x
-
[6]
IRASim: A fine-grained world model for robot manipulation,
Dahou, Y., Huynh, N. D., Le-Khac, P. H., Para, W. R., Singh, A. & Narayan, S. (2025). Vision-language models can’t see the obvious (SalBench). ICCV 2025. DOI: 10.1109/ICCV51701.2025.02239. arXiv:2507.04741
-
[7]
S., Malhotra, G., Dujmović, M., et al
Bowers, J. S., Malhotra, G., Dujmović, M., et al. (2023). Deep problems with neu- ral network models of human vision. Behavioral and Brain Sciences, 46, e385. DOI: 10.1017/S0140525X22002813. arXiv:2312.05355
-
[8]
doi: 10.1017/S0140525X22002849
Quilty-Dunn, J., Porot, N. & Mandelbaum, E. (2023). The best game in town: The re- emergence of the language-of-thought hypothesis across the cognitive sciences. Behavioral and Brain Sciences, 46, e261. DOI: 10.1017/S0140525X22002849
-
[9]
Most, S. B., Scholl, B. J., Clifford, E. R. & Simons, D. J. (2005). What you see is what you set: Sustained inattentional blindness and the capture of awareness. Psychological Review, 112(1), 217–242. DOI: 10.1037/0033-295X.112.1.217
-
[10]
Zamir, E. (2014). The bias of the question posed: A diagnostic “invisible gorilla.” Diagnosis, 1(3), 245-248. DOI: 10.1515/dx-2014-0017
-
[11]
K., Ouyang, B., Kocak, M., Bhabad, S., Bleck, T
Garg, R. K., Ouyang, B., Kocak, M., Bhabad, S., Bleck, T. P. & Jhaveri, M. (2022). Inat- tentional blindness to DWI lesions in spontaneous intracerebral hemorrhage. Neurological Sciences, 43(7), 4355-4361. DOI: 10.1007/s10072-022-05992-2
-
[12]
Hults, C. M., Ding, Y., Xie, G. G., Raja, R., Johnson, W., Lee, A. & Simons, D. J. (2024). Inattentional blindness in medicine. Cognitive Research: Principles and Implications, 9(1), 18. DOI: 10.1186/s41235-024-00537-x
-
[13]
Neisser, U. & Becklen, R. (1975). Selective looking: Attending to visually specified events. Cognitive Psychology, 7(4), 480–494. DOI: 10.1016/0010-0285(75)90019-5
-
[14]
Berbaum, K. S., Franken, E. A., Dorfman, D. D., Rooholamini, S. A., Kathol, M. H., Barloon, T. J., Behlke, F. M., Sato, Y., Lu, C. H., el-Khoury, G. Y., Flickinger, F. W. & Montgomery, W. J. (1990). Satisfaction of search in diagnostic radiology. Invest. Radiol. 25, 133–140. DOI: 10.1097/00004424-199002000-00006
-
[15]
Berbaum, K. S., Franken, E. A., Caldwell, R. T. & Schartz, K. M. (2001). Gaze dwell times on acute trauma injuries missed because of satisfaction of search. Acad. Radiol. 8, 304–314. DOI: 10.1016/S1076-6332(03)80499-3
-
[16]
Adamo, S. H., Gereke, B. J., Shomstein, S. & Schmidt, J. (2021). From “satisfaction of search” to “subsequent search misses”: A review of multiple-target search errors across radiology and cognitive science. Cogn. Res. Princ. Implic. 6, 59. DOI: 10.1186/s41235-021-00318-w
-
[17]
Williams, L. H., Carrigan, A. J., Auffermann, W. F., Mills, M. K., Rich, A. N., Elmore, J. G. & Drew, T. (2021). The invisible breast cancer: Experience does not protect against 19 inattentional blindness to clinically relevant findings in radiology. Psychonomic Bulletin & Review, 28(2), 503–511. DOI: 10.3758/s13423-020-01826-4
-
[18]
Robson, S. G. & Tangen, J. M. (2023). The invisible 800-pound gorilla: Expertise can increase inattentional blindness. Cogn. Res. Princ. Implic. 8, 33. DOI: 10.1186/s41235-023-00486-x
-
[19]
Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J. (2017). Building ma- chines that learn and think like people. Behavioral and Brain Sciences, 40, e253. DOI: 10.1017/S0140525X16001837
-
[20]
Hagendorff, T., Dasgupta, I., Binz, M., Chan, S. C. Y., Lampinen, A., Wang, J. X., Akata, Z. & Schulz, E. (2023). Machine psychology: Investigating emergent capabilities and behavior in large language models using psychological methods. arXiv:2303.13988
arXiv 2023
-
[21]
Lampinen, A. K., Dasgupta, I., Chan, S. C. Y., Sheahan, H. R., Creswell, A., Kumaran, D., McClelland, J. L. & Hill, F. (2024). Language models, like humans, show content effects on reasoning tasks. PNAS Nexus 3, pgae233. DOI: 10.1093/pnasnexus/pgae233
-
[22]
Mahowald, K., Ivanova, A. A., Blank, I. A., Kanwisher, N., Tenenbaum, J. B. & Fedorenko, E. (2024). Dissociating language and thought in large language models. Trends in Cognitive Sciences, 28(6), 517–540. DOI: 10.1016/j.tics.2024.01.011
-
[23]
doi: 10.1016/j.tics.2024.02.008
Yildirim, I. & Paul, L. A. (2024). From task structures to world models: What do LLMs know? Trends Cogn. Sci. 28, 404–415. DOI: 10.1016/j.tics.2024.02.008
-
[24]
Webb, T., Holyoak, K. J. & Lu, H. (2023). Emergent analogical reasoning in large language models. Nat. Hum. Behav. 7, 1526–1541. DOI: 10.1038/s41562-023-01659-w
-
[25]
Block, N. (2011). Perceptual consciousness overflows cognitive access. Trends in Cognitive Sciences, 15(12), 567–575. DOI: 10.1016/j.tics.2011.11.001
-
[26]
Cohen, M. A., Dennett, D. C. & Kanwisher, N. (2016). What is the bandwidth of perceptual experience? Trends Cogn. Sci. 20, 324–335. DOI: 10.1016/j.tics.2016.03.006
-
[27]
van Amsterdam, W. A. C., van Geloven, N., Krijthe, J. H., Ranganath, R. & Cinà, G. (2025). When accurate prediction models yield harmful self-fulfilling prophecies. Patterns, 6(4), 101229. DOI: 10.1016/j.patter.2025.101229
-
[28]
Park, Simon Goldstein, Aidan O'Gara, Michael Chen, and Dan Hendrycks
Park, P. S., Goldstein, S., O’Gara, A., Chen, M. & Hendrycks, D. (2024). AI decep- tion: A survey of examples, risks, and potential solutions. Patterns 5, 100988. DOI: 10.1016/j.patter.2024.100988
-
[29]
Sanchez, M., Alford, K., Krishna, V., Huynh, T. M., Nguyen, C. D. T., Lungren, M. P., Truong, S. Q. H. & Rajpurkar, P. (2023). AI-clinician collaboration via disagreement prediction: A decision pipeline and retrospective analysis of real-world radiologist-AI interactions. Cell Reports Medicine, 4(10), 101207. DOI: 10.1016/j.xcrm.2023.101207
-
[30]
Rahmanzadehgervi, P., Bolton, L., Taesiri, M. R. & Nguyen, A. T. (2024). Vision language models are blind. arXiv:2407.06581 (ACCV 2024)
arXiv 2024
-
[31]
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y. & Xie, S. (2024). Eyes wide shut? Explor- ing the visual shortcomings of multimodal LLMs. Proc. IEEE/CVF CVPR 2024. DOI: 10.1109/CVPR52733.2024.00914. arXiv:2401.06209
-
[32]
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W. X. & Wen, J.-R. (2023). Evaluating object hallucination in large vision-language models. Proc. EMNLP 2023. arXiv:2305.10355
Pith/arXiv arXiv 2023
-
[33]
Y., Shrivastava, A., Moore, J., West, P., Tan, C
Fu, H. Y., Shrivastava, A., Moore, J., West, P., Tan, C. & Holtzman, A. (2025). AbsenceBench: Language models can’t tell what’s missing. arXiv:2506.11440
arXiv 2025
-
[34]
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M. & Wichmann, F. A. (2020). Shortcut learning in deep neural networks. Nat. Mach. Intell. 2, 665–673. DOI: 10.1038/s42256-020-00257-z
-
[35]
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. & Mané, D. (2016). Concrete problems in AI safety. arXiv:1606.06565. 20
Pith/arXiv arXiv 2016
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Booth, S., Knox, W. B., Shah, J., Niekum, S., Stone, P. & Allievi, A. (2023). The perils of trial-and-error reward design: Misdesign through overfitting and invalid task specifications. Proc. AAAI Conf. Artif. Intell. 37, 5920–5929. DOI: 10.1609/aaai.v37i5.25733
-
[37]
Oakden-Rayner, L., Dunnmon, J., Carneiro, G. & Ré, C. (2020). Hidden stratification causes clinically meaningful failures in medical imaging deep learning. Proc. ACM Conf. Health Inference Learn. (CHIL) 151–159. DOI: 10.1145/3368555.3384468
-
[38]
Wu, E., Wu, K., Daneshjou, R., Ouyang, D., Ho, D. E. & Zou, J. (2021). How medical AI devices are evaluated: Limitations and recommendations from an analysis of FDA approvals. Nat. Med. 27, 582–584. DOI: 10.1038/s41591-021-01312-x
-
[39]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. (2017). Attention is all you need. NeurIPS 2017. arXiv:1706.03762
Pith/arXiv arXiv 2017
-
[40]
Evans, J. St. B. T. & Stanovich, K. E. (2013). Dual-process theories of higher cognition: Advancing the debate. Perspect. Psychol. Sci. 8, 223–241. DOI: 10.1177/1745691612460685
-
[41]
Itti, L. & Koch, C. (1998). A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 20, 1254–1259. DOI: 10.1109/34.730558
-
[42]
Bainbridge, L. (1983). Ironies of automation. Automatica, 19(6), 775–779. DOI: 10.1016/0005- 1098(83)90046-8
-
[43]
Parasuraman, R. & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253. DOI: 10.1518/001872097778543886
-
[44]
Parasuraman, R. & Manzey, D. H. (2010). Complacency and bias in human use of automation: An attentional integration. Hum. Factors 52, 381–410. DOI: 10.1177/0018720810376055
-
[45]
Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G. & Beck, H. P. (2003). The role of trust in automation reliance. Int. J. Hum.-Comput. Stud. 58, 697–718. DOI: 10.1016/S1071-5819(03)00038-7
-
[46]
Goddard, K., Roudsari, A. & Wyatt, J. C. (2012). Automation bias: A systematic review of frequency, effect mediators, and mitigators. J. Am. Med. Inform. Assoc. 19, 121–127. DOI: 10.1136/amiajnl-2011-000089
-
[47]
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux
2011
-
[48]
Yu, C., Engelmann, S., Cao, R., Ali, D. & Papakyriakopoulos, O. (2026). How should AI safety benchmarks benchmark safety? arXiv:2601.23112. DOI: 10.48550/arXiv.2601.23112
-
[49]
Torres, I., & Evals-Consensus.AI Consortium. (2026). A call to join a collective effort on AI evaluation. Patterns, 7(3), 101512. DOI: 10.1016/j.patter.2026.101512
-
[50]
Kundel, H. L., Nodine, C. F. & Carmody, D. (1978). Visual scanning, pattern recognition and decision-making in pulmonary nodule detection. Invest. Radiol. 13, 175–181. DOI: 10.1097/00004424-197805000-00001
-
[51]
Krupinski, E. A. (2010). Current perspectives in medical image perception. Atten. Percept. Psychophys. 72, 1205–1217. DOI: 10.3758/APP.72.5.1205
-
[52]
de Cassai, A., Negro, S., Geraldini, F., Boscolo, A., Sella, N., Munari, M. & Navalesi, P. (2021). Inattentional blindness in anesthesiology: A gorilla is worth one thousand words. PLoS ONE 16, e0257508. DOI: 10.1371/journal.pone.0257508
-
[53]
Roadsaw: A large-scale dataset for camera- based road surface and wetness estimation,
Bogdoll, D., Nitsche, M. & Zöllner, J. M. (2022). Anomaly detection in autonomous driving: A survey. Proc. IEEE/CVF CVPR Workshops 2022. DOI: 10.1109/CVPRW56347.2022.00495. arXiv:2204.07974
-
[54]
Chan, R., Lis, K., Uhlemeyer, S., Blum, H., Honari, S., Siegwart, R., Fua, P., Salzmann, M. & Rottmann, M. (2021). SegmentMeIfYouCan: A benchmark for anomaly segmentation. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. arXiv:2104.14812. 21 The complete annotated bibliography of 116 works, each carrying a finding...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.