Black-Box Inference of LLM Architectural Properties with Restrictive API Access
Pith reviewed 2026-07-03 21:32 UTC · model grok-4.3
The pith
Restrictive black-box LLM APIs still permit recovery of hidden dimensions, depth, and parameter counts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
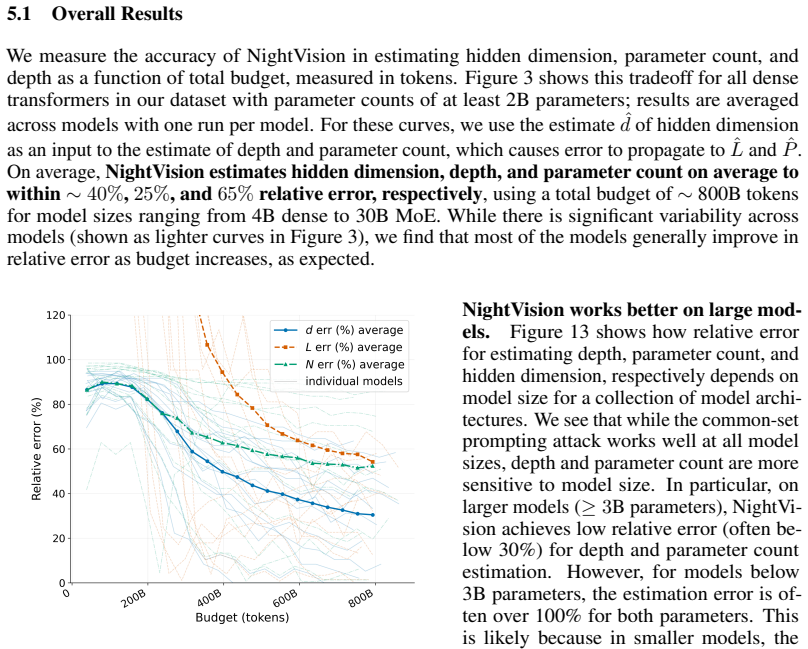
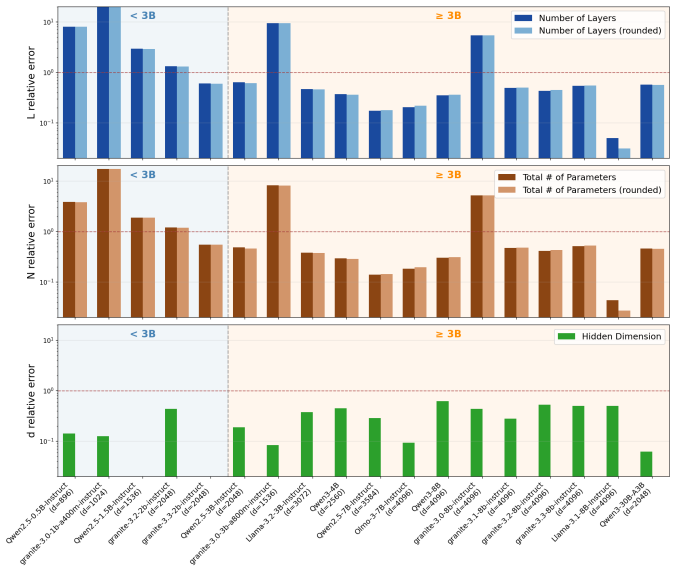
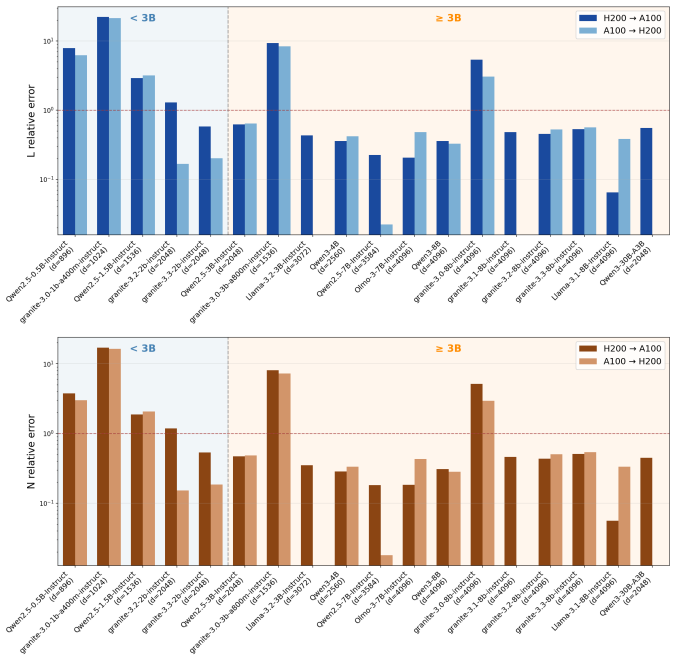
NightVision recovers hidden dimension to 23 percent average relative error across all tested models and 9 percent on MoE models by spectral analysis of log probabilities obtained through common-set prompting; it then uses the dimension estimate together with end-to-end time-to-first-token measurements to recover depth and parameter count to within 53 percent for models exceeding three billion parameters.
What carries the argument
Common-set prompting that forces multiple prompts to surface log probabilities for the same output tokens, enabling spectral analysis to isolate the hidden dimension.
If this is right
- Current API restrictions are insufficient to fully obfuscate LLM architectural details.
- Hidden-dimension recovery reaches 9 percent average relative error on mixture-of-experts models.
- Depth and parameter-count estimates reach 53 percent accuracy for models larger than three billion parameters.
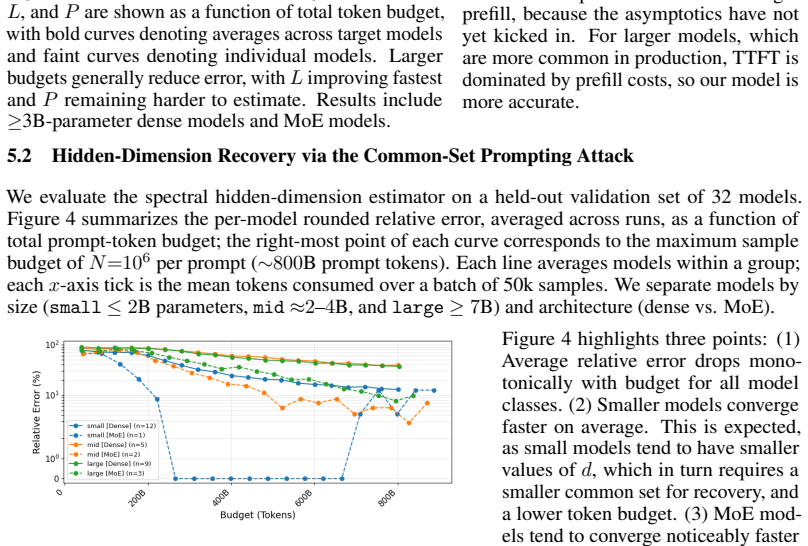
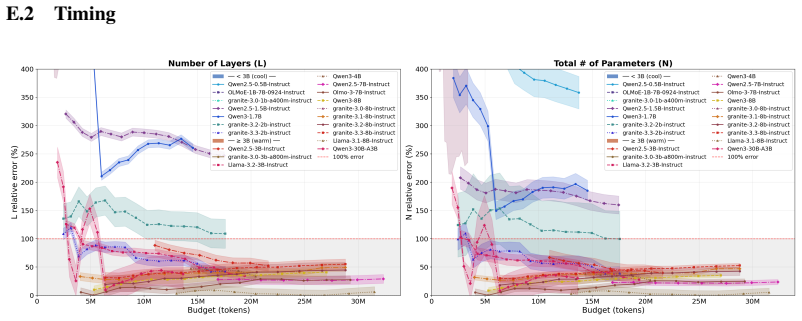
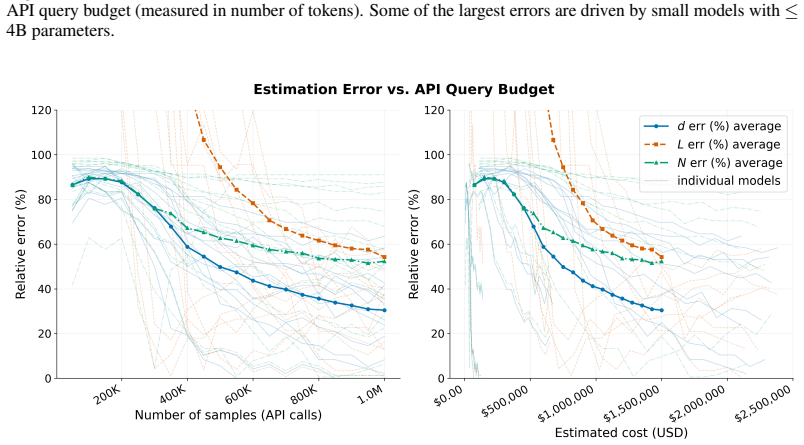
- Inference accuracy improves with larger token budgets and varies systematically with model size and architecture type.
Where Pith is reading between the lines
- The same prompting-plus-timing pipeline could be applied directly to closed commercial endpoints to measure leakage in production settings.
- Small additive noise on output probabilities might disrupt the spectral signatures that NightVision relies upon.
- Response-time side channels could be hardened by server-side padding or rate limits that mask true compute depth.
Load-bearing premise
The spectral properties of the collected log probabilities encode the hidden dimension without substantial confounding from other architectural choices or training details.
What would settle it
Running the common-set prompting procedure on open-source models whose hidden dimensions are publicly known and observing that the spectral estimates deviate from the true values by more than the reported average relative error.
Figures




read the original abstract
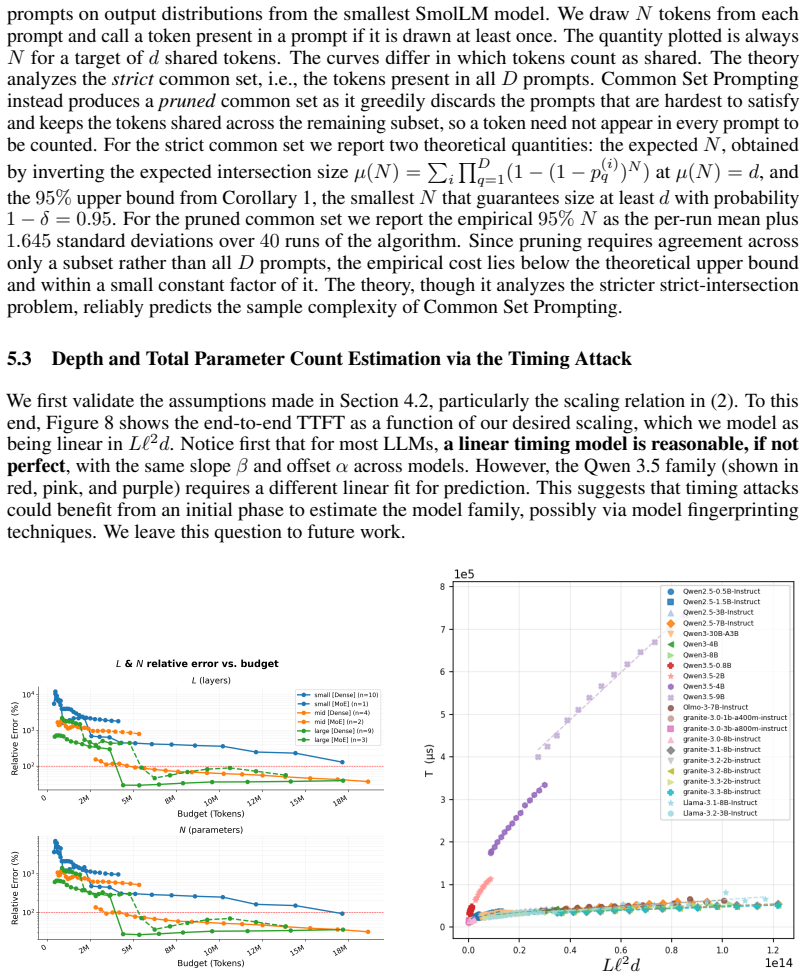
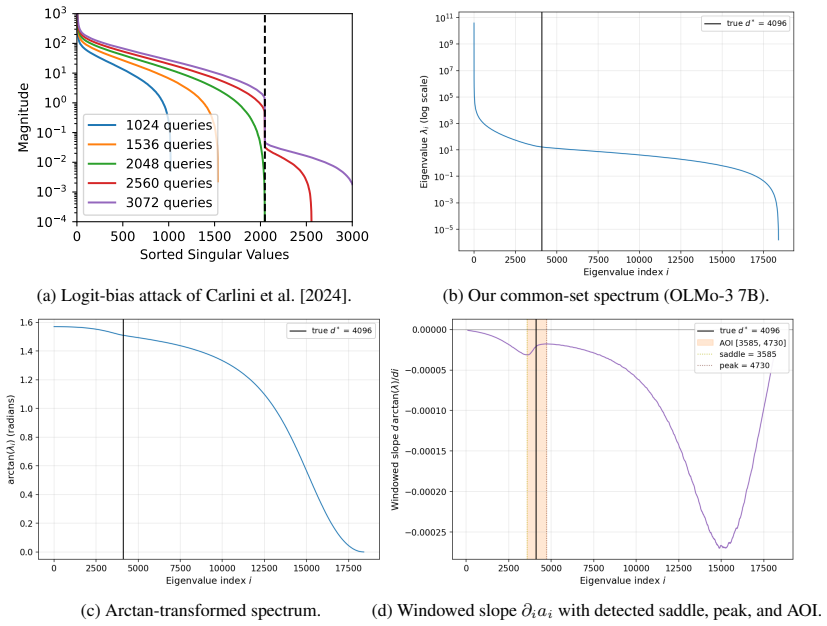
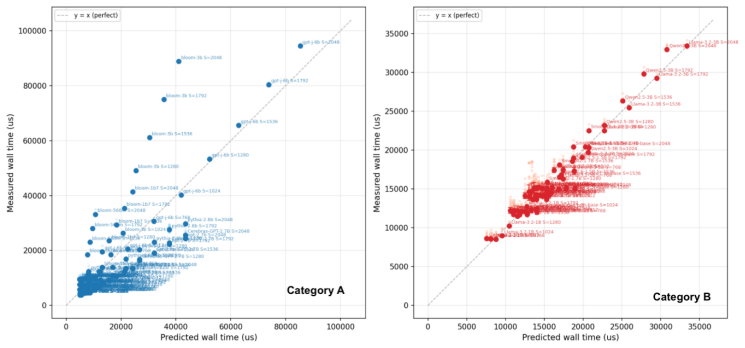
In practice, most commercial LLM providers do not publicly release details of underlying LLM architectures. However, prior work has shown that given limited API access to an LLM (namely, top-$k$ logits and/or a logit bias function), one can recover certain architectural details of an LLM, such as the hidden dimension of the feed-forward network. Perhaps in response to these results, most commercial LLM providers have restricted their APIs to expose only the single logit for each decoded token, and they no longer give users the ability to bias logits. We show that even under current restrictive APIs, several architectural parameters are still recoverable. We present NightVision, an attack that uses restrictive black-box API access to estimate the hidden dimension, depth, and parameter count of an LLM. Algorithmically, NightVision relies on a novel common set prompting technique in which multiple prompts expose log probabilities for the same set of output tokens; a spectral analysis of these results is used to infer hidden dimension. NightVision additionally uses end-to-end time to first token (TTFT) measurements and the estimated hidden dimension to estimate depth and parameter count. We empirically evaluate NightVision on 32 open-source LLMs, recovering hidden dimension to within 23% average relative error across all models (9% on MoE models), and depth and parameter count to within 53% for models exceeding three billion parameters. We run extensive ablations to demonstrate how these accuracies scale with token budget and model properties. Overall, our results suggest that current LLM APIs are not sufficiently restricted to fully obfuscate the architectural details of their underlying models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that restrictive LLM APIs exposing only single logits per token still allow recovery of hidden dimension, depth, and parameter count via NightVision. The method uses common-set prompting to collect log probabilities over identical output tokens across prompts, followed by spectral analysis to infer hidden dimension; TTFT measurements combined with the dimension estimate then recover depth and parameter count. On 32 open-source models under simulated restrictive access, it reports 23% average relative error for hidden dimension (9% on MoE models) and 53% error for depth and parameter count on models exceeding 3B parameters, with ablations on token budget.
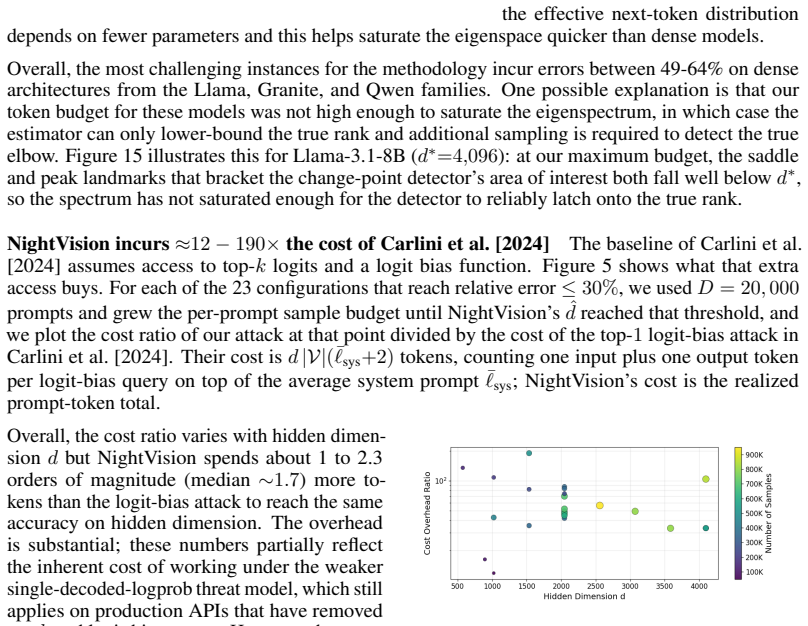
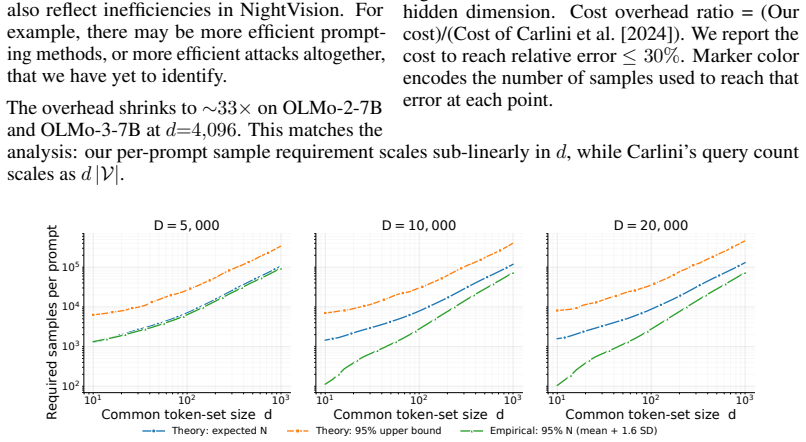
Significance. If the spectral features prove to be driven primarily by hidden dimension rather than correlated architectural or training choices, the result would be significant: it demonstrates that current single-logit API restrictions are insufficient to fully obscure model architecture, with direct implications for model-provenance and security analyses. The work earns credit for its scale (32 models), concrete error metrics, and explicit ablations on token budget and model properties.
major comments (2)
- [NightVision spectral analysis (as described in the method and abstract)] The central recovery of hidden dimension rests on the premise that spectral properties of the collected log-probability vectors encode hidden dimension with limited interference from other factors. The evaluation reports 23% average relative error across 32 models but provides no controls or ablations that isolate hidden dimension from correlated properties such as attention configuration, activation function, or vocabulary-induced logit distributions; without such isolation the reported accuracy may not transfer to unseen closed models.
- [TTFT-based depth and parameter estimation] The TTFT-to-depth and parameter-count mapping is load-bearing for the second half of the claims, yet the manuscript does not detail the precise functional form, any hardware or batch-size assumptions, or sensitivity analysis; the 53% error figure for models >3B therefore cannot be assessed for robustness when the hidden-dimension estimate itself carries 23% error.
minor comments (1)
- [Evaluation and ablations] The abstract states that 'extensive ablations' demonstrate scaling with token budget, but the main text should include a dedicated table or figure quantifying error versus number of prompts/tokens for each recovered quantity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: The central recovery of hidden dimension rests on the premise that spectral properties of the collected log-probability vectors encode hidden dimension with limited interference from other factors. The evaluation reports 23% average relative error across 32 models but provides no controls or ablations that isolate hidden dimension from correlated properties such as attention configuration, activation function, or vocabulary-induced logit distributions; without such isolation the reported accuracy may not transfer to unseen closed models.
Authors: We acknowledge that the evaluation does not include controlled experiments in which only hidden dimension is varied while fixing all other architectural choices, as this would require training many models from scratch. The 32-model testbed does, however, span substantial diversity in attention configurations, activation functions, and vocabulary sizes, and the method achieves lower error on the MoE subset. We will add a discussion section that explicitly addresses potential confounding factors and the limits this places on claims about generalization to unseen closed models. revision: partial
-
Referee: The TTFT-to-depth and parameter-count mapping is load-bearing for the second half of the claims, yet the manuscript does not detail the precise functional form, any hardware or batch-size assumptions, or sensitivity analysis; the 53% error figure for models >3B therefore cannot be assessed for robustness when the hidden-dimension estimate itself carries 23% error.
Authors: We agree that the current manuscript lacks sufficient detail on the TTFT-based estimator. In revision we will specify the exact functional form relating TTFT and the hidden-dimension estimate to depth and parameter count, state the hardware and batch-size conditions under which TTFT was measured, and include a sensitivity analysis that propagates the 23% hidden-dimension error into the final depth and parameter-count predictions. revision: yes
Circularity Check
No circularity: empirical inference method validated on open models
full rationale
The paper describes an empirical attack (NightVision) that collects log-probabilities via common-set prompting, applies spectral analysis to recover hidden dimension, and uses TTFT measurements plus the dimension estimate to recover depth and parameter count. All performance claims (23% relative error on hidden dimension, 53% on depth/params for large models) are measured directly against ground-truth values on 32 open-source LLMs under simulated restrictive access. No derivation step reduces a claimed prediction to a fitted parameter by the paper's own equations, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled in; the method is therefore self-contained as an experimental procedure rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[2]
The Thirteenth International Conference on Learning Representations , year=
Gated Delta Networks: Improving Mamba2 with Delta Rule , author=. The Thirteenth International Conference on Learning Representations , year=
-
[3]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[4]
2023 , url=
Joshua Ainslie and James Lee-Thorp and Michiel de Jong and Yury Zemlyanskiy and Federico Lebron and Sumit Sanghai , booktitle=. 2023 , url=
2023
-
[5]
FlashAttention: Fast and Memory-Efficient Exact Attention with
Tri Dao and Daniel Y Fu and Stefano Ermon and Atri Rudra and Christopher Re , booktitle=. FlashAttention: Fast and Memory-Efficient Exact Attention with. 2022 , url=
2022
-
[6]
Stealing Neural Networks via Timing Side Channels
Stealing neural networks via timing side channels , author=. arXiv preprint arXiv:1812.11720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Deepsniffer: A
Hu, Xing and Liang, Ling and Li, Shuangchen and Deng, Lei and Zuo, Pengfei and Ji, Yu and Xie, Xinfeng and Ding, Yufei and Liu, Chang and Sherwood, Timothy and others , booktitle=. Deepsniffer: A
-
[8]
Inputsnatch: Stealing input in
Zheng, Xinyao and Han, Husheng and Shi, Shangyi and Fang, Qiyan and Du, Zidong and Hu, Xing and Guo, Qi , journal=. Inputsnatch: Stealing input in
-
[9]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Instructional fingerprinting of large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[10]
Negative Association of Random Variables with Applications , urldate =
Kumar Joag-Dev and Frank Proschan , journal =. Negative Association of Random Variables with Applications , urldate =
-
[11]
Journal of Theoretical Probability , year =
Shao, Qi-Man , title =. Journal of Theoretical Probability , year =. doi:10.1023/A:1007849609234 , url =
-
[12]
BRICS Report Series , volume=
Balls and bins: A study in negative dependence , author=. BRICS Report Series , volume=
-
[13]
Logits of
Finlayson, Matthew and Ren, Xiang and Swayamdipta, Swabha , booktitle=. Logits of. 2024 , url=
2024
-
[14]
Stealing part of a production language model , author=. arXiv preprint arXiv:2403.06634 , year=
-
[15]
Fast estimation of approximate matrix ranks using spectral densities
Fast estimation of approximate matrix ranks using spectral densities , author=. arXiv preprint arXiv:1608.05754 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Computational Statistics & Data Analysis , volume=
Automatic dimensionality selection from the scree plot via the use of profile likelihood , author=. Computational Statistics & Data Analysis , volume=. 2006 , publisher=
2006
-
[17]
Statistics and Computing , volume=
A tutorial on spectral clustering , author=. Statistics and Computing , volume=. 2007 , publisher=
2007
-
[18]
Reading Between the Lines: Towards Reliable Black-box
Shao, Shuo and Li, Yiming and Yao, Hongwei and Chen, Yifei and Yang, Yuchen and Qin, Zhan , journal=. Reading Between the Lines: Towards Reliable Black-box
-
[19]
arXiv preprint arXiv:2508.19843 , year=
Sok: Large language model copyright auditing via fingerprinting , author=. arXiv preprint arXiv:2508.19843 , year=
-
[20]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ LLMmap \ : Fingerprinting for large language models , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[21]
arXiv preprint arXiv:2410.14273 , year=
Reef: Representation encoding fingerprints for large language models , author=. arXiv preprint arXiv:2410.14273 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Huref: Human-readable fingerprint for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Trap: Targeted random adversarial prompt honeypot for black-box identification , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[24]
Operationalizing a threat model for red-teaming large language models (
Verma, Apurv and Krishna, Satyapriya and Gehrmann, Sebastian and Seshadri, Madhavan and Pradhan, Anu and Ault, Tom and Barrett, Leslie and Rabinowitz, David and Doucette, John and Phan, NhatHai , journal=. Operationalizing a threat model for red-teaming large language models (
-
[25]
A survey of
Pan, James and Li, Guoliang , journal=. A survey of
-
[26]
Large language model inference acceleration: A comprehensive hardware perspective , author=. arXiv preprint arXiv:2410.04466 , year=
-
[27]
Incompressible Knowledge Probes: Estimating Black-Box
Li, Bojie , journal=. Incompressible Knowledge Probes: Estimating Black-Box
-
[28]
2025 , publisher=
Alhazbi, Saeif and Hussain, Ahmed and Oligeri, Gabriele and Papadimitratos, Panos , journal=. 2025 , publisher=
2025
-
[29]
Proceedings of the 2025 14th International Conference on Software and Computer Applications , pages=
Bridging the Security Gap: An Empirical Analysis of LLM-API Integration Vulnerabilities and Mitigation Strategies , author=. Proceedings of the 2025 14th International Conference on Software and Computer Applications , pages=
2025
-
[30]
Proceedings of the ACM Web Conference 2026 , pages=
Exploring and Exploiting Security Vulnerabilities in Self-Hosted LLM Services , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[31]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
AuditLLM: A tool for auditing large language models using multiprobe approach , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
-
[32]
AI and Ethics , volume=
Auditing large language models: a three-layered approach , author=. AI and Ethics , volume=. 2024 , publisher=
2024
-
[33]
Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society , pages=
Supporting human-ai collaboration in auditing llms with llms , author=. Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society , pages=
2023
-
[34]
25th USENIX security symposium (USENIX Security 16) , pages=
Stealing machine learning models via prediction \ APIs \ , author=. 25th USENIX security symposium (USENIX Security 16) , pages=
-
[35]
Wei, Junyi and Zhang, Yicheng and Zhou, Zhe and Li, Zhou and Al Faruque, Mohammad Abdullah , booktitle=. Leaky. 2020 , organization=
2020
-
[36]
arXiv preprint arXiv:2311.13647 , year=
Language model inversion , author=. arXiv preprint arXiv:2311.13647 , year=
-
[37]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
A survey on model extraction attacks and defenses for large language models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[38]
arXiv preprint arXiv:2512.03816 , year=
Log Probability Tracking of LLM APIs , author=. arXiv preprint arXiv:2512.03816 , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.