When Identity Overrides Incentives: Representational Choices as Governance Decisions in Multi-Agent LLM Systems
Pith reviewed 2026-05-16 14:26 UTC · model grok-4.3
The pith
Assigning role-based personas to LLM agents suppresses payoff-aligned behavior in strategic games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
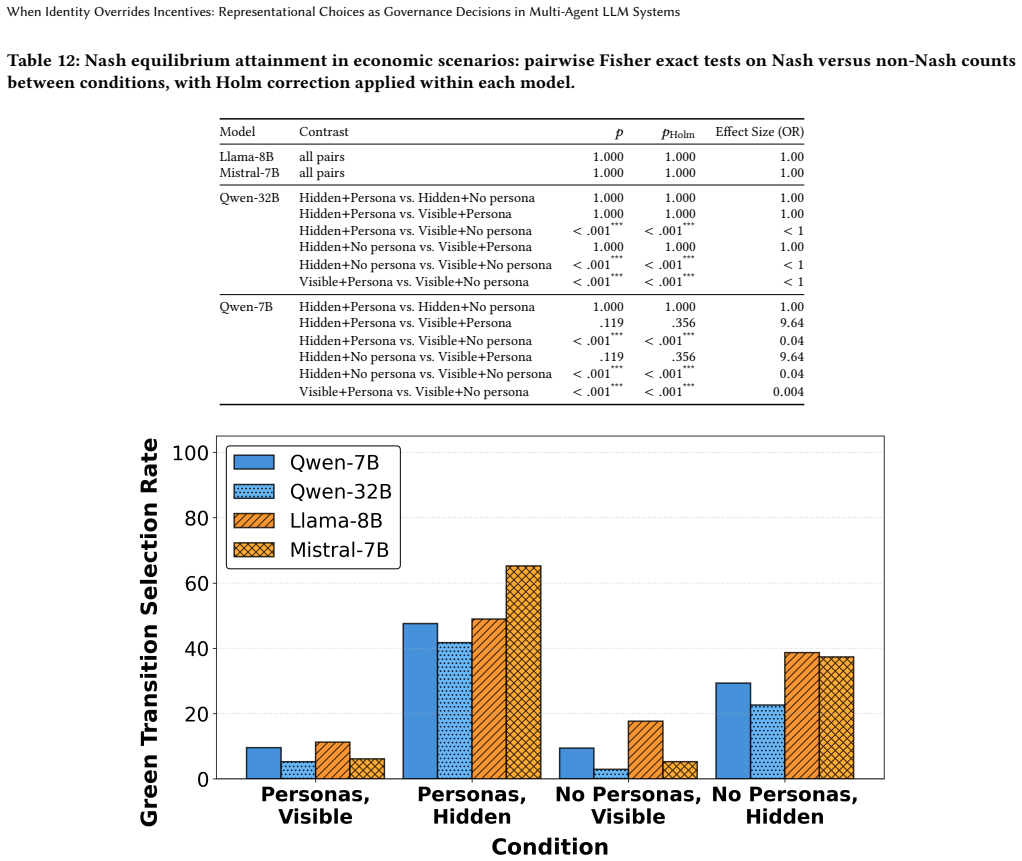
Assigning role-based personas suppresses payoff-aligned behavior in four-agent strategic games, shifting equilibrium attainment by up to 90 percentage points even when agents have complete payoff information. With personas present, all models reach near-zero Tragedy equilibrium rates in Tragedy-dominant scenarios and 100 percent of equilibria correspond to Green Transition. No model reaches Tragedy equilibrium by removing personas alone; only Qwen models reach 65-90 percent Tragedy rates when both personas are removed and payoffs are made explicit. Three behavioral profiles emerge across models.
What carries the argument
The 2x2 factorial design testing persona presence against payoff visibility in four-agent games with Tragedy of the Commons and Green Transition equilibria.
If this is right
- Persona assignment causes all models to select the Green Transition equilibrium at 100 percent in Tragedy-dominant scenarios.
- Payoff visibility alone does not restore Tragedy equilibrium selection in most models.
- Qwen models alone reach 65-90 percent Tragedy equilibrium when personas are absent and payoffs explicit.
- Model-specific profiles determine response patterns: Qwen shifts with framing, Mistral increases variance, Llama stays constant.
- Representational choices determine which equilibrium a simulation produces independent of the incentive structure.
Where Pith is reading between the lines
- In deployed policy simulations, persona selection effectively pre-determines collective versus individual outcomes.
- Model choice and persona design may require joint calibration to achieve desired incentive alignment.
- Testing the same design in non-environmental games could show whether the override is general across strategic domains.
- Neutral prompt templates might reduce but not remove the effect of identity framing.
Load-bearing premise
The large observed shifts are caused by the persona assignments themselves rather than by uncontrolled differences in prompt phrasing or equilibrium classification from generated text.
What would settle it
Re-running the 53 scenarios with identical base prompts but persona text removed and re-classifying equilibria from the output text to check whether the 90-point shift persists.
Figures







read the original abstract
Multi-agent systems built on large language models are increasingly deployed in strategic policy and governance settings, where agents representing stakeholders with conflicting interests must coordinate under shared constraints. These systems typically assign role-based personas to agents, describing their motivations and objectives. Whether agents with role-based identities follow explicit payoffs or their assigned roles in strategic decision-making remains untested. Here we show that assigning role-based personas suppresses payoff-aligned behavior in four-agent strategic games, shifting equilibrium attainment by up to 90 percentage points even when agents have complete payoff information. We test a 2x2 factorial design (persona presence x payoff visibility) across four models (Qwen-7B, Qwen-32B, Llama-8B, Mistral-7B), and 53 environmental policy scenarios with two equilibria: Tragedy of the Commons, where individual payoff dominates, and Green Transition, where collective payoff dominates. With personas present, all models reach near-zero Tragedy equilibrium in the Tragedy-dominant scenarios despite complete payoff information, and 100% of equilibria correspond to Green Transition. No model reaches Tragedy equilibrium by removing personas alone; only Qwen models reach 65-90% Tragedy equilibrium rates when personas are removed, and payoffs are made explicit. Three distinct behavioral profiles emerge: Qwen shifts equilibrium selection based on framing condition, Mistral increases response variance without reaching the Tragedy equilibrium, and Llama holds near-constant across all conditions. Representational choices in multi-agent LLM systems are governance decisions: persona assignment determines which equilibrium a simulation produces, independent of the underlying incentive structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that assigning role-based personas to agents in multi-agent LLM systems suppresses payoff-aligned behavior in four-agent environmental policy games, shifting equilibrium attainment by up to 90 percentage points even with complete payoff information. Using a 2x2 factorial design (persona presence x payoff visibility) across Qwen-7B, Qwen-32B, Llama-8B, and Mistral-7B on 53 scenarios with Tragedy of the Commons vs. Green Transition equilibria, it reports that personas lead to near-100% Green Transition outcomes while removing personas allows some models (Qwen) to reach 65-90% Tragedy equilibria; three behavioral profiles across models are identified, concluding that representational choices function as governance decisions.
Significance. If the central empirical pattern holds under transparent measurement, the result is significant for multi-agent LLM deployments in policy and governance, as it shows that persona framing can override explicit incentives in determining simulated equilibria. This provides a concrete demonstration of how identity assignments shape collective outcomes in LLM-based systems, with potential implications for simulation-based decision support.
major comments (3)
- [Methods / Results] The equilibrium classification procedure used to map free-text agent outputs to Tragedy vs. Green Transition is not described with explicit, reproducible criteria (e.g., keyword lists, semantic rules, or decision tree). This mapping is load-bearing for the headline claim of up to 90pp shifts, and because persona prompts explicitly reference stakeholder motivations and collective goals, any heuristic weighting environmental language will systematically favor Green labels when personas are present, creating an unseparated measurement confound.
- [Experimental Setup] No details are provided on the number of replicates per condition, statistical tests, response variance, or inter-condition reliability. The abstract reports consistent directional effects across models and the factorial design, but without these the magnitude and robustness of the reported shifts (e.g., 65-90% Tragedy rates for Qwen) cannot be evaluated.
- [Results] The 2x2 design does not include controls for prompt-phrasing variations independent of persona content or for how equilibria are extracted from generated text; the model-specific profiles (Qwen shifts, Mistral variance, Llama constancy) are reported but rest on the same unvalidated classification step.
minor comments (1)
- [Abstract] The abstract states '53 environmental policy scenarios' without indicating how scenarios were sampled or balanced between Tragedy-dominant and Green-dominant payoff structures.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important gaps in methodological transparency. We address each point below and will revise the manuscript to improve reproducibility and address potential confounds.
read point-by-point responses
-
Referee: [Methods / Results] The equilibrium classification procedure used to map free-text agent outputs to Tragedy vs. Green Transition is not described with explicit, reproducible criteria (e.g., keyword lists, semantic rules, or decision tree). This mapping is load-bearing for the headline claim of up to 90pp shifts, and because persona prompts explicitly reference stakeholder motivations and collective goals, any heuristic weighting environmental language will systematically favor Green labels when personas are present, creating an unseparated measurement confound.
Authors: We agree that explicit documentation of the classification procedure is essential for reproducibility and to rule out measurement artifacts. In the revised manuscript we will add a dedicated subsection that specifies the full decision criteria: a primary rule based on the agent's explicit final action (e.g., 'choose individual maximization' maps to Tragedy; 'select collective sustainable option' maps to Green Transition), supplemented by a short keyword list and a decision tree for edge cases. Classification is performed on the terminal choice statement rather than on reasoning text or persona language. We will also include representative excerpts from both persona and no-persona conditions to demonstrate that the mapping tracks the selected equilibrium, not descriptive phrasing. These additions directly separate the measurement step from prompt content. revision: yes
-
Referee: [Experimental Setup] No details are provided on the number of replicates per condition, statistical tests, response variance, or inter-condition reliability. The abstract reports consistent directional effects across models and the factorial design, but without these the magnitude and robustness of the reported shifts (e.g., 65-90% Tragedy rates for Qwen) cannot be evaluated.
Authors: We acknowledge that these quantitative details were omitted from the initial submission. The revision will include a complete experimental-methods paragraph stating that each of the 53 scenarios was run for 100 independent replicates per cell of the 2x2 design, that chi-square tests were used to compare equilibrium proportions across conditions, that response variance is quantified via standard deviation of per-scenario attainment rates, and that inter-condition reliability is assessed by reporting 95% confidence intervals on the percentage-point shifts. These statistics will be added to the results tables and text so that the 65-90% Tragedy rates for Qwen can be properly evaluated. revision: yes
-
Referee: [Results] The 2x2 design does not include controls for prompt-phrasing variations independent of persona content or for how equilibria are extracted from generated text; the model-specific profiles (Qwen shifts, Mistral variance, Llama constancy) are reported but rest on the same unvalidated classification step.
Authors: The referee is correct that the current design does not contain an orthogonal prompt-phrasing control. We will add a limitations paragraph and a supplementary robustness check that re-runs a subset of scenarios with paraphrased persona and no-persona prompts while holding all other wording fixed. The model-specific behavioral profiles will be re-presented with the newly documented classification rules and the added statistical tests; we believe the profiles remain informative once the classification step is transparent, but we accept that they currently rest on an incompletely described procedure. revision: partial
Circularity Check
Empirical comparison with no derivation chain or self-referential predictions
full rationale
The paper reports results from a controlled 2x2 factorial experiment measuring equilibrium attainment rates across models, persona conditions, and payoff visibility in 53 scenarios. No equations, fitted parameters, first-principles derivations, or predictions are claimed; outcomes are direct counts from generated text. The central claim is an observed empirical shift, not a reduction of any quantity to its own inputs. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents respond consistently to short role-based persona descriptions across the tested models
- domain assumption The 53 environmental policy scenarios correctly instantiate Tragedy of the Commons and Green Transition payoff structures
Forward citations
Cited by 1 Pith paper
-
When Reasoning Models Hurt Behavioral Simulation: A Solver-Sampler Mismatch in Multi-Agent LLM Negotiation
Stronger reasoning models in LLMs reduce behavioral negotiation by defaulting to authority outcomes in multi-agent settings, unlike structured scaffolds that enable concessions.
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Schönherr, and Mario Fritz. 2024. LLM-Deliberation: Evaluating Large Language Models with Inter- active Multi-Agent Negotiation Games.International Conference on Learning Representations(2024)
work page 2024
- [2]
-
[3]
Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai. 2023. Using large language models to simulate multiple humans and replicate human subject studies. In International conference on machine learning. PMLR, 337–371
work page 2023
-
[4]
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. 2025. Playing repeated games with large language models.Nature Human Behaviour9, 7 (May 2025), 1380–1390. doi:10.1038/s41562-025-02172-y
-
[5]
Scott Barrett. 2003.Environment and statecraft: The strategy of environmental treaty-making: The strategy of environmental treaty-making. OUP Oxford
work page 2003
-
[6]
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big?. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency. 610–623
work page 2021
- [7]
-
[8]
Eric Bonabeau. 2002. Agent-based modeling: Methods and techniques for simu- lating human systems.Proceedings of the national academy of sciences99, suppl_3 (2002), 7280–7287
work page 2002
-
[9]
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, Jérémy Scheurer, Marius Hobbhahn, et al. 2024. Black-box access is insufficient for rigorous ai audits. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Trans- parency. 2254–2272
work page 2024
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. 2021. Training Verifiers to Solve Math Word Problems.Neural Information Processing Systems(2021)
work page 2021
-
[11]
Antonia Creswell and Murray Shanahan. 2023. Faithful Reasoning Using Large Language Models.Neural Information Processing Systems(2023)
work page 2023
-
[12]
Andrés Domínguez Hernández, Shyam Krishna, Antonella Maia Perini, Michael Katell, SJ Bennett, Ann Borda, Youmna Hashem, Semeli Hadjiloizou, Sabeehah Mahomed, Smera Jayadeva, et al. 2024. Mapping the individual, social and bio- spheric impacts of Foundation Models. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 776–796
work page 2024
-
[13]
Jinhao Duan, Shiqi Wang, James Diffenderfer, Lichao Sun, Tianlong Chen, Bhavya Kailkhura, and Kaidi Xu. 2024. ReTA: Recursively Thinking Ahead to Improve the Strategic Reasoning of Large Language Models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
-
[14]
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. 2024. Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evalua- tions.Advances in Neural Information Processing Systems37 (2024), 28219–28253
work page 2024
-
[15]
1996.Growing artificial societies: social science from the bottom up
Joshua M Epstein and Robert Axtell. 1996.Growing artificial societies: social science from the bottom up. Brookings Institution Press
work page 1996
- [16]
-
[17]
Algorithmic Collusion by Large Language Models
Sara Fish, Yannai A. Gonczarowski, and Ran I. Shorrer. 2025. Algorithmic Collusion by Large Language Models. arXiv:2404.00806 [econ.GN] https: //arxiv.org/abs/2404.00806
-
[18]
Nicoló Fontana, Francesco Pierri, and Luca Maria Aiello. 2025. Nicer Than Humans: How Do Large Language Models Behave in the Prisoner’s Dilemma?. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 19. 522–535
work page 2025
- [19]
-
[20]
Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, and Yong Li. 2024. Large language models empowered agent-based modeling and simulation: A survey and perspectives.Humanities and Social Sciences Communications11, 1 (2024), 1–24
work page 2024
-
[21]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large Language Model based Multi-Agents: A Survey of Progress and Challenges. arXiv:2402.01680 [cs.CL] https://arxiv.org/abs/2402.01680
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Garrett Hardin. 1968. The Tragedy of the Commons.Science162, 3859 (1968), 1243–1248. arXiv:https://www.science.org/doi/pdf/10.1126/science.162.3859.1243 doi:10.1126/science.162.3859.1243
-
[24]
Nathan Herr, Fernando Acero, Roberta Raileanu, María Pérez-Ortiz, and Zhibin Li
-
[25]
arXiv:2407.04467 [cs.AI] https://arxiv.org/abs/2407.04467
Are Large Language Models Strategic Decision Makers? A Study of Perfor- mance and Bias in Two-Player Non-Zero-Sum Games. arXiv:2407.04467 [cs.AI] https://arxiv.org/abs/2407.04467
-
[26]
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander van der Linden, and Jon Roozenbeek. 2025. Generative language models exhibit social identity biases.Nature Computational Science5, 1 (2025), 65–75
work page 2025
-
[27]
Jingru Jia, Zehua Yuan, Junhao Pan, Paul E. McNamara, and Deming Chen
-
[28]
arXiv:2502.20432 [cs.AI] https://arxiv.org/abs/2502.20432
LLM Strategic Reasoning: Agentic Study through Behavioral Game Theory. arXiv:2502.20432 [cs.AI] https://arxiv.org/abs/2502.20432
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Nian Li, Chen Gao, Mingyu Li, Yong Li, and Qingmin Liao. 2024. Econagent: large language model-empowered agents for simulating macroeconomic activities. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 15523–15536
work page 2024
-
[31]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing. 17889–17904
work page 2024
-
[32]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. 2023. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Nunzio Lorè and Babak Heydari. 2024. Strategic behavior of large language models and the role of game structure versus contextual framing.Scientific Reports14, 1 (2024), 18490
work page 2024
-
[34]
Olivia Macmillan-Scott and Mirco Musolesi. 2024. (Ir)rationality and cognitive biases in large language models.Royal Society Open Science11 (2024). https: //api.semanticscholar.org/CorpusID:267658066
work page 2024
-
[35]
Yaaseen Mahomed, Charlie M Crawford, Sanjana Gautam, Sorelle A Friedler, and Danaë Metaxa. 2024. Auditing GPT’s Content Moderation Guardrails: Can Chat- GPT Write Your Favorite TV Show?. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 660–686
work page 2024
- [36]
-
[37]
John Nash. 1951. Non-Cooperative Games.Annals of Mathematics54, 2 (1951), 286–295
work page 1951
-
[40]
Anna Neumann, Elisabeth Kirsten, Muhammad Bilal Zafar, and Jatinder Singh
-
[41]
InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
Position is Power: System Prompts as a Mechanism of Bias in Large Language Models (LLMs). InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 573–598
work page 2025
-
[42]
1990.Governing the commons: The evolution of institutions for collective action
Elinor Ostrom. 1990.Governing the commons: The evolution of institutions for collective action. Cambridge university press
work page 1990
-
[43]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
work page 2023
-
[44]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2022. Social simulacra: Creating populated prototypes for social computing systems. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–18. 10 When Identity Overrides Incentives: Representational Choices as Go...
work page 2022
-
[45]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
Like rearranging deck chairs on the Titanic
Gisela Reyes-Cruz, Peter Craigon, Anna-Maria Piskopani, Liz Dowthwaite, Yang Lu, Justyna Lisinska, Elnaz Shafipour, Sebastian Stein, and Joel Fischer. 2024. " Like rearranging deck chairs on the Titanic"? Feasibility, fairness, and ethical concerns of a citizen carbon budget for reducing CO2 emissions. InProceedings of the 2024 ACM Conference on Fairness,...
work page 2024
- [48]
-
[49]
2002.Transboundary environmental negotiation: new approaches to global cooperation
Lawrence Susskind, William Moomaw, and Kevin Gallagher. 2002.Transboundary environmental negotiation: new approaches to global cooperation. John Wiley & Sons
work page 2002
-
[50]
1999.The consensus building handbook: A comprehensive guide to reaching agreement
Lawrence E Susskind, Sarah McKearnen, and Jennifer Thomas-Lamar. 1999.The consensus building handbook: A comprehensive guide to reaching agreement. Sage publications
work page 1999
-
[51]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. 2025. Multi-Agent Collaboration Mechanisms: A Survey of LLMs. arXiv:2501.06322 [cs.AI] https://arxiv.org/abs/2501.06322
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Jen tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, and Michael R. Lyu. 2025. How Far Are We on the Decision-Making of LLMs? Evaluating LLMs’ Gaming Ability in Multi-Agent Environments. arXiv:2403.11807 [cs.AI] https://arxiv.org/abs/ 2403.11807
-
[53]
Alexander Sasha Vezhnevets, John P Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A Duéñez-Guzmán, William A Cunningham, Simon Osindero, Danny Karmon, and Joel Z Leibo. 2023. Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia.arXiv preprint arXiv:2312.03664(2023)
-
[54]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
work page 2022
-
[55]
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al
-
[56]
InProceedings of the 2022 ACM conference on fairness, accountability, and transparency
Taxonomy of risks posed by language models. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency. 214–229
work page 2022
-
[57]
Lin Xu, Zhiyuan Hu, Daquan Zhou, Hongyu Ren, Zhen Dong, Kurt Keutzer, See Kiong Ng, and Jiashi Feng. 2024. Magic: Investigation of large language model powered multi-agent in cognition, adaptability, rationality and collaboration. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 7315–7332
work page 2024
-
[58]
Lin Xu, Zhiyuan Hu, Daquan Zhou, Hongyu Ren, Zhen Dong, Kurt Keutzer, See Kiong Ng, and Jiashi Feng. 2024. MAgIC: Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collabo- ration. arXiv:2311.08562 [cs.CL] https://arxiv.org/abs/2311.08562
- [59]
-
[60]
Kehan Zheng, Jinfeng Zhou, and Hongning Wang. 2025. Beyond Nash Equilib- rium: Bounded Rationality of LLMs and humans in Strategic Decision-making. arXiv:2506.09390 [cs.AI] https://arxiv.org/abs/2506.09390 11 Manoranjan and Gaikwad APPENDIX This appendix contains detailed technical specifications, methodol- ogy, experimental setup, and results that suppor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.