HybridCodec: Fast Dual-Stream, Semantically Enhanced Neural Audio Codec
Pith reviewed 2026-06-27 23:25 UTC · model grok-4.3
The pith
HybridCodec combines separate semantic and acoustic branches with SSL distillation to deliver disentanglement in neural audio codecs without needing an SSL model at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HybridCodec employs separate semantic and acoustic branches while distilling SSL representations into the semantic stream. This unified design ensures strong disentanglement without requiring an SSL model during inference, resulting in superior semantic specialization on RVQ-1 for in-domain test sets, competitive reconstruction on RVQ-all, robustness in out-of-domain and zero-shot cross-lingual settings, and a 3x speedup over existing dual-stream models.
What carries the argument
The hybrid architecture of separate semantic and acoustic branches combined with SSL distillation applied only to the semantic stream.
If this is right
- Semantic specialization on the first RVQ layer improves without harming overall reconstruction quality across all layers.
- The model maintains performance advantages in out-of-domain and zero-shot cross-lingual conditions.
- Inference runs three times faster than prior dual-stream codecs while preserving the disentanglement benefit.
- The codec can serve directly as a tokenizer for multimodal large language models without extra SSL overhead during deployment.
Where Pith is reading between the lines
- Training-time distillation might allow the semantic branch to learn representations that remain useful even if future SSL models improve.
- The speedup could enable real-time applications that previously required heavier dual-stream designs.
- The pattern of separate branches plus targeted distillation may extend to other sequence modalities where semantic and low-level features need separation.
Load-bearing premise
The premise that distilling SSL information into a dedicated semantic branch will create disentanglement strong enough to survive removal of the SSL model at inference time.
What would settle it
An ablation experiment that trains the same architecture with and without the SSL distillation step, then measures whether the RVQ-1 semantic specialization advantage disappears on the in-domain test set.
Figures
read the original abstract
The popularity of neural audio codecs as speech tokenizers has surged with the advent of Multimodal Large Language Models. New codec architectures with semantic and acoustic disentanglement have emerged. There are two main approaches to introduce semantic information into codec models: one distills semantic information from SSL representations into the first RVQ layer, while the other maintains separate streams for semantic and acoustic features. We propose HybridCodec, a unified architecture that combines both paradigms. It employs separate semantic and acoustic branches while distilling SSL representations into the semantic stream. This design ensures strong disentanglement without requiring an SSL model during inference. HybridCodec shows superior semantic specialization (RVQ-1) on in-domain test set and competitive reconstruction (RVQ-all). We demonstrate its robustness in out-of-domain and zero-shot cross-lingual settings, achieving a 3x speedup over existing dual-stream models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HybridCodec, a hybrid neural audio codec that unifies two paradigms: separate semantic and acoustic branches plus training-time distillation of SSL representations into the semantic stream. The design is intended to deliver strong semantic-acoustic disentanglement at inference without an SSL model. Claims include superior RVQ-1 semantic specialization on in-domain data, competitive RVQ-all reconstruction, robustness under out-of-domain and zero-shot cross-lingual conditions, and a 3x speedup relative to prior dual-stream codecs.
Significance. If the empirical claims are substantiated, the hybrid architecture could provide a practical route to efficient, disentangled audio tokenization for multimodal LLMs, combining the strengths of distillation and dual-stream designs while removing the inference-time SSL dependency.
major comments (2)
- [Abstract] Abstract: the performance claims (RVQ-1 specialization, RVQ-all reconstruction, robustness, 3x speedup) are stated without any quantitative results, error bars, dataset descriptions, ablation studies, or baseline comparisons, preventing assessment of whether the hybrid design actually delivers the reported gains.
- [Abstract] Abstract: no information is given on training objectives, loss weighting between branches, distillation targets, or how the semantic stream is prevented from leaking acoustic information, leaving the central disentanglement claim unsupported by visible evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract can be strengthened by incorporating key quantitative results and a concise description of the training approach to better substantiate the claims. We will revise the abstract accordingly while keeping it concise.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (RVQ-1 specialization, RVQ-all reconstruction, robustness, 3x speedup) are stated without any quantitative results, error bars, dataset descriptions, ablation studies, or baseline comparisons, preventing assessment of whether the hybrid design actually delivers the reported gains.
Authors: We agree that the abstract would benefit from including specific quantitative highlights to make the claims more concrete. In the revised manuscript, we will update the abstract to report key metrics from the experiments (e.g., RVQ-1 semantic specialization scores, RVQ-all reconstruction quality, out-of-domain robustness results, and the measured inference speedup relative to prior dual-stream codecs), along with brief references to the evaluation datasets and main baselines. Full details including error bars, ablations, and dataset descriptions remain in the experimental sections. This revision will allow readers to assess the gains more directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract: no information is given on training objectives, loss weighting between branches, distillation targets, or how the semantic stream is prevented from leaking acoustic information, leaving the central disentanglement claim unsupported by visible evidence.
Authors: The abstract is intentionally high-level, with full methodological details (training objectives, loss terms and weighting, distillation targets from SSL models, and the architectural mechanisms such as separate semantic/acoustic branches plus targeted distillation that limit acoustic leakage) provided in the Methods and Training sections. However, we acknowledge the referee's point that a brief indication of the approach would strengthen the abstract. We will add one sentence summarizing the dual-branch design combined with SSL distillation into the semantic stream, which enables disentanglement at inference without an SSL model. This provides visible support for the claim without expanding the abstract excessively. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper describes an architectural design (separate semantic and acoustic branches plus training-time SSL distillation) whose claimed benefits—disentanglement at inference, RVQ-1 specialization, RVQ-all reconstruction, robustness, and speedup—are presented as empirical consequences of that design. No equations, first-principles derivations, or predictions appear in the supplied text that reduce to fitted parameters or self-referential definitions by construction. Standard evaluation metrics are used without evidence that any reported result is forced by the inputs. This is a conventional empirical ML architecture paper whose central claims remain independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction With the rapid adoption of Multimodal Large Language Mod- els (MLLMs), speech discretization has emerged as a key com- ponent for enabling unified modeling across speech and text modalities. Prior works [1, 2, 3] show that the separation of semantic and acoustic information is crucial; semantic tokens represent linguistic content, while acous...
-
[2]
In the dual-stream framework, the model consists of a se- mantic stream and an acoustic stream
and dual-stream codecs (e.g., DualCodec) [4]. In the dual-stream framework, the model consists of a se- mantic stream and an acoustic stream. The semantic stream pro- cesses representations extracted from a self-supervised learning (SSL) model (e.g., w2v-BERT-2.0) [5] using an autoencoder with a vector quantization (VQ) bottleneck, producing quan- tized s...
-
[3]
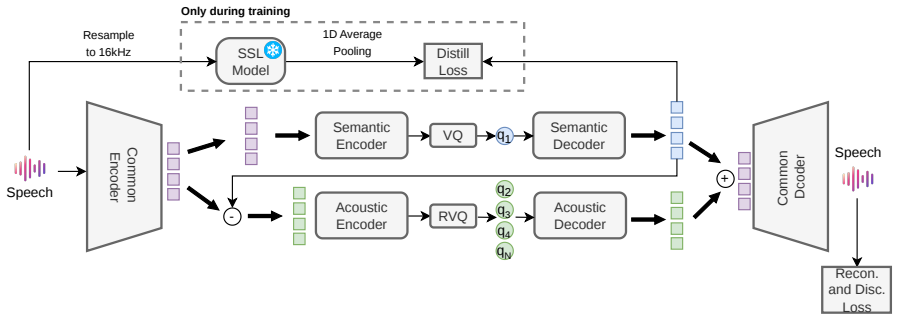
Each branch consists of stream specific encoders and decoders
Methodology As shown in figure 1, we have latents from a common en- coder going into two streams - semantic and acoustic streams. Each branch consists of stream specific encoders and decoders. The latents from both the branches are combined and sent to the common decoder which gives out final audio. The output of the semantic decoder distills semantically...
Pith/arXiv arXiv 2026
-
[4]
During train- Table 2:Results at 60k updates
Experimental Setup We train all models on the full 960-hour LibriSpeech corpus [8], resampling all audio waveforms to 24kHz. During train- Table 2:Results at 60k updates. All models are trainedfrom scratchon LibriSpeech (24kHz) and have 1 semantic codebook of size 16,384 and 11 acoustic codebooks of size 1024. Model WER↓ SSIM↑UTMOS↑PESQ↑RVQ-1 RVQ-1:2 RVQ-...
-
[5]
Results and Discussion Table 2 summarizes the performance of all models at 60k up- dates across in-domain (LibriSpeech Test) and out-of-domain (SeedTTS-en, CV-French) datasets. In-Domain Performance:On Test Clean, HC-SED-AED achieves the lowest RVQ-1 WER (15.36%), outperforming both DualCodec (18.93%) and DAC (Distill) (21.54%), indicating stronger semant...
-
[6]
By utilizing a dual-stream architecture with SSL distillation, HybridCodec eliminates the need for heavy- weight SSL encoders at inference
Conclusion We presented HybridCodec, a dual-stream neural audio codec that bridges the gap between semantic disentanglement and in- ference efficiency. By utilizing a dual-stream architecture with SSL distillation, HybridCodec eliminates the need for heavy- weight SSL encoders at inference. We show that HybridCodec achieves superior semantic specializatio...
-
[7]
All scientific content, experimen- tal design, and conclusions are solely the work of the authors
Generative AI Use Disclosure We used ChatGPT 5.2 and Gemini 3 for minor language editing and phrasing improvements. All scientific content, experimen- tal design, and conclusions are solely the work of the authors
-
[8]
SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models,” inThe Twelfth International Confer- ence on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=AF9Q8Vip84
2024
-
[9]
Codec does matter: exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liu, Y . Guo, and W. Xue, “Codec does matter: exploring the semantic shortcoming of codec for audio language model,” inProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and...
-
[10]
Moshi: a speech- text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech- text foundation model for real-time dialogue,” 2024. [Online]. Available: https://arxiv.org/abs/2410.00037
Pith/arXiv arXiv 2024
-
[11]
DualCodec: A Low-Frame-Rate, Semantically-Enhanced Neural Audio Codec for Speech Generation,
J. Li, X. Lin, Z. Li, S. Huang, Y . Wang, C. Wang, Z. Zhan, and Z. Wu, “DualCodec: A Low-Frame-Rate, Semantically-Enhanced Neural Audio Codec for Speech Generation,” inInterspeech 2025, 2025, pp. 4883–4887
2025
-
[12]
Seamless: Multilingual Expressive and Streaming Speech Translation,
S. Communication, L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haaheim, J. Hoffman, M.-J. Hwang, H. Inaguma, C. Klaiber, I. Kulikov, P. Li, D. Licht, J. Maillard, R. Mavlyutov, A. Rakotoarison, K. R. Sadagopan, A. Ramakrishnan, T. Tran, G. Wenzek, Y . Yang, E. Ye, I. Evtimov, P. Fer...
-
[13]
Available: https://arxiv.org/abs/2312.05187
[Online]. Available: https://arxiv.org/abs/2312.05187
-
[14]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” in Proceedings of the 37th International Conference on Neural In- formation Processing Systems, 2023
2023
-
[15]
A ConvNet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A ConvNet for the 2020s,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 11 976–11 986
2022
-
[16]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[17]
Seed- TTS: A Family of High-Quality Versatile Speech Generation Models,
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gao, M. Gong, P. Huang, Q. Huang, Z. Huang, Y . Huo, D. Jia, C. Li, F. Li, H. Li, J. Li, X. Li, X. Li, L. Liu, S. Liu, S. Liu, X. Liu, Y . Liu, Z. Liu, L. Lu, J. Pan, X. Wang, Y . Wang, Y . Wang, Z. Wei, J. Wu, C. Yao, Y . Yang, Y .-Q.-Q. Yi, J. Zhang, Q. Zhang, S....
Pith/arXiv arXiv 2024
-
[18]
Common V oice: A Massively-Multilingual Speech Corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common V oice: A Massively-Multilingual Speech Corpus,” in Proc. Language Resources and Evaluation (LREC ), 2020, pp. 4211–4215
2020
-
[19]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. International Conference on Machine Learn- ing (ICML), 2023, pp. 28 492–28 518
2023
-
[20]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[21]
Perceptual eval- uation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,
A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual eval- uation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in2001 IEEE In- ternational Conference on Acoustics, Speech, and Signal Process- ing. Proceedings (Cat. No.01CH37221), vol. 2, 2001, pp. 749– 752 vol.2
2001
-
[22]
Ecapa-tdnn embeddings for speaker diarization,
Nauman Dawalatabad and Mirco Ravanelli and Franc ¸ois Grondin and Jenthe Thienpondt and Brecht Desplanques and Hwidong Na, “Ecapa-tdnn embeddings for speaker diarization,” in Interspeech 2021, ser. interspeech 2021. ISCA, Aug. 2021, pp. 3560–3564. [Online]. Available: http://dx.doi.org/10.21437/ Interspeech.2021-941
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.