TurtleAI: Benchmarking Multimodal Models for Visual Programming in Turtle Graphics
Pith reviewed 2026-06-28 10:25 UTC · model grok-4.3
The pith
Vision-language models achieve below 30 percent success on TurtleAI tasks that require seeing geometric patterns and writing Python code to reproduce them exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
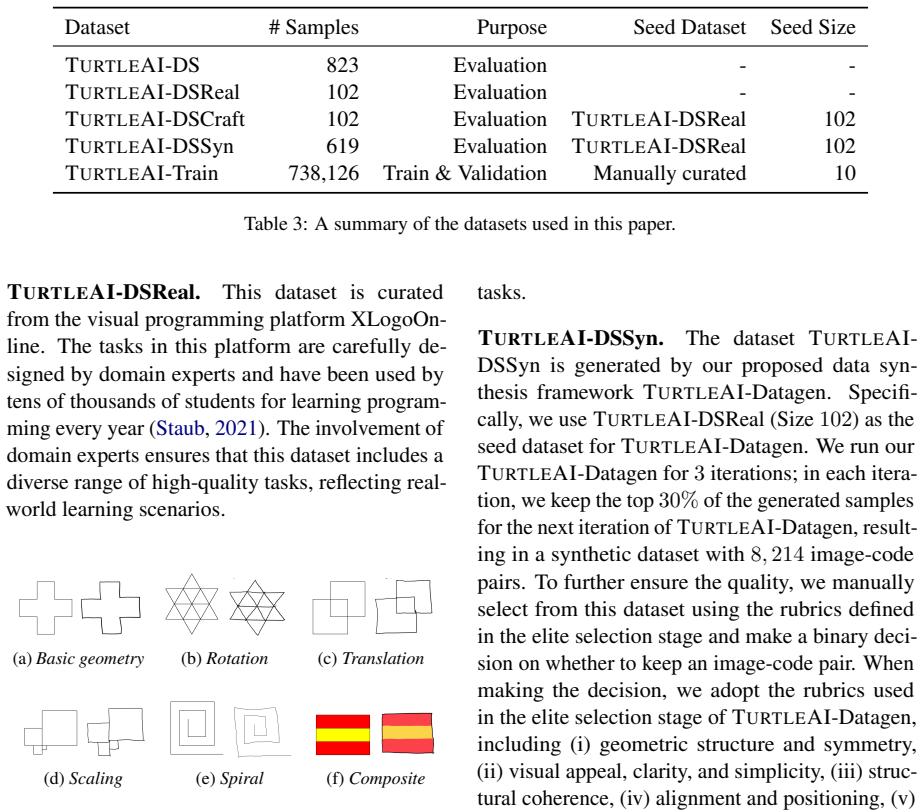
TurtleAI shows that current vision-language models perform poorly when required to combine visual perception of geometric patterns, spatial reasoning, and exact Python code synthesis for education-oriented visual programming, with most models succeeding on fewer than 30 percent of the 823 tasks; fine-tuning on synthetic data created from a small set of seed samples improves performance by about 20 percent, chiefly by strengthening the connection between visual reasoning steps and the resulting code.
What carries the argument
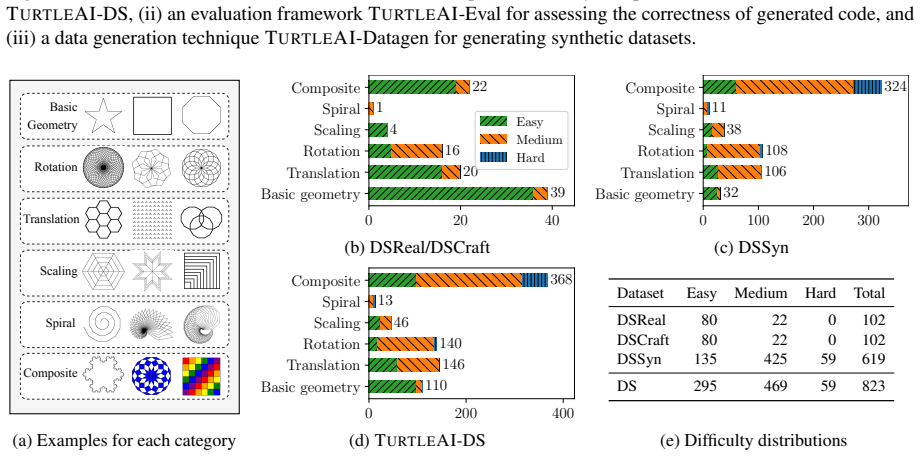
The TurtleAI benchmark of 823 tasks that each demand perception of a geometric pattern, spatial reasoning about its properties, and synthesis of Turtle Python code that reproduces the pattern exactly.
If this is right
- Models that improve spatial reasoning and precise visual replication will be needed before vision-language systems can reliably support visual programming exercises.
- Synthetic data generated from a small number of seed examples can raise accuracy on real tasks without requiring large human-labeled datasets.
- Fine-tuning primarily helps by aligning the model's visual analysis with the code it generates rather than by adding new reasoning abilities.
- GPT-4o and similar base models fail most often on spatial relationships and exact replication, while the tuned model reduces those specific mismatches.
Where Pith is reading between the lines
- Improved results on TurtleAI tasks could enable automated tutors that check student code against visual goals in graphics-based programming courses.
- The seed-based data generation approach may apply to other visual-to-code domains where only limited real examples exist.
- Persistent gaps in spatial reasoning point to a possible need for model architectures that keep visual and symbolic representations more tightly coupled throughout generation.
Load-bearing premise
The 823 tasks represent the main perceptual, spatial-reasoning, and code-synthesis difficulties that appear in actual visual programming education.
What would settle it
An experiment that evaluates the same models on a fresh collection of Turtle Graphics tasks drawn independently from classroom materials and records success rates above 50 percent for most models would undermine the reported performance gap.
Figures












read the original abstract
Vision-language models (VLMs) have been explored for visual programming, where they generate code to solve visual tasks. However, most prior work focuses on visual programming for productivity; it remains unclear how well current VLMs perform on education-oriented visual programming and what factors limit their performance. To bridge this gap, we introduce TurtleAI, a benchmark containing 823 tasks curated based on real-world visual programming tasks in the Turtle Graphics domain. Solving these tasks requires models to perceive geometric patterns, reason about spatial relationships, and synthesize Python code that faithfully reproduces geometric patterns. We evaluate 20+ VLMs, including GPT-5, GPT-4o, and Qwen2-VL-72B, and find that they struggle significantly, with most achieving success rates below 30%. To address these limitations, we propose a data generation technique that requires only a small set of seed samples. Fine-tuning Qwen2-VL-72B on the resulting synthetic data yields an improvement of about 20% on real-world tasks. Our failure analysis reveals that GPT-4o struggles with spatial reasoning and precise visual replication, whereas fine-tuning primarily improves the alignment between visual reasoning and code implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TurtleAI, a benchmark of 823 tasks in the Turtle Graphics domain curated from real-world visual programming tasks. It evaluates 20+ VLMs (including GPT-4o, GPT-5, Qwen2-VL-72B) and reports that most achieve success rates below 30% on tasks requiring geometric pattern perception, spatial reasoning, and Python code synthesis. The paper further claims that a data-generation technique using only a small set of seed samples enables fine-tuning of Qwen2-VL-72B to yield an approximately 20% improvement on real-world tasks, supported by failure analysis attributing GPT-4o issues to spatial reasoning and post-fine-tuning gains to better visual-code alignment.
Significance. If the central claims hold, the work supplies a new benchmark focused on education-oriented visual programming and demonstrates an efficient synthetic-data approach for improving VLM performance in code synthesis; the scale of the model evaluation (20+ VLMs) and the seed-based data generation method are concrete strengths that could guide future multimodal code-generation research.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: the reported success rates below 30% and ~20% improvement from fine-tuning are stated without error bars, without a precise definition of the success metric (e.g., code execution match, visual output similarity threshold), and without any description of the data-generation algorithm; these omissions directly affect the reliability of the primary empirical claims.
- [Benchmark construction (likely §3)] Benchmark construction (likely §3): the 823 tasks are described only as 'curated based on real-world visual programming tasks' with no selection protocol, complexity distribution, coverage of standard Turtle/Logo curricula patterns, or external validation (expert review, inter-rater agreement, or comparison to existing corpora); this is load-bearing because the claims about VLM limitations and the value of the observed improvement rest on the benchmark's representativeness.
minor comments (1)
- [Failure analysis] Failure analysis paragraph: the qualitative distinction between GPT-4o spatial-reasoning failures and post-fine-tuning alignment improvements would benefit from at least one concrete example per category or a quantitative breakdown of error types.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the reported success rates below 30% and ~20% improvement from fine-tuning are stated without error bars, without a precise definition of the success metric (e.g., code execution match, visual output similarity threshold), and without any description of the data-generation algorithm; these omissions directly affect the reliability of the primary empirical claims.
Authors: We agree that error bars, a precise success metric definition, and a description of the data-generation algorithm are necessary for reliability. In the revised version we will add error bars from repeated evaluations, explicitly define success as exact code execution match to the target visual output, and provide a detailed description of the seed-based synthetic data generation algorithm in the Evaluation section. revision: yes
-
Referee: [Benchmark construction (likely §3)] Benchmark construction (likely §3): the 823 tasks are described only as 'curated based on real-world visual programming tasks' with no selection protocol, complexity distribution, coverage of standard Turtle/Logo curricula patterns, or external validation (expert review, inter-rater agreement, or comparison to existing corpora); this is load-bearing because the claims about VLM limitations and the value of the observed improvement rest on the benchmark's representativeness.
Authors: We acknowledge that additional details on benchmark construction are required to substantiate representativeness. The revised manuscript will expand the benchmark section to include the task selection protocol, complexity distribution statistics, coverage of standard Turtle/Logo curricula patterns, and any external validation steps such as expert review or corpus comparisons. revision: yes
Circularity Check
No circularity: empirical benchmark and fine-tuning results are self-contained
full rationale
The paper introduces TurtleAI as a benchmark of 823 tasks and reports direct experimental success rates for 20+ VLMs plus a fine-tuning improvement on Qwen2-VL-72B. No equations, fitted parameters, or predictions appear that reduce by construction to inputs; no self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work consists of curation, evaluation, and data-generation experiments whose claims rest on observable outcomes rather than definitional loops or renamed fits, satisfying the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 823 tasks are representative of real-world Turtle Graphics educational tasks.
Reference graph
Works this paper leans on
-
[1]
NVLM: Open Frontier-Class Multimodal LLMs.CoRR, abs/2409.11402. Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, Yen-Sung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, and 32 others
-
[2]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models.CoRR, abs/2409.17146. Kevin Ellis, Catherine Wong, Maxwell I. Nye, Mathias Sablé-Meyer, Lucas Morales, Luke B. Hewitt, Luc Cary, Armando Solar-Lezama, and Joshua B. Tenen- baum. 2021. DreamCoder: bootstrapping inductive program synthesis with wake-sleep library learning. In...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
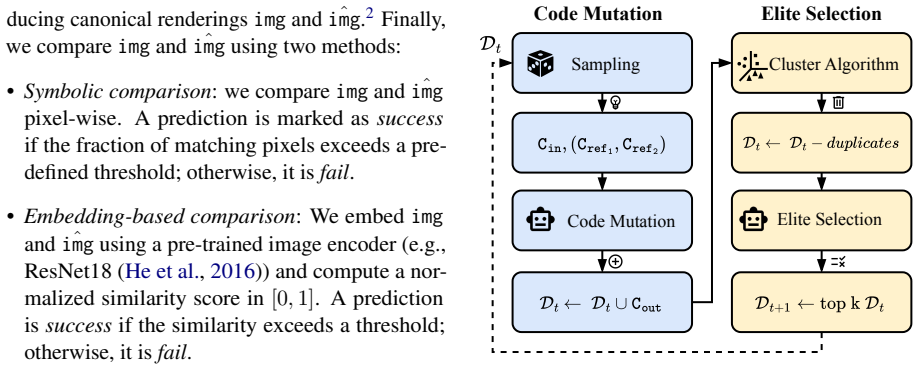
During code mutation, we ran- domly sample 16 pairs of (Cref1,C ref2) from the seed dataset for each input code Cin
We use a higher temperature and top_p values to encourage the model to generate more diverse and creative code. During code mutation, we ran- domly sample 16 pairs of (Cref1,C ref2) from the seed dataset for each input code Cin. This results in 16 possible mutated codes for Cin after applying the mutation for each pair of (Cref1,C ref2). An il- lustrative...
2016
-
[4]
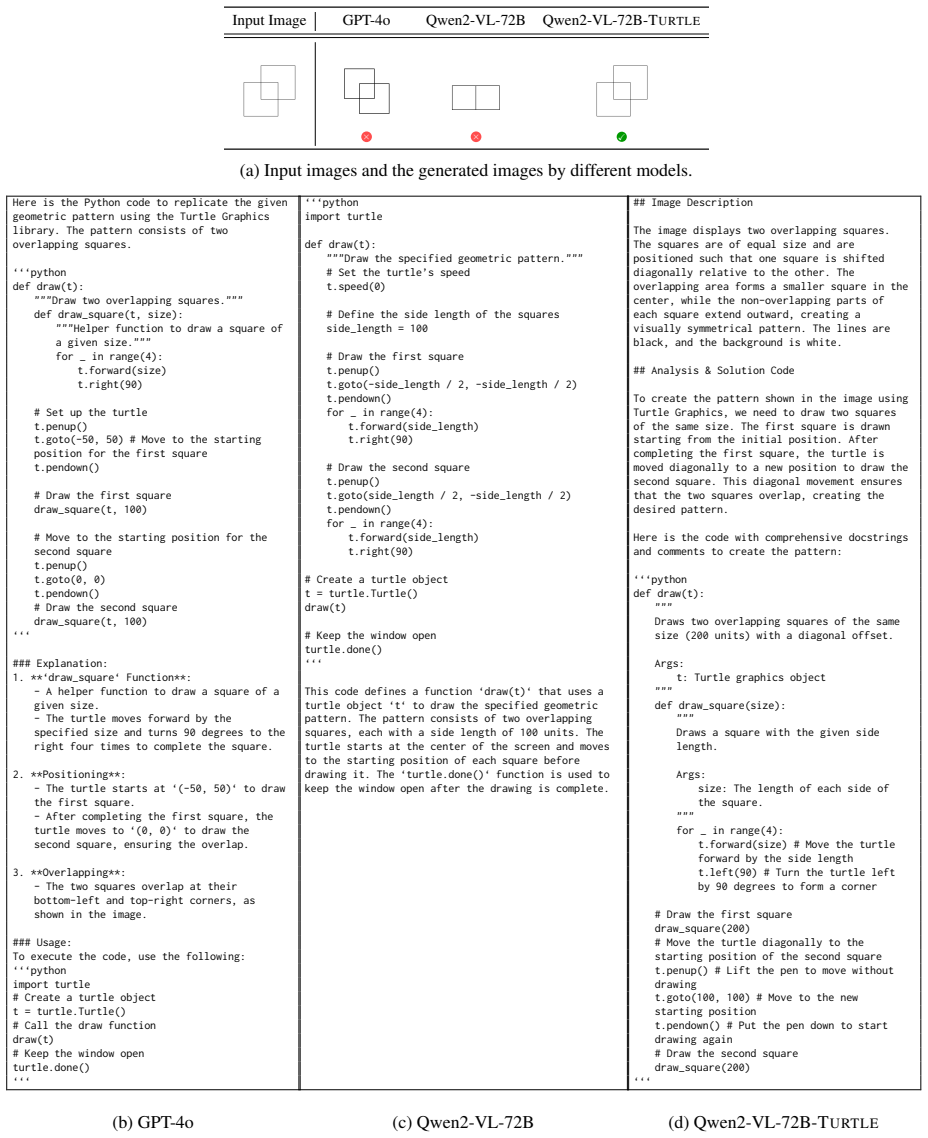
""Draw two overlapping squares
We use the OpenAI API to evaluate propri- etary models from OpenAI. For reasoning mod- els, we set reasoning_effort to medium and max_completion_tokensto 8192. Details of the evaluation procedure.For each task in our evaluation datasets, we provide the task image along with a fixed prompt template (see Fig- ure 15) to guide the VLMs in generating Turtle G...
2025
-
[5]
- The turtle moves forward by the specified size and turns 90 degrees to the right four times to complete the square
**‘draw_square‘ Function**: - A helper function to draw a square of a given size. - The turtle moves forward by the specified size and turns 90 degrees to the right four times to complete the square
-
[6]
- After completing the first square, the turtle moves to ‘(0, 0)‘ to draw the second square, ensuring the overlap
**Positioning**: - The turtle starts at ‘(-50, 50)‘ to draw the first square. - After completing the first square, the turtle moves to ‘(0, 0)‘ to draw the second square, ensuring the overlap
-
[7]
""Draw the specified geometric pattern
**Overlapping**: - The two squares overlap at their bottom-left and top-right corners, as shown in the image. ### Usage: To execute the code, use the following: ‘‘‘python import turtle # Create a turtle object t = turtle.Turtle() # Call the draw function draw(t) # Keep the window open turtle.done() ‘‘‘ (b) GPT-4o ‘‘‘python import turtle def draw(t): """Dr...
-
[8]
**Set Up the Turtle**: Initialize the turtle graphics and set the fill color to blue
-
[9]
A dodecagon has 12 sides, and each internal angle is 150 degrees (calculated as \( \frac{180 \times (12-2)}{12} \))
**Define the Dodecagon**: Create a function to draw a single dodecagon. A dodecagon has 12 sides, and each internal angle is 150 degrees (calculated as \( \frac{180 \times (12-2)}{12} \))
-
[10]
This rotation ensures the symmetrical arrangement of the dodecagons
**Draw the Pattern**: Use a loop to draw 12 dodecagons, each rotated by 30 degrees (360 degrees / 12) relative to the previous one. This rotation ensures the symmetrical arrangement of the dodecagons
-
[11]
"" t.fillcolor(’blue’) # Set the fill color to blue def draw_dodecagon():
**Fill the Shape**: Use the ‘begin_fill‘ and ‘end_fill‘ methods to fill the dodecagons with the specified color. Here is the code with comprehensive docstrings and comments to create the pattern: ‘‘‘python def draw(t): """ Draws a symmetrical, flower-like pattern composed of 12 blue-filled dodecagons. Each dodecagon is rotated by 30 degrees relative to th...
-
[12]
Syntactic Correctness: - The adapted code must besyntactically correctand free of errors
-
[13]
- Ensure that no unintended behavior is introduced by the adaptation
Structural and Logical Consistency: - Maintain thestructural integrityandlogical flowof the original code. - Ensure that no unintended behavior is introduced by the adaptation
-
[14]
Geometric Structure & Symmetry (if applicable): - Ensure that all drawings consist ofclear geometric shapeswithsymmetryandgeometric accuracy
-
[15]
- Avoid overly complex designs that may confuse or clutter the output
Visual Clarity & Simplicity: - The output should bevisually clearandsimple. - Avoid overly complex designs that may confuse or clutter the output
-
[16]
- Use appropriate Turtle Graphics library commands within the`draw(t)`function
Function and Code Requirements: - Define the function`draw(t)`that contains all the drawing code. - Use appropriate Turtle Graphics library commands within the`draw(t)`function. - Only provide the`draw(t)`function.Do not include import statementsor other code outside of the`draw()`function
-
[17]
- The drawing must be a different shape or have a distinct pattern to clearly show the adaptation's impact
Different Output: - Theadapted code must generate a different drawingcompared to the original new code. - The drawing must be a different shape or have a distinct pattern to clearly show the adaptation's impact. ### Your Task: Reference Code 1: ```python {reference_code_1} ``` Reference Code 2: ```python {reference_code_2} ``` New Code to Adapt: ```python...
-
[18]
- Summarize the adaptation in ahigh-level waythat can be applied to other codes
Analyze the Adaptation: - Examine howReference Code 1is adapted intoReference Code 2. - Summarize the adaptation in ahigh-level waythat can be applied to other codes
-
[19]
geometry
Apply the Adaptation: - Apply the core idea of the adaptation to theNew Code to Adapt. - Provide theAdapted Codethat reflects this adaptation. - Ensure the adapted code issyntactically correctand that the resulting drawing after execution meets all the specified requirements (geometric structure, symmetry, visual clarity, simplicity, etc.). Adapted Code: ...
-
[20]
A Python code snippet using Turtle Graphics
-
[21]
"" [Function description] Args: t: Turtle graphics object
The actual image output generated by this code. ## Your Responsibilities: 1.Describe the Image - Provide a detailed description of the visual pattern in the imagewithout referencing the code, focusing on geometric shapes, symmetry, colors, and overall structure. 2.Optimize the Code - Identify and remove redundant code segments that do not contribute to th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.