Disentangling Adversarial Prompts: A Semantic-Graph Defense for Robust LLM Security
Pith reviewed 2026-06-29 12:06 UTC · model grok-4.3
The pith
The APD framework disentangles adversarial prompts with mutual information and graph analysis to cut harmful LLM outputs by over 85 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
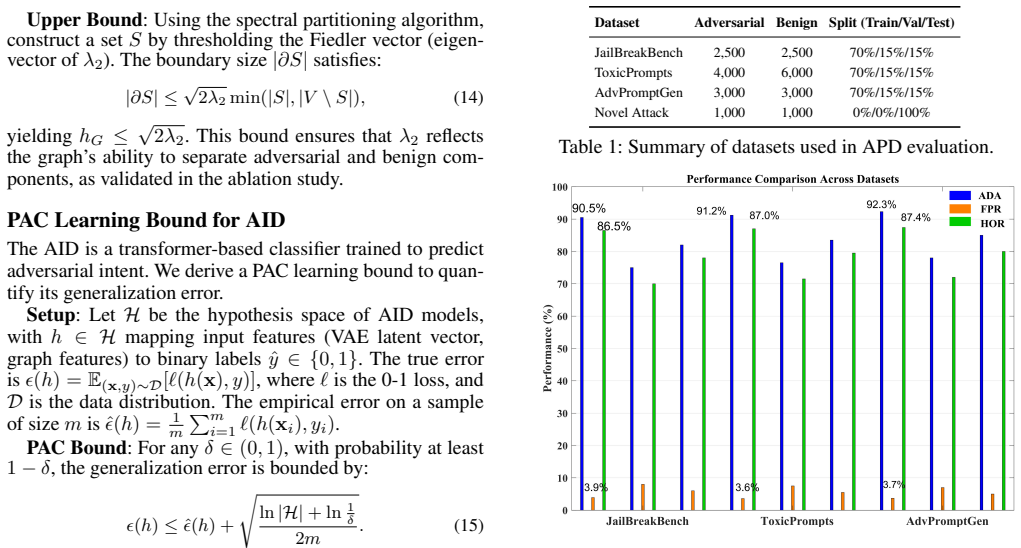
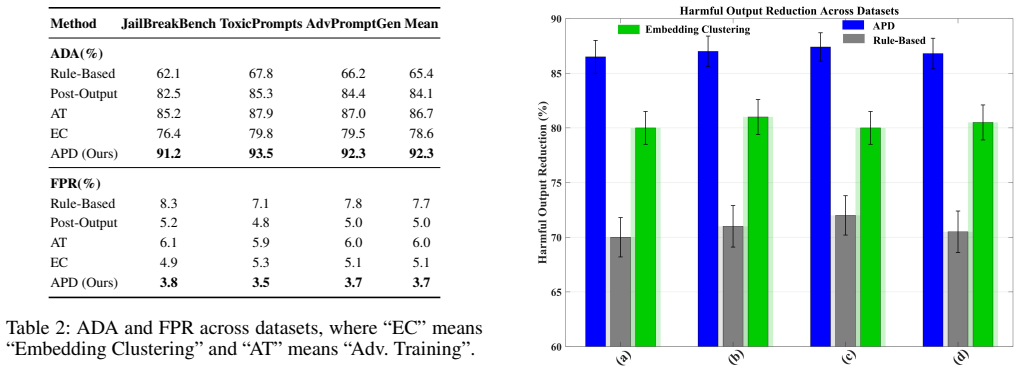
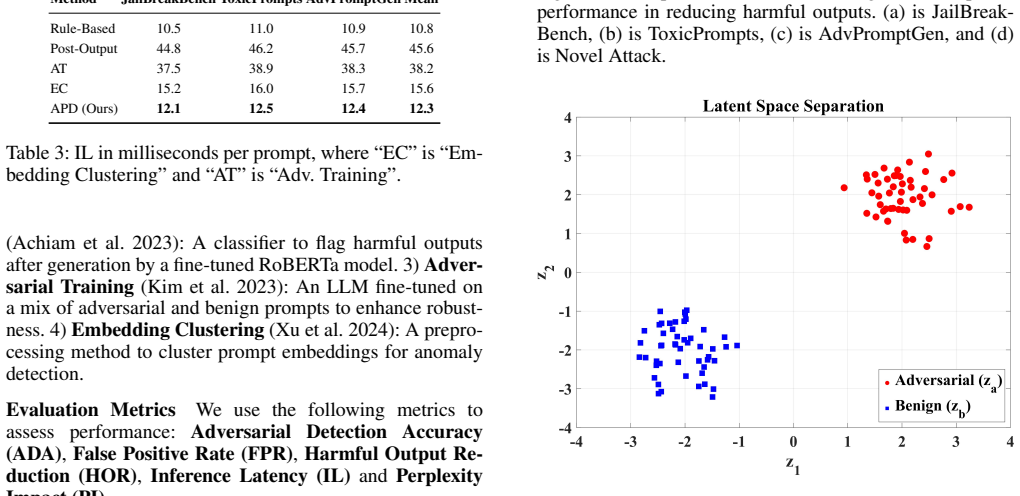
The APD framework proactively identifies and neutralizes malicious components in input prompts before they reach the LLM by combining three elements: a mutual information-based semantic decomposition that isolates adversarial and benign parts while ensuring statistical independence, a graph-based intent classification that uses spectral analysis to detect malicious semantic patterns, and a lightweight transformer classifier trained on real-world toxic and jailbreaking prompts. On diverse adversarial datasets the method reduces harmful output generation by over 85 percent while leaving model performance essentially unchanged and supporting real-time use.
What carries the argument
The Adversarial Prompt Disentanglement (APD) framework, which isolates prompt components via mutual information and detects malicious intent via spectral graph analysis before LLM processing.
If this is right
- LLMs gain robustness against jailbreaking and prompt injection in security-critical deployments.
- The added defense runs efficiently enough for real-time applications without requiring heavy extra hardware.
- Normal task performance on clean prompts remains nearly identical to the undefended model.
- The approach supplies a scalable, pre-processing layer against prompt-based threats.
Where Pith is reading between the lines
- The decomposition step could be tested on multimodal inputs if the mutual-information separation generalizes beyond text.
- Layering APD with output-side filters might create a two-stage defense whose combined failure rate is lower than either alone.
- Performance on attack variants invented after the training data cutoff would need separate measurement to confirm lasting coverage.
Load-bearing premise
Mutual information decomposition can separate adversarial and benign prompt elements into statistically independent parts, and spectral graph analysis can reliably flag the malicious patterns.
What would settle it
Apply APD to a fresh collection of adversarial prompts outside the training and test sets and observe whether the rate of harmful outputs stays above 15 percent.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly vulnerable to adversarial prompts that exploit semantic ambiguities to bypass safety mechanisms, resulting in harmful or inappropriate outputs. Such attacks, including jailbreaking and prompt injection, pose significant risks to the integrity and availability of LLMs in security-critical applications. This paper proposes the Adversarial Prompt Disentanglement (APD) framework, a novel defense mechanism that proactively identifies and neutralizes malicious components in input prompts before they are processed by the LLM. The APD framework integrates three key innovations: (1) a mutual information-based semantic decomposition method to isolate adversarial and benign prompt components, ensuring statistical independence; (2) a graph-based intent classification approach that leverages spectral analysis to detect malicious patterns in prompt semantics; and (3) a lightweight transformer-based classifier trained on real-world datasets of toxic and jailbreaking prompts, enabling efficient and accurate adversarial intent detection. Evaluated on diverse datasets containing adversarial prompts, APD demonstrates superior robustness, reducing harmful output generation by over 85\% while maintaining negligible impact on model performance. The framework's computational efficiency supports real-time deployment, making it a practical solution for securing LLMs. Our work addresses critical challenges in machine learning security on novel attacks and integrity methods for ML systems, and offers a scalable, ethically grounded defense against prompt-based adversarial threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Adversarial Prompt Disentanglement (APD) framework to defend LLMs against adversarial prompts such as jailbreaking and prompt injection. It integrates three components: (1) a mutual information-based semantic decomposition method claimed to isolate adversarial and benign prompt components while ensuring statistical independence, (2) a graph-based intent classification approach using spectral analysis to detect malicious patterns, and (3) a lightweight transformer-based classifier trained on toxic and jailbreaking prompts. The paper asserts that APD reduces harmful output generation by over 85% with negligible impact on model performance and supports real-time deployment.
Significance. If the performance claims hold, the APD framework would represent a meaningful advance in LLM security by providing a proactive, multi-stage defense that addresses semantic ambiguities in adversarial inputs. The combination of information-theoretic decomposition with graph-based and transformer methods could inform future work on prompt-level robustness in generative models deployed in security-critical settings.
major comments (2)
- [Abstract] Abstract: The assertion that the mutual information-based semantic decomposition 'ensures statistical independence' between adversarial and benign components is presented without any supporting quantitative evidence, such as post-decomposition MI estimates, ablation results on residual dependence, or a formal argument that the decomposition operator enforces I(A;B)≈0. This independence is load-bearing for the downstream claim of >85% reduction in harmful outputs, as residual dependence would allow malicious intent to reach the LLM.
- [Abstract] Abstract: The evaluation claims 'superior robustness' and a reduction in harmful output generation 'by over 85%' with 'negligible impact on model performance,' yet the manuscript supplies no datasets, baselines, metrics, error bars, ablation studies, or result tables to substantiate these figures. Without this evidence the central empirical claim cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The description of the three innovations would be clearer if each were tied to a specific section or figure in the main text rather than listed only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to provide the requested supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the mutual information-based semantic decomposition 'ensures statistical independence' between adversarial and benign components is presented without any supporting quantitative evidence, such as post-decomposition MI estimates, ablation results on residual dependence, or a formal argument that the decomposition operator enforces I(A;B)≈0. This independence is load-bearing for the downstream claim of >85% reduction in harmful outputs, as residual dependence would allow malicious intent to reach the LLM.
Authors: We agree that the abstract does not currently include quantitative evidence for the independence claim. In the revised manuscript, we will add post-decomposition mutual information estimates, ablation results on residual dependence, and a formal argument or derivation demonstrating how the decomposition operator enforces I(A;B)≈0. These additions will directly support the downstream performance claims. revision: yes
-
Referee: [Abstract] Abstract: The evaluation claims 'superior robustness' and a reduction in harmful output generation 'by over 85%' with 'negligible impact on model performance,' yet the manuscript supplies no datasets, baselines, metrics, error bars, ablation studies, or result tables to substantiate these figures. Without this evidence the central empirical claim cannot be assessed.
Authors: We acknowledge that the manuscript as submitted lacks the detailed empirical substantiation referenced in the abstract. The revised version will include explicit descriptions of the datasets, baselines, metrics, error bars, ablation studies, and result tables to fully substantiate the reported reductions and performance impacts. revision: yes
Circularity Check
No circularity: method assertions are not derived from self-referential inputs
full rationale
The paper presents APD as a framework with three components, including a mutual information-based decomposition asserted to ensure statistical independence. No equations, derivations, or parameter-fitting steps are described that reduce a claimed prediction or result back to the input data or assumptions by construction. The performance claim (>85% reduction) is presented as an empirical outcome on datasets rather than a mathematical consequence of the method definition. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The description is self-contained as an engineering proposal without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mutual information decomposition can separate adversarial and benign components with statistical independence.
- domain assumption Spectral analysis on semantic graphs can detect malicious intent patterns.
invented entities (1)
-
Adversarial Prompt Disentanglement (APD) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Double Self-weighted Multi-view Clustering via Adaptive View Fusion
Imperceptible Beam-Sensitive Adversarial Attacks for LiDAR-based Object Detection in Autonomous Driving. In2025 IEEE International Conference on Multimedia and Expo (ICME), 1–6. IEEE. Cai, X.; Liu, D.; Qu, X.; Fang, X.; Dong, J.; Tang, K.; Zhou, P.; Sun, L.; and Hu, W. 2026. Towards building model/prompt-transferable attackers against large vision- langua...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Gehman, S.; Gururangan, S.; Sap, M.; Choi, Y .; and Smith, N
Springer. Gehman, S.; Gururangan, S.; Sap, M.; Choi, Y .; and Smith, N. A. 2020. RealToxicityPrompts: Evaluating Neural Toxi- city in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2020, 3356–3369. Jia, X.; Gao, S.; Guo, Q.; Qin, S.; Ma, K.; Huang, Y .; Liu, Y .; Tsang, I.; and Cao, X. 2025a. Semantic-aligned ad- versa...
-
[3]
Kethireddy, R
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37: 47094–47165. Kethireddy, R. R. 2024. Secure Model Distribution and De- ployment for LLMs.JOURNAL OF RECENT TRENDS IN COMPUTER SCIENCE AND ENGINEERING (JRTCSE), 12(4): 1–14. Kim, J.; Mao, Y .; Hou, R.; Yu, H.; Li...
2024
-
[4]
Lei, H.; Cai, X.; Liu, D.; Fang, X.; Qu, X.; Dong, J.; Yu, J.; and Jin, K
Dynamic Graph-enhanced Event Refinement for Tem- poral Sentence Grounding of Micro-moments.IEEE Trans- actions on Multimedia. Lei, H.; Cai, X.; Liu, D.; Fang, X.; Qu, X.; Dong, J.; Yu, J.; and Jin, K. 2025. Exploring Disentangled Appearance- Motion Contexts for Temporal Activity Localization. In 2025 International Joint Conference on Neural Networks (IJCN...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.