FPMoE: A Sparse Mixture-of-Experts Approach to Functional Code Generation
Pith reviewed 2026-06-29 09:45 UTC · model grok-4.3
The pith
FPMoE's sparse MoE with three language-specific experts and one shared expert generates functional code matching much larger models at 3B active parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
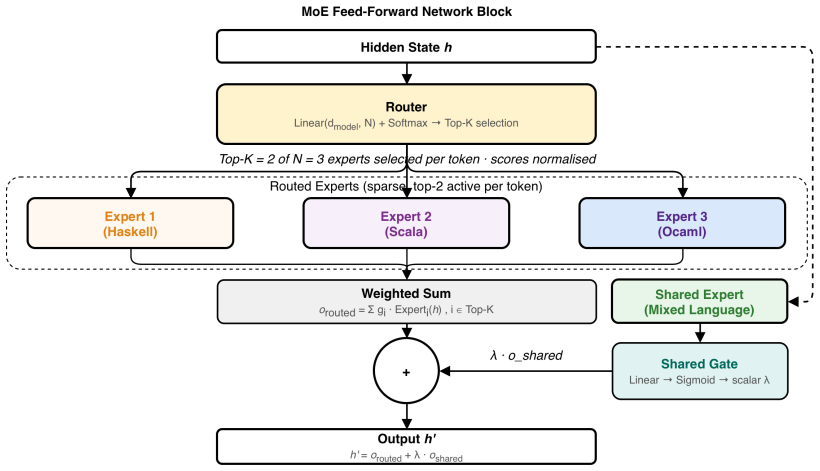
FPMoE is a sparse Mixture-of-Experts architecture with three language-specific routed experts for Haskell, OCaml, and Scala and a shared expert that captures cross-language functional patterns such as monadic reasoning and type-directed programming. This design resolves both the failure of per-language fine-tuning to capture shared abstractions and the cross-language interference from merged multi-language fine-tuning. On the FPEval benchmark, FPMoE substantially outperforms fine-tuned baselines and, with only 3B active parameters, matches the performance of much larger models including DeepSeek-Coder-6.7B, Qwen2.5-Coder-14B-Instruct, and Qwen3-Coder-30B-A3B.
What carries the argument
Sparse Mixture-of-Experts architecture with three language-specific routed experts plus one shared expert.
If this is right
- Dedicated experts remove cross-language interference that appears in merged fine-tuning.
- The shared expert preserves abstractions such as monadic reasoning that per-language models miss.
- Performance parity with 6.7B to 30B models is achieved with only 3B active parameters.
- The approach applies the MoE routing principle specifically to the functional-language interference problem.
- FPEval results demonstrate concrete gains over both per-language and merged baselines.
Where Pith is reading between the lines
- The same expert-separation pattern could be tested on other clusters of related languages or paradigms where interference occurs.
- Ablating the shared expert would directly measure how much of the gain comes from cross-language abstraction capture.
- Extending the design to additional functional languages would test whether the current three-plus-one count remains optimal.
- Deployment cost reductions follow if 3B-active performance holds on larger functional codebases.
Load-bearing premise
Routing to exactly three language-specific experts plus one shared expert will simultaneously eliminate cross-language interference and capture shared functional abstractions without further mechanisms.
What would settle it
An ablation showing that either per-language dense models or a single shared-expert model reach equivalent FPEval scores would falsify the necessity of the three-plus-one routing.
Figures
read the original abstract
Despite rapid progress in LLM-based code generation, existing models are predominantly trained on imperative languages, leaving functional programming languages (FPLs) such as Haskell, OCaml, and Scala chronically underexplored, with even frontier models performing substantially worse on FPLs. Fine-tuning is a natural remedy, but our experiments show that per-language fine-tuning fails to capture shared functional abstractions, while merged multi-language fine-tuning introduces cross-language interference. To address this, we introduce FPMoE, a lightweight, open-source code generation model built on a sparse Mixture-of-Experts (MoE) architecture with three language-specific routed experts (one each for Haskell, OCaml, and Scala) and a shared expert that captures cross-language functional patterns such as monadic reasoning and type-directed programming. This design resolves both failure modes simultaneously: dedicated experts eliminate interference, while the shared expert preserves abstractions that per-language models miss. On FPEval, FPMoE substantially outperforms fine-tuned baselines and, with only 3B active parameters, matches the performance of much larger models including DeepSeek-Coder-6.7B, Qwen2.5-Coder-14B-Instruct, and Qwen3-Coder-30B-A3B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FPMoE, a sparse Mixture-of-Experts architecture for code generation in functional languages (Haskell, OCaml, Scala). It consists of three language-specific routed experts plus one shared expert intended to capture cross-language functional patterns such as monadic reasoning. The central claim is that this design simultaneously avoids the shortcomings of per-language fine-tuning (failure to capture shared abstractions) and merged fine-tuning (cross-language interference), yielding substantial gains over fine-tuned baselines on FPEval while matching much larger models (DeepSeek-Coder-6.7B, Qwen2.5-Coder-14B, Qwen3-Coder-30B) using only 3B active parameters.
Significance. If the empirical claims hold after proper verification, the work would be significant for the PL and LLM communities: it targets an underexplored but practically relevant domain (functional code generation) and proposes a lightweight MoE solution that could generalize to other multi-language settings where shared abstractions exist alongside language-specific syntax and idioms.
major comments (2)
- [Abstract] Abstract: The headline performance claim (substantially outperforming fine-tuned baselines and matching 6.7B–30B models with 3B active parameters) is presented without any reported metrics, dataset statistics, training procedure, baseline details, or statistical controls. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
- [Abstract] Abstract: The assertion that routing to three language-specific experts plus one shared expert 'resolves both failure modes simultaneously' rests on an untested architectural assumption. No mechanism is described for ensuring the shared expert preferentially learns cross-language patterns (e.g., monadic reasoning) rather than language-specific ones, and no routing statistics, expert activation analysis, or ablation isolating the shared expert's contribution are referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires strengthening to better support the central claims and will revise it accordingly. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claim (substantially outperforming fine-tuned baselines and matching 6.7B–30B models with 3B active parameters) is presented without any reported metrics, dataset statistics, training procedure, baseline details, or statistical controls. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
Authors: We agree that the abstract would benefit from additional context to allow immediate evaluation of the claims. In the revised manuscript we will incorporate key quantitative results from the FPEval experiments (including specific performance improvements over the fine-tuned baselines and the 3B active-parameter comparison), a brief reference to the dataset and training procedure, and mention of the primary baselines. Full experimental details, including any statistical controls, remain in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract: The assertion that routing to three language-specific experts plus one shared expert 'resolves both failure modes simultaneously' rests on an untested architectural assumption. No mechanism is described for ensuring the shared expert preferentially learns cross-language patterns (e.g., monadic reasoning) rather than language-specific ones, and no routing statistics, expert activation analysis, or ablation isolating the shared expert's contribution are referenced.
Authors: The design is motivated by the failure-mode experiments reported in Section 4. The shared expert is trained on mixed-language data precisely to capture cross-language functional patterns; this is supported by the ablation studies in Section 5.2 that isolate the shared expert's contribution and the routing/activation analysis in Section 5.3. We will revise the abstract to explicitly reference these sections and to note that the shared expert receives tokens from all three languages during training. We do not claim an additional explicit regularization mechanism beyond the standard MoE training objective and the empirical results. revision: yes
Circularity Check
No circularity: empirical architecture proposal with no derivation chain
full rationale
The paper introduces an MoE model architecture and reports empirical results on FPEval. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation load-bearing claims appear in the provided text. The central claim (that the 3+1 expert design resolves interference and captures shared abstractions) is an empirical assertion supported by experiments, not a reduction to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Peter Achten. 2013. Why functional programming matters to me. In The Beauty of Functional Code
2013
-
[2]
AllenGeng. 2024. https://huggingface.co/datasets/AllenGeng/OCaml_program_corpus OCaml Program Corpus . Hugging Face dataset. A corpus of approximately 350,000 OCaml programs, 1M+ rows
2024
-
[3]
Anthropic. 2025. https://www.anthropic.com/news/claude-code Claude Code : An agentic coding tool . Technical Release
2025
-
[4]
Anysphere. 2023. https://cursor.sh Cursor: The AI -first code editor . Accessed: 2026-03-11
2023
-
[5]
Manuel M. T. Chakravarty and Gabriele Keller. 2004. The risks and benefits of teaching purely functional programming in first year. Journal of Functional Programming, 14:113 -- 123
2004
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. https://arxiv.org/abs/2107.03374 Evaluating large lang...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
CodeParrot. 2022. https://huggingface.co/datasets/codeparrot/github-code GitHub Code Dataset . Hugging Face dataset, version 1.1
2022
-
[8]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. https://arxiv.org/abs/2401.06066 DeepSeekMoE : Towards ultimate expert specialization in mixture-of-experts language models . Preprint, arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Atze Dijkstra, Jos \'e Pedro Magalh \ a es, and Pierre N \'e ron. 2024. Functional programming in financial markets (experience report). Proceedings of the ACM on Programming Languages, 8:234 -- 248
2024
-
[11]
William Fedus, Barret Zoph, and Noam Shazeer. 2022 b . https://arxiv.org/abs/2101.03961 Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity . Preprint, arXiv:2101.03961. Preprint
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Matth \' as P \'a ll Gissurarson, Leonhard Applis, Annibale Panichella, Arie Van Deursen, and David Sands. 2022. Propr: property-based automatic program repair. In Proceedings of the 44th international conference on software engineering, pages 1768--1780
2022
-
[13]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. https://arxiv.org/abs/2401.14196 Deepseek-coder: When the large language model meets programming -- the rise of code intelligence . Preprint, arXiv:2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
John Hughes. 1989. Why functional programming matters. Comput. J., 32:98--107
1989
-
[15]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. 1991. https://api.semanticscholar.org/CorpusID:572361 Adaptive mixtures of local experts . Neural Computation, 3:79--87
1991
-
[16]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, L \'e lio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, and 7 others. 2024...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Lang, Eric Lang, Thanh Le-Cong, Bach Le, and Quyet-Thang Huynh
Nguyet-Anh H. Lang, Eric Lang, Thanh Le-Cong, Bach Le, and Quyet-Thang Huynh. 2026. Perish or flourish? a holistic evaluation of large language models for code generation in functional programming. ArXiv, abs/2601.02060
- [18]
-
[19]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, and 48 others. 2023. https://arxiv.org/abs/2305.06161 Starcoder:...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R\' e mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d'Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, and 7 others. 2022. https://doi.org/10.1126/science.abq1158 ...
-
[21]
Yaron Minsky. 2011. OCaml for the masses. Communications of the ACM , 54(11):53--58
2011
-
[22]
OpenAI. 2022. https://openai.com/index/chatgpt/ Introducing chatgpt . Accessed: 2025-12-29
2022
-
[23]
Baishakhi Ray, Daryl Posnett, Vladimir Filkov, and Premkumar T. Devanbu. 2014. A large scale study of programming languages and code quality in github. Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering
2014
-
[24]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. https://arxiv.org/abs/1701.06538 Outrageously large neural networks: The sparsely-gated mixture-of-experts layer . Preprint, arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
a kel \"a , and Ville Isom \
Ville Tirronen, Samuel Uusi-M \"a kel \"a , and Ville Isom \"o tt \"o nen. 2015. Understanding beginners' mistakes with haskell. Journal of Functional Programming, 25
2015
-
[26]
Tim Van Dam, Frank Van der Heijden, Philippe De Bekker, Berend Nieuwschepen, Marc Otten, and Maliheh Izadi. 2024. Investigating the performance of language models for completing code in functional programming languages: a haskell case study. In Proceedings of the 2024 IEEE/ACM First International Conference on AI Foundation Models and Software Engineering...
2024
-
[27]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. https://doi.org/10.1109/ICSE48619.2023.00129 Automated program repair in the era of large pre-trained language models . In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1482--1494
-
[28]
Zaharia, Mosharaf Chowdhury, Michael J
Matei A. Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2010. Spark: Cluster computing with working sets. In USENIX Workshop on Hot Topics in Cloud Computing
2010
-
[29]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[30]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.