Profy: Interpretable Visualization of Expertise-Dependent Motor Skills Toward Supporting Piano Practice
Pith reviewed 2026-06-27 11:47 UTC · model grok-4.3
The pith
A model trained only on whole-take expert vs amateur ratings produces time-localized piano highlights that match expert review marks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Trained solely on take-level labels that distinguish expert-labeled from amateur-labeled performances, the system generates evidence scores aligned to time that correlate with passages marked for review by expert pianists on unseen amateur clips (Pearson r=0.61, ROC-AUC 0.75).
What carries the argument
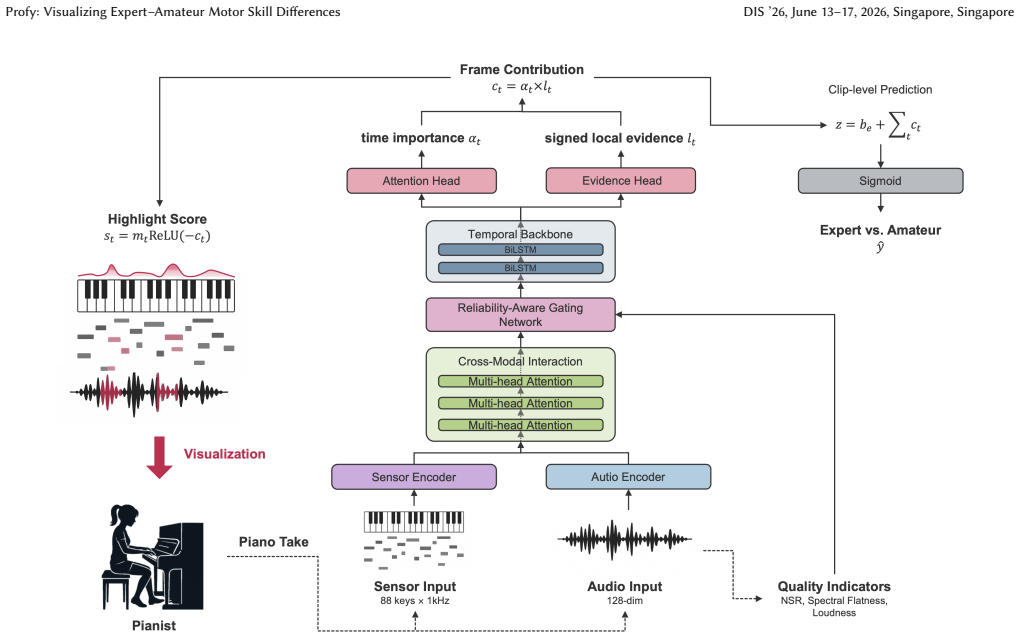
Weakly supervised learning from take-level aggregated listener ratings that produces time-aligned evidence scores on a shared resampled model time base.
If this is right
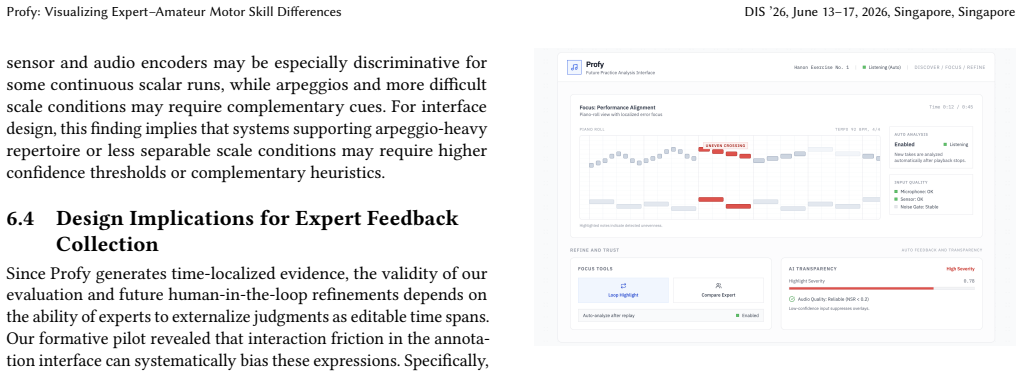
- Learners receive actionable time-localized feedback instead of only a global score for an entire take.
- The output supports scrubbing, looping, and focused replay of passages tied to expert-amateur differences.
- Clip-level predictions and evidence scores are produced together on the same time base for visualization.
Where Pith is reading between the lines
- The same weakly supervised approach could be tested on other motor tasks where only overall quality labels are readily available.
- Extending the model to handle longer pieces or different instruments would require checking whether the take-level signal remains sufficient for localization.
- Real-time versions might allow immediate highlighting while a learner is still playing.
Load-bearing premise
Aggregated ratings of entire takes contain enough signal to train a model that localizes expert-amateur differences without any time-specific supervision during training.
What would settle it
Collecting new amateur piano clips, obtaining independent expert annotations of review passages, and finding zero or near-zero correlation between the model's highlight scores and those annotations would falsify the central claim.
Figures




read the original abstract
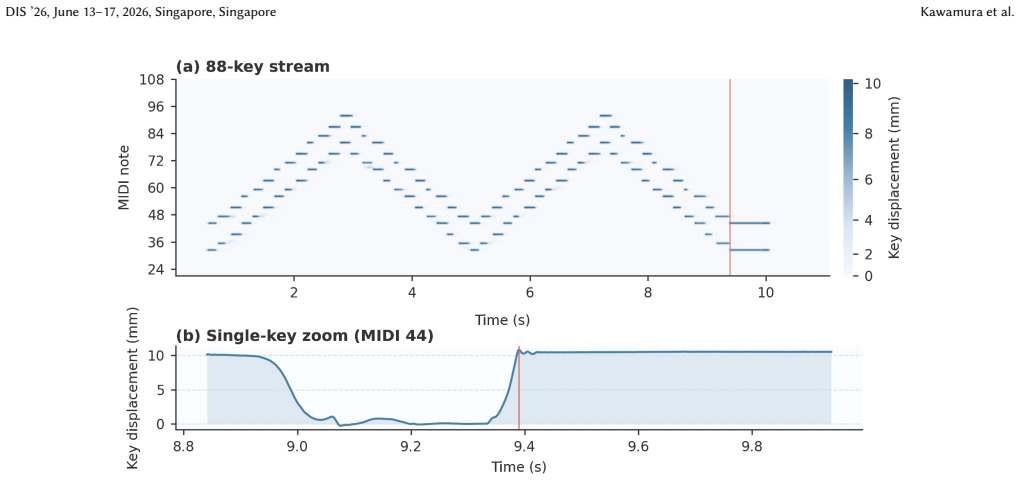
The quality of piano performance depends on nuanced timing, articulation, and dynamic control, but practice feedback is often summary-based and hard to act on. We introduce Profy, a weakly supervised system that learns from take-level labels derived from aggregated listener ratings (expert-labeled vs. amateur-labeled) to produce time-aligned highlights for review during piano practice. We collected synchronized 1 kHz key-motion and audio from 73 pianists and used 1,083 valid takes for modeling and evaluation. The model outputs clip-level predictions together with evidence scores on a shared resampled model time base for visualization. On 20 amateur clips from short technique studies annotated by 21 expert pianists, the displayed highlight score aligns with passages that expert pianists marked for review despite training without localized labels (Pearson r=0.61, ROC-AUC 0.75). Rather than summarizing a take with a single global score, Profy helps learners decide where to inspect next by supporting scrubbing, looping, and focused replay of time-localized passages associated with expert-amateur differences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Profy, a weakly supervised system that trains on take-level labels (expert-labeled vs. amateur-labeled takes derived from aggregated listener ratings) to generate time-aligned evidence scores for highlighting passages in piano performances. Using synchronized 1 kHz key-motion and audio data from 73 pianists (1,083 valid takes), the model produces clip-level predictions and evidence scores on a shared time base. On a held-out set of 20 amateur clips annotated by 21 expert pianists, the highlight scores align with expert-marked review passages (Pearson r=0.61, ROC-AUC=0.75) despite the absence of localized supervision during training. The system supports practice by enabling scrubbing, looping, and focused replay of specific passages.
Significance. If the localization result holds under proper validation, the work offers a practical advance in HCI for motor-skill feedback by showing that bag-level supervision can yield interpretable, time-resolved visualizations without requiring expensive localized annotations. The scale of the sensor dataset and the emphasis on actionable, non-global feedback are positive features. The approach could generalize to other domains involving nuanced timing and control if the weak-supervision mechanism proves robust.
major comments (2)
- [Abstract] Abstract: The headline metrics (r=0.61, AUC=0.75) are presented as evidence that time-localized scores can be recovered from take-level labels alone, yet the abstract supplies no description of the model architecture, the evidence-score extraction method (attention, MIL pooling, gradient-based saliency, etc.), or any control experiments that would rule out leakage from global cues such as tempo or recording quality. This mechanism is load-bearing for the central claim.
- [Abstract] Abstract / evaluation section: The reported alignment is measured on only 20 clips; without details on clip selection criteria, inter-annotator agreement among the 21 experts, or how the expert-marked passages were aggregated into ground-truth segments, it is difficult to assess whether the correlation reflects genuine localization or annotation artifacts.
minor comments (1)
- [Abstract] The abstract states that 1,083 takes were used but does not indicate the total number collected or the exclusion criteria; adding a brief sentence on data filtering would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline metrics (r=0.61, AUC=0.75) are presented as evidence that time-localized scores can be recovered from take-level labels alone, yet the abstract supplies no description of the model architecture, the evidence-score extraction method (attention, MIL pooling, gradient-based saliency, etc.), or any control experiments that would rule out leakage from global cues such as tempo or recording quality. This mechanism is load-bearing for the central claim.
Authors: We agree the abstract is too concise on methodology. In revision we will add a brief clause describing the architecture (weakly-supervised network with attention-based MIL pooling) and evidence-score extraction (attention weights projected to the shared 1 kHz time base). On controls, the full methods section already reports ablation studies that isolate local timing features from global tempo and recording-quality covariates; we will reference these explicitly in the revised abstract to address leakage concerns. revision: yes
-
Referee: [Abstract] Abstract / evaluation section: The reported alignment is measured on only 20 clips; without details on clip selection criteria, inter-annotator agreement among the 21 experts, or how the expert-marked passages were aggregated into ground-truth segments, it is difficult to assess whether the correlation reflects genuine localization or annotation artifacts.
Authors: We will expand the evaluation section (and add a short clause to the abstract) with the requested details: clip selection was random sampling from the held-out amateur technique-study pool stratified by performer; inter-annotator agreement will be reported (Fleiss’ kappa computed on the 21-expert markings); and ground-truth segments were formed by majority vote across experts with a minimum overlap threshold. These statistics are derivable from the existing annotations and will be included in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper trains a weakly supervised model on take-level (bag) labels derived from aggregated expert/amateur ratings and evaluates the resulting time-localized evidence scores against independent expert-marked passages on a separate set of 20 clips. The reported Pearson r=0.61 and ROC-AUC 0.75 are direct empirical comparisons to external annotations never used in training; no equations, self-citations, or fitted parameters are shown that would make the highlight scores equivalent to the input labels by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https: //doi.org/10.1145/3290605.3300233 .https://doi.org/10.1145/3290605.3300233
Saleema Amershi, Ece Kamar, Shamsi T. Iqbal, Jina Suh, Brian A. Chin, Justin Fogarty, and Daniel S. Weld. 2019. Guidelines for Human-AI Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland, UK)(CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3290605.3300233
-
[2]
Reed, Yixiao Zhang, and Jack Armitage
Nick Bryan-Kinns, Berker Banar, Corey Ford, Courtney N. Reed, Yixiao Zhang, and Jack Armitage. 2024. Explainable AI and Music. InArtificial Intelligence for Art Creation and Understanding, Luntian Mou (Ed.). CRC Press, Boca Raton, FL, USA, 1–29. https://doi.org/10.1201/9781003406273-1
-
[3]
Susan Bull and Judy Kay. 2007. Student Models that Invite the Learner In: The SMILI:() Open Learner Modelling Framework.International Journal of Artificial Intelligence in Education17, 2 (2007), 89–120. https://doi.org/10.3233/irg-2007- 17(2)02
-
[4]
Susan Bull and Judy Kay. 2016. SMILI: a Framework for Interfaces to Learning Data in Open Learner Models, Learning Analytics and Related Fields.International Journal of Artificial Intelligence in Education26, 1 (2016), 293–331. https://doi. org/10.1007/s40593-015-0090-8
-
[5]
Qiyu Chen, Richa Mishra, Lia Sparingga Purnamasari, Dina El-Zanfaly, and Kris Kitani. 2025. Origami Sensei: A Mixed Reality AI-Assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–18. https://doi. org/10.1145/3706598.3714099
-
[6]
Pei-Ying Chiang and Chung-Hsuan Sun. 2015. Oncall Piano Sensei: Portable AR Piano Training System. InProceedings of the 3rd ACM Symposium on Spatial User Interaction(Los Angeles, CA, USA)(SUI ’15). Association for Computing Machin- ery, New York, NY, USA, 134–134. https://doi.org/10.1145/2788940.2794353
-
[7]
Roger B. Dannenberg and Robert L. Joseph. 1992. Human-Computer Interaction in the Piano Tutor. InMultimedia Interface Design, M. M. Blattner and R. B. Dannenberg (Eds.). Association for Computing Machinery, New York, NY, USA, 65–78. https://doi.org/10.1145/146022.146033
-
[8]
Jordan Aiko Deja, Sven Mayer, Klen Copic Pucihar, and Matjaz Kljun. 2022. A Survey of Augmented Piano Prototypes: Has Augmentation Improved Learning Experiences?Proceedings of the ACM on Human-Computer Interaction6, ISS, Article 566 (2022), 28 pages. https://doi.org/10.1145/3567719
-
[9]
Chris Donahue, Ian Simon, and Sander Dieleman. 2019. Piano Genie. InProceed- ings of the 24th International Conference on Intelligent User Interfaces(Marina del Rey, CA, USA)(IUI ’19). Association for Computing Machinery, New York, NY, USA, 160–164. https://doi.org/10.1145/3301275.3302288
-
[10]
2010.MAPS Database: A Piano Database for Multipitch Estimation and Automatic Transcription of Music
Valentin Emiya and Bertrand David. 2010.MAPS Database: A Piano Database for Multipitch Estimation and Automatic Transcription of Music. ADASP Group. Retrieved May 3, 2026 from https://adasp.telecom-paris.fr/resources/2010-07-08- maps-database/ Dataset webpage
2010
-
[11]
Vsevolod Eremenko, Alia Morsi, Jyoti Narang, and Xavier Serra. 2020. Perfor- mance Assessment Technologies for the Support of Musical Instrument Learning. InProceedings of the 12th International Conference on Computer Supported Edu- cation - Volume 1: CSME (CSEDU 2020). INSTICC, SciTePress, Setúbal, Portugal, 629–640. https://doi.org/10.5220/0009817006290640
-
[12]
Francesco Foscarin, Andrew McLeod, Philippe Rigaux, Florent Jacquemard, and Masahiko Sakai. 2020. ASAP: A Dataset of Aligned Scores and Performances for Piano Transcription. InProceedings of the 21st International Society for Music Information Retrieval Conference (ISMIR ’20). International Society for Music Information Retrieval, Montreal, Canada, 534–54...
2020
-
[13]
Qijun Gan, Song Wang, Shengtao Wu, and Jianke Zhu. 2025. PianoMotion10M: Dataset and Benchmark for Hand Motion Generation in Piano Performance. In The Thirteenth International Conference on Learning Representations(Singapore) (ICLR ’25). OpenReview.net, Singapore, 18 pages. https://openreview.net/forum? id=rxVvRBgqmS
2025
-
[14]
Gilliland, Celeste Mason, Caitlyn Seim, and Thad Starner
Tan Gemicioglu, Elijah Hopper, Brahmi Dwivedi, Richa Kulkarni, Asha Bhan- darkar, Priyanka Rajan, Nathan Eng, Adithya Ramanujam, Charles Ramey, Scott M. Gilliland, Celeste Mason, Caitlyn Seim, and Thad Starner. 2024. Passive Haptic Rehearsal for Augmented Piano Learning in the Wild.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Tec...
-
[15]
Xuanyu Hao, Jialuo Yang, and Michael Nitsche. 2025. Designing a Teaching Interface for Tacit Knowledge: Approach and Implementation. InProceedings of the 2025 Conference on Creativity and Cognition (C&C ’25). Association for Computing Machinery, New York, NY, USA, 384–389. https://doi.org/10.1145/ 3698061.3734411
arXiv 2025
-
[16]
John Hattie and Helen Timperley. 2007. The Power of Feedback.Review of Edu- cational Research77, 1 (2007), 81–112. https://doi.org/10.3102/003465430298487
-
[17]
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck. 2019. Enabling Factorized Piano Music Modeling and Generation with the MAE- STRO Dataset. InInternational Conference on Learning Representations(New Orleans, LA, USA)(ICLR ’19). OpenReview.net, New Orleans, LA, USA, ...
2019
-
[18]
Kenneth Holstein, Bruce M. McLaren, and Vincent Aleven. 2019. Co-Designing a Real-Time Classroom Orchestration Tool to Support Teacher–AI Complementar- ity.Journal of Learning Analytics6, 2 (2019), 27–52. https://doi.org/10.18608/jla. 2019.62.3
-
[19]
Gaoping Huang, Xun Qian, Tianyi Wang, Fagun Patel, Maitreya Sreeram, Yuanzhi Cao, Karthik Ramani, and Alexander J. Quinn. 2021. AdapTutAR: An Adaptive Tutoring System for Machine Tasks in Augmented Reality. InPro- ceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–...
-
[20]
Jiawen Huang, Yun-Ning Hung, Ashis Pati, Siddharth Kumar Gururani, and Alexander Lerch. 2020. Score-Informed Networks for Music Performance As- sessment. InProceedings of the 21st International Society for Music Information Retrieval Conference(Montreal, Canada)(ISMIR ’20). International Society for Music Information Retrieval, Montreal, Canada, 908–915. ...
2020
-
[21]
Kevin Huang, Thad Starner, Ellen Yi-Luen Do, Gil Weinberg, Daniel Kohlsdorf, Claas Ahlrichs, and Rüdiger Leibrandt. 2010. Mobile Music Touch: Mobile Tactile Stimulation for Passive Learning. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Atlanta, GA, USA)(CHI ’10). Association for Computing Machinery, New York, NY, USA, 791–8...
arXiv 2010
-
[22]
Maximilian Ilse, Jakub Tomczak, and Max Welling. 2018. Attention-based Deep Multiple Instance Learning. InProceedings of the 35th International Conference on Machine Learning (PMLR, Vol. 80). PMLR, Stockholm, Sweden, 2127–2136. https://proceedings.mlr.press/v80/ilse18a.html
2018
-
[23]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton
-
[24]
Adaptive Mixtures of Local Experts.Neural Computation3, 1 (1991), 79–87. https://doi.org/10.1162/neco.1991.3.1.79
-
[25]
Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies(Minneapolis, MN, USA)(NAACL-HLT ’19). Association for Computational Linguistics, Minneapolis, Minnesota, 3543–3556. https://doi.org/10.1865...
-
[26]
Hyerim Jeon and Wen-Syan Li. 2025. Identifying Critical Segments Affecting Piano Performance Evaluation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Korea) (CIKM ’25). Association for Computing Machinery, New York, NY, USA, 1046–
2025
-
[27]
https://doi.org/10.1145/3746252.3761010
-
[28]
Hongfei Ji, Peiyu Hu, and Dina El-Zanfaly. 2025. Reshaping Craft Learning: Insights from Designing an AI-Augmented MR System for Wheel-Throwing. InProceedings of the 2025 ACM Designing Interactive Systems Conference (DIS ’25). Association for Computing Machinery, New York, NY, USA, 2549–2573. https://doi.org/10.1145/3715336.3735844
-
[29]
Yucong Jiang. 2023. Expert and Novice Evaluations of Piano Performances: Crite- ria for Computer-Aided Feedback. InProceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR ’23). International Society for Music Information Retrieval, Milan, Italy, 367–374. https://doi.org/10.5281/ zenodo.10265301
2023
-
[30]
Rose M. G. Johnson, Janet van der Linden, and Yvonne Rogers. 2010. MusicJacket: the efficacy of real-time vibrotactile feedback for learning to play the violin. In CHI ’10 Extended Abstracts on Human Factors in Computing Systems(Atlanta, GA, USA)(CHI ’10). Association for Computing Machinery, New York, NY, USA, 3475–3480. https://doi.org/10.1145/1753846.1754004
-
[31]
Jakob Karolus, Johannes Sylupp, Albrecht Schmidt, and Paweł W. Woźniak. 2023. EyePiano: Leveraging Gaze for Reflective Piano Learning. InProceedings of the 2023 ACM Designing Interactive Systems Conference(Pittsburgh, PA, USA)(DIS ’23). Association for Computing Machinery, New York, NY, USA, 1209–1223. https://doi.org/10.1145/3563657.3596065
-
[32]
Kazuki Kawamura and Jun Rekimoto. 2021. A Language Acquisition Support System that Presents Differences and Distances from Model Speech. InAdjunct Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology(Virtual Event, USA)(UIST ’21 Adjunct). Association for Computing Machinery, New York, NY, USA, 44–46. https://doi.org/10.11...
-
[33]
Kazuki Kawamura and Jun Rekimoto. 2022. DDSupport: Language Learning Support System that Displays Differences and Distances from Model Speech. In 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA)(Nassau, Bahamas)(ICMLA ’22). IEEE, Piscataway, NJ, USA, 313–320. https://doi.org/10.1109/ICMLA55696.2022.00051
-
[34]
Hyon Kim, Pedro Ramoneda, Marius Miron, and Xavier Serra. 2022. An Overview of Automatic Piano Performance Assessment within the Music Education Con- text. InProceedings of the 14th International Conference on Computer Supported Education - Volume 1: CSME (CSEDU 2022), Mutlu Cukurova, Nikol Rummel, De- nis Gillet, Bruce M. McLaren, and James Uhomoibhi (Ed...
-
[35]
Yonghyun Kim, Junhyung Park, Joonhyung Bae, Kirak Kim, Taegyun Kwon, Alexander Lerch, and Juhan Nam. 2025. PianoVAM: A Multimodal Piano Perfor- mance Dataset. InProceedings of the 26th International Society for Music Infor- mation Retrieval Conference (ISMIR ’25). International Society for Music Informa- tion Retrieval, Daejeon, South Korea, 528–535. http...
-
[36]
Kaori Kuromiya, Yuya Kobayashi, Masato Hirano, and Shinichi Furuya. 2025. Mo- tor origins of timbre in piano performance.Proceedings of the National Academy of Sciences122, 39 (2025), e2425073122. https://doi.org/10.1073/pnas.2425073122
-
[37]
Alexander Lerch, Claire Arthur, Ashis Pati, and Siddharth Gururani. 2020. An Interdisciplinary Review of Music Performance Analysis.Transactions of the International Society for Music Information Retrieval3, 1 (2020), 221–245. https: //doi.org/10.5334/tismir.53
-
[38]
Ruofan Liu, Yichen Peng, Takanori Oku, Chen-Chieh Liao, Erwin Wu, Shinichi Furuya, and Hideki Koike. 2025. PiaMuscle: Improving Piano Skill Acquisition by Cost-effectively Estimating and Visualizing Activities of Miniature Hand Muscles. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (Yokohama, Japan)(CHI ’25). Association f...
-
[39]
Ruofan Liu, Erwin Wu, Chen-Chieh Liao, Hayato Nishioka, Shinichi Furuya, and Hideki Koike. 2023. PianoHandSync: An Alignment-Based Hand Pose Discrep- ancy Visualization System for Piano Learning. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany) (CHI EA ’23). Association for Computing Machinery, New Yo...
-
[40]
Ruofan Liu, Erwin Wu, Chen-Chieh Liao, Hayato Nishioka, Shinichi Furuya, and Hideki Koike. 2023. PianoSyncAR: Enhancing Piano Learning through Visualizing Synchronized Hand Pose Discrepancies in Augmented Reality. In 2023 IEEE International Symposium on Mixed and Augmented Reality(Sydney, Australia)(ISMAR ’23). IEEE, Piscataway, NJ, USA, 859–868. https://...
arXiv 2023
-
[41]
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision- and-Language Tasks. InAdvances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc., Red Hook, NY, USA, 13–
2019
-
[42]
https://papers.nips.cc/paper/8297-vilbert-pretraining-task-agnostic- visiolinguistic-representations-for-vision-and-language-tasks
-
[43]
Brian McFee, Justin Salamon, and Juan Pablo Bello. 2018. Adaptive Pooling Operators for Weakly Labeled Sound Event Detection.IEEE/ACM Transactions on Audio, Speech, and Language Processing26, 11 (2018), 2180–2193. https: //doi.org/10.1109/TASLP.2018.2858559
-
[44]
McPherson, Peter Miksza, and Paul Evans
Gary E. McPherson, Peter Miksza, and Paul Evans. 2017. Self-Regulated Learning in Music Practice and Performance. InHandbook of Self-Regulation of Learning and Performance(2 ed.), Dale H. Schunk and Jeffrey A. Greene (Eds.). Routledge, New York, NY, USA, 181–193. https://doi.org/10.4324/9781315697048-12
-
[45]
Alia Morsi, Kana Tatsumi, Akira Maezawa, Takuya Fujishima, and Xavier Serra. 2023. Sounds Out of Pläce?: Score-Independent Detection of Conspic- uous Mistakes in Piano Performances. InProceedings of the 24th International Society for Music Information Retrieval Conference(Milan, Italy)(ISMIR ’23). International Society for Music Information Retrieval, Mil...
2023
-
[46]
Tomohiko Nakamura, Eita Nakamura, and Shigeki Sagayama. 2016. Real-Time Audio-to-Score Alignment of Music Performances Containing Errors and Arbi- trary Repeats and Skips.IEEE/ACM Transactions on Audio, Speech, and Language Processing24, 2 (2016), 329–339. https://doi.org/10.1109/TASLP.2015.2507862
-
[47]
Takanori Oku and Shinichi Furuya. 2022. Noncontact and High-Precision Sensing System for Piano Keys Identified Fingerprints of Virtuosity.Sensors22, 13 (2022),
2022
-
[48]
https://doi.org/10.3390/s22134891
-
[49]
Jisoo Park, Jongho Kim, Jeong Mi Park, Ahyeon Choi, Wen-Syan Li, Jonghwa Park, and Seung won Hwang. 2024. Piano Performance Evaluation Dataset with Multilevel Perceptual Features.Scientific Reports14, 1 (2024), 23002. https: //doi.org/10.1038/s41598-024-73810-0
-
[50]
Varinya Phanichraksaphong and Wei-Ho Tsai. 2021. Automatic Evaluation of Piano Performances for STEAM Education.Applied Sciences11, 24 (2021), 11783. https://doi.org/10.3390/app112411783
-
[51]
Pedro O. Pinheiro and Ronan Collobert. 2015. From Image-Level to Pixel-Level Labeling with Convolutional Networks. InProceedings of the 2015 IEEE Conference DIS ’26, June 13–17, 2026, Singapore, Singapore Kawamura et al. on Computer Vision and Pattern Recognition(Boston, MA, USA)(CVPR ’15). IEEE, Piscataway, NJ, USA, 1713–1721. https://doi.org/10.1109/CVP...
-
[52]
Kaska Porayska-Pomsta. 2016. AI as a Methodology for Supporting Educational Praxis and Teacher Metacognition.International Journal of Artificial Intelligence in Education26, 2 (2016), 679–700. https://doi.org/10.1007/s40593-016-0101-4
-
[53]
Liam Rigby, Burkhard C. Wünsche, and Alex Shaw. 2020. piARno - An Aug- mented Reality Piano Tutor. InProceedings of the 32nd Australian Conference on Human-Computer Interaction(Sydney, NSW, Australia)(OzCHI ’20). As- sociation for Computing Machinery, New York, NY, USA, 481–491. https: //doi.org/10.1145/3441000.3441039
-
[54]
Katja Rogers, Amrei Röhlig, Matthias Weing, Jan Gugenheimer, Bastian Könings, Melina Klepsch, Florian Schaub, Enrico Rukzio, Tina Seufert, and Michael Weber
-
[55]
P.I.A.N.O.: Faster Piano Learning with Interactive Projection. InProceedings of the 2014 ACM International Conference on Interactive Tabletops and Surfaces (Dresden, Germany)(ITS ’14). Association for Computing Machinery, New York, NY, USA, 149–158. https://doi.org/10.1145/2669485.2669514
-
[56]
Kauffmann, Robert A
Lukas Ruff, Jacob R. Kauffmann, Robert A. Vandermeulen, Grégoire Montavon, Wojciech Samek, Marius Kloft, Thomas G. Dietterich, and Klaus-Robert Müller
-
[57]
A Unifying Review of Deep and Shallow Anomaly Detection.Proc. IEEE 109, 5 (2021), 756–795. https://doi.org/10.1109/JPROC.2021.3052449
-
[58]
Makiko Sadakata, David Hoppe, Alex Brandmeyer, Renée Timmers, and Peter Desain. 2008. Real-Time Visual Feedback for Learning to Perform Short Rhythms with Expressive Variations in Timing and Loudness.Journal of New Music Research37, 3 (2008), 207–220. https://doi.org/10.1080/09298210802322401
-
[59]
Craig Stuart Sapp. 2007. Comparative Analysis of Multiple Musical Performances. InProceedings of the 8th International Conference on Music Information Retrieval (Vienna, Austria)(ISMIR ’07). International Society for Music Information Re- trieval, Vienna, Austria, 497–500. https://archives.ismir.net/ismir2007/paper/ 000497.pdf
2007
-
[60]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. https://doi.org/10.48550/arXiv. 1701.06538 arXiv:1701.06538 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[61]
Atsuko Tominaga, Günther Knoblich, and Natalie Sebanz. 2022. Expert Pianists Make Specific Exaggerations for Teaching.Scientific Reports12, 1 (2022), 21296. https://doi.org/10.1038/s41598-022-25711-3
-
[62]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30. Curran As- sociates, Inc., Red Hook, NY, USA, 5998–6008. https://papers.nips.cc/paper/7181- attention-is-all-you-need
2017
-
[63]
Gerhard Widmer. 2016. Getting Closer to the Essence of Music: The Con Espres- sione Manifesto.ACM Transactions on Intelligent Systems and Technology8, 2, Article 19 (2016), 14 pages. https://doi.org/10.1145/2899004
-
[64]
Sarah Wiegreffe and Yuval Pinter. 2019. Attention is not not Explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing(Hong Kong, China)(EMNLP-IJCNLP ’19). Association for Computational Linguistics, Hong Kong, China, 11–20. https://doi....
-
[65]
Katie Wilson and Phillip E. Pfeiffer. 2023. Feedback in augmented and virtual reality piano tutoring systems: a mini review.Frontiers in Virtual Reality4 (2023), 1207397. https://doi.org/10.3389/frvir.2023.1207397
-
[66]
Xiao Xiao and Hiroshi Ishii. 2011. MirrorFugue: communicating hand gesture in remote piano collaboration. InProceedings of the Fifth International Conference on Tangible, Embedded, and Embodied Interaction(Funchal, Portugal)(TEI ’11). Association for Computing Machinery, New York, NY, USA, 13–20. https://doi. org/10.1145/1935701.1935705
-
[67]
Xuanhui Xu, Eleni Mangina, and Abraham G. Campbell. 2021. HMD-Based Virtual and Augmented Reality in Medical Education: A Systematic Review.Frontiers in Virtual Reality2 (2021), 692103. https://doi.org/10.3389/frvir.2021.692103
-
[68]
Masaki Yasuhara, Kazumasa Uehara, Takanori Oku, Sachiko Shiotani, Isao Nambu, and Shinichi Furuya. 2024. Robustness and adaptability of sensorimotor skills in expert piano performance.iScience27, 8 (2024), 110400. https://doi.org/10.1016/ j.isci.2024.110400
arXiv 2024
-
[69]
Beste F. Yuksel, Kurt B. Oleson, Lane Harrison, Evan M. Peck, Daniel Afergan, Remco Chang, and Robert J.K. Jacob. 2016. Learn Piano with BACh: An Adaptive Learning Interface that Adjusts Task Difficulty Based on Brain State. InProceed- ings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, CA, USA)(CHI ’16). Association for Comput...
-
[70]
Huan Zhang, Vincent K. M. Cheung, Hayato Nishioka, Simon Dixon, and Shinichi Furuya. 2025. LLaQo: Towards a Query-Based Coach in Expressive Music Perfor- mance Assessment. InICASSP 2025 - 2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP)(Hyderabad, India)(ICASSP ’25). IEEE, Piscataway, NJ, USA, 1–5. https://doi.org/1...
-
[71]
Huan Zhang, Jinhua Liang, and Simon Dixon. 2024. From Audio Encoders to Piano Judges: Benchmarking Performance Understanding for Solo Piano. InProceedings of the 25th International Society for Music Information Retrieval Conference(San Francisco, CA, USA and Online)(ISMIR ’24). International Society for Music Information Retrieval, San Francisco, CA, USA,...
2024
-
[72]
Katie Zhukov. 2009. Effective Practising: A Research Perspective.Australian Journal of Music Education43, 1 (2009), 3–12. https://files.eric.ed.gov/fulltext/ EJ912405.pdf
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.