Can Multi-Agent LLMs Identify Their Peers? Stylometric Fingerprinting in Role-Constrained Political Analysis
Pith reviewed 2026-06-30 17:40 UTC · model grok-4.3
The pith
LLMs can identify the originating model family of anonymized political texts via stylometric signals that survive prompt anonymization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
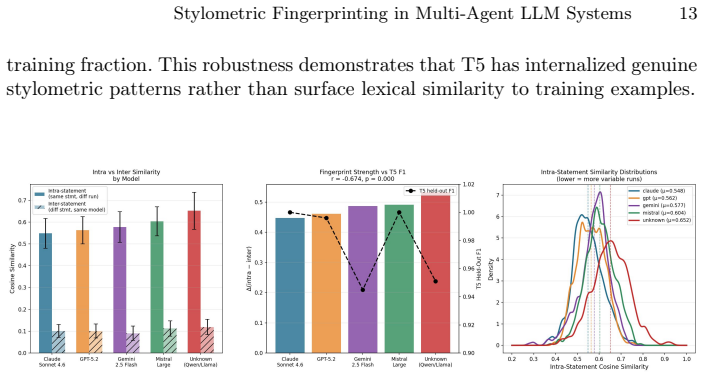
A fine-tuned T5-base classifier attributes anonymized political analysis texts to their source LLM family with Macro F1 of 0.991 under statement-disjoint cross-validation and F1 of 0.978 on 24 completely held-out statements. Performance remains high despite a statistically significant 2.1 times increase in content distance between training and test sets compared with a run-disjoint baseline, confirming that attribution relies on stylometric generalization rather than content leakage.
What carries the argument
The statement-disjoint cross-validation (SD-CV) protocol that partitions data so no individual statement appears in both training and validation folds while preserving role-constrained output style.
If this is right
- Prompt-level anonymization alone leaves model identity detectable in role-constrained political outputs.
- Multi-agent LLM pipelines for political analysis remain exposed to identity-dependent scoring distortions.
- Compliance with transparency and oversight rules such as EU AI Act Articles 13, 14 and 26 requires measures beyond anonymization.
Where Pith is reading between the lines
- Similar stylometric attribution may succeed in other constrained domains such as legal or medical report generation.
- System designers could add explicit style-suppression objectives during fine-tuning to reduce fingerprint strength.
- Validation protocols for multi-agent deployments might routinely include stylometric hold-out tests before production use.
Load-bearing premise
The statement-disjoint cross-validation protocol fully removes any possibility that high attribution scores come from shared content rather than writing style.
What would settle it
Retraining the T5 classifier on a new collection of political statements drawn from entirely different topics and sources while keeping the same anonymization prompts, then measuring whether Macro F1 remains above 0.95.
Figures


read the original abstract
Multi-agent large language model (LLM) pipelines for political statement analysis are vulnerable to peer-preservation bias: models tend to protect peer models from deactivation and show identity-dependent scoring distortions. Prompt-level anonymization was proposed as a mitigation, but prior work simultaneously documented that stylometric fingerprints survive anonymization in role-constrained outputs - raising the question of whether this mitigation is sufficient. This paper provides the first systematic investigation of whether LLMs can identify the model family behind political analysis texts under anonymization conditions. We evaluate three classifier approaches - LLM zero-shot and few-shot (Claude Sonnet 4.6 and Llama-3.3-70B) and a fine-tuned T5-base model - on a five-class attribution task covering four commercial LLM families and an open-world 'unknown' class. We introduce a statement-disjoint cross-validation protocol (SD-CV; defined in Section 3.5) that guarantees no content overlap between training and validation data, and contrast it with a run-disjoint baseline (RD-CV). T5 achieves Macro F1 = 0.991 (+-0.008) under SD-CV and F1 = 0.978 on 24 completely held-out statements - robust despite a 2.1x increase in train-test content distance versus RD-CV (0.767 vs. 0.366, p<0.001), demonstrating genuine stylometric generalization. A fractional SD-CV analysis identifies a performance knee at 40% of training data (~440 texts). Our findings confirm that prompt-level anonymization alone cannot neutralize model identity signals, with direct implications for EU AI Act compliance (Articles 13, 14, 26) and for computer system validation (CSV) in quality-critical multi-agent deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuned T5-base achieves Macro F1 of 0.991 (±0.008) under statement-disjoint cross-validation (SD-CV) and 0.978 on 24 held-out statements for five-class attribution of anonymized LLM-generated political texts, remaining robust despite a 2.1× increase in train-test content distance (0.767 vs. 0.366) relative to run-disjoint CV; this is taken to demonstrate genuine stylometric generalization beyond content leakage, with implications for multi-agent system design and EU AI Act compliance.
Significance. If the SD-CV protocol and distance metric adequately isolate stylometry, the result would establish that prompt-level anonymization is insufficient to remove model-family signals in role-constrained political analysis, directly affecting validation practices in quality-critical deployments. The fractional SD-CV analysis identifying a performance knee at ~40% training data (~440 texts) and the use of error bars with statistical significance testing add empirical value by quantifying data efficiency and robustness.
major comments (2)
- [Section 3.5] Section 3.5: The central claim that SD-CV produces 'genuine stylometric generalization' rests on the content distance metric showing a 2.1× increase while T5 retains high F1; however, the manuscript does not validate that this metric (whatever its exact formulation) is a tight proxy for semantic features an attribution model could exploit, such as shared argument structures, entity distributions, or topic-specific political phrasing across LLM outputs.
- [Section 3.5] Section 3.5 and results on held-out statements: The 24 completely held-out statements yielding F1=0.978 are load-bearing for the out-of-distribution generalization claim, yet no details are provided on whether their generation prompts, role constraints, or anonymization exactly match the SD-CV training distribution or whether any filtering/selection occurred post-generation.
minor comments (2)
- The abstract and Section 3.5 introduce SD-CV and RD-CV without an early, self-contained definition of the content distance metric itself, forcing readers to infer its construction from the reported values.
- The four commercial LLM families are referenced but not enumerated in the abstract or early methods overview, which would improve readability for the five-class task description.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Section 3.5] Section 3.5: The central claim that SD-CV produces 'genuine stylometric generalization' rests on the content distance metric showing a 2.1× increase while T5 retains high F1; however, the manuscript does not validate that this metric (whatever its exact formulation) is a tight proxy for semantic features an attribution model could exploit, such as shared argument structures, entity distributions, or topic-specific political phrasing across LLM outputs.
Authors: We acknowledge the point that the content distance metric requires clearer justification as a proxy. The metric is defined in Section 3.5 as the average cosine distance between sentence embeddings (from a fixed pre-trained encoder) of train and test statements. While this captures broad semantic divergence and correlates with the observed performance gap between RD-CV and SD-CV, it does not explicitly test for argument structures or entity distributions. In revision we will (a) provide the precise embedding model and aggregation formula, (b) add a short analysis comparing the metric to n-gram overlap and entity Jaccard similarity on the same splits, and (c) include a limitations paragraph noting that residual content leakage via higher-order features cannot be ruled out by distance alone. These changes clarify rather than overstate the evidence for stylometric generalization. revision: partial
-
Referee: [Section 3.5] Section 3.5 and results on held-out statements: The 24 completely held-out statements yielding F1=0.978 are load-bearing for the out-of-distribution generalization claim, yet no details are provided on whether their generation prompts, role constraints, or anonymization exactly match the SD-CV training distribution or whether any filtering/selection occurred post-generation.
Authors: The 24 held-out statements were produced with identical prompt templates, role constraints, and anonymization instructions as the SD-CV training data; generation occurred in a single additional run with no post-hoc filtering or selection. We will insert these procedural details into Section 3.5 and the dataset description to make the distributional match explicit. revision: yes
Circularity Check
No significant circularity; evaluation uses explicit held-out splits
full rationale
The paper reports classifier performance (Macro F1 0.991 under SD-CV, 0.978 on held-out statements) measured on statement-disjoint data with an independent content-distance metric. No step reduces a claimed prediction to a fitted parameter by construction, nor relies on self-citation chains or ansatzes imported from prior author work. The SD-CV protocol and distance comparison are defined externally to the model outputs, so the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stylometric signals in LLM-generated text are consistent enough to support family-level attribution even after anonymization prompts
Reference graph
Works this paper leans on
-
[1]
arXiv:2506.17323 (2025),https://arxiv.org/abs/2506.17323(accessed 11 May 2026)
Bisztray, T., et al.: Code stylometry for LLM authorship attribution. arXiv:2506.17323 (2025),https://arxiv.org/abs/2506.17323(accessed 11 May 2026)
-
[2]
Choi, H.K., Zhu, X., Li, S.: When identity skews debate: Anonymization for bias- reducedmulti-agentreasoning.arXiv:2510.07517(2025),https://arxiv.org/abs/ 2510.07517(accessed 11 May 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Dietrich, J.: From safety risk to design principle: Peer-preservation in multi-agent LLM systems and its implications for orchestrated democratic discourse analysis. arXiv:2604.08465 [cs.AI] (2026),https://arxiv.org/abs/2604.08465(accessed 11 May 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Dietrich, J.: Peer identity bias in multi-agent LLM evaluation: An empirical study using the TRUST pipeline. arXiv:2604.22971 [cs.AI] (2026),https://arxiv.org/ abs/2604.22971(accessed 11 May 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Dietrich, J.: When roles fail: Epistemic constraints on advocate role fidelity in LLM-based political statement analysis. arXiv:2604.27228 [cs.AI] (2026),https: //arxiv.org/abs/2604.27228(accessed 11 May 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Drug Safety48, 287–303 (2025)
Dietrich, J., Hollstein, A.: Performance and reproducibility of LLMs in named entity recognition. Drug Safety48, 287–303 (2025)
2025
-
[7]
Drug Safety46(8), 735–750 (2023)
Dietrich, J., Kazzer, P.: Fractional stratifiedk-fold cross-validation for training data sufficiency in computer system validation. Drug Safety46(8), 735–750 (2023)
2023
-
[8]
In: Proceedings of the 41st International Conference on Machine Learning (ICML 2024)
Du, Y., et al.: Improving factuality and reasoning through multiagent debate. In: Proceedings of the 41st International Conference on Machine Learning (ICML 2024). PMLR, vol. 235, pp. 11733–11763 (2024)
2024
-
[9]
European Parliament: Regulation (EU) 2024/1689 on artificial intelligence. Tech. rep., Official Journal of the European Union (2024),https://eur-lex.europa. eu/legal-content/EN/TXT/?uri=CELEX:32024R1689(accessed 11 May 2026)
2024
-
[10]
Proceedings of the National Academy of Sciences (2025)
Guo, M., et al.: Do LLMs write like humans? variation in grammatical and rhetor- ical styles. Proceedings of the National Academy of Sciences (2025)
2025
-
[11]
Journal of the American Society for Information Science and Technology 60(1), 9–26 (2009)
Koppel, M., Schler, J., Argamon, S.: Computational methods in authorship attri- bution. Journal of the American Society for Information Science and Technology 60(1), 9–26 (2009)
2009
-
[12]
Berkeley Center for Responsible Decentralized Intelligence, UC Berkeley / UC Santa Cruz (2026),https://rdi.berkeley.edu/blog/peer-preservation/ (accessed 11 May 2026)
Potter, Y., Crispino, N., Siu, V., Wang, C., Song, D.: Peer-preservation in frontier models. Berkeley Center for Responsible Decentralized Intelligence, UC Berkeley / UC Santa Cruz (2026),https://rdi.berkeley.edu/blog/peer-preservation/ (accessed 11 May 2026)
2026
-
[13]
Expert Systems with Applications296, 129001 (2026), arXiv:2507.00838 (accessed 11 May 2026)
Przystalski, K., Argasiński, J.K., Grabska-Gradzińska, I., Ochab, J.K.: Stylometry recognizes human and LLM-generated texts in short samples. Expert Systems with Applications296, 129001 (2026), arXiv:2507.00838 (accessed 11 May 2026)
-
[14]
Towards Understanding Sycophancy in Language Models
Sharma, M., et al.: Towards understanding sycophancy in language models. arXiv:2310.13548 (2023),https://arxiv.org/abs/2310.13548(accessed 11 May 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Raising the minimum wage to $20/hour will reduce poverty without significant job losses
Tihanyi, N., Cherif, B., Dubniczky, R.A., Ferrag, M.A., Bisztray, T.: The hid- den DNA of LLM-generated JavaScript: Structural patterns enable high-accuracy authorship attribution. arXiv:2510.10493 (2025),https://arxiv.org/abs/2510. 10493(accessed 11 May 2026) 20 J. Dietrich A Statement Dataset The complete set of 55 political statements used to generate ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.