NeoMap: Training-free Novel-View Synthesis from Single Images and Videos
Pith reviewed 2026-07-03 15:44 UTC · model grok-4.3
The pith
NeoMap finds high-fidelity novel views inside the manifold of any pre-trained video model by alternating projections on initial noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeoMap demonstrates that convergent manifold alternating projection iterations applied to initial noise can locate high-fidelity, view-consistent novel-view solutions that are already encoded inside the natural video data manifold of unmodified pre-trained models.
What carries the argument
convergent manifold alternating projection iterations that optimize the initial noise to locate solutions on the learned video manifold
Load-bearing premise
Promising novel-view solutions are already present inside the data manifold of any general pre-trained video model and can be found by alternating projections.
What would settle it
A controlled test in which the alternating-projection iterations produce lower fidelity or less consistent novel views than ordinary sampling from the same pre-trained model on the Tanks-and-Temples, LLFF, or DAVIS benchmarks.
Figures
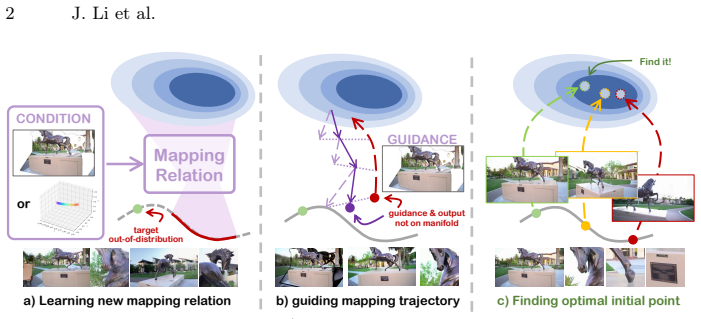
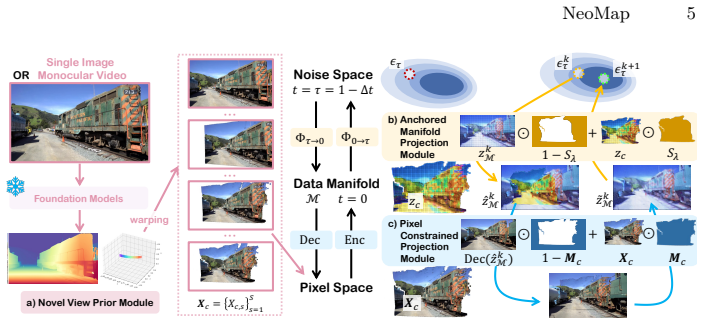








read the original abstract
We study the challenging problem of novel view video synthesis from single images or monocular videos. Existing methods, which operate under the assumption that pre-trained video models lack native novel view synthesis capability and enforce view alignment via camera conditioning, task-specific fine-tuning, or stepwise hard denoising guidance, often suffer from artifacts and compromised global scene consistency. In this paper, we introduce NeoMap, a novel training-free framework designed to locate high-fidelity, view-consistent novel view solutions from general pre-trained video models. The key to our approach is the core insight that promising novel view solutions are inherently encoded within the natural video data manifold learned by pre-trained models, and the core challenge is simply to locate this optimal solution. We solve this via our core mechanism: convergent manifold alternating projection iterations that optimize the initial noise. Extensive experiments demonstrate that NeoMap significantly outperforms all existing methods across 3 standard novel view synthesis benchmarks, including the challenging Tanks-and-Temples, LLFF and DAVIS datasets, achieving state-of-the-art generation fidelity and top-tier view consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeoMap, a training-free framework for novel-view video synthesis from single images or monocular videos. It claims that high-fidelity, view-consistent novel views are inherently encoded in the natural video data manifold of pre-trained models and can be located via convergent manifold alternating projection iterations that optimize the initial noise, without camera conditioning, fine-tuning, or hard denoising guidance. Extensive experiments are reported to show significant outperformance over existing methods on the Tanks-and-Temples, LLFF, and DAVIS benchmarks in generation fidelity and view consistency.
Significance. If the central claims hold with rigorous validation, the work would be significant for enabling training-free novel view synthesis that leverages existing video diffusion models directly, avoiding the artifacts and consistency issues of prior conditioning- or fine-tuning-based approaches. The parameter-free nature of the manifold projection mechanism (no free_parameters listed) and the focus on locating solutions already present in the model would be notable strengths if empirically supported.
major comments (2)
- [Abstract (core insight and mechanism)] The central claim that 'promising novel view solutions are inherently encoded within the natural video data manifold' for arbitrary (OOD) viewpoints is load-bearing but unsupported. Video models are trained on observed trajectories, and the alternating projection iterations provide no explicit mechanism (e.g., 3D consistency loss or multi-view conditioning) to ensure the target view lies on the manifold rather than producing temporally coherent but geometrically inconsistent outputs.
- [Abstract (experiments paragraph)] The outperformance claims on Tanks-and-Temples, LLFF, and DAVIS (including 'state-of-the-art generation fidelity and top-tier view consistency') cannot be assessed, as no method equations, quantitative results, ablation studies, or experimental details are provided to support them.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major point below with clarifications drawn from the full manuscript.
read point-by-point responses
-
Referee: [Abstract (core insight and mechanism)] The central claim that 'promising novel view solutions are inherently encoded within the natural video data manifold' for arbitrary (OOD) viewpoints is load-bearing but unsupported. Video models are trained on observed trajectories, and the alternating projection iterations provide no explicit mechanism (e.g., 3D consistency loss or multi-view conditioning) to ensure the target view lies on the manifold rather than producing temporally coherent but geometrically inconsistent outputs.
Authors: The manuscript (Section 3) explains that video diffusion models trained on diverse real-world trajectories learn a manifold that encodes 3D scene variations beyond observed paths; the convergent alternating projection iterations optimize initial noise to locate points on this manifold, with consistency emerging from the data distribution rather than explicit 3D losses. Experiments on Tanks-and-Temples and LLFF (which include significant viewpoint shifts) show geometrically consistent outputs, supporting the claim. We will add a short clarifying paragraph in the introduction to make this implicit mechanism more explicit. revision: partial
-
Referee: [Abstract (experiments paragraph)] The outperformance claims on Tanks-and-Temples, LLFF, and DAVIS (including 'state-of-the-art generation fidelity and top-tier view consistency') cannot be assessed, as no method equations, quantitative results, ablation studies, or experimental details are provided to support them.
Authors: The full manuscript contains the method equations and algorithm in Section 3, quantitative comparisons in Tables 1–3 on all three benchmarks, ablation studies in Section 4.2, and experimental details plus implementation specifics in the appendix. These directly support the reported outperformance. No changes are required on this point. revision: no
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central claim rests on an explicit modeling assumption (novel-view solutions lie on the pre-trained video manifold) followed by a proposed optimization procedure (manifold alternating projections on initial noise). No equations reduce a fitted parameter or output to an input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior author work. The approach is presented as training-free and uses off-the-shelf models, making the derivation independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Promising novel view solutions are inherently encoded within the natural video data manifold learned by pre-trained models
Reference graph
Works this paper leans on
-
[1]
CVPR (2025)
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. CVPR (2025)
2025
-
[2]
ICLR (2025)
Bahmani, S., Skorokhodov, I., Siarohin, A., Menapace, W., Qian, G., Vasilkovsky, M., Lee, H.Y., Wang, C., Zou, J., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Vd3d: Taming large video diffusion transformers for 3d camera control. ICLR (2025)
2025
-
[3]
ICCV (2025)
Bai, J., Xia, M., Fu, X., Wang, X., Mu, L., Cao, J., Liu, Z., Hu, H., Bai, X., Wan, P., Zhang, D.: Recammaster: Camera-controlled generative rendering from a single video. ICCV (2025)
2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
CVPR (2023)
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. CVPR (2023)
2023
-
[6]
CVPR (2025)
Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., Ryoo, M., Debevec, P., Yu, N.: Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise. CVPR (2025)
2025
-
[7]
ICCV (2023)
Ceylan, D., Huang, C.H., Mitra, N.J.: Pix2video: Video editing using image diffu- sion. ICCV (2023)
2023
-
[8]
ICCV (2023)
Chai, W., Guo, X., Wang, G., Lu, Y.: Stablevideo: Text-driven consistency-aware diffusion video editing. ICCV (2023)
2023
-
[9]
ICLR (2024)
Chang, P., Tang, J., Gross, M., Azevedo, V.C.: How i warped your noise: a temporally-correlated noise prior for diffusion models. ICLR (2024)
2024
-
[10]
ICML (2025)
Chefer, H., Singer, U., Zohar, A., Kirstain, Y., Polyak, A., Taigman, Y., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. ICML (2025)
2025
-
[11]
CVPR (2024)
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion models. CVPR (2024)
2024
-
[12]
arXiv preprint arXiv:2503.13265 (2025)
Chen, L., Zhou, Z., Zhao, M., Wang, Y., Zhang, G., Huang, W., Sun, H., Wen, J.R., Li, C.: Flexworld: Progressively expanding 3d scenes for flexiable-view synthesis. arXiv preprint arXiv:2503.13265 (2025)
-
[13]
TMLR (2024)
Couairon, P., Rambour, C., HAUGEARD, J.E., THOME, N.: Videdit: Zero-shot and spatially aware text-driven video editing. TMLR (2024)
2024
-
[14]
ICCV (2023)
Ge, S., Nah, S., Liu, G., Poon, T., Tao, A., Catanzaro, B., Jacobs, D., Huang, J.B., Liu, M.Y., Balaji, Y.: Preserve your own correlation: A noise prior for video diffusion models. ICCV (2023)
2023
-
[15]
ICLR (2024)
Geyer, M., Bar-Tal, O., Bagon, S., Dekel, T.: Tokenflow: Consistent diffusion fea- tures for consistent video editing. ICLR (2024)
2024
-
[16]
Human and Environment Friendly Robots with High Intelligence and Emotional Quotients (Cat
Goel, P.K., Roumeliotis, S.I., Sukhatme, G.S.: Robust localization using relative andabsolutepositionestimates.Proceedings1999IEEE/RSJInternationalConfer- ence on Intelligent Robots and Systems. Human and Environment Friendly Robots with High Intelligence and Emotional Quotients (Cat. No.99CH36289)2, 1134– 1140 vol.2 (1999),https://api.semanticscholar.org...
1999
-
[17]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
NeurIPS (2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS (2017)
2017
-
[21]
ICLR (2025)
Hou, C., Chen, Z.: Training-free camera control for video generation. ICLR (2025)
2025
-
[22]
arXiv preprint arXiv:2404.15789 (2024)
Hu, T., Zhang, J., Yi, R., Wang, Y., Huang, H., Weng, J., Wang, Y., Ma, L.: Motionmaster: Training-free camera motion transfer for video generation. arXiv preprint arXiv:2404.15789 (2024)
-
[23]
ViPE: Video Pose Engine for 3D Geometric Perception
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev,D.,Lin,C.H.,Ren,J.,Xie,K.,Biswas,J.,Leal-Taixe,L.,Fidler,S.:Vipe: Video pose engine for 3d geometric perception. arXiv preprint arXiv:2508.10934 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
CVPR (2024)
Huberman-Spiegelglas, I., Kulikov, V., Michaeli, T.: An edit friendly DDPM noise space: Inversion and manipulations. CVPR (2024)
2024
-
[25]
Jang, S., Ki, T., Jo, J., Yoon, J., Kim, S.Y., Lin, Z., Hwang, S.J.: Frame guidance: Training-freeguidanceforframe-levelcontrolinvideodiffusionmodel.ICLR(2026)
2026
-
[26]
TOG40(6), 1–12 (2021)
Kasten, Y., Ofri, D., Wang, O., Dekel, T.: Layered neural atlases for consistent video editing. TOG40(6), 1–12 (2021)
2021
-
[27]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[28]
ICCV (2023)
Khachatryan, L., Movsisyan, A., Tadevosyan, V., Henschel, R., Wang, Z., Navasardyan, S., Shi, H.: Text2video-zero: Text-to-image diffusion models are zero- shot video generators. ICCV (2023)
2023
-
[29]
CVPR (2025)
Kim, S., Suh, S., Lee, M.: Rad: Region-aware diffusion models for image inpainting. CVPR (2025)
2025
-
[30]
TOG36(4) (2017)
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and temples: Benchmarking large-scale scene reconstruction. TOG36(4) (2017)
2017
-
[31]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2405.17414 (2024)
Kuang, Z., Cai, S., He, H., Xu, Y., Li, H., Guibas, L., Wetzstein, G.: Collabora- tive video diffusion: Consistent multi-video generation with camera control. arXiv preprint arXiv:2405.17414 (2024)
-
[33]
arXiv preprint arXiv:2406.05338 (2024)
Ling, P., Bu, J., Zhang, P., Dong, X., Zang, Y., Wu, T., Chen, H., Wang, J., Jin, Y.: Motionclone: Training-free motion cloning for controllable video generation. arXiv preprint arXiv:2406.05338 (2024)
-
[34]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
NeurIPS (2022) 18 J
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. NeurIPS (2022) 18 J. Li et al
2022
-
[37]
CVPR (2022)
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Gool, L.V.: Repaint: Inpainting using denoising diffusion probabilistic models. CVPR (2022)
2022
-
[38]
TOG (2019)
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with prescrip- tive sampling guidelines. TOG (2019)
2019
-
[39]
ECCV (2020)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. ECCV (2020)
2020
-
[40]
arXiv preprint arXiv:2211.09794 (2022)
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text in- version for editing real images using guided diffusion models. arXiv preprint arXiv:2211.09794 (2022)
-
[41]
CVPR (2023)
Ni, H., Shi, C., Li, K., Huang, S.X., Min, M.R.: Conditional image-to-video gen- eration with latent flow diffusion models. CVPR (2023)
2023
-
[42]
ECCV (2024)
Pan, L., Barath, D., Pollefeys, M., Schönberger, J.L.: Global Structure-from- Motion Revisited. ECCV (2024)
2024
-
[43]
SIGGRAPH (2023)
Parmar, G., Singh, K.K., Zhang, R., Li, Y., Lu, J., Zhu, J.Y.: Zero-shot image-to- image translation. SIGGRAPH (2023)
2023
-
[44]
CVPR (2016)
Perazzi, F., Pont-Tuset, J., McWilliams, B., Gool, L.V., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. CVPR (2016)
2016
-
[45]
ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. ICML (2021)
2021
-
[46]
CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. CVPR (2022)
2022
-
[47]
arXiv preprint arXiv:2405.17251 (2024)
Seo, J., Fukuda, K., Shibuya, T., Narihira, T., Murata, N., Hu, S., Lai, C.H., Kim, S., Mitsufuji, Y.: Genwarp: Single image to novel views with semantic-preserving generative warping. arXiv preprint arXiv:2405.17251 (2024)
-
[48]
arXiv preprint arXiv:2506.01144 (2025)
Shaulov, A., Hazan, I., Wolf, L., Chefer, H.: Flowmo: Variance-based flow guidance for coherent motion in video generation. arXiv preprint arXiv:2506.01144 (2025)
-
[49]
CVPR (2026)
Song, C., Yang, Y., Zhao, T., Li, R., Zhang, C.: Taming video models for 3d and 4d generation via zero-shot camera control. CVPR (2026)
2026
-
[50]
CVPR (2023)
Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. CVPR (2023)
2023
-
[51]
Openreview (2019)
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation. Openreview (2019)
2019
-
[52]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
ICCV (2025)
Wang, H., Liu, Y., Liu, Z., Wang, W., Dong, Z., Yang, B.: Vistadream: Sampling multiview consistent images for single-view scene reconstruction. ICCV (2025)
2025
-
[54]
CVPR (2025) NeoMap 19
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. CVPR (2025) NeoMap 19
2025
-
[55]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[56]
SIGGRAPH pp
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. SIGGRAPH pp. 1–11 (2024)
2024
-
[57]
ICCV (2023)
Wu, C.H., la Torre, F.D.: A latent space of stochastic diffusion models for zero-shot image editing and guidance. ICCV (2023)
2023
-
[58]
ICLR (2025)
Xiao, Z., Ouyang, W., Zhou, Y., Yang, S., Yang, L., Si, J., Pan, X.: Trajectory attention for fine-grained video motion control. ICLR (2025)
2025
-
[59]
SIGGRAPH pp
Yang, S., Hou, L., Huang, H., Ma, C., Wan, P., Zhang, D., Chen, X., Liao, J.: Direct-a-video: Customized video generation with user-directed camera movement and object motion. SIGGRAPH pp. 1–12 (2024)
2024
-
[60]
ACM SIGGRAPH Asia Conference Proceedings (2023)
Yang, S., Zhou, Y., Liu, Z., Loy, C.C.: Rerender a video: Zero-shot text-guided video-to-video translation. ACM SIGGRAPH Asia Conference Proceedings (2023)
2023
-
[61]
ICLR (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. ICLR (2025)
2025
-
[62]
ICLR (2025)
You, M., Zhu, Z., Liu, H., Hou, J.: Nvs-solver: Video diffusion model as zero-shot novel view synthesizer. ICLR (2025)
2025
-
[63]
ICCV (2025)
Yu, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. ICCV (2025)
2025
-
[64]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. CVPR (2018)
2018
-
[66]
NeurIPS (2023)
Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. NeurIPS (2023)
2023
-
[67]
TMLR (2025)
Zheng, C., Lan, Y., Wang, Y.: Lanpaint: Training-free diffusion inpainting with asymptotically exact and fast conditional sampling. TMLR (2025)
2025
-
[68]
CVPR (2026) 20 J
Zhou, S., Wang, H., Cheng, H., Li, J., Wang, D., Jiang, J., Jin, Y., Huang, J., Mao, S., Liu, S., Yang, Y., Song, H., Wei, S., Zhang, Z., Huang, P., Liu, S., Hao, Z., Li, H., Li, Y., Zhou, W., Zhao, Z., He, Z., Wen, H., Huang, S., Yun, P., Cheng, B., Fu, P.K., Lai, W.K., Chen, J., Wang, K., Sun, Z., Li, Z., Hu, H., Zhang, D., Yuen, C.H., Wang, B., Wang, Z...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.