Lost in Fog: Sensor Perturbations Expose Reasoning Fragility in Driving VLAs
Pith reviewed 2026-06-30 16:51 UTC · model grok-4.3
The pith
Chain-of-Causation explanation consistency predicts trajectory reliability in driving VLAs under sensor perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
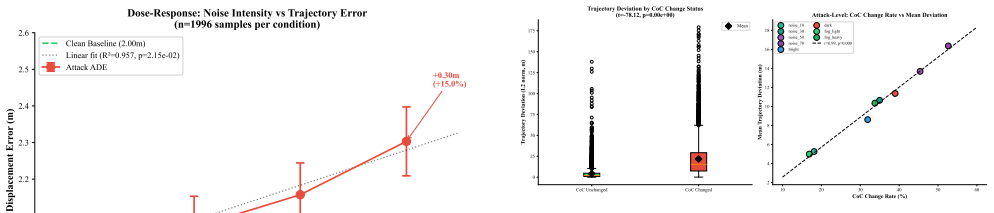
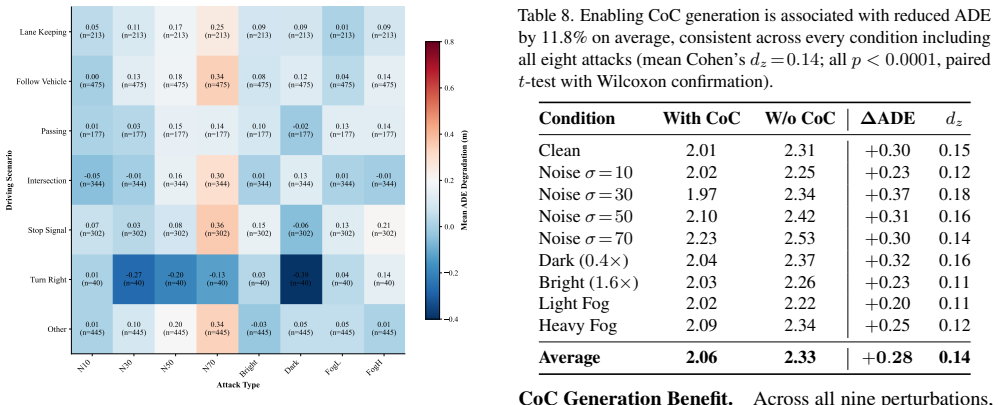
When Chain-of-Causation explanations change after perturbation, trajectory deviation spikes 5.3× (21.8m vs 4.1m), with r=0.99 across attack types and r_pb=0.53 per-sample. Enabling CoC generation improves trajectory accuracy by 11.8 percent on average. Over the tested noise range, degradation is approximately linear while standard input preprocessing provides only marginal relief.
What carries the argument
Chain-of-Causation (CoC) explanation consistency, used as a quantitative proxy that tracks whether planned trajectories remain reliable under sensor perturbation.
If this is right
- CoC consistency can serve as a runtime indicator of planning safety in VLA systems.
- Linear noise degradation implies failure modes become predictable within the tested intensity range.
- Reasoning-based monitoring offers a path to safer VLA deployment beyond current preprocessing defenses.
- Forcing CoC generation yields measurable accuracy gains even under matched inference budgets.
Where Pith is reading between the lines
- Real-time CoC monitoring could be added to existing VLA stacks without retraining the core planner.
- The approach may extend to other sensor-rich domains where explanation stability signals downstream reliability.
- Testing CoC consistency on additional VLA sizes and architectures would clarify how general the observed correlation is.
Load-bearing premise
The eight chosen sensor perturbations represent the degradations that matter for real-world autonomous driving safety.
What would settle it
A new perturbation set or model where CoC consistency remains high yet trajectory deviation still rises sharply, or where CoC changes but trajectories stay accurate.
Figures
read the original abstract
Interpretable autonomous driving planners depend not only on generating explanations, but also on those explanations remaining reliable under real-world sensor degradation. In this paper we present a controlled perturbation study of Vision-Language-Action (VLA) robustness in autonomous driving, evaluating Alpamayo R1 (10B parameters) across 1,996 scenarios under eight sensor perturbations (Gaussian noise at four intensities, two lighting extremes, and two fog levels; ${\sim}18{,}000$ inference trials). We find that reasoning consistency is a high-fidelity indicator of trajectory reliability: when Chain-of-Causation (CoC) explanations change after perturbation, trajectory deviation spikes $5.3{\times}$ (21.8m vs 4.1m), with $r\!=\!0.99$ across attack types and $r_{pb}\!=\!0.53$ per-sample (Cohen's $d\!=\!1.12$). A controlled ablation provides evidence that enabling CoC generation is associated with improved trajectory accuracy (11.8% on average across conditions; $p < 0.0001$) under matched inference settings. Over the tested noise range ($\sigma \in \{10, 30, 50, 70\}$), degradation is approximately linear ($R^2\!=\!0.957$), while standard input preprocessing defenses provide only marginal relief. Together, these results establish CoC consistency as a quantitative proxy for planning safety and motivate reasoning-based runtime monitoring for safer VLA deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled perturbation study of the Alpamayo R1 (10B) VLA model across 1,996 driving scenarios and ~18,000 inference trials under eight synthetic sensor perturbations (Gaussian noise at four intensities, two lighting extremes, two fog levels). It reports that changes in Chain-of-Causation (CoC) explanations after perturbation are associated with a 5.3× increase in trajectory deviation (21.8 m vs 4.1 m), with r=0.99 across attack types and r_pb=0.53 per sample (Cohen's d=1.12). A controlled ablation finds that enabling CoC generation improves trajectory accuracy by 11.8% on average (p<0.0001) under matched settings, with approximately linear degradation over the tested noise range (R²=0.957). The central claim is that CoC consistency provides a high-fidelity quantitative proxy for planning safety and motivates reasoning-based runtime monitoring.
Significance. If the empirical correlations and ablation hold under representative conditions, the work would supply a concrete, falsifiable link between explanation consistency and trajectory reliability in VLAs, offering a practical monitoring signal for deployment. The linear degradation result and marginal effect of standard preprocessing defenses are also useful for robustness engineering. However, the safety-proxy interpretation depends on an unverified assumption about perturbation coverage.
major comments (2)
- [Abstract / perturbation selection] Abstract and perturbation description: the claim that CoC consistency is a 'quantitative proxy for planning safety' is load-bearing on the representativeness of the eight synthetic perturbations (Gaussian noise σ∈{10,30,50,70}, lighting extremes, fog levels). No mapping to real logged sensor data, no coverage argument for omitted real-world artifacts (motion blur, lens flare, partial occlusions, compression artifacts), and no sensitivity analysis showing that the 5.3× deviation spike, r=0.99, and r_pb=0.53 persist under other degradations are provided. This leaves the safety-proxy conclusion internally valid but unsupported for deployment relevance.
- [Ablation study] Ablation results (abstract): the reported 11.8% accuracy improvement (p<0.0001) when enabling CoC generation is presented under 'matched inference settings,' but the abstract and available description do not confirm that all other generation parameters (temperature, sampling, prompt length) were held identical across the with/without-CoC conditions. This detail is required to rule out confounding factors in the causal attribution.
minor comments (2)
- [Abstract] Notation: the abstract uses r_pb without defining the point-biserial correlation in the main text; a brief parenthetical or footnote would improve clarity.
- [Results figures] Figure clarity: if trajectory deviation plots are shown, ensure error bars or per-sample scatter are visible to support the reported r=0.99 and Cohen's d=1.12.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our perturbations and the details of the ablation study. We address each major comment below, indicating revisions where appropriate to improve clarity and qualification of claims.
read point-by-point responses
-
Referee: [Abstract / perturbation selection] Abstract and perturbation description: the claim that CoC consistency is a 'quantitative proxy for planning safety' is load-bearing on the representativeness of the eight synthetic perturbations (Gaussian noise σ∈{10,30,50,70}, lighting extremes, fog levels). No mapping to real logged sensor data, no coverage argument for omitted real-world artifacts (motion blur, lens flare, partial occlusions, compression artifacts), and no sensitivity analysis showing that the 5.3× deviation spike, r=0.99, and r_pb=0.53 persist under other degradations are provided. This leaves the safety-proxy conclusion internally valid but unsupported for deployment relevance.
Authors: We agree that the safety-proxy claim depends on the tested perturbations and that the study provides no mapping to real logged sensor data, no explicit coverage argument for omitted artifacts such as motion blur or lens flare, and no sensitivity analysis for additional degradations. The experiments were intentionally scoped to these eight controlled synthetic perturbations to isolate reasoning effects. We will revise the abstract, introduction, and conclusion to qualify the proxy statement as holding under the evaluated conditions, and add a limitations section that explicitly notes the synthetic scope, lists the omitted real-world artifacts, and identifies validation on logged data as future work. This addresses the deployment-relevance concern without overstating the current results. revision: yes
-
Referee: [Ablation study] Ablation results (abstract): the reported 11.8% accuracy improvement (p<0.0001) when enabling CoC generation is presented under 'matched inference settings,' but the abstract and available description do not confirm that all other generation parameters (temperature, sampling, prompt length) were held identical across the with/without-CoC conditions. This detail is required to rule out confounding factors in the causal attribution.
Authors: All ablation trials used identical generation parameters across the with/without-CoC conditions: temperature fixed at 0.0, identical base prompt templates with only the CoC instruction added or removed, fixed top-p and top-k sampling, and the same maximum output length. We will expand the methods and results sections to list these parameters explicitly, confirming that the only controlled difference was the presence of CoC generation and thereby strengthening the causal attribution. revision: yes
Circularity Check
Empirical perturbation study exhibits no circularity in its reported findings.
full rationale
The manuscript reports direct experimental outcomes from running a fixed VLA model (Alpamayo R1) across 1,996 scenarios under eight synthetic perturbations, measuring trajectory deviation, CoC change rates, and ablation effects. All key statistics (5.3× deviation spike, r=0.99, r_pb=0.53, 11.8% accuracy lift, R²=0.957) are computed from observed trial data rather than derived from any equations or parameters that are defined in terms of the target quantities. No self-citations appear as load-bearing premises, no uniqueness theorems are invoked, and no ansatz or fitted inputs are relabeled as predictions. The derivation chain is therefore self-contained as a set of controlled measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Pearson correlation, point-biserial correlation, and two-sample statistical tests hold for the collected trajectory and explanation data.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2112.11561 (2024), revised 2024
Shahin Atakishiyev, Mohammad Salameh, Hengshuai Yao, and Randy Goebel. Explainable artificial intelligence for autonomous driving: A comprehensive overview and field guide for future research directions.arXiv preprint arXiv:2112.11561, 2021
-
[2]
End to End Learning for Self-Driving Cars
Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, et al. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car
Mariusz Bojarski, Philip Yeres, Anna Choromanska, Krzysztof Choromanski, Bernhard Firner, Lawrence Jackel, and Urs Muller. Explaining how a deep neural network trained with end-to-end learning steers a car.arXiv preprint arXiv:1704.07911, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[5]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gian- carlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gian- carlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[6]
Morley Mao
Yulong Cao, Chaowei Xiao, Benjamin Cyr, Yimeng Zhou, Won Park, Sara Rampazzi, Qi Alfred Chen, Kevin Fu, and Z. Morley Mao. Adversarial sensor attack on LiDAR-based perception in autonomous driving. InACM Conference on Computer and Communications Security (CCS), 2019
2019
-
[7]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InConference on Robot Learning (CoRL), 2017
2017
-
[8]
Robust physical-world attacks on deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[9]
Practical Poissonian-Gaussian noise model- ing and fitting for single-image raw-data.IEEE Transactions on Image Processing, 17(10):1737–1754, 2008
Alessandro Foi, Mejdi Trimeche, Vladimir Katkovnik, and Karen Egiazarian. Practical Poissonian-Gaussian noise model- ing and fitting for single-image raw-data.IEEE Transactions on Image Processing, 17(10):1737–1754, 2008
2008
-
[10]
Octo: An open-source generalist robot policy
Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS), 2024
2024
-
[11]
On robustness of vision-language-action model against multi-modal perturba- tions
Jianing Guo, Zhenhong Wu, Chang Tu, Yiyao Ma, Xiangqi Kong, Zhiqian Liu, Jiaming Ji, Shuning Zhang, Yuanpei Chen, Kai Chen, Qi Dou, Yaodong Yang, Xianglong Liu, Huijie Zhao, Weifeng Lv, and Simin Li. On robustness of vision-language-action model against multi-modal perturba- tions. InInternational Conference on Learning Representa- tions (ICLR), 2026
2026
-
[12]
Spencer Hallyburton, Yupei Liu, Yulong Cao, Z
R. Spencer Hallyburton, Yupei Liu, Yulong Cao, Z. Morley Mao, and Miroslav Pajic. Security analysis of camera-LiDAR fusion against black-box attacks on autonomous vehicles. In USENIX Security Symposium, 2022
2022
-
[13]
ISO/PAS 8800:2024 — road vehicles: Safety and arti- ficial intelligence
ISO. ISO/PAS 8800:2024 — road vehicles: Safety and arti- ficial intelligence. Publicly available specification, Interna- tional Organization for Standardization, Geneva, 2024
2024
-
[14]
Textual explanations for self-driving vehicles
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[15]
Dacheng Liao, Mengshi Qi, Peng Shu, Zhining Zhang, Yuxin Lin, Liang Liu, and Huadong Ma. RoboDriveVLM: A novel benchmark and baseline towards robust vision-language mod- els for autonomous driving.arXiv preprint arXiv:2512.01300, 2025
-
[16]
KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Yiyi Liao, Jun Xie, and Andreas Geiger. KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
2022
-
[17]
Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations
Hanqing Liu, Shouwei Ruan, Jiahuan Long, Junqi Wu, Ji- acheng Hou, Huili Tang, Tingsong Jiang, Weien Zhou, and Wen Yao. Eva-VLA: Evaluating vision-language-action mod- els’ robustness under real-world physical variations.arXiv preprint arXiv:2509.18953, 2025
-
[18]
Ecker, Matthias Bethge, and Wieland Brendel
Claudio Michaelis, Benjamin Mitzkus, Robert Geirhos, Evge- nia Rusak, Oliver Bringmann, Alexander S. Ecker, Matthias Bethge, and Wieland Brendel. Benchmarking robustness in object detection: Autonomous driving when winter is coming. arXiv preprint arXiv:1907.07484, 2019
-
[19]
Sun glare and road safety: An empirical investigation of intersection crashes.Safety Science, 70:246– 254, 2014
Sudeshna Mitra. Sun glare and road safety: An empirical investigation of intersection crashes.Safety Science, 70:246– 254, 2014
2014
-
[20]
Narasimhan and Shree K
Srinivasa G. Narasimhan and Shree K. Nayar. Vision and the atmosphere.International Journal of Computer Vision (IJCV), 48(3):233–254, 2002
2002
-
[21]
Model adaptation with synthetic and real data for semantic dense foggy scene understanding
Christos Sakaridis, Dengxin Dai, Simon Hecker, and Luc Van Gool. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[22]
Semantic foggy scene understanding with synthetic data.International Journal of Computer Vision (IJCV), 2018
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Semantic foggy scene understanding with synthetic data.International Journal of Computer Vision (IJCV), 2018
2018
-
[23]
Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data
Tim Salzmann, Boris Ivanovic, Punarjay Chakravarty, and Marco Pavone. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[24]
Albert Schotschneider, Svetlana Pavlitska, and J. Marius Z¨ollner. Runtime safety monitoring of deep neural networks for perception: A survey.arXiv preprint arXiv:2511.05982, 2025
-
[25]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beisswenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[26]
Physically realizable adversarial examples for LiDAR object detection
James Tu, Mengye Ren, Sivabalan Manivasagam, Ming Liang, Bin Yang, Richard Du, Frank Cheng, and Raquel Urtasun. Physically realizable adversarial examples for LiDAR object detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[27]
AugMax: Ad- versarial composition of random augmentations for robust training
Haotao Wang, Chaowei Xiao, Jean Kossaifi, Zhiding Yu, Anima Anandkumar, and Zhangyang Wang. AugMax: Ad- versarial composition of random augmentations for robust training. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2021
2021
-
[28]
Alpamayo-R1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail, 2025
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, et al. Alpamayo-R1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail, 2025
2025
-
[29]
Rethinking the open-loop evaluation of end-to- end autonomous driving in nuScenes, 2023
Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang- Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jing- dong Wang. Rethinking the open-loop evaluation of end-to- end autonomous driving in nuScenes, 2023
2023
-
[30]
Morley Mao
Qingzhao Zhang, Shengtuo Hu, Jiachen Sun, Qi Alfred Chen, and Z. Morley Mao. On adversarial robustness of trajectory prediction for autonomous vehicles. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15159–15168, 2022
2022
-
[31]
Visual Adversarial Attack on Vision-Language Models for Autonomous Driving
Tianyuan Zhang, Lu Wang, Xinwei Zhang, Yitong Zhang, Boyi Jia, Siyuan Liang, Shengshan Hu, Qiang Fu, Aishan Liu, and Xianglong Liu. Visual adversarial attack on vision- language models for autonomous driving.arXiv preprint arXiv:2411.18275, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.