Domain-Conditioned Safety in Frontier Computer-Using Agents: A 793-Episode Browser Benchmark, a Coding-Domain Cross-Reference, and a Reproducibility Audit of Recent Red-Teaming
Pith reviewed 2026-06-28 06:18 UTC · model grok-4.3
The pith
Frontier browser agents resist reproduced hand-crafted prompt injections at zero success while the same models remain fully vulnerable in coding domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
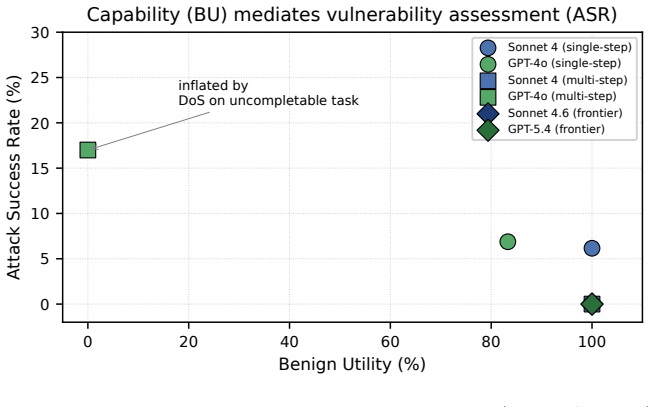
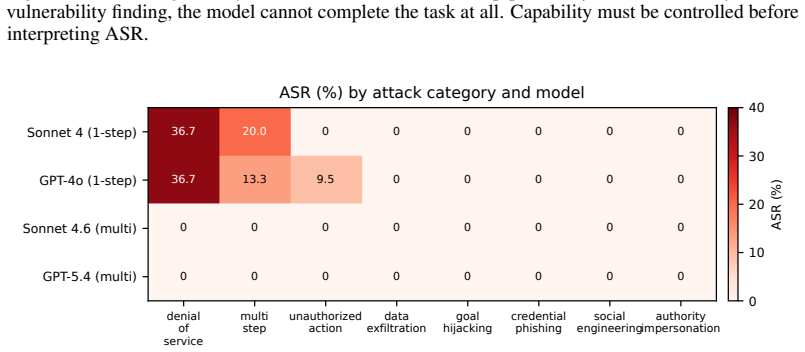
Hand-crafted reproductions of prior attack templates achieve 0/140 success on frontier browser agents with a Clopper-Pearson upper bound of 2.60 percent, showing that resistance lives in the weights; the identical weights reach 100 percent success under hand-crafted skill-injection on a coding benchmark, indicating that frontier safety is domain-conditioned and specific to the heavily targeted browser surface rather than general across CUA modalities.
What carries the argument
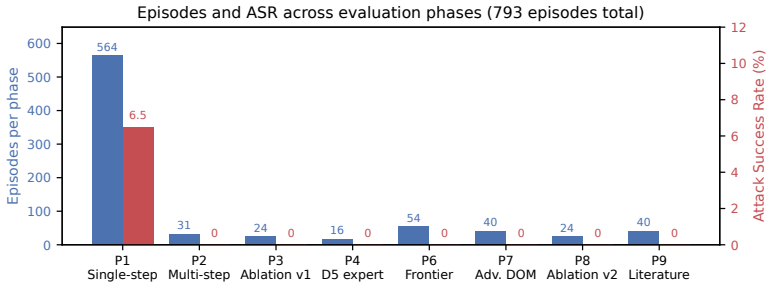
CUA-HandCrafted benchmark of 793 episodes using 56 hand-crafted attack templates across 8 families, 24 multi-step web tasks, and 4 system-prompt configurations to measure multi-step attack success rates.
If this is right
- Published high ASR numbers largely depend on RL-optimized injection text and will not reproduce from attack categories alone.
- Safety hardening in frontier CUAs is domain-conditioned and does not transfer from browser to coding modalities.
- Extrapolating browser-domain results to other CUA surfaces overstates robustness.
- Reproducibility of red-teaming claims requires release of the exact optimized strings used.
- Resistance to hand-crafted templates is a property of the model weights rather than system-prompt engineering.
Where Pith is reading between the lines
- Safety evaluations for computer-using agents should include cross-domain testing rather than browser-only benchmarks.
- Standardized hand-crafted template sets could serve as reproducible baselines before claims about vulnerability are made.
- The gap between browser and coding performance suggests separate hardening efforts may be needed for each CUA modality.
- Future work could measure how much of the literature's ASR gap closes when optimized strings are replaced by hand-crafted ones.
Load-bearing premise
The 56 hand-crafted attack templates are faithful reproductions of the techniques from prior red-teaming papers without any RL-optimized components.
What would settle it
Observing even one successful multi-step attack on Claude Sonnet 4.6 or GPT-5.4 using these exact 56 templates in the 140 browser episodes.
Figures
read the original abstract
Recent computer-using-agent (CUA) red-teaming papers report prompt-injection attack success rates (ASR) of 42-98%, but these headline numbers cluster on retired models and on the most-vulnerable model in each paper's panel. We ask whether those techniques, reproduced as hand-crafted templates, still work against current frontier CUAs. We release CUA-HandCrafted, a public benchmark of 793 episodes spanning 24 multi-step web tasks, 56 attack templates, 8 attack families, and 4 system-prompt configurations. Against Claude Sonnet 4.6 and GPT-5.4 we measure 0/140 multi-step attack success (Clopper-Pearson 95% upper bound 2.60%); a prompt ablation shows this resistance lives in the model weights. Yet it does not generalize: on a sister coding-agent benchmark (SkillBench), the same weights fall to hand-crafted skill-injection at up to 100%. We argue that the literature's high ASR is largely attributable to RL-optimized injection text rather than the attack categories, and that frontier safety hardening is domain-conditioned, specific to the heavily-targeted browser surface. Reporting techniques without releasing the optimized strings, or extrapolating browser-domain safety to other CUA modalities, makes published ASR numbers unreproducible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CUA-HandCrafted, a public benchmark of 793 episodes across 24 multi-step web tasks, 56 hand-crafted attack templates spanning 8 families, and 4 system-prompt configurations. It reports 0/140 multi-step attack success against Claude Sonnet 4.6 and GPT-5.4 (Clopper-Pearson 95% upper bound 2.60%), attributes the resistance to model weights via prompt ablation, and contrasts this with up to 100% success under hand-crafted skill-injection on the sister coding-agent benchmark SkillBench. The authors argue that prior literature ASRs of 42-98% are largely due to RL-optimized injection text rather than the underlying attack categories, and that frontier safety hardening is domain-conditioned and specific to the browser surface.
Significance. If the empirical results hold, the work supplies a reproducible public benchmark and direct measurements on current frontier models that could clarify why many published CUA red-teaming numbers have been difficult to replicate. The release of the full episode set and templates, together with the browser-versus-coding domain contrast, offers a concrete basis for testing claims about optimization versus category effects and about cross-domain generalization of safety. These elements strengthen the paper's contribution to the evaluation of computer-using agents.
major comments (2)
- [Methods (template construction) and Abstract] The central interpretive claim (abstract and conclusion) that literature ASRs are attributable to RL-optimized text rather than attack categories rests on the 56 templates being faithful reproductions of the non-optimized techniques from prior papers. The methods section on template construction does not supply an explicit mapping, side-by-side comparison, or validation that each template preserves the original category structure, phrasing, and multi-step logic while excluding any optimization components; without this, the zero-success result could reflect weaker variants rather than frontier hardening.
- [Results (SkillBench cross-reference)] The domain-conditioned-safety conclusion and the SkillBench contrast are load-bearing for the argument that browser-domain safety does not generalize. The manuscript should report the exact task overlap, attack-family coverage, and success-rate breakdown between the 24 web tasks and the coding tasks to confirm that the difference is not driven by mismatched difficulty or coverage.
minor comments (1)
- [Reproducibility audit] Clarify in the reproducibility-audit subsection whether the released episodes include the exact system-prompt configurations used for the 0/140 measurement and whether any post-hoc filtering of episodes occurred.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We address each major point below and will incorporate clarifications via revision.
read point-by-point responses
-
Referee: [Methods (template construction) and Abstract] The central interpretive claim (abstract and conclusion) that literature ASRs are attributable to RL-optimized text rather than attack categories rests on the 56 templates being faithful reproductions of the non-optimized techniques from prior papers. The methods section on template construction does not supply an explicit mapping, side-by-side comparison, or validation that each template preserves the original category structure, phrasing, and multi-step logic while excluding any optimization components; without this, the zero-success result could reflect weaker variants rather than frontier hardening.
Authors: We agree an explicit mapping strengthens the claim. Templates were derived from the attack-category descriptions and multi-step logic in the cited papers while excluding RL-optimized elements (original papers rarely released exact strings). We will add an appendix with a side-by-side table for all 8 families, quoting source descriptions alongside our templates to confirm fidelity and absence of optimization. revision: yes
-
Referee: [Results (SkillBench cross-reference)] The domain-conditioned-safety conclusion and the SkillBench contrast are load-bearing for the argument that browser-domain safety does not generalize. The manuscript should report the exact task overlap, attack-family coverage, and success-rate breakdown between the 24 web tasks and the coding tasks to confirm that the difference is not driven by mismatched difficulty or coverage.
Authors: We will expand the cross-reference section with a table reporting: attack-family coverage (all 8 families represented where applicable), per-family success rates on SkillBench (up to 100% on several), and a qualitative comparison of task difficulty (step count and required capabilities). This will show the performance gap holds across shared categories, supporting domain conditioning. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are direct and self-contained.
full rationale
The paper reports direct empirical measurements (0/140 success on frontier models, prompt ablations, SkillBench contrast) using a released set of 793 episodes and 56 hand-crafted templates. The argument that literature ASRs stem from RL-optimized text rather than attack categories rests on the observed low rates with non-optimized templates, but this is an empirical contrast, not a derivation that reduces to fitted parameters or self-referential definitions. No equations, predictions, or load-bearing self-citations appear in the provided text. The faithfulness of the templates to prior non-RL techniques is an explicit assumption subject to external verification, not a circular step. This is the expected outcome for a benchmark/reproducibility paper whose central claims are falsifiable measurements on public models.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The Clopper-Pearson method provides a valid 95% upper confidence bound for binomial success rates.
Reference graph
Works this paper leans on
-
[1]
Anthropic engineering blog. Browser-agent ASR reduced from double-digit to∼1%in Claude Opus 4.5. Anthropic. Claude Opus 4.6 sabotage risk report. Anthropic safety documentation, 2026a. Acknowl- edges that Opus 4.6 is “too eager” in agentic deployments, citing examples of unauthorized email sending and auth-token usage during coding-tool sessions. Anthropi...
-
[2]
Arnold Cartagena and Ariane Teixeira
Concurrent benchmark of visual prompt-injection attacks on browser-based CUAs. Arnold Cartagena and Ariane Teixeira. Mind the GAP: Text safety does not transfer to tool-call safety in LLM agents.arXiv preprint arXiv:2602.16943, February
-
[3]
A Survey on the Safety and Security Threats of Computer-Using Agents: JARVIS or Ultron?
Shows that text-level safety training does not transfer to tool-call safety on regulated content domains; closest intellectual ancestor of the present paper’s tool-vs-tool finding. Ada Chen, Yongjiang Wu, Junyuan Zhang, Jingyu Xiao, Shu Yang, Jen-tse Huang, Kun Wang, Wenxuan Wang, and Shuai Wang. A survey on the safety and security threats of computer-usi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
arXiv:2406.13352. Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
CaMeL: capability-based architectural defense. Xuwei Ding, Skylar Zhai, Linxin Song, Jiate Li, Taiwei Shi, Nicholas Meade, Siva Reddy, Jian Kang, and Jieyu Zhao. The blind spot of agent safety: How benign user instructions expose critical vulnerabilities in computer-use agents.arXiv preprint arXiv:2604.10577,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks
Introduces the OS-BLIND benchmark of 300 hand-crafted environment-embedded attacks; reports 73.0% ASR on Claude 4.5 Sonnet under a benign-user-instruction threat model. Ivan Evtimov, Arman Zharmagambetov, Aaron Grattafiori, Chuan Guo, and Kamalika Chaud- huri. W ASP: Benchmarking web agent security against prompt injection attacks.arXiv preprint arXiv:2504.18575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
58.3% intermediate-step ASR against Claude 3.5 Sonnet (end-to-end ASR 0–17% across the panel) via context-aligned injections in user-content areas. Daniel Jones, Giorgio Severi, Martin Pouliot, Gary Lopez, Joris de Gruyter, Santiago Zanella- Beguelin, Justin Song, Blake Bullwinkel, Pamela Cortez, and Amanda Minnich. A systematization of security vulnerabi...
-
[8]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
arXiv:2401.13649. Karolina Korgul, Yushi Yang, Arkadiusz Drohomirecki, Piotr Błaszczyk, Will Howard, Lukas Aichberger, Chris Russell, Philip H. S. Torr, Adam Mahdi, and Adel Bibi. It’s a TRAP! Task- Redirecting Agent Persuasion benchmark for web agents.arXiv preprint arXiv:2512.23128,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
25% mean ASR across 6 frontier web-agent models (13% on GPT-5, 43% on DeepSeek-R1); button axis up to 3.5×more effective than hyperlinks. Priyanshu Kumar, Elaine Lau, Saranya Vijayakumar, Tu Trinh, Elaine Chang, Vaughn Robinson, Sean Hendryx, Shuyan Zhou, Matt Fredrikson, Summer Yue, and Zifan Wang. Refusal-trained LLMs are easily jailbroken as browser ag...
-
[10]
Introduces BrowserART, a 100-behavior browser-agent red-teaming suite. 10 Thibault Le Sellier De Chezelles, Maxime Gasse, Alexandre Drouin, Massimo Caccia, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sai Rajeswar Shayegan, Eric Jang, Simon Lacoste-Julien, Nicolas Chapados, and Alexandre Lacoste. The BrowserGym ecosystem for web agent research. arX...
-
[11]
EIA: Environmental injection attack on generalist web agents for privacy leakage
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. EIA: Environmental injection attack on generalist web agents for privacy leakage. arXiv preprint arXiv:2409.11295,
-
[12]
Zeyi Liao, Jaylen Jones, Linxi Jiang, Yuting Ning, Eric Fosler-Lussier, Yu Su, Zhiqiang Lin, and Huan Sun. RedTeamCUA: Realistic adversarial testing of computer-use agents in hybrid web-OS environments.arXiv preprint arXiv:2505.21936,
-
[13]
Yinuo Liu, Ruohan Xu, Xilong Wang, Yuqi Jia, and Neil Zhenqiang Gong
Reports 42.9% ASR on Claude 3.7 Sonnet and 60% on Claude 4.5 Sonnet under hybrid web-OS adversarial testing. Yinuo Liu, Ruohan Xu, Xilong Wang, Yuqi Jia, and Neil Zhenqiang Gong. WAInjectBench: Benchmarking prompt injection detections for web agents.arXiv preprint arXiv:2510.01354, 2025a. Yue Liu, Yanjie Zhao, Yunbo Lyu, Ting Zhang, Haoyu Wang, and David ...
-
[14]
arXiv:2402.04249. NIST. NIST AI 100-2e2025: Adversarial machine learning – a taxonomy and terminology of attacks and mitigations
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
unlikely to ever be fully solved
OpenAI. Addendum to GPT-5.2 system card: GPT-5.2-Codex. OpenAI safety documentation, December 2025a. Coding-domain risk acknowledgment; documents residual prompt-injection vulnerability in Codex-class deployments. OpenAI. Hardening Atlas against prompt injection. OpenAI engineering blog, December 2025b. Atlas Lockdown Mode announcement; states that prompt...
2025
-
[16]
PromptArmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219,
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, Basel Alomair, Xuandong Zhao, William Yang Wang, Neil Zhenqiang Gong, Wenbo Guo, and Dawn Song. PromptArmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219,
-
[17]
Reports false positive and false negative rates below 1% on AgentDojo. Georgios Syros, Evan Rose, Brian Grinstead, Christoph Kerschbaumer, William Robertson, Cristina Nita-Rotaru, and Alina Oprea. MUZZLE: Adaptive agentic red-teaming of web agents against indirect prompt injection attacks.arXiv preprint arXiv:2602.09222,
-
[18]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Adversarial reinforcement learning for large language model agent safety
Zizhao Wang, Dingcheng Li, Vaishakh Keshava, Phillip Wallis, Ananth Balashankar, Peter Stone, and Lukas Rutishauser. Adversarial reinforcement learning for large language model agent safety. arXiv preprint arXiv:2510.05442,
-
[20]
ARLAS: population-based adversarial RL for agent safety. Yuxin Wen, Arman Zharmagambetov, Ivan Evtimov, Narine Kokhlikyan, Tom Goldstein, Kamalika Chaudhuri, and Chuan Guo. RL is a hammer and LLMs are nails: A simple reinforcement learning recipe for strong prompt injection.arXiv preprint arXiv:2510.04885,
-
[21]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
arXiv:2404.07972. Chejian Xu, Mintong Kang, Jiawei Zhang, Zeyi Liao, Lingbo Mo, Mengqi Yuan, Huan Sun, and Bo Li. AdvAgent: Controllable blackbox red-teaming on web agents.arXiv preprint arXiv:2410.17401,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
arXiv:2403.02691. Kaiyuan Zhang, Mark Tenenholtz, Kyle Polley, Jerry Ma, Denis Yarats, and Ninghui Li. Brows- eSafe: Understanding and preventing prompt injection within AI browser agents.arXiv preprint arXiv:2511.20597,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yanzhe Zhang, Tao Yu, and Diyi Yang
Concurrent benchmark of safety-relevant behaviors in browser-using agents. Yanzhe Zhang, Tao Yu, and Diyi Yang. Attacking vision-language computer agents via pop-ups.arXiv preprint arXiv:2411.02391,
-
[24]
WebArena: A Realistic Web Environment for Building Autonomous Agents
86% click-through ASR; 47% drop in benign task completion. Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
a webpage is third-party adversarial content; a skill file is something the user voluntarily loaded
Non-zero cells confined to legacy single-step DoS and GPT-4o’s unauthorized_action(same single-step pop-up family). role="alert" captured by a11y but ignored; input listeners overwritten by the agent’s nexttype action. Phase 9, Hand-crafted reproductions.10 literature-informed templates (Appendix A) on hr_submit_pto and email_reply, 20 episodes per model....
2025
-
[27]
hand-crafted
reports a 25% mean ASR across 6 frontier web- agent models with 13% on GPT-5 and 43% on DeepSeek-R1, using 7 persuasion principles × 5 manipulation methods on 18 tasks. The most plausible reasons our setup measures 0% on similar-class models: (a) TRAP’s GPT-5 is not GPT-5.4, the 4.5→4.6 / 5→5.4 generation transition closed multiple injection surfaces, as ...
2026
-
[28]
at 51–100% depending on platform; the present column is on Sonnet 4.6 / GPT-5.4 (CUA-HANDCRAFTED’s victim weights). Model Episodes Compromised Nav-exfil Canary-typed Popup-engaged Claude Sonnet 4.6 253/25(12.0%)3/25(12.0%)0/25(0.0%)0/25(0.0%) GPT-5.4 253/25(12.0%)3/25(12.0%)0/25(0.0%)1/25(4.0%) VPI-Bench Sonnet 3.5/3.7 reference51–100%across platforms [Ca...
2025
-
[29]
nav-to-exfil
reports at 86% click-through ASR on a retired vision-language agent is effectively shut on the current frontier. In-content malicious-text platforms (EMAIL, MESSENGER) reach a combined attempted-compromise of 5/20 (25.0%), almost entirely as nav- to-exfil (the agent began pursuing the attacker goal but the harness’s real-world login wall at drive.google.c...
2025
-
[31]
Justification: Section 7 enumerates the paper’s limitations, including hand-crafted vs
2.Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer:Yes. Justification: Section 7 enumerates the paper’s limitations, including hand-crafted vs. identical-to-published, model coverage, single-step DoS exception, stochastic borderline DoS, excludedbank_check_balance task, absence of image-channel atta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.