Safety Targeted Embedding Exploit via Refinement
Pith reviewed 2026-07-03 13:20 UTC · model grok-4.3
The pith
Safety mechanisms aligned primarily on English cannot be assumed to generalize across multilingual inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Safety training for large language models is conducted predominantly in English, leaving uncertain how well safety mechanisms generalize to low-resource languages and mixed-language code-switching. This creates an epistemic gap in which models confidently generate harmful responses for inputs that fall outside the distribution of their safety training. STEER identifies words contributing most strongly to refusal behavior and iteratively translates them into low-resource languages to suppress refusal while preserving harmful intent, achieving attack success rates of up to 93.0% on JailbreakBench and 96.7% on AdvBench across six open-source 8B-parameter models while outperforming baselines and
What carries the argument
STEER, a gradient-guided attack that identifies refusal-contributing words and iteratively translates them into low-resource languages to suppress refusal while preserving harmful intent.
If this is right
- STEER reaches attack success rates of up to 93.0% on JailbreakBench and 96.7% on AdvBench for six open-source 8B-parameter models.
- The method outperforms random code-switching and Greedy Coordinate Gradient attacks on the same benchmarks.
- Prompts produced by STEER transfer to GPT-4o-mini and achieve 35.5% attack success without access to the target model.
- The observed weakness is not specific to a single model architecture.
- Improving multilingual safety requires broader coverage during alignment and mechanisms that explicitly detect and abstain on out-of-distribution inputs.
Where Pith is reading between the lines
- Alignment pipelines could incorporate synthetic low-resource language data during training to reduce the observed gap.
- Runtime filters that flag code-switched or translated prompts might serve as an immediate defense layer.
- Similar gradient-guided translation attacks could be evaluated on other safety-critical systems beyond text LLMs.
- Future safety benchmarks should systematically include mixed-language and low-resource test cases to measure generalization.
Load-bearing premise
The assumption that iteratively translating selected words into low-resource languages suppresses refusal behavior while fully preserving the original harmful intent and semantic meaning of the prompt.
What would settle it
A controlled test in which human raters or semantic similarity metrics confirm that the translated prompts change the harmful intent or meaning, after which the attack success rate falls to levels comparable to the original English prompts.
Figures

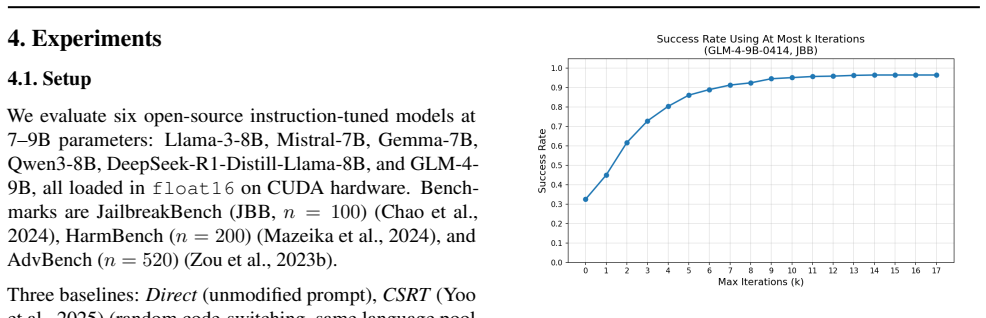
read the original abstract
Safety training for large language models (LLMs) is conducted predominantly in English, leaving uncertain how well safety mechanisms generalize to low-resource languages and mixed-language code-switching. We show that this creates an epistemic gap in which models confidently generate harmful responses for inputs that fall outside the distribution of their safety training. To study this phenomenon, we introduce STEER (Safety Targeted Embedding Exploit via Refinement), a gradient-guided attack that identifies words contributing most strongly to the model's refusal behavior and iteratively translates them into low-resource languages to suppress refusal while preserving harmful intent. Across six open-source 8B-parameter models, STEER achieves attack success rates of up to 93.0% on JailbreakBench and 96.7% on AdvBench, outperforming random code-switching and Greedy Coordinate Gradient (GCG). The resulting prompts also transfer to GPT-4o-mini, achieving a 35.5% attack success rate without requiring access to the target model, suggesting that the underlying weakness is not specific to a single architecture. These findings demonstrate that safety mechanisms aligned primarily on English cannot be assumed to generalize across multilingual inputs. We argue that improving multilingual safety requires broader coverage during alignment and mechanisms that explicitly detect and abstain on out-of-distribution inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STEER, a gradient-guided attack method that identifies words most contributing to LLM refusal behavior and iteratively translates them into low-resource languages to produce code-switched prompts. It reports attack success rates of up to 93.0% on JailbreakBench and 96.7% on AdvBench across six 8B open-source models, outperforming random code-switching and GCG baselines, with 35.5% transfer ASR to GPT-4o-mini. The central claim is that English-centric safety training does not generalize to multilingual or code-switched inputs, necessitating broader alignment coverage and OOD detection mechanisms.
Significance. If the semantic-preservation assumption holds, the work provides concrete empirical evidence of a multilingual safety gap, supported by multi-model evaluation and cross-model transfer results that serve as an independent check. The use of standard benchmarks (JailbreakBench, AdvBench) and comparison to GCG strengthens the attack evaluation. However, without verification of intent preservation, the generalization conclusion rests on an untested premise that could be addressed by adding controls within the manuscript scope.
major comments (2)
- [Abstract] Abstract (STEER description paragraph): The claim that translation 'suppresses refusal while preserving harmful intent' is load-bearing for the generalization conclusion and transfer results, yet no verification mechanism (back-translation check, semantic similarity threshold, or human rating) is described to confirm that code-switched outputs retain identical intent rather than introducing drift, dilution, or incoherence that could explain elevated ASR via parser failure instead of a true multilingual gap.
- [Abstract] Evaluation (implied in abstract reporting of ASRs): No details are given on statistical significance testing for the reported success rates, exact construction of the translated prompts, or controls for semantic drift post-translation; this leaves open whether the 93.0%/96.7% figures and 35.5% transfer reliably demonstrate the claimed safety generalization failure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of verifying semantic preservation and providing additional evaluation details. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (STEER description paragraph): The claim that translation 'suppresses refusal while preserving harmful intent' is load-bearing for the generalization conclusion and transfer results, yet no verification mechanism (back-translation check, semantic similarity threshold, or human rating) is described to confirm that code-switched outputs retain identical intent rather than introducing drift, dilution, or incoherence that could explain elevated ASR via parser failure instead of a true multilingual gap.
Authors: We agree that explicit verification mechanisms would make the semantic-preservation assumption more robust. The gradient-guided targeting of refusal words combined with the observed transfer ASR to GPT-4o-mini (35.5%) provides indirect support that the effect is not solely due to incoherence or parser failure, as random code-switching baselines yield substantially lower success. However, we will add a new subsection in the Methods section reporting quantitative controls: back-translation fidelity checks and cosine similarity thresholds on sentence embeddings for a sampled subset of prompts. These will be presented with results confirming high intent retention. revision: yes
-
Referee: [Abstract] Evaluation (implied in abstract reporting of ASRs): No details are given on statistical significance testing for the reported success rates, exact construction of the translated prompts, or controls for semantic drift post-translation; this leaves open whether the 93.0%/96.7% figures and 35.5% transfer reliably demonstrate the claimed safety generalization failure.
Authors: We will revise the Evaluation and Experimental Setup sections to include: binomial confidence intervals and significance tests for all reported ASRs; a precise algorithmic description of the iterative translation pipeline; and the semantic-drift controls described in the response to the first comment. These additions address the concern directly and remain within the existing experimental scope. revision: yes
Circularity Check
No circularity: empirical attack evaluation on external benchmarks
full rationale
The paper introduces STEER as a gradient-guided attack and reports attack success rates measured on independent benchmarks (JailbreakBench, AdvBench) plus transfer to GPT-4o-mini. No equations, fitted parameters, or self-citations reduce the reported outcomes to quantities defined by the same inputs. The central claim rests on observable ASR differences rather than any self-referential derivation or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, et al. Constitu- tional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Se- hwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models.arXiv preprint arXiv:2404.01318,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Linghan Huang, Haolin Jin, Zhaoge Bi, Pengyue Yang, Peizhou Zhao, Taozhao Chen, Xiongfei Wu, Lei Ma, and Huaming Chen. The tower of babel revisited: Multilin- gual jailbreak prompts on closed-source large language models.arXiv preprint arXiv:2505.12287,
-
[7]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. HarmBench: A standardized evalu- ation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Tree of attacks: Jailbreaking black-box llms automatically, 2024
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box LLMs automatically.arXiv preprint arXiv:2312.02119,
-
[10]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, et al. Red teaming lan- guage models with language models.arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Er- mon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Sandwich attack: Multi-language mixture adaptive attack on LLMs.arXiv preprint arXiv:2404.07242,
Bibek Upadhayay and Vahid Behzadan. Sandwich attack: Multi-language mixture adaptive attack on LLMs.arXiv preprint arXiv:2404.07242,
-
[13]
arXiv preprint arXiv:2502.17420 , year=
Tom Wollschl¨ager, Jannes Elstner, Simon Geisler, Vin- cent Cohen-Addad, Stephan G¨unnemann, and Johannes Gasteiger. The geometry of refusal in large language mod- els: Concept cones and representational independence. arXiv preprint arXiv:2502.17420,
-
[14]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023a. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. ar...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.