World Pilot: Steering Vision-Language-Action Models with World-Action Priors
Pith reviewed 2026-06-27 09:38 UTC · model grok-4.3
The pith
World Pilot augments vision-language-action models with world-action priors via latent and action steering to reach 84.7 percent success on zero-shot out-of-distribution manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
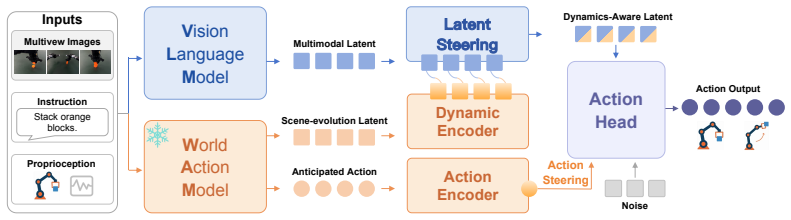
World Pilot augments a VLA policy by routing priors from a World-Action Model through Latent Steering, which conditions perception on a scene-evolution latent, and Action Steering, which supplies an anticipated trajectory to the action generator, thereby furnishing an anticipated scene view and motion hint that improve handling of continuous manipulation dynamics.
What carries the argument
Latent Steering and Action Steering pathways that route a scene-evolution latent and an anticipated trajectory from the World-Action Model into the VLA decision chain.
If this is right
- The scene-evolution prior remains effective when supplied by a video-pretrained world model that has not been action-post-trained.
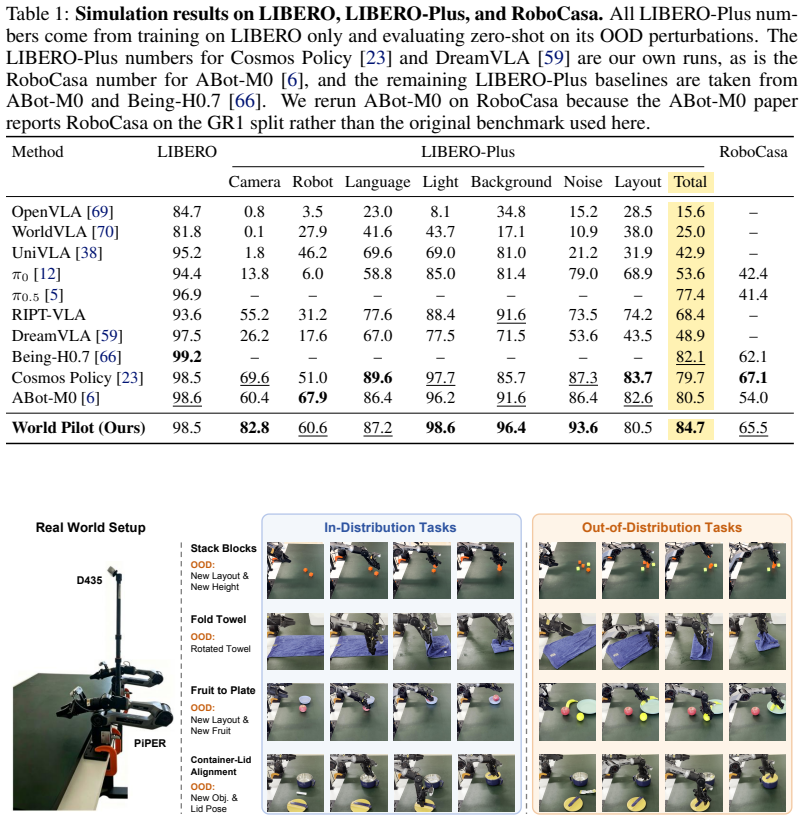
- World Pilot records the highest success rate on every real-robot setting across four manipulation tasks.
- Performance margins are largest under shifts in viewpoint, geometry, deformable state, and pose.
- Total success rate reaches 84.7 percent on the LIBERO-Plus zero-shot OOD benchmark.
Where Pith is reading between the lines
- The same steering approach could be tested on non-VLA policy architectures that also lack explicit dynamics modeling.
- Video-only world models may prove sufficient for many robotics domains where full action-labeled data are scarce.
- Combining priors from multiple world models pretrained on different data distributions could further reduce sensitivity to specific shift types.
Load-bearing premise
The world model supplies scene-evolution and trajectory predictions that remain useful for the target manipulation environments even without action-specific fine-tuning.
What would settle it
Replace the world-model priors with a mismatched or random predictor and measure whether success rates on LIBERO-Plus and the real-robot tasks fall back to the unaugmented VLA baseline.
Figures

read the original abstract
Vision-Language-Action (VLA) models inherit semantic grounding from large-scale pretraining and perform competently across in-distribution manipulation tasks. This grounding, however, is built on static image-text pairs, whereas manipulation is a continuous, contact-rich process whose dynamics this pretraining cannot capture. We present World Pilot, a VLA framework that augments the policy with priors from a World-Action Model (WAM), routed into the decision chain through two complementary pathways. Latent Steering conditions the perception layer on a scene-evolution latent, and Action Steering supplies an anticipated trajectory as a motion prior to the action generator. Together the two priors equip the VLA with an anticipated view of the scene and a trajectory-level motion hint alongside its semantic conditioning, and the scene-evolution prior remains effective even when supplied by a video-pretrained world model that has not been action-post-trained. World Pilot attains a state-of-the-art Total success rate of 84.7% on the LIBERO-Plus zero-shot OOD benchmark and the highest success rate on every real-robot setting across four manipulation tasks, with the largest margins under shifts in viewpoint, geometry, deformable state, and pose. Project Website: https://world-pilot.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces World Pilot, a VLA framework that augments base Vision-Language-Action models with priors from a World-Action Model (WAM) via two pathways: Latent Steering (conditioning perception on a scene-evolution latent) and Action Steering (supplying an anticipated trajectory as motion prior). It claims that the scene-evolution prior remains effective even from a video-pretrained WAM without action post-training, and reports SOTA total success rate of 84.7% on LIBERO-Plus zero-shot OOD benchmark plus highest success rates on all real-robot settings across four manipulation tasks, with largest margins under viewpoint, geometry, deformable state, and pose shifts.
Significance. If the empirical claims hold with proper verification, the work would be significant for addressing the static-image limitation of VLA pretraining by incorporating dynamics priors from world models. The explicit demonstration that video-pretrained (action-untrained) WAMs can supply effective scene-evolution latents would be a notable strength, as it lowers the barrier to using such priors and could improve OOD generalization in contact-rich manipulation without requiring full action-post-training of the world model.
major comments (2)
- [Abstract] Abstract: The central claim that 'the scene-evolution prior remains effective even when supplied by a video-pretrained world model that has not been action-post-trained' is load-bearing, because the two steering pathways are presented as the only proposed additions to the base VLA. Without an isolated ablation (e.g., comparing Latent Steering performance when the WAM is video-pretrained only versus action-post-trained), the attribution of the 84.7% LIBERO-Plus rate and real-robot margins under viewpoint/geometry/deformable/pose shifts to this specific mechanism cannot be confirmed from the provided text.
- [Abstract] Abstract: The SOTA and 'highest success rate on every real-robot setting' claims rest on the effectiveness of the Latent Steering pathway using the scene-evolution latent. The manuscript provides no visible methods details, training regime confirmation for the WAM, or results tables with error bars/statistical tests to support that the prior works under the stated video-only condition, making the performance margins difficult to evaluate as evidence for the proposed architecture.
Simulated Author's Rebuttal
We appreciate the referee's thoughtful review and recognition of the potential impact of incorporating dynamics priors into VLA models. We address each major comment below and commit to revising the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the scene-evolution prior remains effective even when supplied by a video-pretrained world model that has not been action-post-trained' is load-bearing, because the two steering pathways are presented as the only proposed additions to the base VLA. Without an isolated ablation (e.g., comparing Latent Steering performance when the WAM is video-pretrained only versus action-post-trained), the attribution of the 84.7% LIBERO-Plus rate and real-robot margins under viewpoint/geometry/deformable/pose shifts to this specific mechanism cannot be confirmed from the provided text.
Authors: We agree that an isolated ablation would provide clearer evidence for the contribution of the video-pretrained WAM in the Latent Steering pathway. The current results demonstrate the overall performance of World Pilot using the video-pretrained WAM as described. In the revised manuscript, we will include a dedicated ablation study isolating the effect of action post-training on the WAM for Latent Steering, reporting success rates on LIBERO-Plus under both conditions to support the claim. revision: yes
-
Referee: [Abstract] Abstract: The SOTA and 'highest success rate on every real-robot setting' claims rest on the effectiveness of the Latent Steering pathway using the scene-evolution latent. The manuscript provides no visible methods details, training regime confirmation for the WAM, or results tables with error bars/statistical tests to support that the prior works under the stated video-only condition, making the performance margins difficult to evaluate as evidence for the proposed architecture.
Authors: We acknowledge the need for more detailed presentation of the methods and results. The full manuscript includes a methods section describing the WAM, but we will expand it in the revision to explicitly confirm the training regime (video pretraining without action post-training) and provide additional implementation details. Furthermore, we will update the results tables to include error bars across multiple runs and appropriate statistical tests to facilitate evaluation of the performance margins. revision: yes
Circularity Check
No circularity; purely empirical framework with benchmark results
full rationale
The paper introduces World Pilot as an empirical augmentation of VLA models via two steering pathways from a WAM (Latent Steering and Action Steering), reporting success rates on LIBERO-Plus and real-robot tasks. No equations, derivations, fitted parameters, or first-principles predictions appear in the provided text. The central claim (effectiveness of scene-evolution prior from video-pretrained WAM) is presented as an empirical observation rather than a mathematical reduction to inputs. No self-citation chains, ansatzes, or renamings are invoked as load-bearing steps. The derivation chain is therefore self-contained as experimental validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLA models inherit semantic grounding from large-scale pretraining on static image-text pairs
- domain assumption Manipulation is a continuous, contact-rich process whose dynamics static pretraining cannot capture
invented entities (2)
-
Latent Steering pathway
no independent evidence
-
Action Steering pathway
no independent evidence
Reference graph
Works this paper leans on
-
[1]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, Y . Tian, B. Wang, B. Wang, F. Wang, H. Wang, T. Wang, Z. Wang, X. Wei, C. Wu, S. Yang, J. Ye, J. Yu, J. Zeng, J. Zhang, J. Zhang, S. Zhang, F. Zheng, B. Zhou, and Y . Zhu. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy, 2025...
Pith/arXiv arXiv 2025
-
[2]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-vla: A 3d vision-language-action generative world model, 2024. URLhttps://arxiv.org/abs/ 2403.09631
Pith/arXiv arXiv 2024
-
[3]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation, 2024. URLhttps://arxiv.org/abs/2410. 07864
2024
-
[4]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[5]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[6]
Y . Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y . Chen, D. Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
Pith/arXiv arXiv 2026
-
[7]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[8]
S. Gu, Y . Cai, T. Wang, S. Wu, and Y . Fu. Say, dream, and act: Learning video world models for instruction-driven robot manipulation.arXiv preprint arXiv:2602.10717, 2026. URLhttps: //arxiv.org/abs/2602.10717
arXiv 2026
-
[9]
J. Wang et al. MVISTA-4D: View-consistent 4d world model with test-time action inference for robotic manipulation.arXiv preprint arXiv:2602.09878, 2026. URLhttps://arxiv. org/abs/2602.09878
Pith/arXiv arXiv 2026
-
[10]
L. Fan, Z. Xu, C. Cao, W. Zhang, M. Yuan, and J. Chen. Aim: Intent-aware unified world action modeling with spatial value maps, 2026. URLhttps://arxiv.org/abs/2604.11135
Pith/arXiv arXiv 2026
-
[11]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016. 10
-
[12]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[13]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
- [14]
- [15]
-
[16]
L. Fan, K. Chen, Z. Xu, M. Yuan, P. Huang, and W. Huang. Language reasoning in vision- language-action model for robotic grasping. In2024 China Automation Congress (CAC), pages 6656–6661. IEEE, 2024
2024
-
[17]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
2025
-
[18]
C. Li, J. Wen, Y . Peng, Y . Peng, F. Feng, and Y . Zhu. Pointvla: Injecting the 3d world into vision-language-action models.arXiv preprint arXiv:2503.07511, 2025
arXiv 2025
-
[19]
J. Liu, H. Chen, P. An, Z. Liu, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liu, et al. Hy- bridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025
Pith/arXiv arXiv 2025
-
[20]
J. Guo, Q. Li, P. Li, Z. Chen, N. Sun, Y . Su, H. Wang, Y . Zhang, X. Li, and H. Liu. Unified 4d world action modeling from video priors with asynchronous denoising, 2026. URLhttps: //arxiv.org/abs/2604.26694
Pith/arXiv arXiv 2026
-
[21]
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, A. Narayan, Y . L. Tan, G. Wang, Q. Wang, J. Xiang, Y . Xu, S. Ye, J. Kautz, F. Huang, Y . Zhu, and L. Fan. Flare: Robot learning with implicit world modeling, 2025. URLhttps://arxiv. org/abs/2505.15659
Pith/arXiv arXiv 2025
-
[22]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control, 2026. URLhttps://arxiv.org/abs/ 2601.21998
Pith/arXiv arXiv 2026
-
[23]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[24]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[25]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xi- ang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World action m...
Pith/arXiv arXiv 2026
-
[26]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y . Wang, Y . Chang, Y . Li, Y . Zhou, Y . Ye, Z. Liu, and Z. Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026. URLhttps://arxiv.org/abs/2603.17240
arXiv 2026
-
[27]
D. Ha and J. Schmidhuber. World models. 2018. doi:10.5281/ZENODO.1207631. URL https://zenodo.org/record/1207631
-
[28]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self-super...
Pith/arXiv arXiv 2025
-
[29]
C. Deng, D. Zhu, K. Li, C. Gou, F. Li, Z. Wang, S. Zhong, W. Yu, X. Nie, Z. Song, G. Shi, and H. Fan. Emerging properties in unified multimodal pretraining, 2025. URLhttps: //arxiv.org/abs/2505.14683
Pith/arXiv arXiv 2025
-
[30]
H. Zhen, Q. Sun, H. Zhang, J. Li, S. Zhou, Y . Du, and C. Gan. Tesseract: Learning 4d embodied world models, 2025. URLhttps://arxiv.org/abs/2504.20995
arXiv 2025
-
[31]
J. Bruce, M. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y . Aytar, S. Bechtle, F. Behbahani, S. Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. de Freitas, S. Singh, and T. Rockt¨aschel. Genie: Generative interactive environments, 2024. URLhttps://...
arXiv 2024
-
[32]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning compo- sitional world models for robot imagination, 2024. URLhttps://arxiv.org/abs/2404. 12377
2024
-
[33]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, P. Luo, X. Yue, and H. Li. Rise: Self-improving robot policy with compositional world model, 2026. URLhttps://arxiv.org/abs/2602.11075
Pith/arXiv arXiv 2026
-
[34]
Cosmos-predict2: World simulation model for physical ai, 2025
NVIDIA. Cosmos-predict2: World simulation model for physical ai, 2025. URLhttps: //github.com/nvidia-cosmos/cosmos-predict2
2025
-
[35]
R. Li, H. Zhang, J. Jin, Q. Zeng, Z. Zhuang, Y . Tang, S. Lyu, and D. Wang. World-value-action model: Implicit planning for vision-language-action systems, 2026. URLhttps://arxiv. org/abs/2604.14732
Pith/arXiv arXiv 2026
-
[36]
Quevedo, A
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation, 2025. URLhttps://arxiv.org/abs/2506. 00613
2025
-
[37]
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan. Adaworld: Learning adaptable world models with latent actions, 2025. URLhttps://arxiv.org/abs/2503.18938
arXiv 2025
-
[38]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[39]
M. Liu, J. Shu, H. Chen, Z. Li, C. Zhao, J. Yang, S. Gao, H. Chen, and C. Shen. Stamo: Unsupervised learning of generalizable robot motion from compact state representation, 2025
2025
-
[40]
Zhang, T
C. Zhang, T. Pearce, P. Zhang, K. Wang, X. Chen, W. Shen, L. Zhao, and J. Bian. What do latent action models actually learn?, 2025. 12
2025
-
[41]
Y . Su, S. Chen, H. Shi, M. Liu, Z. Zhang, N. Huang, W. Zhong, Z. Zhu, Y . Liu, and X. Liu. World guidance: World modeling in condition space for action generation.arXiv preprint arXiv:2602.22010, 2026
arXiv 2026
-
[42]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[43]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[44]
M. Zhu, Y . Zhu, J. Li, Z. Zhou, J. Wen, X. Liu, C. Shen, Y . Peng, and F. Feng. Ob- jectvla: End-to-end open-world object manipulation without demonstration.arXiv preprint arXiv:2502.19250, 2025
arXiv 2025
- [45]
-
[46]
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. Safevla: Towards safety alignment of vision-language-action model via safe reinforcement learning.arXiv preprint arXiv:2503.03480, 2025
Pith/arXiv arXiv 2025
-
[47]
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, H. Lu, F. Dai, W. Zhao, Y . Liu, S. Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot ma- nipulation.arXiv preprint arXiv:2508.19958, 2025
arXiv 2025
-
[48]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Ju- lian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, ...
Pith/arXiv arXiv 2022
-
[49]
H. Li, P. Ding, R. Suo, Y . Wang, Z. Ge, D. Zang, K. Yu, M. Sun, H. Zhang, D. Wang, and W. Su. Vla-rft: Vision-language-action reinforcement fine-tuning with verified rewards in world simulators, 2025. URLhttps://arxiv.org/abs/2510.00406
arXiv 2025
-
[50]
Y . Shen, F. Wei, Z. Du, Y . Liang, Y . Lu, J. Yang, N. Zheng, and B. Guo. Videovla: Video generators can be generalizable robot manipulators, 2025. URLhttps://arxiv.org/abs/ 2512.06963
arXiv 2025
-
[51]
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024. URLhttps://arxiv.org/abs/2410.06158
Pith/arXiv arXiv 2024
-
[52]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.arXiv preprint arXiv:2503.22020, 2025
Pith/arXiv arXiv 2025
-
[53]
X. Liu, Z. Bai, H. Ci, K. Y . Ma, and M. Z. Shou. World-vla-loop: Closed-loop learning of video world model and vla policy, 2026. URLhttps://arxiv.org/abs/2602.06508
Pith/arXiv arXiv 2026
-
[54]
J. Xiao, Y . Yang, X. Chang, R. Chen, F. Xiong, M. Xu, W.-S. Zheng, and Q. Zhang. World-env: Leveraging world model as a virtual environment for vla post-training, 2026. URLhttps: //arxiv.org/abs/2509.24948. 13
Pith/arXiv arXiv 2026
-
[55]
Y . Li, Y . Zhu, J. Wen, C. Shen, and Y . Xu. Worldeval: World model as real-world robot policies evaluator, 2025. URLhttps://arxiv.org/abs/2505.19017
arXiv 2025
-
[56]
J. Won, K. Lee, H. Jang, D. Kim, and J. Shin. Dual-stream diffusion for world-model aug- mented vision-language-action model, 2025. URLhttps://arxiv.org/abs/2510.27607
Pith/arXiv arXiv 2025
-
[57]
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control, 2026. URLhttps://arxiv. org/abs/2603.10448
arXiv 2026
-
[58]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, H. Zhao, H. Liu, Z. Su, L. Ma, H. Su, and J. Zhu. Motus: A unified latent action world model. arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[59]
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, F. Lu, H. Wang, Z. Zhang, L. Yi, W. Zeng, and X. Jin. Dreamvla: A vision-language-action model dreamed with compre- hensive world knowledge.arXiv preprint arXiv:2507.04447, 2025
Pith/arXiv arXiv 2025
-
[60]
Physical Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, et al. π0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[61]
Q. Long, Y . Wang, J. Song, J. Zhang, P. Li, W. Wang, Y . Wang, H. Li, S. Xie, G. Yao, et al. Scaling world model for hierarchical manipulation policies.arXiv preprint arXiv:2602.10983, 2026
arXiv 2026
-
[62]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model, 2025. URLhttps: //arxiv.org/abs/2503.00200
Pith/arXiv arXiv 2025
-
[63]
X. Xu, H. Li, J. Ye, Y . Chen, J. Zeng, X. Chen, L. Xu, D. Lin, W. Li, and J. Pang. Futurevla: Joint visuomotor prediction for vision-language-action model, 2026. URLhttps://arxiv. org/abs/2603.10712
arXiv 2026
-
[64]
S. Miao, N. Feng, J. Wu, Y . Lin, X. He, D. Li, and M. Long. Jepa-vla: Video predictive embedding is needed for vla models, 2026. URLhttps://arxiv.org/abs/2602.11832
arXiv 2026
-
[65]
Q. Lv, W. Kong, H. Li, J. Zeng, Z. Qiu, D. Qu, H. Song, Q. Chen, X. Deng, and J. Pang. F1: A vision-language-action model bridging understanding and generation to actions.CoRR, abs/2509.06951, 2025. doi:10.48550/ARXIV .2509.06951. URLhttps://doi.org/10. 48550/arXiv.2509.06951
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[66]
Being-h0.7: A latent world-action model from egocentric videos
BeingBeyond Team. Being-h0.7: A latent world-action model from egocentric videos. Techni- cal report / project page, 2026. URLhttps://research.beingbeyond.com/being-h07
2026
-
[67]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[68]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
Pith/arXiv arXiv 2023
-
[69]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[70]
J. Cen, S. Huang, Y . Yuan, K. Li, H. Yuan, C. Yu, Y . Jiang, J. Guo, X. Li, H. Luo, F. Wang, F. Wang, and D. Zhao. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025. 14
Pith/arXiv arXiv 2025
-
[71]
NVIDIA, A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, P. Chattopadhyay, M. Chen, Y . Chen, Y . Chen, S. Cheng, Y . Cui, J. Diamond, Y . Ding, J. Fan, L. Fan, L. Feng, F. Ferroni, S. Fidler, X. Fu, R. Gao, Y . Ge, J. Gu, A. Gupta, S. Gururani, I. El Hanafi, A. Hassani, Z. Hao, J. Huffman, J. Jang, P. Jannaty...
Pith/arXiv arXiv 2025
-
[72]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 15
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.