sGPO: Trading Inference FLOPs for Training Efficiency in RLVR
Pith reviewed 2026-06-27 18:22 UTC · model grok-4.3
The pith
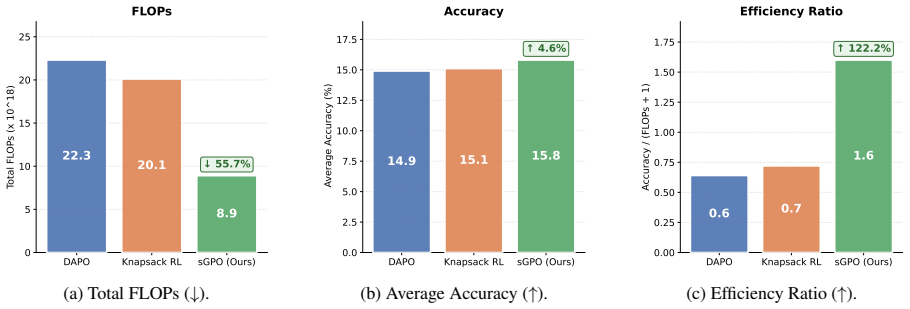
sGPO allocates RLVR rollout groups by the inverse of each query's initial success rate, cutting total compute by a factor of three.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
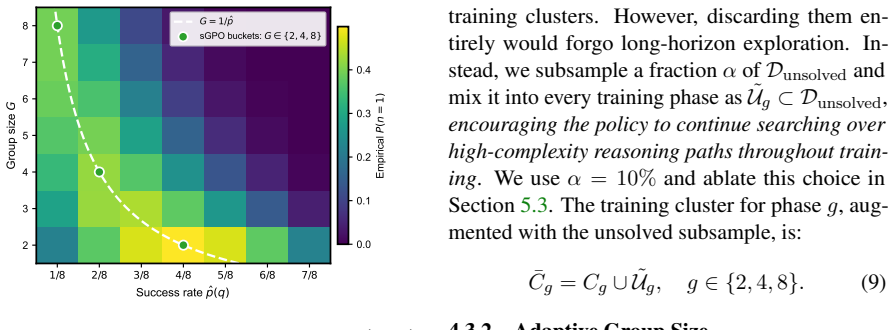
By running a fixed small batch of parallel samples under the initial policy, sGPO obtains an empirical success rate for every query that serves as a proxy for difficulty. It then applies the rule group_size = 1 / success_rate, which concentrates rollouts where they produce the largest advantage signal, while simultaneously filtering out trivial and unsolvable queries and constructing a curriculum by sorting on the same rates.
What carries the argument
sorted Group Policy Optimization (sGPO) that sets training rollout group size to the inverse of the initial-policy empirical success rate for each query.
If this is right
- Total training compute drops by a factor of three even after adding the cost of the initial profiling pass.
- Final model performance matches or exceeds the fixed-budget baseline.
- The same profiling pass supplies data filtering, adaptive group sizes, and curriculum ordering.
- Easy queries receive smaller groups so they stop wasting compute once solved; hard queries receive larger groups to increase the chance of obtaining a positive example.
Where Pith is reading between the lines
- If the success-rate ordering stays roughly stable, the method could be applied to other on-policy RL algorithms that rely on group rollouts.
- Re-profiling success rates at a few checkpoints might further improve efficiency if the policy changes rapidly.
- Extending the approach to estimate difficulty for new queries without full retraining could reduce the need for repeated profiling.
Load-bearing premise
The empirical success rate measured from a small batch of samples under the initial policy remains a stable and useful proxy for query difficulty throughout the entire training run.
What would settle it
Measuring success rates again after half the training steps and finding that many queries have moved from high to low success (or vice versa) would show that the fixed allocations no longer match actual difficulty.
Figures







read the original abstract
Standard Reinforcement Learning with Verifiable Rewards (RLVR) training allocates a fixed rollout budget to every query, without regard for what each query's difficulty means for the current policy. This leads to two symmetric failure modes: easy queries produce near-zero advantage because the policy already solves them, while unsolvable queries produce no signal because the policy never solves them. Both regimes waste training FLOPs without contributing to a learning gradient. We introduce sorted Group Policy Optimization (sGPO), a compute-efficient strategy that trades a small budget of inference FLOPs for a large reduction in wasted training FLOPs. The key insight is that cheap inference compute can serve as a single offline proxy for query difficulty. By generating a small batch of parallel samples per query under the initial policy, we obtain a model-aware empirical success rate. This motivates setting the training rollout group size to the inverse of this success rate, a practical rule that maximizes sample efficiency by extracting the most advantage per generated rollout. This single profiling pass simultaneously drives data filtering (removing trivial queries and sub-sampling unsolvable ones), adaptive group size allocation, and curriculum construction (scheduling queries from easy to hard). sGPO matches or exceeds baseline performance while reducing total training compute by a factor of three, with the upfront inference profiling cost included.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces sorted Group Policy Optimization (sGPO) for RLVR. It performs a single offline profiling pass under the initial policy to compute per-query empirical success rates, then fixes training rollout group sizes to the inverse of those rates (plus filtering of trivial/unsolvable queries and curriculum ordering). The central claim is that this trades a small inference cost for a 3× reduction in total training compute (including profiling) while matching or exceeding standard fixed-budget RLVR performance.
Significance. If the empirical results and stationarity assumption hold, sGPO provides a concrete, low-overhead method to reduce wasted FLOPs in RLVR by allocating rollouts according to model-aware difficulty. This is potentially significant for scaling verifiable-reward training, as it directly targets the symmetric waste on near-solved and unsolvable queries.
major comments (2)
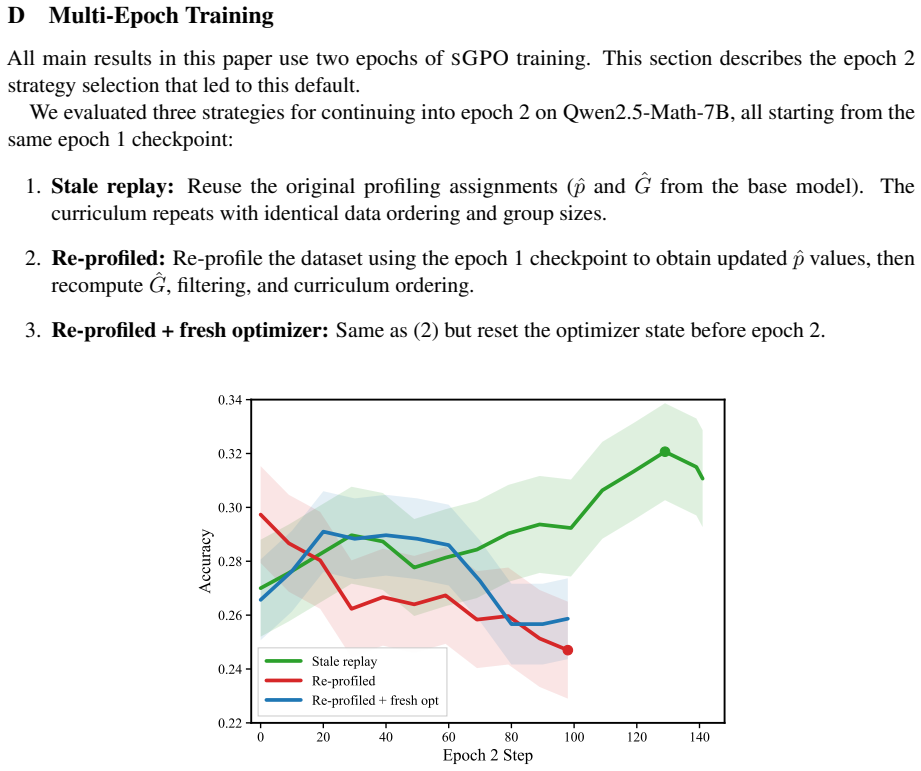
- [Method (profiling and allocation rule)] The fixed group_size = 1/p rule (p from initial-policy profiling) is load-bearing for the 3× training-FLOP claim, yet the manuscript supplies no ablation, correlation analysis, or re-profiling experiment showing that initial success rates remain stable proxies for query difficulty as the policy updates. The skeptic concern therefore lands: as success probabilities rise on previously marginal queries, both optimal group sizes and relative difficulty ordering can shift, potentially eroding the reported efficiency gain.
- [Abstract / Experiments] Abstract and results sections state the 3× total-compute reduction (profiling included) and performance parity, but the provided text supplies no concrete experimental details, baselines, number of runs, or error bars; without these the central efficiency claim cannot be assessed for robustness.
minor comments (1)
- [Method] Specify the exact profiling batch size, sampling temperature, and any post-processing used to compute the empirical success rate; this is listed as the sole free parameter but its sensitivity is not quantified.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and outline the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Method (profiling and allocation rule)] The fixed group_size = 1/p rule (p from initial-policy profiling) is load-bearing for the 3× training-FLOP claim, yet the manuscript supplies no ablation, correlation analysis, or re-profiling experiment showing that initial success rates remain stable proxies for query difficulty as the policy updates. The skeptic concern therefore lands: as success probabilities rise on previously marginal queries, both optimal group sizes and relative difficulty ordering can shift, potentially eroding the reported efficiency gain.
Authors: We acknowledge that the manuscript does not contain an explicit ablation or re-profiling study demonstrating the stability of the initial success-rate estimates as training progresses. The reported 3× efficiency gain is measured under the single initial profiling pass, and the empirical results show that this suffices to match or exceed baseline performance. However, to directly address the stationarity concern, we will add a new experiment in the revised version that re-profiles a subset of queries at multiple training checkpoints and measures how much the group-size allocation and ordering change. revision: yes
-
Referee: [Abstract / Experiments] Abstract and results sections state the 3× total-compute reduction (profiling included) and performance parity, but the provided text supplies no concrete experimental details, baselines, number of runs, or error bars; without these the central efficiency claim cannot be assessed for robustness.
Authors: We agree that the abstract and main results presentation should be more self-contained. The full experimental section of the manuscript does specify the baselines (standard GRPO with fixed group size), datasets, and compute accounting, but these details are not summarized in the abstract or highlighted with error bars in the submitted version. In the revision we will expand the abstract to include the key experimental parameters and ensure all reported figures and tables display error bars across the stated number of independent runs. revision: yes
Circularity Check
No significant circularity; derivation relies on independent empirical measurement
full rationale
The sGPO method performs an offline profiling pass that directly measures empirical success rate p from samples generated under the initial policy π₀. Group size is then set to 1/p as a heuristic rule motivated by maximizing advantage per rollout. This measurement is external to the training objective and does not reduce to a fitted parameter or self-referential definition within the training loop. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing steps in the provided description. The stationarity assumption on p is an empirical claim open to falsification rather than a definitional tautology. The central claim of compute reduction therefore rests on independent data collection and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- profiling batch size
axioms (1)
- domain assumption The success rate measured from a small batch of samples under the initial policy is a reliable proxy for query difficulty that justifies setting the training rollout group size to its inverse.
Reference graph
Works this paper leans on
-
[1]
Unifying Molecular and Textual Representations via Multi-task Language Modelling , author =
-
[2]
Solving quantitative reasoning problems with language models , author =
-
[3]
Chain of thought prompting elicits reasoning in large language models , author =
-
[4]
Multimodal chain-of-thought reasoning in language models , author =
-
[5]
Self-consistency improves chain of thought reasoning in language models , author =
-
[6]
Controllable Text Generation with Language Constraints , author =
-
[7]
Semantic supervision: Enabling generalization over output spaces , author =
-
[8]
V-STaR: Training Verifiers for Self-Taught Reasoners , author =
-
[9]
Advances in Neural Information Processing Systems , volume = 35, pages =
Star: Bootstrapping reasoning with reasoning , author =. Advances in Neural Information Processing Systems , volume = 35, pages =
-
[10]
Training Chain-of-Thought via Latent-Variable Inference , author =
-
[12]
Journal of Mechanical Design , volume = 114, number = 1, pages =
A New Graph Representation for the Automatic Kinematic Analysis of Planetary Spur-Gear Trains , author =. Journal of Mechanical Design , volume = 114, number = 1, pages =. doi:10.1115/1.2916916 , issn =
-
[13]
Journal of Mechanical Design , volume = 140, number = 1, doi =
New Graph Representation for Planetary Gear Trains , author =. Journal of Mechanical Design , volume = 140, number = 1, doi =
-
[14]
Journal of Computing and Information Science in Engineering , volume = 21, number = 2, doi =
An Image-Based Approach to Variational Path Synthesis of Linkages , author =. Journal of Computing and Information Science in Engineering , volume = 21, number = 2, doi =
-
[15]
Journal of Mechanical Design , volume = 144, number = 7, doi =
Deep Generative Models in Engineering Design: A Review , author =. Journal of Mechanical Design , volume = 144, number = 7, doi =
-
[16]
doi:10.1115/DETC2013-13058 , url =
Topology Optimization of Fluid Channels Using Generative Graph Grammars , author =. doi:10.1115/DETC2013-13058 , url =
-
[17]
doi:10.1115/DETC2014-35652 , url =
Graph Based Representation and Analyses for Conceptual Stages , author =. doi:10.1115/DETC2014-35652 , url =
-
[18]
doi:10.1115/DETC2016-59404 , url =
Deep Network-Based Feature Extraction and Reconstruction of Complex Material Microstructures , author =. doi:10.1115/DETC2016-59404 , url =
-
[19]
doi:10.1115/DETC2018-85529 , url =
Kinematic Synthesis Using Reinforcement Learning , author =. doi:10.1115/DETC2018-85529 , url =
-
[20]
doi:10.1115/DETC2019-97711 , url =
Reinforcement Learning Content Generation for Virtual Reality Applications , author =. doi:10.1115/DETC2019-97711 , url =
-
[21]
doi:10.1115/DETC2020-22355 , url =
Graph Representation of 3D CAD Models for Machining Feature Recognition With Deep Learning , author =. doi:10.1115/DETC2020-22355 , url =
-
[22]
doi:10.1115/DETC2020-22624 , url =
Multi-Context Generation in Virtual Reality Environments Using Deep Reinforcement Learning , author =. doi:10.1115/DETC2020-22624 , url =
-
[23]
A 99 Line Topology Optimization Code Written in Matlab , author =. Struct. Multidiscip. Optim. , publisher =. doi:10.1007/s001580050176 , issn =
-
[24]
Gradio: Hassle-free sharing and testing of ml models in the wild , author =
-
[25]
Composite Structures , volume = 227, pages = 111264, doi =
Prediction and optimization of mechanical properties of composites using convolutional neural networks , author =. Composite Structures , volume = 227, pages = 111264, doi =
-
[26]
Topology optimization of 2D structures with nonlinearities using deep learning , author =. Computers. doi:10.1016/j.compstruc.2020.106283 , issn =
-
[27]
The Journal of Machine Learning Research , publisher =
Emergence of invariance and disentanglement in deep representations , author =. The Journal of Machine Learning Research , publisher =
-
[28]
IEEE transactions on pattern analysis and machine intelligence , publisher =
Information dropout: Learning optimal representations through noisy computation , author =. IEEE transactions on pattern analysis and machine intelligence , publisher =
-
[29]
Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr
Life-Long Disentangled Representation Learning with Cross-Domain Latent Homologies , author =. Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr
2018
-
[30]
A neural dynamics model for structural optimization—Theory , author =. Computers. doi:10.1016/0045-7949(95)00048-L , issn =
-
[31]
Neural Networks , volume = 8, number = 5, pages =
Optimization of space structures by neural dynamics , author =. Neural Networks , volume = 8, number = 5, pages =. doi:10.1016/0893-6080(95)00026-V , issn =
-
[32]
The affNIST dataset , author =
-
[33]
Proceedings of seventh international conference on bio-inspired computing: theories and applications (BIC-TA 2012) , pages =
Constructive solid geometry based topology optimization using evolutionary algorithm , author =. Proceedings of seventh international conference on bio-inspired computing: theories and applications (BIC-TA 2012) , pages =
2012
-
[34]
International Design Engineering Technical Conferences and Computers and Information in Engineering Conference , volume = 50190, pages =
Discovering diverse, high quality design ideas from a large corpus , author =. International Design Engineering Technical Conferences and Computers and Information in Engineering Conference , volume = 50190, pages =
-
[35]
Advances in Neural Information Processing Systems , volume = 34, pages =
Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text , author =. Advances in Neural Information Processing Systems , volume = 34, pages =
-
[36]
Comptes Rendus Mathematique , publisher =
A level-set method for shape optimization , author =. Comptes Rendus Mathematique , publisher =
-
[37]
Comptes Rendus Mathematique , volume = 334, number = 12, pages =
A level-set method for shape optimization , author =. Comptes Rendus Mathematique , volume = 334, number = 12, pages =. doi:10.1016/S1631-073X(02)02412-3 , issn =
-
[38]
Gradient flows: in metric spaces and in the space of probability measures , author =
-
[40]
Proceedings of the National Academy of Sciences , publisher =
Shifter circuits: a computational strategy for dynamic aspects of visual processing , author =. Proceedings of the National Academy of Sciences , publisher =
-
[41]
Structural and Multidisciplinary Optimization , volume = 43, number = 1, pages =
Efficient topology optimization in MATLAB using 88 lines of code , author =. Structural and Multidisciplinary Optimization , volume = 43, number = 1, pages =. doi:10.1007/s00158-010-0594-7 , issn =
-
[42]
Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain , pages =
Learning to learn by gradient descent by gradient descent , author =. Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain , pages =
2016
-
[43]
Hyperprior Induced Unsupervised Disentanglement of Latent Representations , author =. The Thirty-Third. doi:10.1609/aaai.v33i01.33013175 , url =
-
[44]
Representation learning in sensory cortex: a theory , author =
-
[45]
Towards principled methods for training generative adversarial networks , author =
-
[46]
International conference on machine learning , pages =
Wasserstein generative adversarial networks , author =. International conference on machine learning , pages =
-
[47]
Article title , author =. Journal
-
[48]
6th International Conference on Learning Representations,
Latent Space Oddity: on the Curvature of Deep Generative Models , author =. 6th International Conference on Learning Representations,
-
[49]
KNN-Diffusion: Image Generation via Large-Scale Retrieval , author =
-
[50]
ASME , year = 2003, address =
2003
-
[51]
Structural and Multidisciplinary Optimization , publisher =
Two-stage convolutional encoder-decoder network to improve the performance and reliability of deep learning models for topology optimization , author =. Structural and Multidisciplinary Optimization , publisher =. doi:10.1007/s00158-020-02788-w , issn =
-
[52]
Mathieu Aubry and Daniel Maturana and Alexei A. Efros and Bryan C. Russell and Josef Sivic , year = 2014, booktitle =. Seeing 3D Chairs: Exemplar Part-Based 2D-3D Alignment Using a Large Dataset of. doi:10.1109/CVPR.2014.487 , url =
-
[53]
Evolutionary generation of neural network update signals for the topology optimization of structures , author =. Proceedings of the 15th annual conference companion on Genetic and evolutionary computation , publisher =. doi:10.1145/2464576.2464685 , isbn = 9781450319645, url =
-
[54]
TOPOLOGY OPTIMIZATION BY PREDICTING SENSITIVITIES BASED ON LOCAL STATE FEATURES , author =
-
[55]
Applications of Evolutionary Computation , author =. Applications of Evolutionary Computation, 18th European Conference, EvoApplications 2015, Copenhagen, Denmark, April 8–10, 2015 , publisher =. doi:10.1007/978-3-319-16549-3 , isbn =
-
[56]
Structured denoising diffusion models in discrete state-spaces , author =
-
[57]
Nature Communications , volume = 11, number = 1, pages = 2735, doi =
Closing the gap towards super-long suspension bridges using computational morphogenesis , author =. Nature Communications , volume = 11, number = 1, pages = 2735, doi =
-
[58]
3rd International Conference on Learning Representations,
Neural Machine Translation by Jointly Learning to Align and Translate , author =. 3rd International Conference on Learning Representations,
-
[59]
doi:10.1007/978-3-030-32644-9 , isbn =
Recent Trends and Advances in Artificial Intelligence and Internet of Things , author =. doi:10.1007/978-3-030-32644-9 , isbn =
-
[60]
Banerjee, Satanjeev and Lavie, Alon , year = 2005, month = jun, booktitle =
2005
-
[61]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages =
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author =. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages =
-
[62]
Preprint , url =
3D Topology Optimization using Convolutional Neural Networks , author =. Preprint , url =
-
[63]
Beit: Bert pre-training of image transformers , author =
-
[64]
Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models , author =
-
[65]
Label-Efficient Semantic Segmentation with Diffusion Models , author =
-
[66]
IEEE Transactions on Magnetics , publisher =
A Deep Learning Surrogate Model for Topology Optimization , author =. IEEE Transactions on Magnetics , publisher =. doi:10.1109/TMAG.2021.3063470 , issn =
-
[67]
Elements of Green's functions and propagation: potentials, diffusion, and waves , author =
-
[68]
International Conference on Artificial Intelligence and Statistics,
Few-shot Generative Modelling with Generative Matching Networks , author =. International Conference on Artificial Intelligence and Statistics,
-
[69]
ArXiv preprint , volume =
Relational inductive biases, deep learning, and graph networks , author =. ArXiv preprint , volume =
-
[70]
Learning stochastic recurrent networks , author =
-
[71]
Computer-Aided Design , publisher =
Real-Time Topology Optimization in 3D via Deep Transfer Learning , author =. Computer-Aided Design , publisher =. doi:10.1016/j.cad.2021.103014 , issn =
-
[72]
Computer-Aided Design , volume = 135, pages = 103014, doi =
Real-Time Topology Optimization in 3D via Deep Transfer Learning , author =. Computer-Aided Design , volume = 135, pages = 103014, doi =
-
[73]
Computer-Aided Design , publisher =
Real-time topology optimization in 3d via deep transfer learning , author =. Computer-Aided Design , publisher =
-
[74]
Journal of Mechanical Design , pages =
GANTL: Towards Practical and Real-Time Topology Optimization with Conditional GANs and Transfer Learning , author =. Journal of Mechanical Design , pages =. doi:10.1115/1.4052757 , issn =
-
[75]
Computer methods in applied mechanics and engineering , publisher =
Generating optimal topologies in structural design using a homogenization method , author =. Computer methods in applied mechanics and engineering , publisher =
-
[76]
Structural Optimization , volume = 1, number = 4, pages =
Optimal shape design as a material distribution problem , author =. Structural Optimization , volume = 1, number = 4, pages =. doi:10.1007/BF01650949 , issn =
-
[77]
Structural optimization , publisher =
Optimal shape design as a material distribution problem , author =. Structural optimization , publisher =
-
[78]
Topology optimization: theory, methods, and applications , author =
-
[79]
Computer Methods in Applied Mechanics and Engineering , volume = 71, number = 2, pages =
Generating optimal topologies in structural design using a homogenization method , author =. Computer Methods in Applied Mechanics and Engineering , volume = 71, number = 2, pages =. doi:10.1016/0045-7825(88)90086-2 , issn =
-
[80]
Foundations and trends
Learning deep architectures for AI , author =. Foundations and trends
-
[81]
IEEE transactions on pattern analysis and machine intelligence , publisher =
Representation learning: A review and new perspectives , author =. IEEE transactions on pattern analysis and machine intelligence , publisher =
-
[82]
Partial differential equations , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.