Ego-Pi: VLA Fine-Tuning for Ego-Centric Human and Robot Data
Pith reviewed 2026-06-27 19:29 UTC · model grok-4.3
The pith
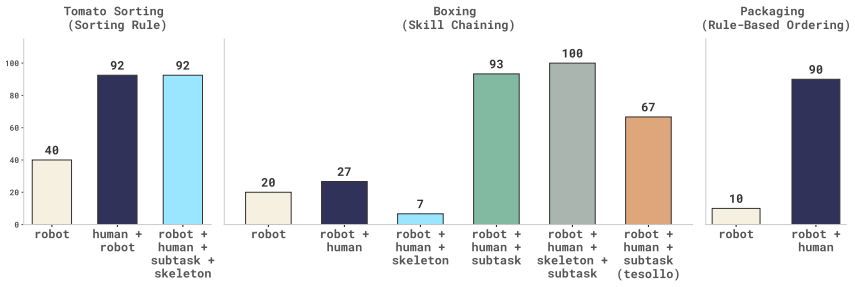
Egocentric human data lets humanoid robots learn new task semantics and compose novel behaviors without matching robot data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
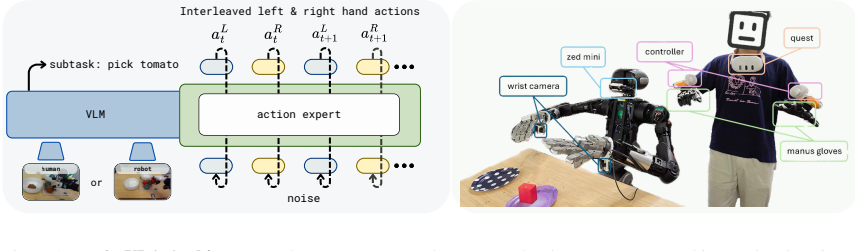
Fine-tuning the π₀.₅ model on mixed egocentric human and robot datasets enables the robot to acquire task semantics present only in the human data and to compose existing skills into novel behaviors for which no robot demonstrations exist.
What carries the argument
Fine-tuning the π₀.₅ vision-language-action model on combined egocentric human and robot datasets to transfer semantics and enable skill composition across human and humanoid embodiments.
If this is right
- Robots can execute tasks whose semantics are supplied exclusively by human demonstrations.
- Existing robot skills can be recombined using human examples to produce behaviors absent from robot training sets.
- Human data collection can expand the range of robot capabilities without collecting robot data for every new combination.
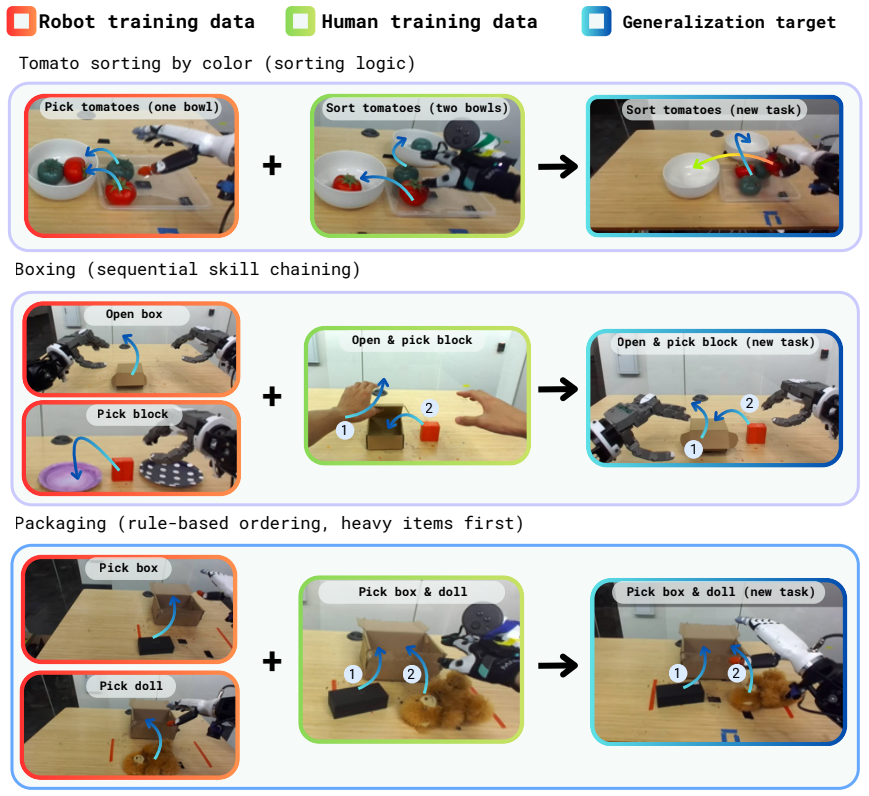
- The transfer applies to dexterous five-finger hands on humanoid bodies.
Where Pith is reading between the lines
- If the transfer succeeds, embodiment mismatch between similar hand structures may not require explicit alignment modules.
- The method suggests a route to leverage large existing collections of human egocentric video for robot training.
- Limits may appear when human and robot hand kinematics differ more than in the tested cases.
Load-bearing premise
Human hand movements and visual observations can be aligned to five-fingered humanoid robot actions through fine-tuning without embodiment differences blocking the transfer.
What would settle it
A robot fine-tuned with human data fails to perform a composed task shown only in human videos while a robot trained only on robot data also fails, or succeeds only when the same task appears in robot data.
Figures



read the original abstract
Robotics faces a fundamental challenge of data scarcity. Unlike language or vision research, there is no internet-scale dataset for robotic manipulation. A promising path forward is to leverage egocentric human data, which can be collected more easily, with greater breadth, and at a larger scale. Towards this end, we investigate key design choices for learning across human and humanoid embodiments equipped with dexterous five-finger hands, using the $\pi_{0.5}$ model as a foundation. Our results show that human data enables robots to learn new task semantics and compose existing skills into novel behaviors without corresponding robot data. The paper website is here: https://egopipaper.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ego-Pi, a fine-tuning procedure for the π₀.₅ vision-language-action model that incorporates egocentric human data alongside robot data. It claims that this enables humanoid robots with five-finger hands to acquire new task semantics and compose existing skills into novel behaviors even when no robot demonstrations exist for the target tasks, thereby mitigating data scarcity by leveraging easier-to-collect human video.
Significance. If the central transfer result holds under controlled conditions, the work would be significant for robotics because it provides a concrete path to scale manipulation policies using internet-scale human egocentric data rather than robot-specific teleoperation. The approach directly targets the embodiment gap between human and humanoid hands, which remains a core open problem.
major comments (2)
- [Abstract] Abstract: the headline claim that 'human data enables robots to learn new task semantics and compose existing skills into novel behaviors without corresponding robot data' is load-bearing yet unsupported by any reported quantitative metrics, baselines, or ablation tables that isolate the incremental contribution of the human egocentric fine-tuning stage from the base π₀.₅ robot priors.
- [Experimental evaluation (implied)] No section provides an ablation or error analysis that quantifies residual embodiment mismatch (e.g., hand-pose alignment error, grasp success on contact-rich subtasks, or failure modes attributable to kinematic differences between human and five-finger humanoid hands). Without such evidence the transfer assumption remains untested.
minor comments (1)
- [Abstract] The notation π₀.₅ is introduced without an explicit reference to the base model paper or a clear statement of which weights are frozen versus updated during fine-tuning.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our manuscript. We address each major comment below and outline planned revisions to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'human data enables robots to learn new task semantics and compose existing skills into novel behaviors without corresponding robot data' is load-bearing yet unsupported by any reported quantitative metrics, baselines, or ablation tables that isolate the incremental contribution of the human egocentric fine-tuning stage from the base π₀.₅ robot priors.
Authors: The manuscript reports task success rates comparing the base π₀.₅ model against the Ego-Pi fine-tuned variant on novel behaviors, with the website providing additional video evidence. We acknowledge, however, that the current version lacks explicit ablation tables that isolate the human-data fine-tuning stage from the robot priors. We will add these quantitative ablations and baselines in the revised manuscript. revision: yes
-
Referee: [Experimental evaluation (implied)] No section provides an ablation or error analysis that quantifies residual embodiment mismatch (e.g., hand-pose alignment error, grasp success on contact-rich subtasks, or failure modes attributable to kinematic differences between human and five-finger humanoid hands). Without such evidence the transfer assumption remains untested.
Authors: We agree that a dedicated analysis of embodiment mismatch would strengthen the claims. The present experiments emphasize end-to-end task performance rather than per-subtask kinematic error breakdowns. We will incorporate an error analysis section quantifying hand-pose alignment and contact-rich failure modes in the revision. revision: yes
Circularity Check
No circularity: empirical results from fine-tuning experiments
full rationale
The manuscript presents an empirical study of fine-tuning the π0.5 VLA model on egocentric human and robot data. Its strongest claim—that human data enables new task semantics and skill composition without robot data—is supported by experimental outcomes rather than any derivation chain. No equations, parameter fits renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. The work is self-contained against external benchmarks (robot evaluations) and does not reduce its conclusions to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mirage: Cross-embodiment zero-shot policy transfer with cross-painting, 2024
Lawrence Yunliang Chen, Kush Hari, Karthik Dharmarajan, Chenfeng Xu, Quan Vuong, and Ken Goldberg. Mirage: Cross-embodiment zero-shot policy transfer with cross-painting, 2024. 2
2024
-
[2]
Sirui Chen, Chen Wang, Kaden Nguyen, Li Fei- Fei, and C Karen Liu. Arcap: Collecting high- quality human demonstrations for robot learning with augmented reality feedback.arXiv preprint arXiv:2410.08464, 2024. 3, 4
arXiv 2024
-
[3]
Project aria: A new tool for egocentric multi-modal ai re- search, 2023
Jakob Engel, Kiran Somasundaram, Michael Goe- sele, Albert Sun, Alexander Gamino, Andrew Turner, Arjang Talattof, Arnie Yuan, Bilal Souti, Brighid Meredith, Cheng Peng, Chris Sweeney, Cole Wilson, Dan Barnes, Daniel DeTone, David Caruso, Derek Valleroy, Dinesh Ginjupalli, Dun- can Frost, Edward Miller, Elias Mueggler, Evgeniy Oleinik, Fan Zhang, Guruprasa...
2023
-
[4]
Yoon, Mouli Sivapurapu, and Jian Zhang
Ryan Hoque, Peide Huang, David J. Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video, 2025. 2, 3
2025
-
[5]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Nic- colo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szy- mon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pe...
2025
-
[6]
Egomimic: Scaling imi- tation learning via egocentric video, 2024
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imi- tation learning via egocentric video, 2024. 2
2024
-
[7]
Emergence of human to robot trans- fer in vision-language-action models, 2025
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoffman, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of human to robot trans- fer in vision-language-action models, 2025. 2
2025
-
[8]
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025. 2
Pith/arXiv arXiv 2025
-
[9]
Being- h0: Vision-language-action pretraining from large- scale human videos, 2025
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being- h0: Vision-language-action pretraining from large- scale human videos, 2025. 2
2025
-
[10]
Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system
Yuzhe Qin, Wei Yang, Binghao Huang, Karl Van Wyk, Hao Su, Xiaolong Wang, Yu-Wei Chao, and Dieter Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. In Robotics: Science and Systems, 2023. 4
2023
-
[11]
Yoon, Ryan Hoque, Lars Paulsen, Ge Yang, Jian Zhang, Sha Yi, Guanya Shi, and Xiaolong Wang
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J. Yoon, Ryan Hoque, Lars Paulsen, Ge Yang, Jian Zhang, Sha Yi, Guanya Shi, and Xiaolong Wang. Humanoid policy human policy, 2025. 2, 3
2025
-
[12]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), 2017. 4
2017
-
[13]
Q4 / full year 2024 results – smartglasses as a new driver: Ray-ban meta at 2 million units sold since launch
EssilorLuxottica S.A. Q4 / full year 2024 results – smartglasses as a new driver: Ray-ban meta at 2 million units sold since launch. Press Release,
2024
-
[14]
Ray-Ban Meta at 2 million units sold since the launch, with strong acceleration in 2024
“Ray-Ban Meta at 2 million units sold since the launch, with strong acceleration in 2024.”. 1
2024
-
[15]
Egovla: Learning vision-language-action models from egocentric human videos, 2025
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, Hongxu Yin, Sifei Liu, Song Han, Yao Lu, and Xiaolong Wang. Egovla: Learning vision-language-action models from egocentric human videos, 2025. 2
2025
-
[16]
Egoscale: Scaling dexterous manipula- tion with diverse egocentric human data, 2026
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Casta ˜neda, Fengyuan Hu, You Liang Tan, Letian Fu, Trevor Darrell, Furong Huang, Yuke Zhu, Danfei Xu, and Linxi Fan. Egoscale: Scaling dexterous manipula- tion with diverse egocentric human data, 2026. 3
2026
-
[17]
On the continuity of rotation representations in neural networks, 2020
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks, 2020. 4 Ego-Pi: VLA Fine-Tuning for Ego-Centric Human and Robot Data Supplementary Material Figure 6. Hand labelled with joint angle locations
2020
-
[18]
6), and letq robot ∈ R20 be the corresponding robot joint angles (e.g., Tesollo hand)
Joint Mapping between Human and Robot Hands Letq∈R 20 be the human hand joint angles mea- sured by the Manus glove (Fig. 6), and letq robot ∈ R20 be the corresponding robot joint angles (e.g., Tesollo hand). We map each human joint angle to its robot counterpart using a per-joint offsetδ i and a scaling factorf i: qrobot,i = qi +δ i fi, i∈ {1, . . . ,20}....
-
[19]
Model Details The hyperparameters for fine-tuning theπ0.5 policy are shown in Table 2. Table 2. Hyperparameters forπ 0.5 fine-tuning. Hyperparameter Value Optimizer AdamW β1 0.9 β2 0.95 Weight Decay 0 Gradient Clip Norm 1.0 LR Schedule Cosine Warmup Ratio 0.001 Batch Size 128 Training Steps 5000 - 10,000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.