ScaffoldAgent: Utility-Guided Dynamic Outline Optimization for Open-Ended Deep Research
Pith reviewed 2026-06-26 17:48 UTC · model grok-4.3
The pith
ScaffoldAgent improves long-form reports by using a utility signal to dynamically expand, contract or revise outlines during research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
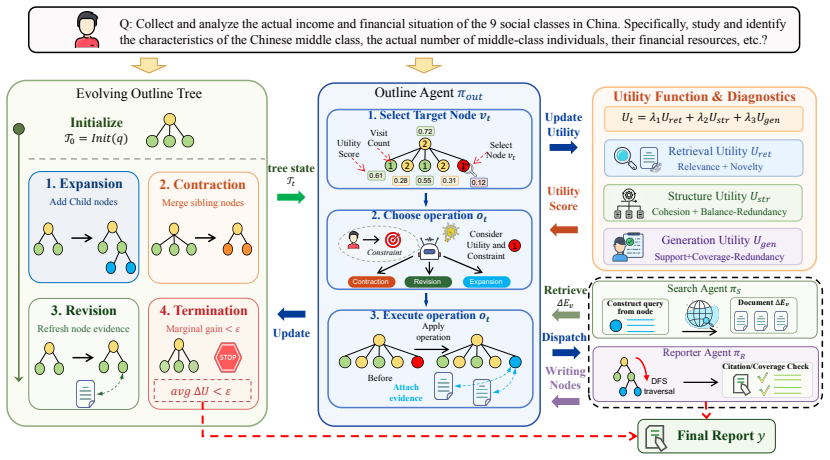
ScaffoldAgent models outline evolution as a structured decision process with Expansion, Contraction, and Revision operations and introduces a utility-guided feedback mechanism that estimates the downstream value of each operation from retrieval gain, structural coherence, and trial-generation quality; the resulting signal directs node selection, operation scheduling, and termination, producing consistent gains in long-form report generation and factual grounding on DeepResearch Bench and DeepResearch Gym.
What carries the argument
Utility-guided feedback mechanism that estimates the downstream value of each outline operation from retrieval gain, structural coherence, and trial-generation quality.
If this is right
- Dynamic outline operations reduce scaffold drift that occurs under continuous information accumulation.
- The utility signal enables informed choices for which nodes to update and when to terminate the process.
- Controlled updates via the three operations improve coordination between retrieval and evidence organization.
- Experiments demonstrate measurable gains in both report coherence and factual grounding over fixed-outline baselines.
Where Pith is reading between the lines
- The same utility-driven update logic could be applied to other evolving structures such as research plans or code architectures.
- If utility estimation works, it suggests a general route for providing intermediate feedback in tasks where final evaluation is expensive.
- The approach may scale to longer research horizons by keeping the decision space structured rather than fully open-ended.
Load-bearing premise
The utility signal computed from retrieval gain, structural coherence, and trial-generation quality accurately predicts the downstream value of each outline operation and does not introduce new forms of scaffold drift.
What would settle it
A controlled run in which outline decisions are made randomly instead of by the utility signal and final report factual accuracy shows no drop, or a run in which the computed utility values show low correlation with measured report quality metrics.
Figures

read the original abstract
Open-ended deep research (OEDR) requires systems to acquire knowledge through multi-round retrieval and generate coherent long-form reports. The outline plays a central role as a structural scaffold that coordinates retrieval, evidence organization, and generation. However, existing methods either fix the outline before writing or refine it with local heuristics, leading to scaffold drift under continuous information accumulation and delayed feedback for evaluating outline modifications. We propose ScaffoldAgent, a utility-guided dynamic outline optimization framework for OEDR. ScaffoldAgent models outline evolution as a structured decision process with three operations: Expansion, Contraction, and Revision, enabling controlled updates to the report scaffold. It further introduces a utility-guided feedback mechanism that estimates the downstream value of each outline operation from retrieval gain, structural coherence, and trial-generation quality. The resulting utility signal guides node selection, operation scheduling, and termination during inference. Experiments on DeepResearch Bench and DeepResearch Gym show that ScaffoldAgent consistently improves long-form report generation and factual grounding over existing deep research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ScaffoldAgent, a utility-guided dynamic outline optimization framework for open-ended deep research (OEDR). It models outline evolution as a structured decision process using three operations—Expansion, Contraction, and Revision—and introduces a utility signal derived from retrieval gain, structural coherence, and trial-generation quality to guide node selection, operation scheduling, and termination. Experiments on DeepResearch Bench and DeepResearch Gym are claimed to demonstrate consistent improvements in long-form report generation and factual grounding over existing deep research agents.
Significance. If the empirical improvements hold under rigorous evaluation, the work could meaningfully advance adaptive scaffolding in multi-round retrieval and generation systems by addressing scaffold drift through controlled outline updates and delayed-feedback utility estimation. The structured operations and composite utility mechanism provide a concrete decision process that existing heuristic or fixed-outline methods lack.
major comments (1)
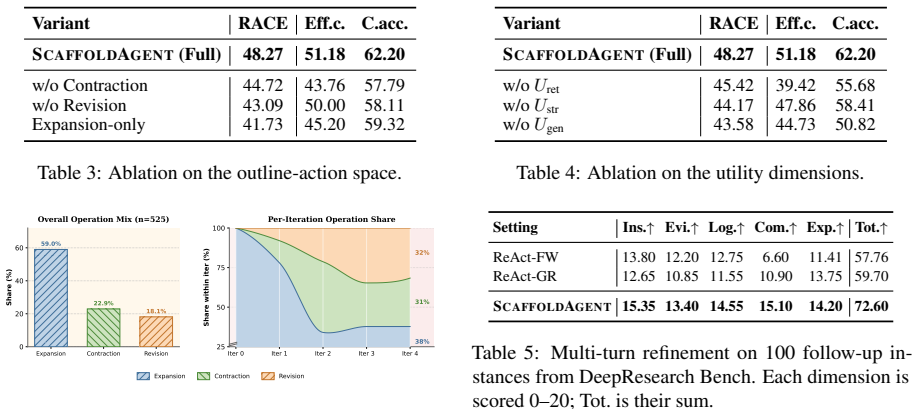
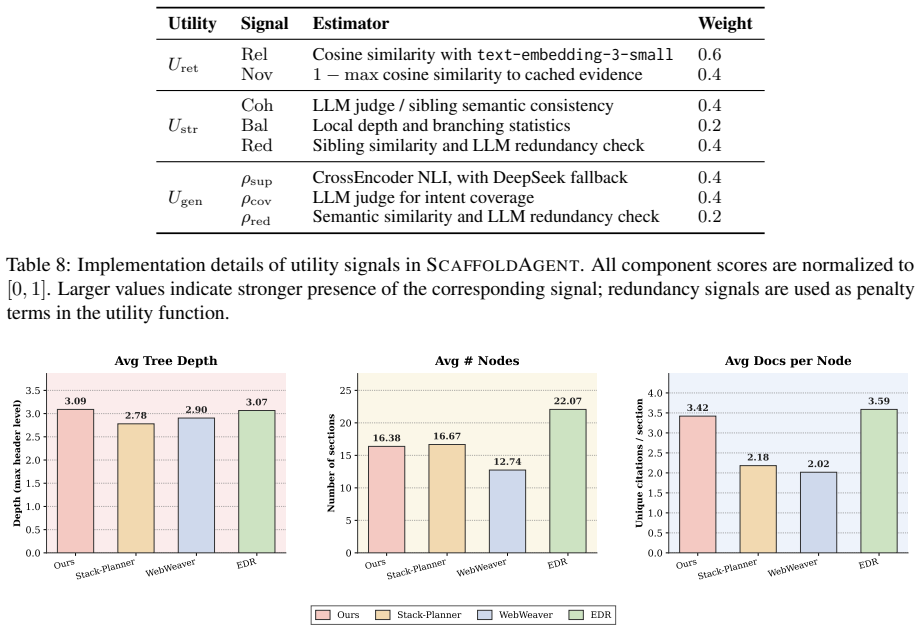
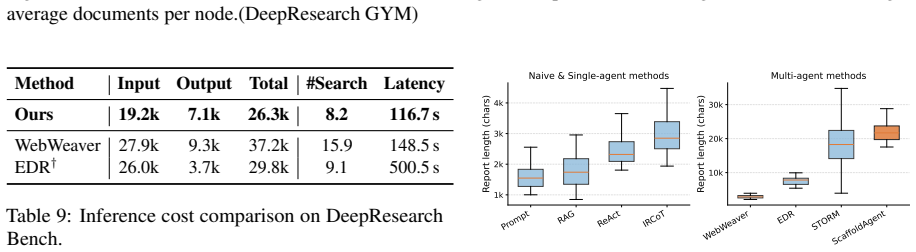
- The central empirical claim (consistent gains on two benchmarks) cannot be assessed because the manuscript provides no implementation details, baseline descriptions, statistical tests, error bars, or ablation results for the utility components; this renders the reported improvements unverifiable from the text.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the need for greater transparency in the experimental evaluation. We address the major comment below.
read point-by-point responses
-
Referee: The central empirical claim (consistent gains on two benchmarks) cannot be assessed because the manuscript provides no implementation details, baseline descriptions, statistical tests, error bars, or ablation results for the utility components; this renders the reported improvements unverifiable from the text.
Authors: We agree that the current manuscript version does not contain sufficient implementation details, baseline specifications, statistical tests, error bars, or component ablations to allow full verification of the empirical claims. In the revised manuscript we will expand the Experiments section to include: (1) complete implementation details for ScaffoldAgent and the utility function, (2) explicit descriptions of all baselines together with their hyper-parameters, (3) results of statistical significance tests, (4) error bars or confidence intervals on all reported metrics, and (5) ablation studies that isolate the contribution of each utility component (retrieval gain, structural coherence, and trial-generation quality). These additions will be placed in the main text or a dedicated appendix so that the reported gains can be independently assessed. revision: yes
Circularity Check
No significant circularity; empirical framework with no self-referential derivations
full rationale
The paper presents ScaffoldAgent as a utility-guided framework for outline operations (Expansion/Contraction/Revision) driven by a composite signal from retrieval gain, structural coherence, and trial-generation quality. Validation rests on empirical results from DeepResearch Bench and DeepResearch Gym. No equations, fitted parameters, or first-principles derivations are described that reduce to their own inputs by construction. The utility signal is introduced conceptually without self-definition or renaming of known results. Central claims are performance improvements over baselines, not predictions forced by internal definitions or self-citation chains. This is a standard empirical systems paper whose validity depends on experimental details rather than circular theoretical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Carlos E Alchourr \'o n, Peter G \"a rdenfors, and David Makinson. 1985. On the logic of theory change: Partial meet contraction and revision functions. The journal of symbolic logic, 50(2):510--530
1985
-
[2]
Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2025. Longwriter: Unleashing 10,000+ word generation from long context llms. In International Conference on Learning Representations, volume 2025, pages 36528--36546
2025
-
[3]
S \'e bastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, and 1 others. 2023. Paper review:'sparks of artificial general intelligence: Early experiments with gpt-4'
2023
-
[4]
Jaime Carbonell and Jade Goldstein. 1998. The use of mmr, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335--336
1998
-
[5]
Jing Chen, Zhiheng Yang, Yixian Shen, Jie Liu, Adam Belloum, Paola Grosso, and Chrysa Papagianni. 2025. Surveygen-i: Consistent scientific survey generation with evolving plans and memory-guided writing. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Associ...
2025
-
[6]
Jo \ a o Coelho, Jingjie Ning, Jingyuan He, Kangrui Mao, Abhijay Paladugu, Pranav Setlur, Jiahe Jin, Jamie Callan, Jo \ a o Magalh \ a es, Bruno Martins, and 1 others. 2025. Deepresearchgym: A free, transparent, and reproducible evaluation sandbox for deep research. arXiv preprint arXiv:2505.19253
arXiv 2025
-
[7]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. 2025. Deepresearch bench: A comprehensive benchmark for deep research agents. arXiv preprint arXiv:2506.11763
Pith/arXiv arXiv 2025
-
[8]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465--6488
2023
-
[9]
Rujun Han, Yanfei Chen, Zoey CuiZhu, Lesly Miculicich, Guan Sun, Yuanjun Bi, Weiming Wen, Hui Wan, Chunfeng Wen, Sol \`e ne Ma \^ tre, and 1 others. 2025. Deep researcher with test-time diffusion. arXiv preprint arXiv:2507.16075
arXiv 2025
-
[10]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card. arXiv preprint arXiv:2412.16720
Pith/arXiv arXiv 2024
-
[11]
Xinke Jiang, Yuchen Fang, Rihong Qiu, Haoyu Zhang, Yongxin Xu, Hao Chen, Wentao Zhang, Ruizhe Zhang, Xu Chu, Junfeng Zhao, and 1 others. 2024. Tc-rag: Turing-complete rag's case study on medical llm systems. CoRR
2024
-
[12]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, volume 2024, pages 54107--54157
2024
-
[13]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516
Pith/arXiv arXiv 2025
-
[14]
Yukyung Lee, Soonwon Ka, Bokyung Son, Pilsung Kang, and Jaewook Kang. 2025. Navigating the path of writing: Outline-guided text generation with large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track), pages 233--250
2025
-
[15]
Yu Lei, Shuzheng Si, Wei Wang, Yifei Wu, Gang Chen, Fanchao Qi, and Maosong Sun. 2025. Rhinoinsight: Improving deep research through control mechanisms for model behavior and context. arXiv preprint arXiv:2511.18743
arXiv 2025
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. https://arxiv.org/abs/2005.11401 Retrieval-augmented generation for knowledge-intensive nlp tasks . Preprint, arXiv:2005.11401
Pith/arXiv arXiv 2021
-
[17]
Yishan Li, Wentong Chen, Yukun Yan, Mingwei Li, Sen Mei, Xiaorong Wang, Kunpeng Liu, Xin Cong, Shuo Wang, Zhong Zhang, and 1 others. 2026. Agentcpm-report: Interleaving drafting and deepening for open-ended deep research. arXiv preprint arXiv:2602.06540
arXiv 2026
-
[18]
Zijian Li, Xin Guan, Bo Zhang, Shen Huang, Houquan Zhou, Shaopeng Lai, Ming Yan, Yong Jiang, Pengjun Xie, Fei Huang, and 1 others. 2025. Webweaver: Structuring web-scale evidence with dynamic outlines for open-ended deep research. arXiv preprint arXiv:2509.13312
arXiv 2025
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
Pith/arXiv arXiv 2024
-
[20]
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and 1 others. 2022. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147
Pith/arXiv arXiv 2022
-
[21]
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. Gaia: a benchmark for general ai assistants. In International Conference on Learning Representations, volume 2024, pages 9025--9049
2024
-
[22]
Akshara Prabhakar, Roshan Ram, Zixiang Chen, Silvio Savarese, Frank Wang, Caiming Xiong, Huan Wang, and Weiran Yao. 2025. Enterprise deep research: Steerable multi-agent deep research for enterprise analytics. arXiv preprint arXiv:2510.17797
arXiv 2025
-
[23]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539--68551
2023
-
[24]
Yijia Shao, Yucheng Jiang, Theodore Kanell, Peter Xu, Omar Khattab, and Monica Lam. 2024 a . Assisting in writing wikipedia-like articles from scratch with large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6...
2024
-
[25]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024 b . Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[26]
Xiaofeng Shi, Qian Kou, Yuduo Li, Ning Tang, Jinxin Xie, Longbin Yu, Songjing Wang, and Hua Zhou. 2025. Scisage: A multi-agent framework for high-quality scientific survey generation. arXiv preprint arXiv:2506.12689
arXiv 2025
-
[27]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2024. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36
2024
-
[28]
Zhengwei Tao, Jialong Wu, Wenbiao Yin, Junkai Zhang, Baixuan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. 2025. https://arxiv.org/abs/2507.15061 Webshaper: Agentically data synthesizing via information-seeking formalization . Preprint, arXiv:2507.15061
arXiv 2025
-
[29]
Trieu H Trinh, Yuhuai Wu, Quoc V Le, He He, and Thang Luong. 2024. Solving olympiad geometry without human demonstrations. Nature, 625(7995):476--482
2024
-
[30]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. https://arxiv.org/abs/2212.10509 Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions . Preprint, arXiv:2212.10509
Pith/arXiv arXiv 2023
-
[31]
Kaiyang Wan, Honglin Mu, Rui Hao, Haoran Luo, Tianle Gu, and Xiuying Chen. 2025. A cognitive writing perspective for constrained long-form text generation. In Findings of the Association for Computational Linguistics: ACL 2025, pages 9832--9844
2025
-
[32]
Qianyue Wang, Jinwu Hu, Zhengping Li, Yufeng Wang, Daiyuan Li, Yu Hu, and Mingkui Tan. 2025. Generating long-form story using dynamic hierarchical outlining with memory-enhancement. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pape...
2025
-
[33]
Yuhao Wu, Yushi Bai, Zhiqiang Hu, Juanzi Li, and Roy Ka-Wei Lee. 2025. Superwriter: Reflection-driven long-form generation with large language models. arXiv preprint arXiv:2506.04180
arXiv 2025
-
[34]
Ruibin Xiong, Yimeng Chen, Dmitrii Khizbullin, Mingchen Zhuge, and J \"u rgen Schmidhuber. 2025. Beyond outlining: Heterogeneous recursive planning for adaptive long-form writing with language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24689--24725
2025
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[36]
Kevin Yang, Dan Klein, Nanyun Peng, and Yuandong Tian. 2023. Doc: Improving long story coherence with detailed outline control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3378--3465
2023
-
[37]
Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. 2022. Re3: Generating longer stories with recursive reprompting and revision. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 4393--4479
2022
-
[38]
Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2019. Plan-and-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7378--7385
2019
-
[40]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022 b . React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[41]
Ruizhe Zhang, Xinke Jiang, Zhibang Yang, Zhixin Zhang, Jiaran Gao, Yuzhen Xiao, Hongbin Lai, Xu Chu, Junfeng Zhao, and Yasha Wang. 2026. Stackplanner: A centralized hierarchical multi-agent system with task-experience memory management. arXiv preprint arXiv:2601.05890
Pith/arXiv arXiv 2026
-
[42]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, and 1 others. 2024. Webarena: A realistic web environment for building autonomous agents. In International Conference on Learning Representations, volume 2024, pages 15585--15606
2024
-
[43]
Chiwei Zhu, Benfeng Xu, Mingxuan Du, Shaohan Wang, Xiaorui Wang, Zhendong Mao, and Yongdong Zhang. 2026. Fs-researcher: Test-time scaling for long-horizon research tasks with file-system-based agents. arXiv preprint arXiv:2602.01566
Pith/arXiv arXiv 2026
-
[44]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[45]
Publications Manual , year = "1983", publisher =
1983
-
[46]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[47]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[48]
Dan Gusfield , title =. 1997
1997
-
[49]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[50]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[51]
Family practice , volume=
Diagnostic uncertainty in primary care: what is known about its communication, and what are the associated ethical issues? , author=. Family practice , volume=. 2021 , publisher=
2021
-
[52]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[53]
Journal of Engineering and Applied Science , volume=
Building an enhanced case-based reasoning and rule-based systems for medical diagnosis , author=. Journal of Engineering and Applied Science , volume=. 2023 , publisher=
2023
-
[54]
Meena, P. L. and Sarmah, S. P. , title =. Transportation Research Part E: Logistics and Transportation Review , year =
-
[55]
arXiv preprint arXiv:2404.10981 , year=
A survey on retrieval-augmented text generation for large language models , author=. arXiv preprint arXiv:2404.10981 , year=
-
[56]
2023 , eprint=
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[57]
Patricia S. Abril and Robert Plant. The patent holder's dilemma: Buy, sell, or troll?. Communications of the ACM. 2007. doi:10.1145/1188913.1188915
-
[58]
Deciding equivalances among conjunctive aggregate queries
Sarah Cohen and Werner Nutt and Yehoshua Sagic. Deciding equivalances among conjunctive aggregate queries. doi:10.1145/1219092.1219093
-
[59]
Special issue: Digital Libraries. 1996
1996
-
[60]
Understanding Policy-Based Networking
David Kosiur. Understanding Policy-Based Networking. 2001
2001
-
[63]
The title of book two. 2008. doi:10.1007/3-540-09237-4
-
[64]
Asad Z. Spector. Achieving application requirements. Distributed Systems. 1990. doi:10.1145/90417.90738
-
[65]
Douglass and David Harel and Mark B
Bruce P. Douglass and David Harel and Mark B. Trakhtenbrot. Statecarts in use: structured analysis and object-orientation. Lectures on Embedded Systems. 1998. doi:10.1007/3-540-65193-4_29
-
[66]
Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd. ed.). 1997
1997
-
[67]
Donald E. Knuth. The Art of Computer Programming. 1998
1998
-
[68]
Structured Variational Inference Procedures and their Realizations (as incol)
Dan Geiger and Christopher Meek. Structured Variational Inference Procedures and their Realizations (as incol). Proceedings of Tenth International Workshop on Artificial Intelligence and Statistics, The Barbados
-
[69]
Stan W. Smith. An experiment in bibliographic mark-up: Parsing metadata for XML export. Proceedings of the 3rd. annual workshop on Librarians and Computers. 2010. doi:99.9999/woot07-S422
2010
-
[70]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies
-
[71]
Sten Andler. Predicate Path expressions. Proceedings of the 6th. ACM SIGACT-SIGPLAN symposium on Principles of Programming Languages. 1979. doi:10.1145/567752.567774
-
[72]
LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER
David Harel. LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER. 1978
1978
-
[73]
Anisi , title =
David A. Anisi , title =
-
[74]
Clarkson
Kenneth L. Clarkson. Algorithms for Closest-Point Problems (Computational Geometry). 1985
1985
-
[75]
Introduction to Bayesian Statistics
Harry Thornburg. Introduction to Bayesian Statistics. 2001
2001
-
[76]
CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11
Rafal Ablamowicz and Bertfried Fauser. CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11. 2007
2007
-
[77]
Stats and Analysis
Poker-Edge.Com. Stats and Analysis. 2006
2006
-
[78]
A more perfect union
Barack Obama. A more perfect union. 2008
2008
-
[79]
The fountain of youth
Joseph Scientist. The fountain of youth. 2009
2009
-
[80]
Solder man
Dave Novak. Solder man. ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol. 145 (July 27--27, 2003). 2003. doi:99.9999/woot07-S422
2003
-
[81]
Interview with Bill Kinder: January 13, 2005
Newton Lee. Interview with Bill Kinder: January 13, 2005. Comput. Entertain. 2005. doi:10.1145/1057270.1057278
-
[82]
The Enabling of Digital Libraries
Bernard Rous. The Enabling of Digital Libraries. Digital Libraries. 2008
2008
-
[84]
(new) Finding minimum congestion spanning trees , journal =
Werneck, Renato and Setubal, Jo\. (new) Finding minimum congestion spanning trees , journal =. doi:10.1145/351827.384253 , acmid = 384253, publisher =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.