World from Motion: Generative Dynamic Gaussian Reconstruction from Monocular Video
Pith reviewed 2026-07-02 13:19 UTC · model grok-4.3
The pith
A video model conditioned on 3D renderings produces consistent dynamic 3D Gaussians from monocular video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
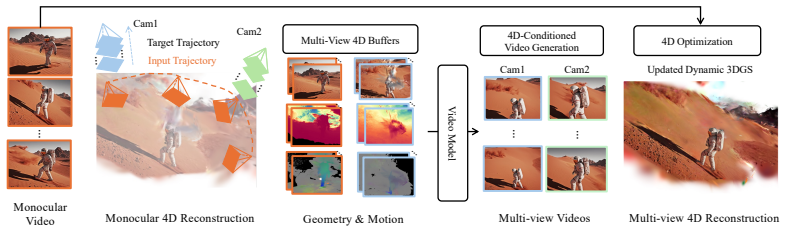
We condition a video model on dense, pixel-aligned renderings that encode appearance, geometry, and 3D scene motion along both input and target camera trajectories to correct rendering artifacts and fill in missing regions from an initial reconstruction. We construct a dataset of aligned multiview video pairs and dynamic 3DGS representations with simulated artifacts for training. At test time we distill the model's generations back into a single consistent high-quality dynamic 3DGS, improving novel-view synthesis and the underlying 3D motion. The method sets a new state of the art in 4D reconstruction and generalizes to in-the-wild videos.
What carries the argument
The generative video model conditioned on dense pixel-aligned renderings encoding appearance, geometry, and 3D motion for artifact correction and region synthesis prior to distillation into consistent 3D Gaussians.
If this is right
- The resulting 3DGS allows improved novel-view synthesis.
- The underlying 3D motion estimates are improved.
- The approach works on in-the-wild videos with large viewpoint changes.
- It achieves state-of-the-art performance in 4D reconstruction tasks.
Where Pith is reading between the lines
- This conditioning technique could be applied to other 3D reconstruction problems where consistency across views is needed.
- Future work might explore using the method for longer videos or more complex motions.
- It opens the possibility of combining generative models with explicit 3D representations for better controllability.
Load-bearing premise
The generative video model can reliably correct artifacts and synthesize missing regions in a manner that allows distillation to a single consistent 3D representation without new inconsistencies.
What would settle it
If applying the full pipeline to a video with available ground-truth multi-view captures results in a 3DGS that has larger rendering errors on held-out views than the initial monocular reconstruction, the claim would be falsified.
Figures



read the original abstract
We present World from Motion, a method for generating freely renderable dynamic 3D Gaussian representations from monocular videos. Our approach conditions a video model on dense, pixel-aligned renderings that encode appearance, geometry, and 3D scene motion along both input and target camera trajectories to correct rendering artifacts and fill in missing regions from an initial reconstruction. To train this model, we construct a dataset of aligned multiview video pairs and dynamic 3DGS representations, with simulated artifacts characteristic of monocular reconstruction. At test time, we distill the model's generations, including newly observed regions and motions, back into a single consistent, high-quality dynamic 3DGS, improving both novel-view synthesis and the underlying 3D motion. Our method sets a new state of the art in 4D reconstruction and seamlessly generalizes to in-the-wild videos with large viewpoint changes and dynamic motions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents World from Motion, a method for generating freely renderable dynamic 3D Gaussian representations from monocular videos. It conditions a video model on dense pixel-aligned renderings of appearance, geometry, and 3D scene motion along input and target trajectories to correct monocular artifacts and synthesize missing regions. The model is trained on a constructed dataset of aligned multiview video pairs and dynamic 3DGS with simulated artifacts; at test time, generations are distilled into a single consistent dynamic 3DGS via optimization, claiming new state-of-the-art performance in 4D reconstruction that generalizes to in-the-wild videos with large viewpoint changes and dynamic motions.
Significance. If the distillation step reliably produces consistent 3D representations, the approach could meaningfully advance monocular 4D reconstruction by integrating generative video priors with explicit 3D Gaussian optimization, improving novel-view synthesis and motion recovery from casual videos beyond current baselines.
major comments (1)
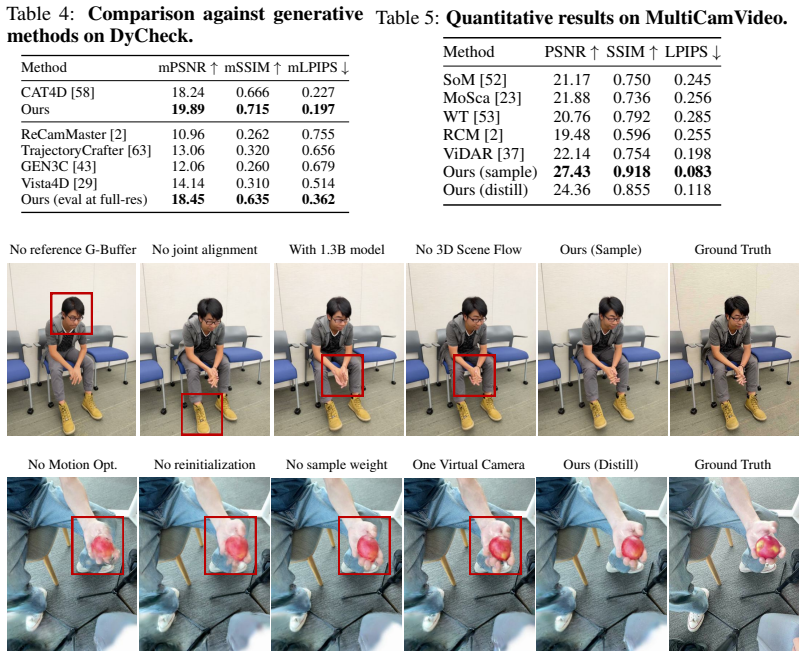
- [§4.3] §4.3: The distillation is described as an optimization that incorporates new observations and motions from the conditioned generative model, but the manuscript provides no analysis of how conflicting motion fields or appearance hallucinations across overlapping target trajectories are reconciled. The optimization appears to rely only on standard rendering losses without an explicit consistency regularizer, which directly bears on whether a single high-quality dynamic 3DGS can be obtained without residual artifacts or over-smoothing.
minor comments (1)
- The description of the training dataset construction (aligned multiview pairs with simulated monocular artifacts) would benefit from additional detail on how the simulated artifacts are generated to ensure they match real monocular reconstruction failures.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the specific comment on the distillation procedure in §4.3. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [§4.3] §4.3: The distillation is described as an optimization that incorporates new observations and motions from the conditioned generative model, but the manuscript provides no analysis of how conflicting motion fields or appearance hallucinations across overlapping target trajectories are reconciled. The optimization appears to rely only on standard rendering losses without an explicit consistency regularizer, which directly bears on whether a single high-quality dynamic 3DGS can be obtained without residual artifacts or over-smoothing.
Authors: We agree that the manuscript does not include an explicit analysis or ablation of conflict reconciliation across overlapping trajectories. The distillation optimizes a single dynamic 3DGS by rendering losses against the generated frames (appearance, depth, and motion) produced by the conditioned video model. Because the generative model is itself conditioned on pixel-aligned renderings of the initial 3DGS along both input and target trajectories, the generated outputs inherit a degree of geometric and motion coherence from the shared 3D prior; this implicit coupling is what allows the subsequent optimization to converge to a single representation. Nevertheless, we did not quantify how often or how severely conflicting motion fields arise, nor did we introduce or evaluate an explicit consistency regularizer. In the revision we will add (i) a description of the exact loss terms used in the distillation, (ii) an analysis of trajectory overlap and any observed inconsistencies, and (iii) a short ablation that measures the effect of adding a simple motion-consistency term. We therefore mark this comment as requiring a revision. revision: yes
Circularity Check
No circularity: method pipeline relies on external data and optimization without self-referential reductions
full rationale
The provided abstract and method outline describe a standard generative pipeline: constructing a training dataset of multiview pairs with simulated monocular artifacts, conditioning a video model on pixel-aligned renderings of appearance/geometry/motion, and distilling outputs into a dynamic 3DGS via optimization. No equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are visible that would reduce any claimed result to its inputs by construction. The SOTA claim is presented as an empirical outcome of the pipeline rather than a mathematical identity, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lindell, Zan Gojcic, Sanja Fidler, Huan Ling, Jun Gao, and Xuanchi Ren
Sherwin Bahmani, Tianchang Shen, Jiawei Ren, Jiahui Huang, Yifeng Jiang, Haithem Turki, Andrea Tagliasacchi, David B. Lindell, Zan Gojcic, Sanja Fidler, Huan Ling, Jun Gao, and Xuanchi Ren. Lyra: Generative 3d scene reconstruction via self-distillation with video diffusion models. InICLR, 2026
2026
-
[2]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InICCV, 2025
2025
-
[3]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InCVPR, 2023
2023
-
[4]
Recovering non-rigid 3d shape from image streams
Christoph Bregler, Aaron Hertzmann, and Henning Biermann. Recovering non-rigid 3d shape from image streams. InCVPR, 2000
2000
-
[5]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
M.W.M.G. Dissanayake, P. Newman, S. Clark, H.F. Durrant-Whyte, and M. Csorba. A solution to the simultaneous localization and map building (slam) problem.IEEE Transactions on Robotics and Automation, 17(3):229–241, 2001. doi: 10.1109/70.938381
-
[7]
Tapir: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InICCV, 2023
2023
-
[8]
BootsTAP: Bootstrapped training for tracking-any-point.ACCV, 2024
Carl Doersch, Pauline Luc, Yi Yang, Dilara Gokay, Skanda Koppula, Ankush Gupta, Joseph Heyward, Ignacio Rocco, Ross Goroshin, João Carreira, and Andrew Zisserman. BootsTAP: Bootstrapped training for tracking-any-point.ACCV, 2024
2024
-
[9]
Fast dynamic radiance fields with time-aware neural voxels
Jiemin Fang, Taoran Yi, Xinggang Wang, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Matthias Nießner, and Qi Tian. Fast dynamic radiance fields with time-aware neural voxels. InSIG- GRAPH Asia 2022 Conference Papers, pages 1–9, 2022
2022
-
[10]
Flowr: Flowing from sparse to dense 3d reconstructions
Tobias Fischer, Samuel Rota Bulò, Yung-Hsu Yang, Nikhil Keetha, Lorenzo Porzi, Norman Müller, Katja Schwarz, Jonathon Luiten, Marc Pollefeys, and Peter Kontschieder. Flowr: Flowing from sparse to dense 3d reconstructions. InICCV, 2025
2025
-
[11]
Plenoptic video generation
Xiao Fu, Shitao Tang, Min Shi, Xian Liu, Jinwei Gu, Ming-Yu Liu, Dahua Lin, and Chen-Hsuan Lin. Plenoptic video generation. InCVPR, 2026
2026
-
[12]
Monocular dynamic view synthesis: A reality check.NeurIPS, 2022
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check.NeurIPS, 2022
2022
-
[13]
Veo: A text-to-video generation system
Google DeepMind. Veo: A text-to-video generation system. Technical report, Google DeepMind, 2025. URL https://storage.googleapis.com/deepmind-media/veo/ Veo-3-Tech-Report.pdf
2025
-
[14]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[15]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URLhttps://openreview. net/forum?id=qw8AKxfYbI
2021
-
[17]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas, Laura Leal-Taixé, and Sanja Fidler. ViPE: Video pose engine for 3d geometric perception. InarXiv preprint arXiv:2508.10934, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Vivid4d: Improving 4d reconstruction from monocular video by video inpainting
Jiaxin Huang, Sheng Miao, Bangbang Yang, Yuewen Ma, and Yiyi Liao. Vivid4d: Improving 4d reconstruction from monocular video by video inpainting. InICCV, 2025
2025
-
[19]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InICCV, 2025
2025
-
[20]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker: It is better to track together. InECCV, 2024
2024
-
[21]
Any4D: Unified feed-forward metric 4d reconstruction
Jay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, and Deva Ramanan. Any4D: Unified feed-forward metric 4d reconstruction. InCVPR, 2026
2026
-
[22]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4), 2023
2023
-
[23]
Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds
Jiahui Lei, Yijia Weng, Adam W Harley, Leonidas Guibas, and Kostas Daniilidis. Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds. InCVPR, 2025
2025
-
[24]
Vmem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory. InICCV, 2025
2025
-
[25]
Neural scene flow fields for space-time view synthesis of dynamic scenes
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6498–6508, 2021
2021
-
[26]
MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos. InCVPR, 2025
2025
-
[27]
Movies: Motion-aware 4d dynamic view synthesis in one second
Chenguo Lin, Yuchen Lin, Panwang Pan, Yifan Yu, Tao Hu, Honglei Yan, Katerina Fragkiadaki, and Yadong Mu. Movies: Motion-aware 4d dynamic view synthesis in one second. InCVPR, 2026
2026
-
[28]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InICLR, 2026
2026
-
[29]
Vista4D: Video Reshooting with 4D Point Clouds
Kuan Heng Lin, Zhizheng Liu, Pablo Salamanca, Yash Kant, Ryan Burgert, Yuancheng Xu, Koichi Namekata, Yiwei Zhao, Bolei Zhou, Micah Goldblum, et al. Vista4d: Video reshooting with 4d point clouds.arXiv preprint arXiv:2604.21915, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors. InNeurIPS, 2024
2024
-
[31]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Robust dynamic radiance fields
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Johannes Kopf, and Jia-Bin Huang. Robust dynamic radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13–23, 2023
2023
-
[33]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In3DV, 2024. 12
2024
-
[35]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=aBsCjcPu_tE
2022
-
[36]
Orb-slam: A versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163, 2015
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: A versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163, 2015
2015
-
[37]
Michal Nazarczuk, Sibi Catley-Chandar, Thomas Tanay, Zhensong Zhang, Gregory Slabaugh, and Eduardo Pérez-Pellitero. Vidar: Video diffusion-aware 4d reconstruction from monocular inputs.arXiv preprint arXiv:2506.18792, 2025
-
[38]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5865–5874, 2021
2021
-
[39]
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields.arXiv preprint arXiv:2106.13228, 2021
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[41]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10318–10327, 2021
2021
-
[43]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InCVPR, 2025
2025
-
[44]
Seyedmorteza Sadat, Otmar Hilliges, and Romann M. Weber. Eliminating oversaturation and artifacts of high guidance scales in diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=e2ONKX6qzJ
2025
-
[45]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InCVPR, 2016
2016
-
[46]
Dynamic gaussian marbles for novel view synthesis of casual monocular videos
Colton Stearns, Adam Harley, Mikaela Uy, Florian Dubost, Federico Tombari, Gordon Wet- zstein, and Leonidas Guibas. Dynamic gaussian marbles for novel view synthesis of casual monocular videos. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[47]
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. Dreamcraft3d: Hierarchical 3d generation with bootstrapped diffusion prior.arXiv preprint arXiv:2310.16818, 2023
-
[48]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV. Springer, 2020
2020
-
[49]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.NeurIPS, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.NeurIPS, 2021
2021
-
[50]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[52]
Shape of motion: 4d reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruction from a single video. InICCV, 2025
2025
-
[53]
Qisen Wang, Yifan Zhao, and Jia Li. Worldtree: Towards 4d dynamic worlds from monocular video using tree-chains.arXiv preprint arXiv:2602.11845, 2026
-
[54]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[55]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems, 36:8406–8441, 2023
2023
-
[56]
Difix3d+: Improving 3d reconstructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models. InCVPR, 2025
2025
-
[57]
Reconfusion: 3d reconstruction with diffusion priors
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al. Reconfusion: 3d reconstruction with diffusion priors. InCVPR, 2024
2024
-
[58]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. In CVPR, 2025
2025
-
[59]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284,
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
-
[60]
Spatialtrackerv2: Advancing 3d point tracking with explicit camera motion
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: Advancing 3d point tracking with explicit camera motion. InICCV, 2025
2025
-
[61]
4dgt: Learning a 4d gaussian transformer using real-world monocular videos
Zhen Xu, Zhengqin Li, Zhao Dong, Xiaowei Zhou, Richard Newcombe, and Zhaoyang Lv. 4dgt: Learning a 4d gaussian transformer using real-world monocular videos. InNeurIPS, 2025
2025
-
[62]
Neoverse: Enhancing 4d world model with in-the-wild monocular videos.CVPR, 2026
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, and Zhaoxiang Zhang. Neoverse: Enhancing 4d world model with in-the-wild monocular videos.CVPR, 2026
2026
-
[63]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InICCV, 2025
2025
-
[64]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. Monst3r: A simple approach for estimating geometry in the presence of motion.arXiv preprint arXiv:2410.03825, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Wildgs-slam: Monocular gaussian splatting slam in dynamic environments
Jianhao Zheng, Zihan Zhu, Valentin Bieri, Marc Pollefeys, Songyou Peng, and Armeni Iro. Wildgs-slam: Monocular gaussian splatting slam in dynamic environments. InCVPR, 2025
2025
-
[67]
Dynpoint: Dynamic neural point for view synthesis.Advances in Neural Information Processing Systems, 36:69532–69545, 2023
Kaichen Zhou, Jia-Xing Zhong, Sangyun Shin, Kai Lu, Yiyuan Yang, Andrew Markham, and Niki Trigoni. Dynpoint: Dynamic neural point for view synthesis.Advances in Neural Information Processing Systems, 36:69532–69545, 2023. 14
2023
-
[68]
Page-4d: Disentangled pose and geometry estimation for 4d perception.arXiv e-prints, 2025
Kaichen Zhou, Yuhan Wang, Grace Chen, Xinhai Chang, Gaspard Beaudouin, Fangneng Zhan, Paul Pu Liang, and Mengyu Wang. Page-4d: Disentangled pose and geometry estimation for 4d perception.arXiv e-prints, 2025
2025
-
[69]
Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction
Zhizhuo Zhou and Shubham Tulsiani. Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction. InCVPR, 2023
2023
-
[70]
Liyuan Zhu, Manjunath Narayana, Michal Stary, Will Hutchcroft, Gordon Wetzstein, and Iro Armeni. Gaussfusion: Improving 3d reconstruction in the wild with a geometry-informed video generator.arXiv preprint arXiv:2603.25053, 2026. 15 Supplementary Material for World from Motion Abstract This supplementary document provides additional technical details, exp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.