Accurate Large-sample Uncertainty Quantification using Stochastic Gradient Markov Chain Monte Carlo
Pith reviewed 2026-06-28 22:45 UTC · model grok-4.3
The pith
New discrete-time approximations to stochastic gradient Langevin dynamics deliver accurate covariance and autocorrelation predictions for large-batch and misspecified models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We address these shortcomings by proposing new discrete-time approximations to SG(L)D with and without momentum, which enables accurate predictions of the stationary covariance, iterate average covariance, and integrated autocorrelation time. Moreover, we prove quantitative, non-asymptotic error bounds showing that these estimates are sufficiently accurate for practical tuning and uncertainty quantification.
What carries the argument
Discrete-time approximations to stochastic gradient Langevin dynamics (SGLD) and its momentum variant, used to predict covariance and autocorrelation quantities.
If this is right
- The approximations supply concrete tuning guidance for SGD and SGLD when batch size is large.
- They extend to the case of beta-divergence loss for statistically robust inferences.
- They improve uncertainty quantification across a range of models and data-generating distributions where continuous-time theory fails.
- The non-asymptotic bounds quantify how close the predictions are to the true discrete-time behavior.
Where Pith is reading between the lines
- The same style of discrete-time analysis could be applied to other stochastic-gradient samplers that currently rely on continuous-time diffusion limits.
- If the error bounds remain tight under model misspecification, practitioners could use the approximations to decide when robust losses such as beta-divergence are worth the extra computation.
Load-bearing premise
The discrete-time approximations remain quantitatively accurate with the stated non-asymptotic bounds in the large-batch and model-misspecification regimes where continuous-time limits become inaccurate.
What would settle it
Numerical comparison showing that measured stationary covariance or integrated autocorrelation time in large-batch SGLD runs deviates from the new approximations by more than the proved error bound would falsify the claim that the estimates are sufficiently accurate for practical use.
Figures
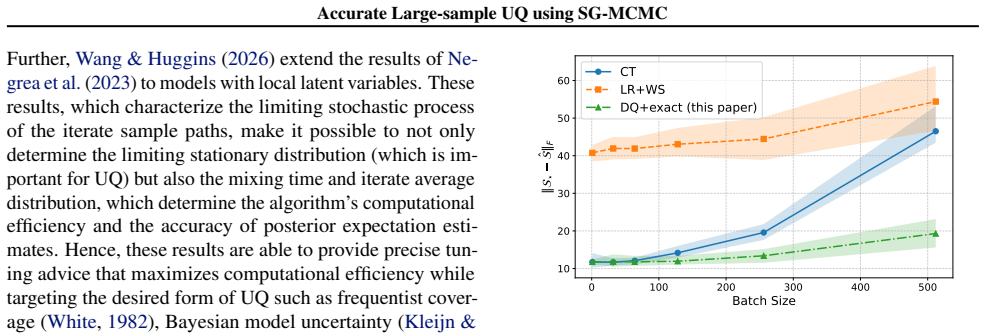
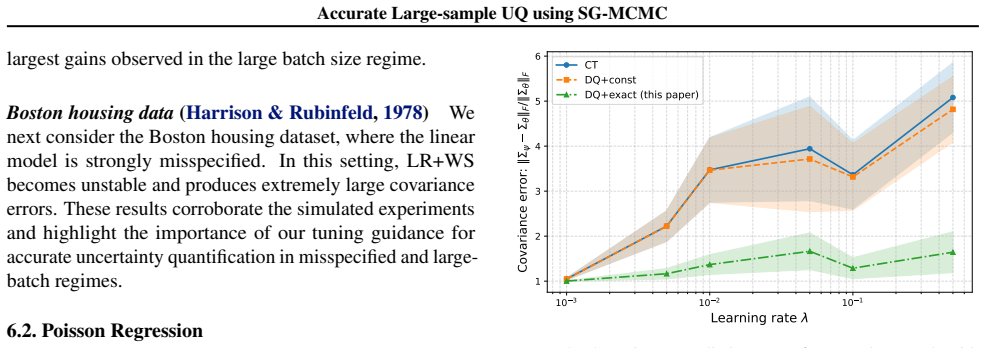
read the original abstract
Tuning algorithms such as stochastic gradient descent (SGD) and stochastic gradient Langevin dynamics (SGLD) for approximate sampling and uncertainty quantification remains challenging, particularly in the practically relevant settings when the batch size is large or the model is misspecified. Existing theory that provides tuning guidance relies on continuous-time limits or strong statistical assumptions, which can become quantitatively inaccurate in these regimes. We address these shortcomings by proposing new discrete-time approximations to SG(L)D with and without momentum, which enables accurate predictions of the stationary covariance, iterate average covariance, and integrated autocorrelation time. Moreover, we prove quantitative, non-asymptotic error bounds showing that these estimates are sufficiently accurate for practical tuning and uncertainty quantification. Numerical experiments demonstrate that our theory yields improved tuning guidance across a range of models and data-generating distributions where existing approaches fail, including when using the $\beta$-divergence rather than log-loss to obtain statistically robust inferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes new discrete-time approximations to stochastic gradient Langevin dynamics (SGLD) and SGD with/without momentum. These approximations are used to predict stationary covariance, iterate-average covariance, and integrated autocorrelation time. The authors derive quantitative non-asymptotic error bounds on the approximations and claim they remain sufficiently accurate for practical tuning and uncertainty quantification even in large-batch and model-misspecified regimes (including under the β-divergence). Supporting numerical experiments are presented across models and data distributions where continuous-time limits fail.
Significance. If the non-asymptotic bounds are tight and the discrete-time predictions remain accurate under large batch sizes and misspecification, the work would supply concrete, usable tuning guidance for approximate sampling and uncertainty quantification in stochastic optimization, addressing a documented practical limitation of existing continuous-time analyses.
major comments (2)
- [main theorem / error-bound statement (location of the quantitative bounds)] The central practical claim (abstract and introduction) that the new estimates are 'sufficiently accurate for practical tuning' in large-batch and misspecified regimes rests on the error terms in the non-asymptotic bounds remaining small enough to be useful when batch size B grows or when the β-divergence is used. The manuscript must explicitly display the dependence of the leading error terms on B and on the misspecification measure; if these terms grow with B or with the divergence, the claim does not hold even if the formal bounds are valid.
- [section deriving the discrete-time approximations and bounds] The discrete-time approximations are asserted to overcome the quantitative inaccuracy of continuous-time limits precisely in the regimes of interest. The paper should include a direct comparison (analytic or numerical) showing that the new error bounds are smaller than the continuous-time approximation error under the same large-B or misspecified conditions; otherwise the improvement is not demonstrated.
minor comments (2)
- Notation for the momentum parameter and the step-size schedule should be unified between the main text and the appendix to avoid reader confusion.
- [numerical experiments] The experimental section would benefit from reporting the actual numerical values of the predicted versus empirical covariances and autocorrelation times (rather than only qualitative improvement) so that the practical tightness of the bounds can be assessed directly.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the presentation of the error bounds and comparisons.
read point-by-point responses
-
Referee: [main theorem / error-bound statement (location of the quantitative bounds)] The central practical claim (abstract and introduction) that the new estimates are 'sufficiently accurate for practical tuning' in large-batch and misspecified regimes rests on the error terms in the non-asymptotic bounds remaining small enough to be useful when batch size B grows or when the β-divergence is used. The manuscript must explicitly display the dependence of the leading error terms on B and on the misspecification measure; if these terms grow with B or with the divergence, the claim does not hold even if the formal bounds are valid.
Authors: We agree that the dependence on batch size B and the misspecification measure must be displayed explicitly to substantiate the practical claims. Our non-asymptotic bounds are constructed such that the leading error terms remain bounded independently of B (for fixed step size and under standard smoothness assumptions) and scale appropriately with the β-divergence without invalidating the approximation accuracy. In the revision we will add an explicit corollary or remark immediately following the main theorem that isolates and states these dependencies (or their absence) for both B and the divergence parameter. revision: yes
-
Referee: [section deriving the discrete-time approximations and bounds] The discrete-time approximations are asserted to overcome the quantitative inaccuracy of continuous-time limits precisely in the regimes of interest. The paper should include a direct comparison (analytic or numerical) showing that the new error bounds are smaller than the continuous-time approximation error under the same large-B or misspecified conditions; otherwise the improvement is not demonstrated.
Authors: We acknowledge that a direct analytic or numerical side-by-side comparison of the discrete-time versus continuous-time error bounds under identical large-B and misspecified conditions would make the improvement more transparent. While the existing numerical experiments already illustrate superior predictive accuracy of the discrete-time approximations, we will add either a short analytic comparison of the respective error terms or supplementary numerical results quantifying the bound gaps in the regimes of interest. revision: yes
Circularity Check
No circularity: new discrete approximations and non-asymptotic bounds derived independently
full rationale
The paper proposes discrete-time approximations to SG(L)D and proves quantitative non-asymptotic error bounds on stationary covariance, iterate-average covariance, and integrated autocorrelation time. These steps are presented as direct derivations from the discrete dynamics rather than reductions to fitted inputs, self-citations, or ansatzes imported from prior author work. No load-bearing claim reduces by construction to a quantity defined inside the paper or to a self-citation chain; the central assertions about accuracy in large-batch and misspecified regimes rest on the stated bounds themselves. This is the normal case of a self-contained theoretical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bayesian Posterior Sampling via Stochastic Gradient Fisher Scoring
Ahn, S., Korattikara, A., and Welling, M. Bayesian Posterior Sampling via Stochastic Gradient Fisher Scoring . In Langford, J. and Pineau, J. (eds.), Proceedings of the 29th International Conference on Machine Learning (ICML-12), ICML '12, pp.\ 1591--1598, New York, NY, USA, July 2012. Omnipress. ISBN 978-1-4503-1285-1
2012
-
[2]
Stochastic Gradient MCMC for Nonlinear State Space Models
Aicher, C., Putcha, S., Nemeth, C., Fearnhead, P., and Fox, E. Stochastic Gradient MCMC for Nonlinear State Space Models . Bayesian Analysis, 20 0 (1): 0 83 -- 105, 2025
2025
-
[3]
Akyildiz, O. D. and Sabanis, S. Nonasymptotic analysis of Stochastic Gradient Hamiltonian Monte Carlo under local conditions for nonconvex optimization . Journal of Machine Learning Research, 25 0 (113): 0 1--34, 2024
2024
-
[4]
J., and Mandt, S
Alexos, A., Boyd, A. J., and Mandt, S. Structured stochastic gradient MCMC . In International Conference on Machine Learning, pp.\ 414--434. PMLR, 2022
2022
-
[5]
Bissiri, P. G., Holmes, C. C., and Walker, S. G. A general framework for updating belief distributions. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78 0 (5): 0 1103--1130, 2016. doi:10.1111/rssb.12158
-
[6]
Large-scale machine learning with stochastic gradient descent
Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT'2010: 19th International Conference on Computational Statistics, Paris, France, August 22-27, 2010 Keynote, Invited and Contributed Papers, pp.\ 177--186. Springer, 2010
2010
-
[7]
The promises and pitfalls of stochastic gradient L angevin dynamics
Brosse, N., Durmus, A., and Moulines, E. The promises and pitfalls of stochastic gradient L angevin dynamics. In Advances in Neural Information Processing Systems, 2018
2018
-
[8]
Active bias: Training more accurate neural networks by emphasizing high variance samples
Chang, H.-S., Learned-Miller, E., and McCallum, A. Active bias: Training more accurate neural networks by emphasizing high variance samples. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[9]
Efficient and generalizable tuning strategies for stochastic gradient mcmc
Coullon, J., South, L., and Nemeth, C. Efficient and generalizable tuning strategies for stochastic gradient MCMC . Statistics and Computing, 33 0 (3): 0 66, 2023. ISSN 0960-3174. doi:10.1007/s11222-023-10233-3
-
[10]
Dalalyan, A. S. Theoretical guarantees for approximate sampling from smooth and log-concave densities. Journal of the Royal Statistical Society Series B: Statistical Methodology, 79 0 (3): 0 651--676, 2017. doi:10.1111/rssb.12183
-
[11]
Bridging the gap between constant step size stochastic gradient descent and M arkov chains
Dieuleveut, A., Durmus, A., and Bach, F. Bridging the gap between constant step size stochastic gradient descent and Markov chains . Annals of Statistics, 48 0 (3): 0 1348--1382, 2020. doi:10.1214/19-AOS1850
-
[12]
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R. Least angle regression. The Annals of Statistics, 32 0 (2): 0 407--499, 2004. doi:10.1214/009053604000000067
-
[13]
Gardiner, C. W. Handbook of stochastic methods for physics, chemistry and the natural sciences. Springer series in synergetics, 1985
1985
-
[14]
B., Stern, H
Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B. Bayesian data analysis. Chapman and Hall/CRC, 1995
1995
-
[15]
Geyer, C. J. Practical Markov Chain Monte Carlo . Statistical Science, 7 0 (4): 0 473 -- 483, 1992. doi:10.1214/ss/1177011137
-
[16]
Ghosh, A. and Basu, A. Robust Bayes estimation using the density power divergence . Annals of the Institute of Statistical Mathematics, 68 0 (2): 0 413--437, 2016. ISSN 0020-3157. doi:10.1007/s10463-014-0499-0
-
[17]
Deep Learning
Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning . MIT Press, 2016
2016
-
[18]
Accurate, large minibatch SGD : Training ImageNet in 1 hour
Goyal, P., Doll \'a r, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., and He, K. Accurate, large minibatch SGD : Training ImageNet in 1 hour. arXiv preprint arXiv:1706.02677, 2017
Pith/arXiv arXiv 2017
-
[19]
Hammarling, S. J. Numerical solution of the stable, non-negative definite Lyapunov equation . IMA Journal of Numerical Analysis, 2 0 (3): 0 303--323, 1982. doi:10.1093/imanum/2.3.303
-
[20]
Train faster, generalize better: Stability of stochastic gradient descent
Hardt, M., Recht, B., and Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. In International Conference on Machine Learning, pp.\ 1225--1234. PMLR, 2016
2016
-
[21]
Harrison, D. and Rubinfeld, D. L. Hedonic housing prices and the demand for clean air. Journal of Environmental Economics and Management, 5 0 (1): 0 81--102, 1978. doi:https://doi.org/10.1016/0095-0696(78)90006-2
-
[22]
and Mahoney, M
Hodgkinson, L. and Mahoney, M. Multiplicative noise and heavy tails in stochastic optimization. In International Conference on Machine Learning, pp.\ 4262--4274. PMLR, 2021
2021
-
[23]
Train longer, generalize better: closing the generalization gap in large batch training of neural networks
Hoffer, E., Hubara, I., and Soudry, D. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[24]
Statlog (German Credit Data)
Hofmann, H. Statlog (German Credit Data) . UCI Machine Learning Repository, 1994
1994
-
[25]
Validated variational inference via practical posterior error bounds
Huggins, J., Kasprzak, M., Campbell, T., and Broderick, T. Validated variational inference via practical posterior error bounds. In International Conference on Artificial Intelligence and Statistics, pp.\ 1792--1802. PMLR, 2020
2020
-
[26]
Huggins, J. H. and Miller, J. W. Reproducible parameter inference using bagged posteriors . Electronic Journal of Statistics, 18 0 (1), 2024. ISSN 1935-7524. doi:10.1214/24-ejs2237
-
[27]
Uncertainty-Based Selective Clustering for Active Learning
Hwang, S., Choi, J., and Choi, J. Uncertainty-Based Selective Clustering for Active Learning . IEEE Access, 10: 0 110983--110991, 2022. doi:10.1109/ACCESS.2022.3216065
-
[28]
Jantre, S., Urban, N. M., Qian, X., and Yoon, B.-J. Learning Active Subspaces for Effective and Scalable Uncertainty Quantification in Deep Neural Networks . In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 5330--5334, 2024. doi:10.1109/ICASSP48485.2024.10448265
-
[29]
Jewson, J., Smith, J. Q., and Holmes, C. Principles of Bayesian Inference Using General Divergence Criteria . Entropy, 20 0 (6): 0 442, 2018. doi:10.3390/e20060442
-
[30]
Jewson, J., Smith, J. Q., and Holmes, C. On the Stability of General Bayesian Inference . Bayesian Analysis, pp.\ 1 -- 31, 2024. doi:10.1214/24-BA1502
-
[31]
Subsampling Error in Stochastic Gradient Langevin Diffusions
Jin, K., Liu, C., and Latz, J. Subsampling Error in Stochastic Gradient Langevin Diffusions . In International Conference on Artificial Intelligence and Statistics, pp.\ 1414--1422. PMLR, 2024
2024
-
[32]
Jones, G. L. On the Markov chain central limit theorem . Probability Surveys, 1 0 (none): 0 299 -- 320, 2004. doi:10.1214/154957804100000051
-
[33]
S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P
Keskar, N. S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P. T. P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima . In International Conference on Learning Representations, 2017
2017
-
[34]
Learning to Explore for Stochastic Gradient MCMC
Kim, S., Jung, S., Kim, S., and Lee, J. Learning to Explore for Stochastic Gradient MCMC . In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024
2024
-
[35]
Kleijn, B. and van der Vaart, A. The Bernstein-Von-Mises theorem under misspecification . Electronic Journal of Statistics, 6: 0 354--381, 2012. doi:10.1214/12-EJS675
-
[36]
Kushner, H. and Yin, G. G. Stochastic approximation and recursive algorithms and applications. Springer, 2003. doi:10.1007/b97441
-
[37]
Kushner, H. J. and Huang, H. Asymptotic properties of stochastic approximations with constant coefficients. SIAM Journal on Control and Optimization, 19 0 (1): 0 87--105, 1981. doi:10.1137/0319007
-
[38]
Kushner, H. J. and Yang, J. Stochastic Approximation with Averaging of the Iterates: Optimal Asymptotic Rate of Convergence for General Processes . SIAM Journal on Control and Optimization, 31 0 (4): 0 1045--1062, 1993. ISSN 0363-0129. doi:10.1137/0331047
-
[39]
The large learning rate phase of deep learning: the catapult mechanism
Lewkowycz, A., Bahri, Y., Dyer, E., Sohl-Dickstein, J., and Gur-Ari, G. The large learning rate phase of deep learning: the catapult mechanism. arXiv preprint arXiv:2003.02218, 2020
arXiv 2003
-
[40]
Preconditioned stochastic gradient langevin dynamics for deep neural networks
Li, C., Chen, C., Carlson, D., and Carin, L. Preconditioned stochastic gradient langevin dynamics for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30, 2016. doi:10.1609/aaai.v30i1.10200
-
[41]
Stochastic Modified Equations and Adaptive Stochastic Gradient Algorithms
Li, Q., Tai, C., and E, W. Stochastic Modified Equations and Adaptive Stochastic Gradient Algorithms . In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp.\ 2101--2110. PMLR, 06--11 Aug 2017
2017
-
[42]
Stochastic Modified Equations and Dynamics of Stochastic Gradient Algorithms I: Mathematical Foundations
Li, Q., Tai, C., and E, W. Stochastic Modified Equations and Dynamics of Stochastic Gradient Algorithms I: Mathematical Foundations . Journal of Machine Learning Research, 20 0 (40): 0 1--47, 2019
2019
-
[43]
Noise and Fluctuation of Finite Learning Rate Stochastic Gradient Descent
Liu, K., Ziyin, L., and Ueda, M. Noise and Fluctuation of Finite Learning Rate Stochastic Gradient Descent . In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 7045--7056. PMLR, 18--24 Jul 2021
2021
-
[44]
A Bayesian Perspective on Training Speed and Model Selection
Lyle, C., Schut, L., Ru, R., Gal, Y., and van der Wilk, M. A Bayesian Perspective on Training Speed and Model Selection . In Advances in Neural Information Processing Systems, volume 33, pp.\ 10396--10408, 2020
2020
-
[45]
MacKay, D. J. A practical Bayesian framework for backpropagation networks. Neural Computation, 4 0 (3): 0 448--472, 1992
1992
-
[46]
D., and Blei, D
Mandt, S., Hoffman, M. D., and Blei, D. M. Stochastic Gradient Descent as Approximate Bayesian Inference . Journal of Machine Learning Research, 18 0 (134): 0 1--35, 2017
2017
-
[47]
and Zanella, G
Mauri, L. and Zanella, G. Robust Approximate Sampling via Stochastic Gradient Barker Dynamics . In Dasgupta, S., Mandt, S., and Li, Y. (eds.), Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pp.\ 2107--2115. PMLR, 02--04 May 2024
2024
-
[48]
Dynamic of stochastic gradient descent with state-dependent noise
Meng, Q., Gong, S., Chen, W., Ma, Z.-M., and Liu, T.-Y. Dynamic of stochastic gradient descent with state-dependent noise. arXiv preprint arXiv:2006.13719, 2020
arXiv 2006
-
[49]
Merad, I. and Ga \"i ffas, S. Convergence and concentration properties of constant step-size SGD through Markov chains . Electronic Journal of Statistics, 19 0 (2): 0 5843 -- 5894, 2025. doi:10.1214/25-EJS2471
-
[50]
Mori, T. and Ueda, M. Improved generalization by noise enhancement. arXiv preprint arXiv:2009.13094, 2020
arXiv 2009
-
[51]
Power-law escape rate of SGD
Mori, T., Ziyin, L., Liu, K., and Ueda, M. Power-law escape rate of SGD . In International Conference on Machine Learning, pp.\ 15959--15975. PMLR, 2022
2022
-
[52]
and Bach, F
Moulines, E. and Bach, F. Non-Asymptotic Analysis of Stochastic Approximation Algorithms for Machine Learning . In Advances in Neural Information Processing Systems, volume 24, 2011
2011
-
[53]
Negrea, J., Yang, J., Feng, H., Roy, D. M., and Huggins, J. H. Tuning stochastic gradient algorithms for statistical inference via large-sample asymptotics, 2023. arXiv preprint arXiv:2207.12395
arXiv 2023
-
[54]
Journal of the American Statistical Association , volume =
Nemeth, C. and Fearnhead, P. Stochastic Gradient Markov Chain Monte Carlo . Journal of the American Statistical Association, 116 0 (533): 0 433--450, 2021. doi:10.1080/01621459.2020.1847120
-
[55]
A., Chada, N
Paulin, D., Whalley, P. A., Chada, N. K., and Leimkuhler, B. J. Sampling from bayesian neural network posteriors with symmetric minibatch splitting langevin dynamics. In Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 of Proceedings of Machine Learning Research, pp.\ 5014--5022. PMLR, 03--05 May 2025
2025
-
[56]
Pflug, G. C. Stochastic minimization with constant step-size: asymptotic laws. SIAM Journal on Control and Optimization, 24 0 (4): 0 655--666, 1986. doi:10.1137/0324039
-
[57]
Non-convex learning via Stochastic Gradient Langevin Dynamics: a nonasymptotic analysis
Raginsky, M., Rakhlin, A., and Telgarsky, M. Non-convex learning via Stochastic Gradient Langevin Dynamics: a nonasymptotic analysis . In Proceedings of the 2017 Conference on Learning Theory, volume 65 of Proceedings of Machine Learning Research, pp.\ 1674--1703. PMLR, 07--10 Jul 2017
2017
-
[58]
Adaptive Stepsizing for Stochastic Gradient Langevin Dynamics in Bayesian Neural Networks
Rajpal, R., Leimkuhler, B., and Jiang, Y. Adaptive Stepsizing for Stochastic Gradient Langevin Dynamics in Bayesian Neural Networks . arXiv preprint arXiv:2511.11666, 2025
Pith/arXiv arXiv 2025
-
[59]
A Universal Prior for Integers and Estimation by Minimum Description Length
Rissanen, J. A Universal Prior for Integers and Estimation by Minimum Description Length . The Annals of Statistics, 11 0 (2): 0 416 -- 431, 1983. doi:10.1214/aos/1176346150
-
[60]
Roberts, G. O. and Rosenthal, J. S. Optimal Scaling of Discrete Approximations to Langevin Diffusions . Journal of the Royal Statistical Society Series B: Statistical Methodology, 60 0 (1): 0 255--268, 01 1998. ISSN 1369-7412. doi:10.1111/1467-9868.00123
-
[61]
Roberts, G. O. and Rosenthal, J. S. Optimal scaling for various Metropolis-Hastings algorithms . Statistical Science, 16 0 (4): 0 351 -- 367, 2001. doi:10.1214/ss/1015346320
-
[62]
A tail-index analysis of stochastic gradient noise in deep neural networks
Simsekli, U., Sagun, L., and Gurbuzbalaban, M. A tail-index analysis of stochastic gradient noise in deep neural networks. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 5827--5837. PMLR, 09--15 Jun 2019
2019
-
[63]
Simsekli, U., Sener, O., Deligiannidis, G., and Erdogdu, M. A. Hausdorff dimension, heavy tails, and generalization in neural networks. Advances in Neural Information Processing Systems, 33: 0 5138--5151, 2020
2020
-
[64]
Monte Carlo Methods in Statistical Mechanics: Foundations and New Algorithms, pp.\ 131--192
Sokal, A. Monte Carlo Methods in Statistical Mechanics: Foundations and New Algorithms, pp.\ 131--192. Springer US, Boston, MA, 1997. doi:10.1007/978-1-4899-0319-8_6
-
[65]
W., Thiery, A
Teh, Y. W., Thiery, A. H., and Vollmer, S. J. Consistency and Fluctuations For Stochastic Gradient Langevin Dynamics . Journal of Machine Learning Research, 17 0 (7): 0 1--33, 2016
2016
-
[66]
Statistical analysis of stochastic gradient methods for generalized linear models
Toulis, P., Airoldi, E., and Rennie, J. Statistical analysis of stochastic gradient methods for generalized linear models. In Proceedings of the 31st International Conference on Machine Learning, volume 32 of Proceedings of Machine Learning Research, pp.\ 667--675, Bejing, China, 22--24 Jun 2014. PMLR
2014
-
[67]
Van der Vaart, A. W. Asymptotic statistics, volume 3. Cambridge University Press, 2000
2000
-
[68]
Random Vectors in High Dimensions, pp.\ 38--69
Vershynin, R. Random Vectors in High Dimensions, pp.\ 38--69. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2018
2018
-
[69]
J., Zygalakis, K
Vollmer, S. J., Zygalakis, K. C., and Teh, Y. W. Exploration of the (Non-)Asymptotic Bias and Variance of Stochastic Gradient Langevin Dynamics . Journal of Machine Learning Research, 17 0 (159): 0 1--48, 2016
2016
-
[70]
An invariance principle for the Robbins-Monro process in a Hilbert space
Walk, H. An invariance principle for the Robbins-Monro process in a Hilbert space . Zeitschrift f \"u r Wahrscheinlichkeitstheorie und verwandte Gebiete , 39 0 (2): 0 135--150, 1977
1977
-
[71]
and Huggins, J
Wang, X. and Huggins, J. H. Large-scale Uncertainty Quantification for Latent Variable Models Using Subsampling Markov Chain Monte Carlo . In International Conference on Machine Learning, PMLR, 2026
2026
-
[72]
J., Negrea, J., Bourguin, S., and Huggins, J
Wang, X., Kasprzak, M. J., Negrea, J., Bourguin, S., and Huggins, J. H. Quantitative Error Bounds for Scaling Limits of Stochastic Iterative Algorithms . arXiv, 2025. doi:10.48550/arxiv.2501.12212
-
[73]
and Teh, Y
Welling, M. and Teh, Y. W. Bayesian learning via stochastic gradient Langevin dynamics . In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pp.\ 681--688, 2011
2011
-
[74]
Maximum likelihood estimation of misspecified models
White, H. Maximum likelihood estimation of misspecified models. Econometrica, 50 0 (1): 0 1--25, January 1982. doi:10.2307/1912526
-
[75]
Sampling as optimization in the space of measures: The Langevin dynamics as a composite optimization problem
Wibisono, A. Sampling as optimization in the space of measures: The Langevin dynamics as a composite optimization problem . In Bubeck, S., Perchet, V., and Rigollet, P. (eds.), Proceedings of the 31st Conference on Learning Theory, volume 75 of Proceedings of Machine Learning Research, pp.\ 2093--3027. PMLR, 2018
2093
-
[76]
N., and Hou, L
Ye, H., Michel, A. N., and Hou, L. Stability theory for hybrid dynamical systems. IEEE T ransactions on A utomatic C ontrol , 43 0 (4): 0 461--474, 1998
1998
-
[77]
The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Sharp Minima and Regularization Effects
Zhu, Z., Wu, J., Yu, B., Wu, L., and Ma, J. The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Sharp Minima and Regularization Effects . In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 7654--7663. PMLR, 09--15 Jun 2019
2019
-
[78]
Strength of Minibatch Noise in SGD
Ziyin, L., Liu, K., Mori, T., and Ueda, M. Strength of Minibatch Noise in SGD . In International Conference on Learning Representations, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.