Vision Inference Former: Sustaining Visual Consistency in Multimodal Large Language Models
Pith reviewed 2026-05-20 11:34 UTC · model grok-4.3
The pith
A lightweight module called Vision Inference Former keeps multimodal models grounded in visual input by injecting visual semantics at every decoding step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By establishing a direct bridge between pure visual representations and the model's output space, the Vision Inference Former continuously injects visual semantics throughout the decoding phase, counteracting the progressive weakening of visual dependence that occurs as generation length increases within limited context windows.
What carries the argument
The Vision Inference Former (VIF), a lightweight architectural module that establishes a direct bridge between pure visual representations and the model's output space and continuously injects visual semantics during decoding.
Load-bearing premise
The assumption that visual dependence weakens progressively with generation length inside a limited context window and that direct continuous injection of visual representations will counteract this without introducing new alignment problems or computational trade-offs.
What would settle it
Run the same long-generation benchmarks with and without VIF and measure whether visual consistency scores stop improving or begin to drop once output length exceeds the training context limit.
Figures





read the original abstract
In recent years, multimodal large language models (MLLMs) have achieved remarkable progress, primarily attributed to effective paradigms for integrating visual and textual information. The dominant connector-based paradigm projects visual features into textual sequence, enabling unified multimodal alignment and reasoning within a generative architecture. However, our experiments reveal two key limitations: (1) Although visual information serves as the core evidential modality in MLLMs, it is treated on par with textual tokens, diminishing the unique contribution of the visual modality; (2) As generation length increases, particularly within a limited context window, the model's dependence on visual information progressively weakens, resulting in deteriorated vision-language alignment and reduced consistency between generated content and visual semantics. To address these challenges, we propose the Vision Inference Former (VIF), a lightweight architectural module that establishes a direct bridge between pure visual representations and the model's output space. Specifically, VIF continuously injects visual semantics throughout the decoding phase of the inference process, ensuring that the model remains firmly grounded in visual content during generation. We conduct experiments on 14 benchmark tasks covering general reasoning, OCR, table understanding, vision-centric evaluation, and hallucination. Experimental results show that VIF consistently improves model performance across diverse architectures while introducing minimal additional overhead. The code for this work is available at https://github.com/Dong-Xinpeng/VIF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Vision Inference Former (VIF), a lightweight module inserted into multimodal LLMs that continuously injects pure visual representations directly into the output space throughout the decoding phase. The authors identify two limitations in existing connector-based MLLMs: visual tokens are treated equivalently to text tokens, and visual dependence weakens with increasing generation length inside limited context windows, leading to degraded vision-language alignment. VIF is claimed to counteract this by sustaining visual grounding, yielding consistent gains across 14 benchmarks (general reasoning, OCR, table understanding, vision-centric tasks, hallucination) on multiple architectures while adding minimal overhead. Code is released.
Significance. If the central mechanism is validated, the work could provide a practical, low-overhead method for improving visual consistency in long-form MLLM generation. Releasing code is a positive for reproducibility. The diagnosed issue of progressive visual dependence decay is plausible and worth addressing, but the significance is limited by the current experimental design not yet isolating whether continuous visual injection is the operative factor versus a generic capacity boost.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): the reported consistent improvements on 14 tasks are stated without accompanying quantitative tables, error bars, or ablations that compare VIF against a single-injection baseline or a non-visual auxiliary module; without such controls the causal attribution of gains to continuous visual injection (rather than added parameters or generic regularization) remains unestablished and is load-bearing for the central claim.
- [§2 and §3] §2 (Problem Diagnosis) and §3 (VIF Design): the assumption that visual dependence weakens progressively with generation length is asserted but not directly quantified (e.g., via per-step attention weights on visual tokens or grounding metrics across output length); likewise, no analysis is provided of whether the direct bridge to output space introduces new alignment artifacts or computational trade-offs.
minor comments (2)
- [Abstract] Abstract: key numerical results (e.g., average or per-task deltas) should be included to allow readers to gauge the magnitude of the claimed improvements.
- [§3] Notation: the integration of VIF outputs into the decoder hidden states could be clarified with a short equation or diagram in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging where additional evidence would strengthen the claims, and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments)] the reported consistent improvements on 14 tasks are stated without accompanying quantitative tables, error bars, or ablations that compare VIF against a single-injection baseline or a non-visual auxiliary module; without such controls the causal attribution of gains to continuous visual injection (rather than added parameters or generic regularization) remains unestablished and is load-bearing for the central claim.
Authors: We appreciate this point. Section 4 does report performance gains on the 14 benchmarks across multiple MLLM backbones, but we agree that the absence of error bars and targeted ablations limits the strength of the causal argument. In the revision we will add (i) standard error bars on the main results and (ii) explicit ablations that compare VIF against both a single-injection baseline and a non-visual auxiliary module of comparable parameter count. These additions will be placed in an expanded experimental section to better isolate the contribution of continuous visual injection. revision: yes
-
Referee: [§2 and §3] the assumption that visual dependence weakens progressively with generation length is asserted but not directly quantified (e.g., via per-step attention weights on visual tokens or grounding metrics across output length); likewise, no analysis is provided of whether the direct bridge to output space introduces new alignment artifacts or computational trade-offs.
Authors: We agree that direct quantification would make the problem diagnosis more rigorous. In the revised manuscript we will include (i) per-step attention-weight statistics on visual tokens as a function of generation length and (ii) grounding metrics (e.g., object-reference accuracy) measured at successive output lengths. We will also report a focused analysis of potential alignment artifacts introduced by the output-space bridge and provide a precise breakdown of the added FLOPs and latency relative to the baseline models. revision: yes
Circularity Check
No significant circularity; architectural addition validated externally
full rationale
The paper diagnoses two limitations via its own experiments and proposes the VIF module as a direct architectural fix that continuously injects visual representations during decoding. Performance gains are reported on 14 external benchmark tasks spanning reasoning, OCR, and hallucination evaluation. No equations, parameter fits, self-citations, or uniqueness theorems appear as load-bearing steps in the provided text. The derivation chain therefore remains self-contained: the claimed mechanism is tested against independent benchmarks rather than reducing to a redefinition or internal fit of its inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Vision Inference Former (VIF)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VIF continuously injects visual semantics throughout the decoding phase... p(o_l | o_<l, Zv, Zt, A_l) ... I(o_l; Z_v, A_l | Z_t, o_<l) ≥ I(o_l; Z_v | Z_t, o_<l)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
visual consistency decay... dependence on visual information progressively weakens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 6077–6086, 2018. 3
work page 2018
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In European Conference on Computer Vision, pages 370–387. Springer, 2024. 1
work page 2024
-
[4]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 3
work page 2024
-
[6]
Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, and Weiping Li. Qwen look again: Guiding vision-language reasoning mod- els to re-attention visual information.arXiv preprint arXiv:2505.23558, 2025. 1, 3
-
[7]
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999. 5
work page 1999
-
[8]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 3
work page 2023
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Multi- modal autoregressive pre-training of large vision encoders
Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor G Turrisi da Costa, Louis B ´ethune, Zhe Gan, et al. Multi- modal autoregressive pre-training of large vision encoders. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 9641–9654, 2025. 3
work page 2025
-
[11]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017. 1
work page 2017
-
[12]
Tuomo Hiippala, Malihe Alikhani, Jonas Haverinen, Timo Kalliokoski, Evanfiya Logacheva, Serafina Orekhova, Aino Tuomainen, Matthew Stone, and John A Bateman. Ai2d- rst: a multimodal corpus of 1000 primary school science dia- grams.Language Resources and Evaluation, 55(3):661–688,
-
[13]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6700–6709, 2019. 5, 1
work page 2019
-
[14]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, ICML, pages 4904–4916,
-
[15]
Dvqa: Understanding data visualizations via ques- tion answering
Kushal Kafle, Scott Cohen, Brian Price, and Christopher Kanan. Dvqa: Understanding data visualizations via ques- tion answering. InCVPR, 2018. 1
work page 2018
-
[16]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024. 1
work page 2024
-
[17]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
work page 2023
-
[18]
Mingxiao Li, Na Su, Fang Qu, Zhizhou Zhong, Ziyang Chen, Yuan Li, Zhaopeng Tu, and Xiaolong Li. Vista: Enhancing vision-text alignment in mllms via cross-modal mutual in- formation maximization.arXiv preprint arXiv:2505.10917,
-
[19]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models.arXiv preprint arXiv:2305.10355, 2023. 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 1, 3, 6
work page 2024
-
[21]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024. 5, 1
work page 2024
-
[22]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2025. 5, 1
work page 2025
-
[23]
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.Advances in neural information processing systems, 32, 2019. 3
work page 2019
-
[24]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019. 5, 1
work page 2019
-
[25]
ChartQA: A benchmark for question answer- ing about charts with visual and logical reasoning
Ahmed Masry, Do Long, Jia Qing Tan, Shafiq Joty, and Ena- mul Hoque. ChartQA: A benchmark for question answer- ing about charts with visual and logical reasoning. InFind- ings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, 2022. Association for Computational Linguistics. 1
work page 2022
-
[26]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 5, 1
work page 2021
-
[27]
Minesh Mathew, Viraj Bagal, Rub `en Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision, pages 1697–1706, 2022. 5, 1
work page 2022
-
[28]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 international conference on document analysis and recognition (ICDAR), pages 947–
- [29]
-
[30]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. pages 8748–8763, 2021. 3, 6
work page 2021
-
[31]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable train- ing deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international con- ference on knowledge discovery & data mining, pages 3505– 3506, 2020. 6
work page 2020
-
[32]
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhattacharyya. Scienceqa: A novel resource for question answering on scholarly articles.International Journal on Digital Libraries, 23(3):289–301, 2022. 5, 1
work page 2022
-
[33]
What is a savitzky-golay filter?[lecture notes].IEEE Signal processing magazine, 28(4):111–117,
Ronald W Schafer. What is a savitzky-golay filter?[lecture notes].IEEE Signal processing magazine, 28(4):111–117,
-
[34]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019. 5, 1
work page 2019
-
[35]
Octopus: Alleviating hal- lucination via dynamic contrastive decoding
Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. Octopus: Alleviating hal- lucination via dynamic contrastive decoding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29904–29914, 2025. 1
work page 2025
-
[36]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian- 1: A fully open, vision-centric exploration of multimodal llms.arXiv preprint arXiv:2406.16860, 2024. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal understanding and generation via instruction tuning.arXiv preprint arXiv:2412.14164, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 5, 1
work page 2024
-
[40]
Reconstructive visual instruction tuning.arXiv preprint arXiv:2410.09575, 2024
Haochen Wang, Anlin Zheng, Yucheng Zhao, Tiancai Wang, Zheng Ge, Xiangyu Zhang, and Zhaoxiang Zhang. Reconstructive visual instruction tuning.arXiv preprint arXiv:2410.09575, 2024. 3, 6, 1
-
[41]
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Mea- suring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Sys- tems, 37:95095–95169, 2024. 1
work page 2024
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
x.ai. Grok-1.5 vision preview, 2024. Accessed: 2025-01-26. 5, 1
work page 2024
-
[44]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556– 9567, 2024. 5, 1
work page 2024
-
[46]
Li Yujian and Liu Bo. A normalized levenshtein distance metric.IEEE transactions on pattern analysis and machine intelligence, 29(6):1091–1095, 2007. 1
work page 2007
-
[47]
De- biasing multimodal large language models.arXiv preprint arXiv:2403.05262, 2024
Yi-Fan Zhang, Weichen Yu, Qingsong Wen, Xue Wang, Zhang Zhang, Liang Wang, Rong Jin, and Tieniu Tan. De- biasing multimodal large language models.arXiv preprint arXiv:2403.05262, 2024. 1
-
[48]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 3 Vision Inference Former: Sustaining Visual Consistency in Multimodal Large Language Models Supp...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Experimental details In this section, we present the specific experimental setting including benchmarks and train details. 7.1. Benchmarks We conducted extensive evaluations across a comprehen- sive set of 14 benchmark datasets, includin MMMU [45], RealWorldQA [43], MMBench [22], MMStar [4], OK- VQA [24], GQA [13], ScienceQA [32], and MMVP [39], OCRBench ...
-
[51]
Where is the woman’s blue bag located in the image?
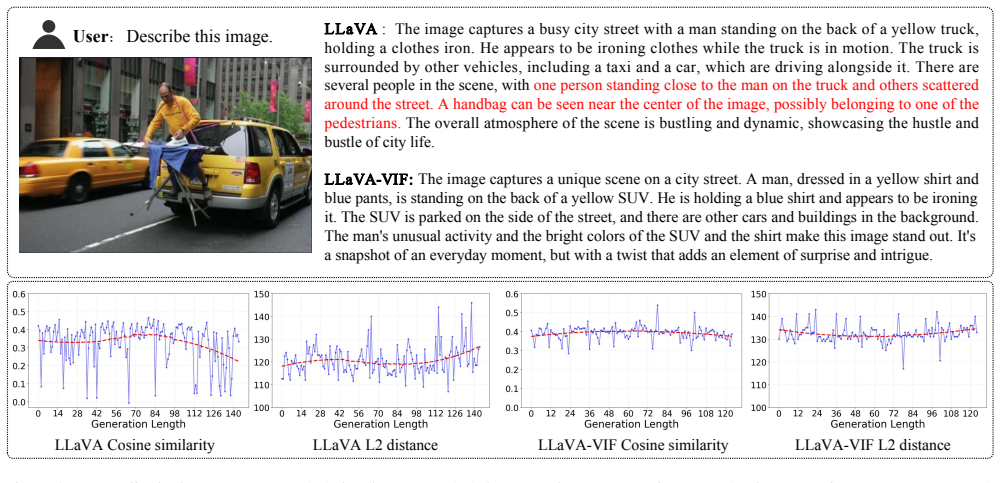
Case study To qualitatively assess how the proposed Vision Inference Former (VIF) enhances visual grounding and reasoning consistency, we present representative case studies compar- ing LLaV A-1.5-7B and our LLaV A-VIF on visual question answering and image description tasks. As shown in Figure 5, the question asks: “Where is the woman’s blue bag located ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.