AnyScene: Towards Highly Controllable Driving Scene Generation at Anywhere and Beyond
Pith reviewed 2026-06-29 21:12 UTC · model grok-4.3
The pith
AnyScene generates controllable multi-view driving videos from arbitrary BEV layouts by treating occupancy as the central spatial representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
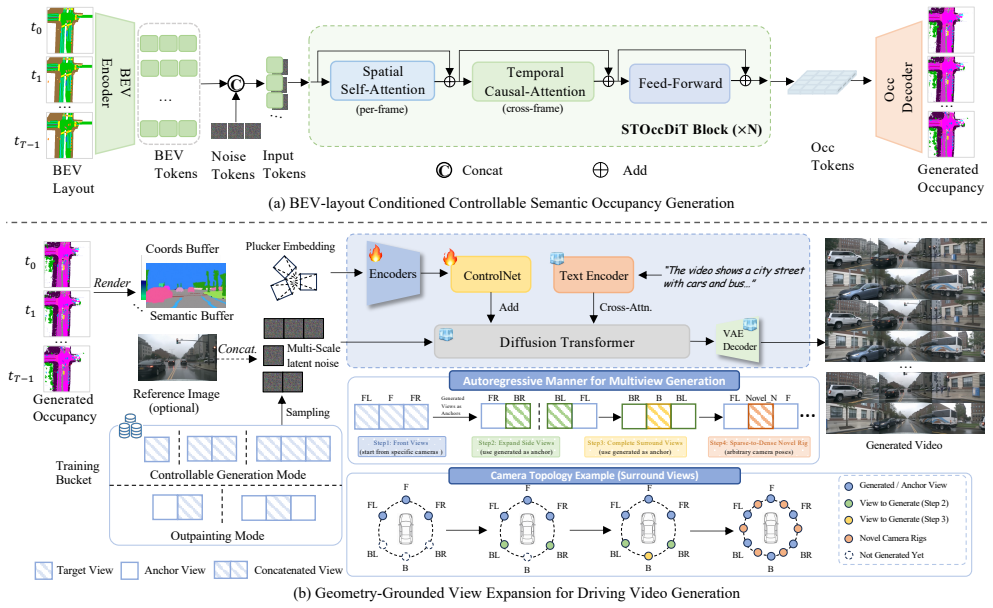
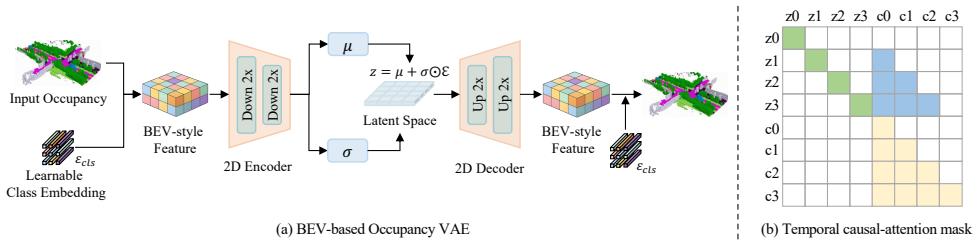
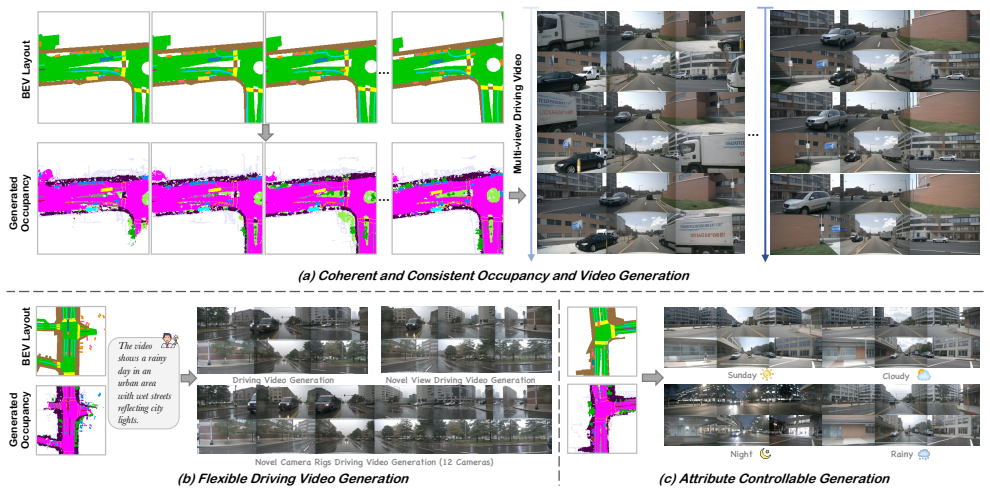
AnyScene generates semantic occupancy sequences from BEV layouts through a Spatial-Temporal Occupancy Diffusion Transformer that jointly tokenizes BEV and occupancy features in an autoregressive manner. This enables precise controllability from cross-dataset and user-defined BEV inputs while naturally supporting long-horizon generation. Building upon the generated occupancy, a Geometry-Grounded View Expansion module treats occupancy as the canonical spatial representation and synthesizes temporally consistent multi-view driving videos in a reference-free and autoregressive fashion, supporting flexible camera configurations at inference time.
What carries the argument
Spatial-Temporal Occupancy Diffusion Transformer for autoregressive BEV-to-occupancy generation, paired with the Geometry-Grounded View Expansion module that uses occupancy as the canonical spatial representation for reference-free video synthesis.
If this is right
- Precise controllability from cross-dataset and user-defined BEV inputs.
- Natural support for long-horizon generation.
- State-of-the-art performance in both occupancy and video generation tasks.
- Strong generalization to unseen and customized layouts.
- Measurable benefits for downstream tasks such as sparse-view 3D reconstruction.
Where Pith is reading between the lines
- The reference-free video synthesis step could reduce the engineering overhead of maintaining reference frames when building large-scale simulation datasets.
- Because the method separates occupancy generation from view synthesis, it may allow independent scaling of the spatial and visual components in future work.
- The same occupancy-centric pipeline could be tested on non-driving robotic environments where layout control from top-down inputs is useful.
Load-bearing premise
Occupancy serves as a sufficient canonical spatial representation enabling reference-free autoregressive multi-view video synthesis with flexible camera configurations at inference time.
What would settle it
A set of test cases in which video outputs lose temporal consistency or controllability when the model is given unseen customized BEV layouts together with novel camera configurations at inference time.
Figures













read the original abstract
Generating high-fidelity and controllable synthetic data is critical for advancing end-to-end autonomous driving, particularly for addressing the long tail of rare safety-critical scenarios. Existing occupancy-guided methods typically rely on shallow conditioning mechanisms and reference-frame-dependent video synthesis, which limits fine-grained controllability from arbitrary BEV layouts and restricts their applicability for scalable simulation. In this paper, we propose AnyScene, a unified occupancy-centric framework for driving scene generation. AnyScene generates semantic occupancy sequences from BEV layouts through a Spatial-Temporal Occupancy Diffusion Transformer that jointly tokenizes BEV and occupancy features in an autoregressive manner. This design enables precise controllability from cross-dataset and user-defined BEV inputs while naturally supporting long-horizon generation. Building upon the generated occupancy, a Geometry-Grounded View Expansion module treats occupancy as the canonical spatial representation and synthesizes temporally consistent multi-view driving videos in a reference-free and autoregressive fashion, supporting flexible camera configurations at inference time. Extensive experiments demonstrate that AnyScene achieves state-of-the-art performance in both occupancy and video generation. It exhibits strong generalization to unseen and customized layouts, and provides measurable benefits for downstream tasks such as sparse-view 3D reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
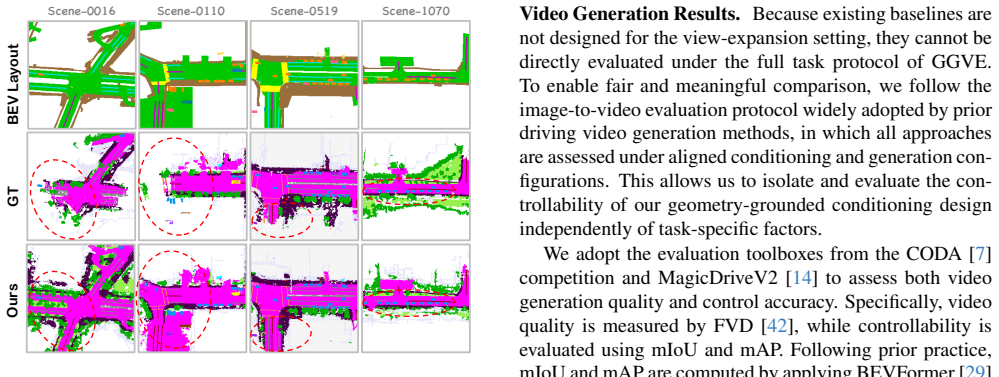
Summary. The paper introduces AnyScene, a unified occupancy-centric framework for generating high-fidelity and controllable driving scenes. It proposes a Spatial-Temporal Occupancy Diffusion Transformer to generate semantic occupancy sequences autoregressively from BEV layouts, enabling controllability from cross-dataset and user-defined inputs and long-horizon generation. Building on this, the Geometry-Grounded View Expansion module uses occupancy as the canonical representation to synthesize temporally consistent multi-view videos in a reference-free autoregressive manner with flexible camera configurations at inference. The authors report state-of-the-art performance in occupancy and video generation, strong generalization to unseen and customized layouts, and benefits for downstream tasks such as sparse-view 3D reconstruction.
Significance. If the results hold, AnyScene would advance controllable synthetic data generation for autonomous driving by overcoming shallow conditioning and reference-frame dependence in prior occupancy-guided approaches, supporting scalable simulation of rare scenarios and improved downstream perception.
major comments (1)
- [Geometry-Grounded View Expansion module] Geometry-Grounded View Expansion module (abstract): the claim that occupancy serves as a sufficient canonical spatial representation for reference-free autoregressive multi-view video synthesis with flexible cameras is load-bearing for the generalization and downstream-task claims. Semantic occupancy encodes layout and semantics but omits view-dependent appearance, surface normals, lighting, and dynamic occlusions; the manuscript must show (via module architecture or targeted ablations) how these are recovered without error accumulation over long horizons or unseen poses.
minor comments (1)
- Abstract: the SOTA and generalization claims would be strengthened by naming the specific benchmarks, metrics, and baselines used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comment on the Geometry-Grounded View Expansion module raises an important point about the sufficiency of occupancy as a canonical representation. We address this directly below and commit to revisions that strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Geometry-Grounded View Expansion module] Geometry-Grounded View Expansion module (abstract): the claim that occupancy serves as a sufficient canonical spatial representation for reference-free autoregressive multi-view video synthesis with flexible cameras is load-bearing for the generalization and downstream-task claims. Semantic occupancy encodes layout and semantics but omits view-dependent appearance, surface normals, lighting, and dynamic occlusions; the manuscript must show (via module architecture or targeted ablations) how these are recovered without error accumulation over long horizons or unseen poses.
Authors: We agree that semantic occupancy primarily captures layout and semantics and does not explicitly encode view-dependent appearance, surface normals, lighting, or dynamic occlusions. The Geometry-Grounded View Expansion module addresses this by using occupancy as a 3D geometric scaffold that conditions a diffusion-based video generator; the model learns to infer missing photometric and dynamic elements from large-scale training data while the geometry grounding enforces spatial consistency across views and time. The autoregressive, reference-free design conditions each new frame on the evolving occupancy sequence and previously synthesized views, which our long-horizon experiments (Section 4.3) show maintains stability without measurable error accumulation up to 20-second sequences. Generalization to unseen poses and flexible cameras is validated through cross-dataset and user-defined layout tests. To make the recovery mechanism fully explicit, we will revise the manuscript to include (i) a detailed architectural diagram and description of how geometry features are injected into the view-expansion diffusion process and (ii) targeted ablations isolating the contribution of occupancy grounding to appearance and occlusion handling. revision: yes
Circularity Check
No circularity: novel framework with independent architectural claims
full rationale
The paper presents AnyScene as a new unified occupancy-centric framework consisting of a Spatial-Temporal Occupancy Diffusion Transformer for generating semantic occupancy sequences from BEV layouts and a Geometry-Grounded View Expansion module for reference-free multi-view video synthesis. The abstract and described components introduce these as original constructions without any equations, fitted parameters, or derivations that reduce outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing elements. The central claims rest on the proposed modules' design and downstream experimental results rather than renaming or self-referential fitting, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Occupancy grids serve as a canonical spatial representation sufficient for reference-free video synthesis
invented entities (2)
-
Spatial-Temporal Occupancy Diffusion Transformer
no independent evidence
-
Geometry-Grounded View Expansion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dynamiccity: Large-scale 4d occu- pancy generation from dynamic scenes
Hengwei Bian, Lingdong Kong, Haozhe Xie, Liang Pan, Yu Qiao, and Ziwei Liu. Dynamiccity: Large-scale 4d occu- pancy generation from dynamic scenes. InICLR, 2025. 5
2025
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InCVPR, 2023. 3
2023
-
[4]
nuscenes: A multi- modal dataset for autonomous driving.CVPR, 2020
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving.CVPR, 2020. 2, 6
2020
-
[5]
Monoscene: Monoc- ular 3d semantic scene completion
Anh-Quan Cao and Raoul de Charette. Monoscene: Monoc- ular 3d semantic scene completion. InCVPR, 2022. 2
2022
-
[6]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Kai Chen, Ruiyuan Gao, Lanqing Hong, Hang Xu, Xu Jia, Holger Caesar, Dengxin Dai, Bingbing Liu, Dzmitry Tsishkou, Songcen Xu, et al. Eccv 2024 w-coda: 1st 9 workshop on multimodal perception and comprehension of corner cases in autonomous driving.arXiv preprint arXiv:2507.01735, 2025. 8
-
[8]
Rui Chen, Zehuan Wu, Yichen Liu, Yuxin Guo, Jingcheng Ni, Haifeng Xia, and Siyu Xia. Unimlvg: Unified framework for multi-view long video generation with comprehensive control capabilities for autonomous driving.arXiv preprint arXiv:2412.04842, 2024. 3
-
[9]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Omnire: Omni ur- ban scene reconstruction.arXiv preprint arXiv:2408.16760,
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Go- jcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni ur- ban scene reconstruction.arXiv preprint arXiv:2408.16760,
-
[11]
Omnire: Omni urban scene reconstruction
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo De Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Goj- cic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni urban scene reconstruction. InInternational Conference on Learn- ing Representations, pages 85508–85527, 2025. 3
2025
-
[12]
MMEngine: Openmmlab founda- tional library for training deep learning models
MMEngine Contributors. MMEngine: Openmmlab founda- tional library for training deep learning models. 2022. 6
2022
-
[13]
Magicdrive: Street view generation with diverse 3d geometry control
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhen- guo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control. InIn- ternational Conference on Learning Representations, pages 22841–22860, 2024. 2, 3, 9
2024
-
[14]
Magicdrive-v2: High-resolution long video generation for autonomous driving with adaptive con- trol
Ruiyuan Gao, Kai Chen, Bo Xiao, Lanqing Hong, Zhen- guo Li, and Qiang Xu. Magicdrive-v2: High-resolution long video generation for autonomous driving with adaptive con- trol. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 28135–28144, 2025. 2, 3, 8, 9
2025
-
[15]
Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yi- hang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024. 2, 3, 9
2024
-
[16]
Dome: Taming diffusion model into high-fidelity controllable occupancy world model,
Songen Gu, Wei Yin, Bu Jin, Xiaoyang Guo, Junming Wang, Haodong Li, Qian Zhang, and Xiaoxiao Long. Dome: Tam- ing diffusion model into high-fidelity controllable occupancy world model.arXiv preprint arXiv:2410.10429, 2024. 5
-
[17]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Xiaotao Hu, Wei Yin, Mingkai Jia, Junyuan Deng, Xiaoyang Guo, Qian Zhang, Xiaoxiao Long, and Ping Tan. Driving- world: Constructing world model for autonomous driving via video gpt.arXiv preprint arXiv:2412.19505, 2024. 3
-
[19]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023. 2
2023
-
[20]
Subjectdrive: Scaling generative data in autonomous driving via subject control
Binyuan Huang, Yuqing Wen, Yucheng Zhao, Yaosi Hu, Yingfei Liu, Fan Jia, Weixin Mao, Tiancai Wang, Chi Zhang, Chang Wen Chen, et al. Subjectdrive: Scaling generative data in autonomous driving via subject control. InAAAI, pages 3617–3625, 2025. 3
2025
-
[21]
Neural kernel surface re- construction
Jiahui Huang, Zan Gojcic, Matan Atzmon, Or Litany, Sanja Fidler, and Francis Williams. Neural kernel surface re- construction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4369– 4379, 2023. 2
2023
-
[22]
Tri-perspective view for vision-based 3d se- mantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision-based 3d se- mantic occupancy prediction. InCVPR, 2023. 2
2023
-
[23]
Junpeng Jiang, Gangyi Hong, Miao Zhang, Hengtong Hu, Kun Zhan, Rui Shao, and Liqiang Nie. Dive: Efficient multi-view driving scenes generation based on video diffu- sion transformer.arXiv preprint arXiv:2504.19614, 2025. 3
-
[24]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17191–17202, 2025. 6
2025
-
[25]
Drivegan: Towards a controllable high-quality neural simulation
Seung Wook Kim, Jonah Philion, Antonio Torralba, and Sanja Fidler. Drivegan: Towards a controllable high-quality neural simulation. InCVPR, 2021. 3
2021
-
[26]
Semcity: Semantic scene gener- ation with triplane diffusion
Jumin Lee, Sebin Lee, Changho Jo, Woobin Im, Juhyeong Seon, and Sung-Eui Yoon. Semcity: Semantic scene gener- ation with triplane diffusion. InCVPR, pages 28337–28347,
-
[27]
Uniscene: Unified occupancy-centric driving scene generation
Bohan Li, Jiazhe Guo, Hongsi Liu, Yingshuang Zou, Yikang Ding, Xiwu Chen, Hu Zhu, Feiyang Tan, Chi Zhang, Tiancai Wang, et al. Uniscene: Unified occupancy-centric driving scene generation. InCVPR, 2025. 2, 3, 5, 7, 9, 4
2025
-
[28]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive frame- work for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong- hao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 47(3):2020–2036,
2020
-
[30]
Focal Loss for Dense Object Detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ar. Focal loss for dense object detection. arXiv:1708.02002, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Hannan Lu, Xiaohe Wu, Shudong Wang, Xiameng Qin, Xinyu Zhang, Junyu Han, Wangmeng Zuo, and Ji Tao. Seeing beyond views: Multi-view driving scene video generation with holistic attention.arXiv preprint arXiv:2412.03520, 2024. 3
-
[32]
Wovogen: World volume-aware diffusion for con- trollable multi-camera driving scene generation
Jiachen Lu, Ze Huang, Zeyu Yang, Jiahui Zhang, and Li Zhang. Wovogen: World volume-aware diffusion for con- trollable multi-camera driving scene generation. InECCV,
-
[33]
Infinicube: Unbounded and con- trollable dynamic 3d driving scene generation with world- guided video models
Yifan Lu, Xuanchi Ren, Jiawei Yang, Tianchang Shen, Zhangjie Wu, Jun Gao, Yue Wang, Siheng Chen, Mike 10 Chen, Sanja Fidler, et al. Infinicube: Unbounded and con- trollable dynamic 3d driving scene generation with world- guided video models. InICCV, 2025. 2, 3, 6, 7
2025
-
[34]
Yuechen Luo et al. Last-vla: Thinking in latent spatio- temporal space for vision-language-action in autonomous driving.arXiv preprint arXiv:2603.01928, 2026. 2
-
[35]
OpenStreetMap.https:// www.openstreetmap.org, 2025
OpenStreetMap contributors. OpenStreetMap.https:// www.openstreetmap.org, 2025. Accessed: May 15,
2025
-
[36]
arXiv preprint arXiv:2506.09042 (2025) 2 E³C: Video Generation with 3D Environmental Memory 19
Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhangjie Wu, Runjian Chen, et al. Cosmos-drive- dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042,
-
[37]
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fe- doseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InCVPR, pages 2446–2454, 2020. 2
2020
-
[39]
Rethinking the inception archi- tecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception archi- tecture for computer vision. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2818–2826, 2016. 8
2016
-
[40]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.Advances in Neural Information Processing Systems, 36:64318–64330, 2023
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.Advances in Neural Information Processing Systems, 36:64318–64330, 2023. 2
2023
-
[41]
Neurad: Neural rendering for autonomous driving
Adam Tonderski, Carl Lindstr ¨om, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. InCVPR,
-
[42]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Rapha¨el Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019. 8
2019
-
[43]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 8, 15
2025
-
[45]
Occsora: 4d occupancy generation models as world simulators for autonomous driving,
Lening Wang, Wenzhao Zheng, Yilong Ren, Han Jiang, Zhiyong Cui, Haiyang Yu, and Jiwen Lu. Occsora: 4d occupancy generation models as world simulators for au- tonomous driving.arXiv preprint arXiv:2405.20337, 2024. 2, 7
-
[46]
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, and Jiwen Lu. Drivedreamer: Towards real-world-driven world models for autonomous driving.arXiv preprint arXiv:2309.09777, 2023. 3
-
[47]
Julong Wei, Shanshuai Yuan, Pengfei Li, Qingda Hu, Zhongxue Gan, and Wenchao Ding. Occllama: An occupancy-language-action generative world model for au- tonomous driving.arXiv preprint arXiv:2409.03272, 2024. 7
-
[48]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6902–6912, 2024. 2, 3, 9
2024
-
[49]
fvdb: A deep- learning framework for sparse, large scale, and high perfor- mance spatial intelligence.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024
Francis Williams, Jiahui Huang, Jonathan Swartz, Gergely Klar, Vijay Thakkar, Matthew Cong, Xuanchi Ren, Ruilong Li, Clement Fuji-Tsang, Sanja Fidler, et al. fvdb: A deep- learning framework for sparse, large scale, and high perfor- mance spatial intelligence.ACM Transactions on Graphics (TOG), 43(4):1–15, 2024. 6
2024
-
[50]
Argoverse 2: Next generation datasets for self-driving perception and fore- casting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lam- bert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Rat- nesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and fore- casting. InNeurIPS Datasets and Benchmarks Track, 2021. 2
2021
-
[51]
Mars: An instance- aware, modular and realistic simulator for autonomous driv- ing.CICAI, 2023
Zirui Wu, Tianyu Liu, Liyi Luo, Zhide Zhong, Jianteng Chen, Hongmin Xiao, Chao Hou, Haozhe Lou, Yuantao Chen, Runyi Yang, Yuxin Huang, Xiaoyu Ye, Zike Yan, Yongliang Shi, Yiyi Liao, and Hao Zhao. Mars: An instance- aware, modular and realistic simulator for autonomous driv- ing.CICAI, 2023. 2
2023
-
[52]
Glad: A streaming scene generator for autonomous driving.arXiv preprint arXiv:2503.00045, 2025
Bin Xie, Yingfei Liu, Tiancai Wang, Jiale Cao, and Xiangyu Zhang. Glad: A streaming scene generator for autonomous driving.arXiv preprint arXiv:2503.00045, 2025. 3
-
[53]
Cross modal trans- former: Towards fast and robust 3d object detection
Junjie Yan, Yingfei Liu, Jianjian Sun, Fan Jia, Shuailin Li, Tiancai Wang, and Xiangyu Zhang. Cross modal trans- former: Towards fast and robust 3d object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 18268–18278, 2023. 1
2023
-
[54]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024. 2, 3
2024
-
[55]
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Se- ung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision.arXiv preprint arXiv:2311.02077, 2023. 2
-
[56]
Resim: Reliable world simula- tion for autonomous driving.Advances in Neural Informa- tion Processing Systems, 38:167710–167741, 2026
Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao, Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, and Li Chen. Resim: Reliable world simula- tion for autonomous driving.Advances in Neural Informa- tion Processing Systems, 38:167710–167741, 2026. 3 11
2026
-
[57]
Drivearena: A closed-loop generative sim- ulation platform for autonomous driving
Xuemeng Yang, Licheng Wen, Tiantian Wei, Yukai Ma, Jian- biao Mei, Xin Li, Wenjie Lei, Daocheng Fu, Pinlong Cai, Min Dou, et al. Drivearena: A closed-loop generative sim- ulation platform for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 26933–26943, 2025. 3
2025
-
[58]
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, and Zhaoxiang Zhang. Neoverse: Enhancing 4d world model with in-the-wild monocular videos.arXiv preprint arXiv:2601.00393, 2026. 6
-
[59]
X-scene: Large-scale driving scene generation with high fidelity and flexible controllability
Yu Yang, Alan Liang, Jianbiao Mei, Yukai Ma, Yong Liu, and Gim Hee Lee. X-scene: Large-scale driving scene generation with high fidelity and flexible controllability. Advances in Neural Information Processing Systems, 38: 104415–104451, 2026. 3, 6, 7
2026
-
[60]
Unisim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Mani- vasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Ur- tasun. Unisim: A neural closed-loop sensor simulator. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1389–1399, 2023. 3
2023
-
[61]
Zhenya Yang, Zhe Liu, Yuxiang Lu, Liping Hou, Chenxuan Miao, Siyi Peng, Bailan Feng, Xiang Bai, and Hengshuang Zhao. Geniedrive: Towards physics-aware driving world model with 4d occupancy guided video generation.arXiv preprint arXiv:2512.12751, 2025. 2, 5, 8, 9
-
[62]
Urban scene dif- fusion through semantic occupancy map.arXiv preprint arXiv:2403.11697, 2024
Junge Zhang, Qihang Zhang, Li Zhang, Ramana Rao Kom- pella, Gaowen Liu, and Bolei Zhou. Urban scene dif- fusion through semantic occupancy map.arXiv preprint arXiv:2403.11697, 2024. 3, 5
-
[63]
Epona: Autoregressive dif- fusion world model for autonomous driving
Kaiwen Zhang, Zhenyu Tang, Xiaotao Hu, Xingang Pan, Xiaoyang Guo, Yuan Liu, Jingwei Huang, Li Yuan, Qian Zhang, Xiao-Xiao Long, et al. Epona: Autoregressive dif- fusion world model for autonomous driving. InICCV, 2025. 3
2025
-
[64]
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video generation.arXiv preprint arXiv:2403.06845,
-
[65]
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. Occworld: Learning a 3d occupancy world model for autonomous driving.arXiv preprint arXiv:2311.16038, 2023. 2, 5, 7, 3, 4
-
[66]
Genad: Generative end-to-end au- tonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end au- tonomous driving. InECCV, 2024. 3
2024
-
[67]
Shine-mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations
Xingguang Zhong, Yue Pan, Jens Behley, and Cyrill Stach- niss. Shine-mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8371–8377. IEEE, 2023. 2
2023
-
[68]
Drivinggaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes. InCVPR, pages 21634–21643,
-
[69]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
nucraft: Crafting high resolution 3d semantic occupancy for unified 3d scene understanding
Benjin Zhu, Zhe Wang, and Hongsheng Li. nucraft: Crafting high resolution 3d semantic occupancy for unified 3d scene understanding. InEuropean Conference on Computer Vi- sion, pages 125–141. Springer, 2024. 1
2024
-
[71]
Consis- tentcity: Semantic flow-guided occupancy dit for temporally consistent driving scene synthesis
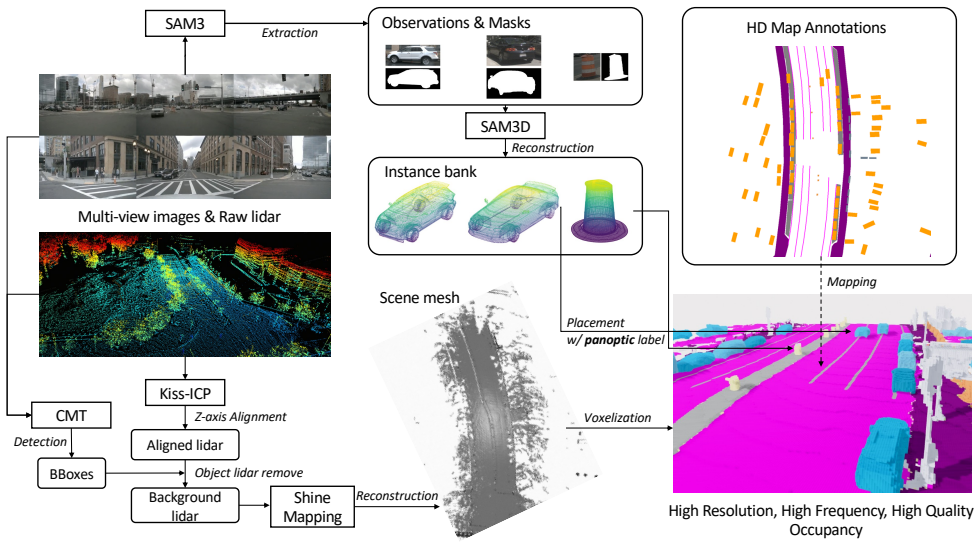
Benjin Zhu, Xiaogang Wang, and Hongsheng Li. Consis- tentcity: Semantic flow-guided occupancy dit for temporally consistent driving scene synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26382–26392, 2025. 3 12 AnyScene: Towards Highly Controllable Driving Scene Generation at Anywhere and Beyond Supplementary Mat...
2025
-
[72]
The data-curation pipeline is decomposed into two up- stream pre-stages that compute detection and per-instance priors, and five core stages that fuse them into the final vox- elized GT, executed in the following order, shown as Fig. 7. Cross-modal 3D detection.nuScenes provides GT 3D box annotations only at the2 Hzkey-frame rate, which is in- sufficient ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.