Graph Interpolating Activation Improves Both Natural and Robust Accuracies in Data-Efficient Deep Learning
Pith reviewed 2026-05-24 21:10 UTC · model grok-4.3
The pith
Replacing softmax with a graph Laplacian interpolator raises both natural accuracy and adversarial robustness for DNNs trained on limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a DNN whose final activation is the graph Laplacian interpolator, rather than softmax, integrates manifold geometry into the output layer and thereby improves both natural accuracy on clean images and robust accuracy on adversarially perturbed images, with the gains being largest when the training set is small.
What carries the argument
The graph Laplacian-based high-dimensional interpolating function that replaces softmax and converges to the solution of a Laplace-Beltrami equation on the data manifold.
If this is right
- High-capacity networks become usable with training sets an order of magnitude smaller than current practice.
- Robustness to both white-box and black-box attacks improves without extra adversarial training.
- The architecture supplies a built-in mechanism for incorporating unlabeled data in semi-supervised regimes.
- End-to-end training and inference algorithms remain essentially unchanged from standard DNN pipelines.
Where Pith is reading between the lines
- The method effectively embeds a discrete manifold-learning step inside the final layer, offering a tighter coupling than typical manifold-regularization add-ons.
- Because the interpolator is data-dependent, it may adapt automatically to distribution shift between training and test sets.
- The same construction could be applied to intermediate layers to propagate geometric information deeper into the network.
Load-bearing premise
The graph Laplacian interpolator can be inserted as the output activation of a standard DNN and trained end-to-end without introducing instabilities or prohibitive extra cost.
What would settle it
Train identical DNNs on a small labeled subset of CIFAR-10 or SVHN, once with the new activation and once with softmax, then compare clean test accuracy and accuracy under FGSM or PGD attacks; if the graph version shows no consistent gain the claim fails.
Figures



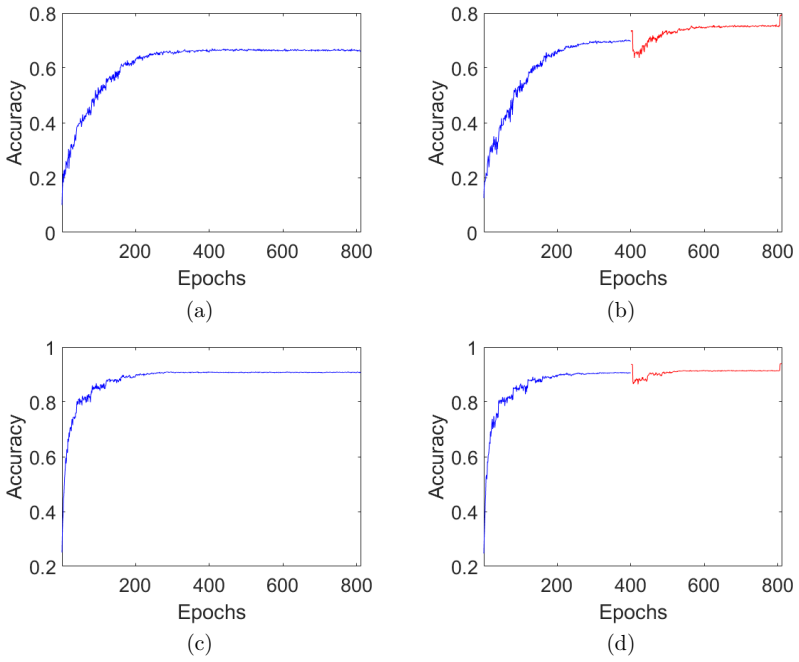



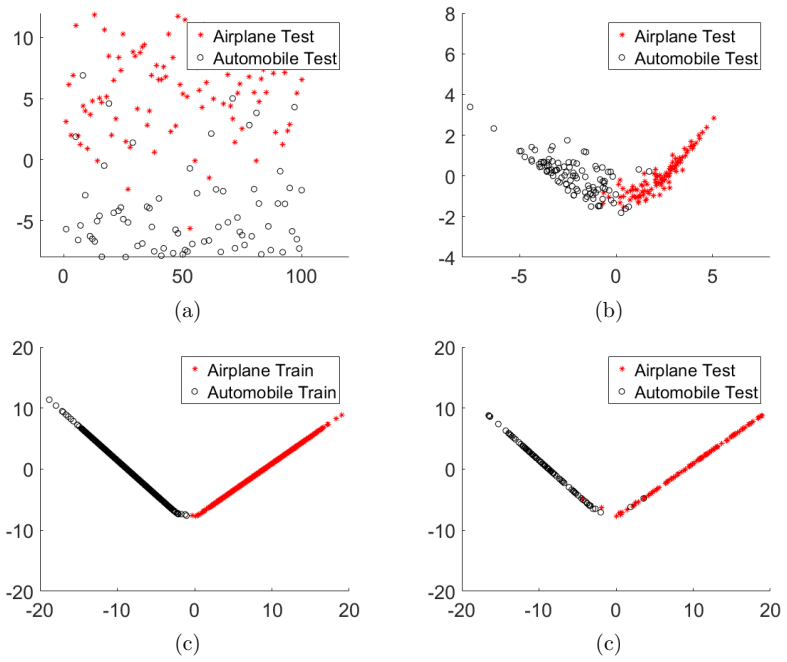


read the original abstract
Improving the accuracy and robustness of deep neural nets (DNNs) and adapting them to small training data are primary tasks in deep learning research. In this paper, we replace the output activation function of DNNs, typically the data-agnostic softmax function, with a graph Laplacian-based high dimensional interpolating function which, in the continuum limit, converges to the solution of a Laplace-Beltrami equation on a high dimensional manifold. Furthermore, we propose end-to-end training and testing algorithms for this new architecture. The proposed DNN with graph interpolating activation integrates the advantages of both deep learning and manifold learning. Compared to the conventional DNNs with the softmax function as output activation, the new framework demonstrates the following major advantages: First, it is better applicable to data-efficient learning in which we train high capacity DNNs without using a large number of training data. Second, it remarkably improves both natural accuracy on the clean images and robust accuracy on the adversarial images crafted by both white-box and black-box adversarial attacks. Third, it is a natural choice for semi-supervised learning. For reproducibility, the code is available at \url{https://github.com/BaoWangMath/DNN-DataDependentActivation}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes replacing the standard softmax output activation in DNNs with a graph Laplacian-based high-dimensional interpolating function that, in the continuum limit, solves a Laplace-Beltrami equation on the data manifold. It introduces end-to-end training and testing procedures for this architecture and claims three advantages over conventional DNNs: improved applicability to data-efficient regimes, higher natural accuracy on clean data and robust accuracy under white- and black-box adversarial attacks, and natural suitability for semi-supervised learning. Reproducible code is provided.
Significance. If the claimed accuracy and robustness gains are shown to be statistically significant, reproducible across architectures, and not artifacts of altered optimization dynamics, the work would provide a concrete mechanism for injecting manifold geometry into the output layer of deep networks. The explicit provision of code strengthens the contribution by enabling direct verification of the end-to-end differentiability claim.
major comments (3)
- [Section 3 (training algorithm)] The central claim that the graph interpolant can be stably integrated into the output layer and trained end-to-end with SGD-style optimizers rests on unverified assumptions about differentiability. The manuscript must supply the explicit back-propagation rule through the graph-Laplacian solve (or pseudoinverse) and demonstrate that the resulting gradients remain well-conditioned for standard mini-batch sizes; without this, reported gains could arise from an incidental change in the loss landscape rather than the manifold property itself.
- [Section 4 (experiments)] No quantitative results, error bars, or baseline comparisons appear in the abstract, and the full text must include tables that report natural and robust accuracy (with standard deviations over multiple runs) against at least ResNet- and VGG-style softmax baselines on CIFAR-10/100 and ImageNet subsets for the data-efficient regime. The absence of these numbers makes it impossible to assess whether the claimed improvements are load-bearing or marginal.
- [Section 2 (graph interpolating activation)] The construction of the graph Laplacian from high-dimensional features is described only at a high level; the paper must specify whether the Laplacian is recomputed every epoch from the current mini-batch embeddings or held fixed, and must quantify the additional per-iteration cost relative to standard softmax. If the cost scales with batch size squared, the data-efficiency advantage may be offset by computational overhead.
minor comments (2)
- Notation for the graph Laplacian matrix and its pseudoinverse should be introduced with an explicit equation number and kept consistent between the theoretical derivation and the algorithmic pseudocode.
- The abstract states that the method 'remarkably improves' both accuracies; the results section should replace this phrasing with precise percentage-point gains relative to the softmax baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Section 3 (training algorithm)] The central claim that the graph interpolant can be stably integrated into the output layer and trained end-to-end with SGD-style optimizers rests on unverified assumptions about differentiability. The manuscript must supply the explicit back-propagation rule through the graph-Laplacian solve (or pseudoinverse) and demonstrate that the resulting gradients remain well-conditioned for standard mini-batch sizes; without this, reported gains could arise from an incidental change in the loss landscape rather than the manifold property itself.
Authors: We agree that explicit details on differentiability are required. The accompanying code implements the graph-Laplacian solve (via pseudoinverse) and its backward pass using automatic differentiation. In the revised manuscript we will add an explicit derivation of the back-propagation rule through the linear solve and include numerical verification that gradient norms remain well-conditioned for the batch sizes employed in the experiments. This will confirm that the reported gains stem from the manifold geometry rather than incidental optimization effects. revision: yes
-
Referee: [Section 4 (experiments)] No quantitative results, error bars, or baseline comparisons appear in the abstract, and the full text must include tables that report natural and robust accuracy (with standard deviations over multiple runs) against at least ResNet- and VGG-style softmax baselines on CIFAR-10/100 and ImageNet subsets for the data-efficient regime. The absence of these numbers makes it impossible to assess whether the claimed improvements are load-bearing or marginal.
Authors: We will revise the abstract to include key quantitative highlights. In Section 4 we will add tables that report natural and robust accuracies together with standard deviations computed over multiple independent runs, and we will include direct comparisons against ResNet- and VGG-style softmax baselines on CIFAR-10/100 and ImageNet subsets in the data-efficient regime. These additions will enable a clear statistical assessment of the improvements. revision: yes
-
Referee: [Section 2 (graph interpolating activation)] The construction of the graph Laplacian from high-dimensional features is described only at a high level; the paper must specify whether the Laplacian is recomputed every epoch from the current mini-batch embeddings or held fixed, and must quantify the additional per-iteration cost relative to standard softmax. If the cost scales with batch size squared, the data-efficiency advantage may be offset by computational overhead.
Authors: We will expand Section 2 to state explicitly that the graph Laplacian is built from the current mini-batch embeddings and is recomputed at every training iteration. We will also add a complexity analysis together with empirical timing measurements that quantify the additional per-iteration cost relative to softmax; the dominant term is the linear solve whose size equals the batch size. These details will allow readers to evaluate the computational trade-off against the observed data-efficiency gains. revision: yes
Circularity Check
No circularity; architectural proposal with empirical validation
full rationale
The paper introduces a graph-Laplacian interpolating activation as a direct replacement for softmax, justified by its continuum limit to the Laplace-Beltrami equation and supported by proposed end-to-end algorithms. No derivation step equates a claimed prediction or result to its own fitted inputs or self-citations by construction. Advantages in accuracy and data efficiency are framed as empirical outcomes rather than tautological identities. The central claims rest on experimental comparisons, not on re-deriving inputs from outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning Activation Functions to Improve Deep Neural Networks
F. Agostinelli, M. Hoffman, P. Sadowski, and P. Baldi. Learning Activation Functions to Improve Deep Neural Networks. arXiv preprint arXiv:1412.6830 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Adversarial Machine Learning against Tesla’s Autopilot
Anonymous. Adversarial Machine Learning against Tesla’s Autopilot. https://www. schneier.com/blog/archives/2019/04/adversarial_mac.html,
work page 2019
-
[3]
Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models
W. Brendel, J. Rauber, and M. Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv preprint arXiv:1712.04248 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
X. Chen, C. Liu, B. Li, K. Liu, and D. Song. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. arXiv preprint arXiv:1712.05526 , 2017a. Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng. Dual Path Networks. In Advances in neural information processing systems, 2017b. J. Cohen, E. Rosenfeld, and J. Z. Kolter. Certified Adversarial ...
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[5]
Z. Dou, S. J. Osher, and B. Wang. Mathematical Analysis of Adversarial Attacks. arXiv preprint arXiv:1811.06492,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
I. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio. Maxout Networks. arXiv preprint arXiv:1302.4389 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and Harnessing Adversarial Exam- ples. arXiv preprint arXiv:1412.6275 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Improving neural networks by preventing co-adaptation of feature detectors
G. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Improv- ing neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Adam: A Method for Stochastic Optimization
D. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Deep Residual Learning and PDEs on Manifold
Z. Li and Z. Shi. Deep Residual Learning and PDEs on Manifold. arXiv preprint arXiv:1708.05115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Y. Liu, X. Chen, C. Liu, and D. Song. Delving into transferable adversarial examples and black-box attacks. arXiv preprint arXiv:1611.02770 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
S. J. Osher, B. Wang, P. Yin, X. Luo, M. Pham, and A. Lin. Laplacian Smoothing Gradient Descent. arXiv preprint arXiv:1806.06317 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z.B. Celik, and A. Swami. The Limita- tions of Deep Learning in Adversarial Settings. IEEE European Symposium on Security and Privacy, pages 372–387, 2016a. N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. IEEE Europe...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
32 A. Ross and F. Doshi-Velez. Improving the Adversarial Robustness and Interpretabil- ity of Deep Neural Networks by Regularizing Their Input Gradients. arXiv preprint arXiv:1711.09404,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://openreview.net/forum?id=BkJ3ibb0-. Z. Shi, B. Wang, and S. Osher. Error Estimation of the Weighted Nonlocal Laplacian on Random Point Cloud. arXiv preprint arXiv:1809.08622 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing Properties of Neural Networks. arXiv preprint arXiv:1312.6199 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Y. Tang. Deep Learning Using Linear Support Vector Machines. ArXiv:1306.0239,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https://openreview.net/forum?id= rkZvSe-RZ. V. Verma, A. Lamb, C. Beckham, A. Najafi, I. Mitiagkas, A. Courville, D. Lopez-Paz, and Y. Bengio. Manifold Mixup: Better Representations by Interpolating Hidden States. arXiv preprint arXiv:1806.05236 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
B. Wang, A. T. Lin, Z. Shi, W. Zhu, P. Yin, A. L. Bertozzi, and S. J. Osher. Adversar- ial Defense via Data Dependent Activation Function and Total Variation Minimization. arXiv preprint arXiv:1809.08516 , 2018a. B. Wang, X. Luo, Z. Li, W. Zhu, Z. Shi, and S. Osher. Deep Neural Nets with Interpolating Function as Output Activation. In Advances in Neural I...
-
[21]
Theoretically Principled Trade-off between Robustness and Accuracy
H. Zhang, Y. Yu, J. Jiao, E. Xing, L. Ghaoui, and M. Jordan. Theoretically Principled Trade-off between Robustness and Accuracy. arXiv preprint arXiv:1901.08573 ,
work page internal anchor Pith review Pith/arXiv arXiv 1901
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.