ROSA: A Robotics Foundation Model Serving System for Robot Factories
Pith reviewed 2026-07-02 11:09 UTC · model grok-4.3
The pith
ROSA lets fleets of factory robots share server-class GPUs over the network to run robotics foundation models and raises overall productivity up to 12 times versus dedicated per-robot hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
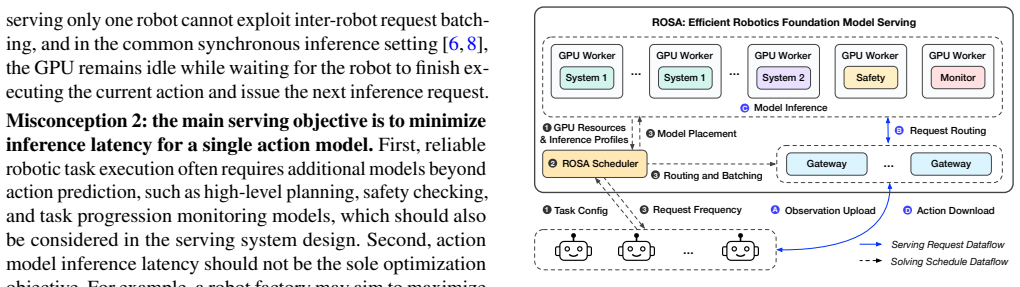
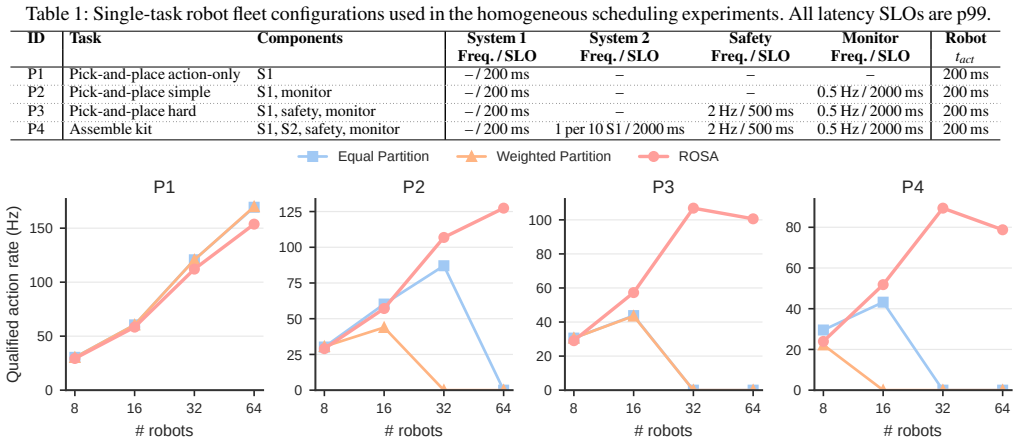
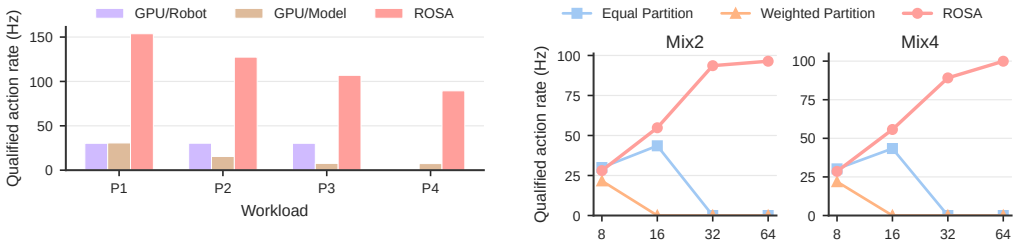
ROSA adopts shared GPU-pool serving so a fleet of robots can access powerful server-class GPUs over the network, supplies a robotics-aware programming abstraction that supports multi-model pipelines, per-task performance targets, and failure handling, and applies factory-objective-driven scheduling that maximizes the number of SLO-qualified tasks completed rather than minimizing latency for any single request. Built on Ray Serve with vLLM, PyTorch, and JAX backends, the system is tested on real robots and synthetic large-scale workloads and delivers up to 12.06 times higher factory productivity than conventional dedicated serving systems.
What carries the argument
Factory-objective-driven scheduling that allocates shared GPU resources across robot fleets while respecting per-task service level objectives and robotics-aware multi-model pipelines.
If this is right
- A fleet can share a smaller number of high-end GPUs instead of equipping every robot with its own, improving utilization and extending battery life on the robots.
- Multi-model pipelines and failure recovery become first-class features that the serving layer manages without each robot handling them locally.
- Scheduling decisions are made to increase the count of tasks that meet factory-wide performance targets rather than to shorten any individual inference time.
Where Pith is reading between the lines
- Factories could lower capital costs by deploying fewer total GPUs while still supporting larger robot fleets, provided the network remains stable.
- The same shared-pool and productivity-driven approach might apply to other multi-robot settings such as warehouses if similar network conditions hold.
- Direct measurements of end-to-end factory output under varying network quality would be the clearest way to confirm whether the reported gains survive real industrial conditions.
Load-bearing premise
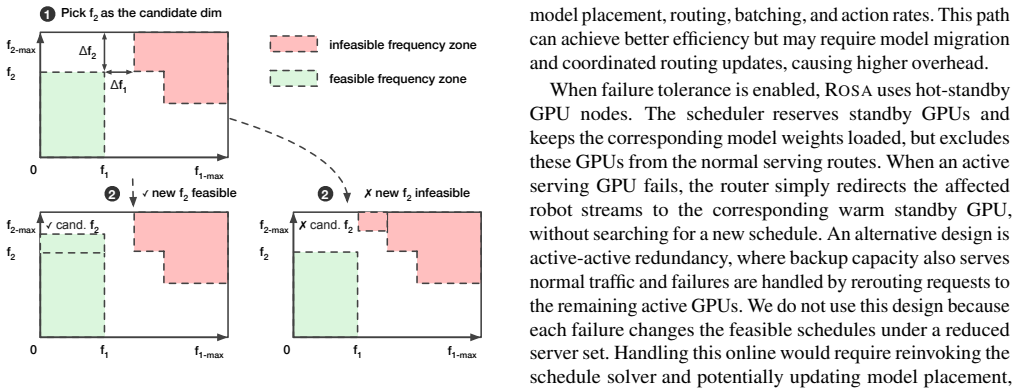
Network latency and reliability problems in a real factory setting will not cancel out the advantages of shared GPU access, and the added robotics-aware abstractions will not create new failure modes that reduce total output.
What would settle it
A physical factory deployment in which measured task throughput under ROSA falls below twice the throughput of a dedicated-GPU baseline once real network delays and packet loss are present.
Figures




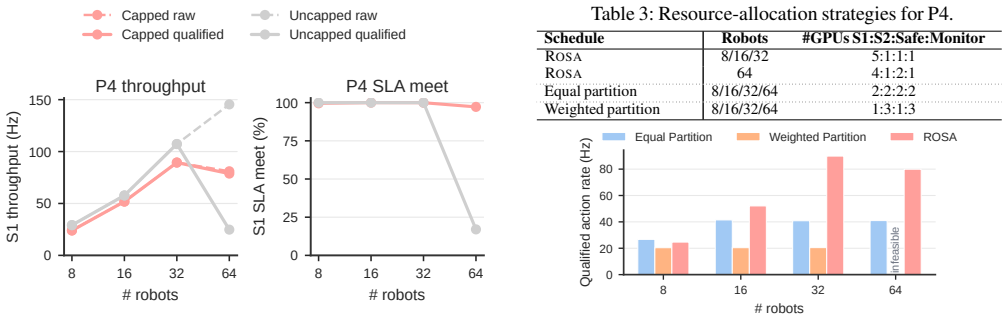



read the original abstract
Robotics foundation models (RFMs) are making general-purpose robots increasingly practical for factory deployments. While RFM serving systems are central to this vision, existing systems are largely shaped by a single-robot, single-model assumption: inference is treated as an edge-computing problem handled by an on-robot or dedicated nearby GPU, and the serving objective is to minimize the latency of a single action model. In this paper, we propose ROSA, an RFM serving system for robot factories designed around three key principles. First, ROSA adopts shared GPU-pool serving, allowing a fleet of robots to access powerful server-class GPUs over the network in order to improve inference performance, battery duration, and GPU utilization. Second, ROSA provides a robotics-aware programming abstraction and system design that supports multi-model pipelines, per-task performance requirements, and failure handling. Third, ROSA uses factory-objective-driven scheduling to maximize SLO-qualified factory productivity rather than minimizing individual request latency. We implement ROSA on top of Ray Serve for distributed orchestration, with vLLM, PyTorch, and JAX as model-serving backends, and evaluate it on both real robots and synthetic large-scale workloads. The results show that ROSA improves factory productivity by up to 12.06x over conventional dedicated serving systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ROSA, an RFM serving system for robot factories that replaces the single-robot dedicated-GPU model with three elements: shared GPU-pool serving over the network, robotics-aware abstractions supporting multi-model pipelines and failure handling, and factory-objective scheduling that maximizes SLO-qualified productivity rather than per-request latency. The system is built on Ray Serve with vLLM/PyTorch/JAX backends and is evaluated on real robots plus synthetic workloads, claiming up to 12.06x productivity gains over conventional dedicated serving systems.
Significance. If the empirical claims hold under realistic conditions, ROSA could materially improve GPU utilization, robot battery life, and factory throughput when deploying foundation models at scale. The shift from latency minimization to factory-level objective optimization is a substantive contribution to robotics systems research.
major comments (2)
- [Abstract] Abstract: the central 12.06x productivity claim is stated without any description of the workload, baseline implementation, measurement methodology, or error bars, rendering the result impossible to assess from the provided text.
- [Evaluation] Evaluation section: no end-to-end measurements are reported under realistic factory network conditions (variable latency, jitter, or transient disconnects), even though the architecture relies on network-based shared GPU access; if these factors increase missed SLOs or recovery overhead, the reported multiplier cannot be sustained.
minor comments (1)
- The terms 'conventional dedicated serving systems' and 'SLO-qualified factory productivity' are used without explicit definitions or references to prior work.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 12.06x productivity claim is stated without any description of the workload, baseline implementation, measurement methodology, or error bars, rendering the result impossible to assess from the provided text.
Authors: We agree that the abstract's brevity omits these specifics, which are instead detailed in the Evaluation section (real-robot and synthetic workloads, dedicated per-robot baseline, productivity metric under SLOs, and reported gains). To address the concern, we will revise the abstract to include a concise clause referencing the evaluation setup and directing readers to the full methodology, while preserving the abstract's length constraints. revision: yes
-
Referee: [Evaluation] Evaluation section: no end-to-end measurements are reported under realistic factory network conditions (variable latency, jitter, or transient disconnects), even though the architecture relies on network-based shared GPU access; if these factors increase missed SLOs or recovery overhead, the reported multiplier cannot be sustained.
Authors: The real-robot experiments use network-based GPU access and thus incorporate some natural network variability, with the robotics-aware failure handling designed to manage disconnects. However, we did not perform controlled sweeps of latency/jitter or explicit transient disconnect scenarios. We will add a dedicated paragraph in the Evaluation section analyzing observed network effects from the real-robot runs and discussing implications for the productivity multiplier; if space and resources permit, we will also include targeted synthetic experiments quantifying sensitivity to these factors. revision: partial
Circularity Check
No significant circularity; empirical results are self-contained
full rationale
The paper reports an empirical performance claim (up to 12.06x factory productivity improvement) obtained from direct evaluations on real robots plus synthetic workloads using Ray Serve, vLLM, PyTorch, and JAX. No equations, fitted parameters, or first-principles derivations appear in the abstract or description. The productivity multiplier is presented as a measured outcome rather than a prediction derived from inputs by construction, and no load-bearing self-citations or self-definitional steps are indicated. The derivation chain therefore rests on external experimental data and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos 3: Omnimodal World Models for Physical AI
Niket Agarwal, Arslan Ali, Jon Allen, Martin Antolini, Adeline Aubame, Alisson Azzolini, Junjie Bai, Maciej Bala, Yogesh Balaji, Josh Bapst, et al. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
DeepFleet: Multi-Agent Foundation Models for Mobile Robots
Ameya Agaskar, Sriram Siva, William Pickering, Kyle O’Brien, Charles Kekeh, Alexandre Ormiga Galvao Bar- bosa, Ang Li, Brianna Gallo Sarker, Alicia Chua, Mayur Nemade, et al. Deepfleet: Multi-agent foundation models for mobile robots.arXiv preprint arXiv:2508.08574, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Understanding Asynchronous Inference Methods for Vision-Language-Action Models
Ayoub Agouzoul. Understanding asynchronous inference methods for vision-language-action models. arXiv preprint arXiv:2605.08168, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Performance of 802.11 be wi-fi 7 with multi-link operation on ar applications
Molham Alsakati, Charlie Pettersson, Sebastian Max, Vishnu Narayanan Moothedath, and James Gross. Performance of 802.11 be wi-fi 7 with multi-link operation on ar applications. In2023 IEEE Wireless Communications and Networking Conference (WCNC), pages 1–6. IEEE, 2023
2023
-
[5]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, et al. π0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Johan Bjorck, Zhiqi Li, Yunze Man, Jing Wang, An-Chieh Cheng, Sifei Liu, Shihao Wang, Zhiding Yu, Abhishek Badki, Stan Birchfield, Valts Blukis, Yevgen Chebotar, Siyi Chen, Sicong Leng, Yu-Cheng Chou, Tianli Ding, Boyi Li, Zhengyi Luo, Hang Su, Jonathan Tremblay, Tingwu Wang, Bowen Wen, Jimmy Wu, Xianghui Xie, Hanrong Ye, Hongxu Yin, K. R. Zentner, Liangy...
2026
-
[8]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A visionlanguage-action flow model for general robot control, 2024a.URL https://arxiv. org/abs/2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Clemens C Christoph, Maximilian Eberlein, Filippos Katsimalis, Arturo Roberti, Aristotelis Sympetheros, Michel R V ogt, Davide Liconti, Chenyu Yang, Barn- abas Gavin Cangan, Ronan J Hinchet, et al. Orca: An open-source, reliable, cost-effective, anthropomorphic robotic hand for uninterrupted dexterous task learning. arXiv preprint arXiv:2504.04259, 2025
-
[11]
Kairos: A Scalable Serving System for Physical AI
Yinwei Dai, Ganesh Ananthanarayanan, Landon Cox, Xenofon Foukas, Bozidar Radunovic, and Ravi Netravali. Kairos: A scalable serving system for physical ai.arXiv preprint arXiv:2605.11381, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation.arXiv preprint arXiv:2410.00371, 2024
-
[13]
Ramy ElMallah, Krish Chhajer, and Chi-Guhn Lee. Score the steps, not just the goal: Vlm-based subgoal evaluation for robotic manipulation.arXiv preprint arXiv:2509.19524, 2025
-
[14]
F.02 contributed to the production of 30,000 cars at bmw.https://www.figure.ai/news/ production-at-bmw, November 2025
Figure AI. F.02 contributed to the production of 30,000 cars at bmw.https://www.figure.ai/news/ production-at-bmw, November 2025
2025
-
[15]
Helix: A vision-language-action model for generalist humanoid control
Figure AI. Helix: A vision-language-action model for generalist humanoid control. https: //www.figure.ai/news/helix, 2025
2025
-
[16]
Chi-Pin Huang, Yunze Man, Zhiding Yu, Min-Hung Chen, Jan Kautz, Yu-Chiang Frank Wang, and Fu-En Yang. Fast-thinkact: Efficient vision-language-action reasoning via verbalizable latent planning.arXiv preprint arXiv:2601.09708, 2026
-
[17]
Enabling the robotic revolution: Bridging the performance gap between present and future
Qijing Huang, Wenqi Jiang, Christos Kozyrakis, and Jason Clemons. Enabling the robotic revolution: Bridging the performance gap between present and future. In2026 IEEE/JSAP Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), Honolulu, HI, USA, 2026
2026
-
[18]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P Intelligence, K Black, N Brown, J Darpinian, K Dha- balia, D Driess, A Esmail, M Equi, C Finn, N Fusai, et al. π0.5: A vision-language-action model with open-world generalization. arxiv 2025.arXiv preprint arXiv:2504.16054
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Safety aware task planning via large language models in robotics
Azal Ahmad Khan, Michael Andrev, Muhammad Ali Murtaza, Sergio Aguilera, Rui Zhang, Jie Ding, Seth Hutchinson, and Ali Anwar. Safety aware task planning via large language models in robotics. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 21024–21031. IEEE, 2025
2025
-
[21]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine- tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: 14 An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[24]
Amo: Adaptive motion optimization for hyper-dexterous humanoid whole- body control,
Jialong Li, Xuxin Cheng, Tianshu Huang, Shiqi Yang, Ri- Zhao Qiu, and Xiaolong Wang. Amo: Adaptive motion optimization for hyper-dexterous humanoid whole-body control.arXiv preprint arXiv:2505.03738, 2025
-
[25]
Tao Lin, Yilei Zhong, Yuxin Du, Jingjing Zhang, Jiting Liu, Yinxinyu Chen, Encheng Gu, Ziyan Liu, Hongyi Cai, Yanwen Zou, et al. Evo-1: Lightweight vision-language-action model with preserved semantic alignment.arXiv preprint arXiv:2511.04555, 2025
-
[26]
Jun Liu, Pu Zhao, Zhenglun Kong, Xuan Shen, Peiyan Dong, Fan Yang, Lin Cui, Hao Tang, Geng Yuan, Wei Niu, et al. When should a robot think? resource-aware rea- soning via reinforcement learning for embodied robotic decision-making.arXiv preprint arXiv:2603.16673, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
A first look at wi-fi 6 in action: Throughput, latency, energy efficiency, and security.Proceedings of the ACM on Measurement and Analysis of Computing Systems, 7(1):1–25, 2023
Ruofeng Liu and Nakjung Choi. A first look at wi-fi 6 in action: Throughput, latency, energy efficiency, and security.Proceedings of the ACM on Measurement and Analysis of Computing Systems, 7(1):1–25, 2023
2023
-
[28]
Vision-language models for robot success detection
Fiona Luo. Vision-language models for robot success detection. InProceedings of the AAAI Conference on Arti- ficial Intelligence, volume 38, pages 23750–23752, 2024
2024
-
[29]
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castaneda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025
Yunchao Ma, Yizhuang Zhou, Yunhuan Yang, Tiancai Wang, and Haoqiang Fan. Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025
-
[31]
Ray: A distributed framework for emerging{AI} applications
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging{AI} applications. In13th USENIX symposium on operating systems design and implementation (OSDI 18), pages 561–577, 2018
2018
-
[32]
Chemist eye: a visual language model-powered system for safety monitoring and robot decision-making in self-driving laboratories.Digital Discovery, 5(5):2209–2220, 2026
Francisco Munguia-Galeano, Zhengxue Zhou, Satheeshkumar Veeramani, Hatem Fakhruldeen, Louis Longley, Rob Clowes, and Andrew I Cooper. Chemist eye: a visual language model-powered system for safety monitoring and robot decision-making in self-driving laboratories.Digital Discovery, 5(5):2209–2220, 2026
2026
-
[33]
Vulcan pick: A robotic system for picking targeted objects from fabric pods
Kiru Park, Johannes Kulick, Alexander Melkozerov, Roc Arandes Vilagrasa, Teguh Santoso Lembono, Vanessa Neubauer, Artem Minichev, Kade Turner, Oana Agrigoroaiei, Pascal Klink, et al. Vulcan pick: A robotic system for picking targeted objects from fabric pods. 2025
2025
- [34]
-
[35]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action
Dhruv Shah, Bła ˙zej Osi ´nski, Sergey Levine, et al. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. InConference on robot learning, pages 492–504. pmlr, 2023
2023
-
[36]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432, 2025
-
[38]
Dadu-e: Rethinking the role of large language model in robotic computing pipelines.Journal of Field Robotics, 2026
Wenhao Sun, Sai Hou, Zixuan Wang, Bo Yu, Shaoshan Liu, Xu Yang, Shuai Liang, Yiming Gan, and Yinhe Han. Dadu-e: Rethinking the role of large language model in robotic computing pipelines.Journal of Field Robotics, 2026
2026
-
[39]
Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, and Song Han. Vlash: Real-time vlas via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025
-
[40]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Tesla to kill off model s and x ve- hicles, convert fremont factory to build robots
Aidin Vaziri. Tesla to kill off model s and x ve- hicles, convert fremont factory to build robots. https://www.sfchronicle.com/tech/article/ tesla-end-model-s-x-21320796.php , January 2026. 15
2026
-
[42]
Hongyu Wang, Chuyan Xiong, Ruiping Wang, and Xilin Chen. Bitvla: 1-bit vision-language-action models for robotics manipulation.arXiv preprint arXiv:2506.07530, 2025
-
[43]
Probing Collision Grounding in Vision-Language Models for Safe Human-Robot Collaboration
Jun Wang, Xiaohao Xu, and Xiaonan Huang. Probing collision grounding in vision-language models for safe human-robot collaboration.arXiv preprint arXiv:2605.31196, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
2025
-
[46]
Dysl-vla: Efficient vision-language-action model inference via dynamic-static layer-skipping for robot manipulation
Zebin Yang, Yijiahao Qi, Tong Xie, Bo Yu, Shaoshan Liu, and Meng Li. Dysl-vla: Efficient vision-language-action model inference via dynamic-static layer-skipping for robot manipulation
-
[47]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Deer- vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shen- zhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer- vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
2024
-
[49]
Jianke Zhang, Yanjiang Guo, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, and Jianyu Chen. Hirt: Enhancing robotic control with hierarchical robot transformers.arXiv preprint arXiv:2410.05273, 2024
-
[50]
Jie Zhang, Xiaoyue Chen, Anzhe Chen, Chenxu Lv, Deqing Li, Gengze Zhou, Hang Yin, Haoqi Yuan, Haoyang Li, Jiahao Li, et al. Qwen-robotworld technical report: Unifying embodied world modeling through language-conditioned video generation.arXiv preprint arXiv:2606.17030, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control. InConfer- ence on Robot Learning, pages 2165–2183. PMLR, 2023. 16
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.